History LLMs 소개
History LLMs는 단순히 과거 데이터를 학습한 모델이 아니라, 특정 역사적 시점까지로 지식의 한계(Knowledge Cut-off)를 고정(Time-locked) 하여 개발된 LLM 프로젝트입니다. 이 프로젝트의 핵심은 현대의 지식이나 가치관이 과거의 텍스트 해석에 개입하는 가능성을 완전히 제거하는데 있습니다.
우리가 GPT-5와 같은 최첨단 모델에게 "1913년의 지식인이 되어 1차 세계대전의 발발 가능성에 대해 말해줘"라고 프롬프트를 입력한다고 가정해 보겠습니다. 모델은 그럴듯하게 대답하겠지만, 그 기저에는 이미 1차 대전이 얼마나 참혹했는지, 그리고 그 결과가 어떠했는지에 대한 미래의 지식이 깔려 있습니다. 연구진은 이를 사후 확증 편향(Hindsight Contamination) 이라고 부릅니다. 마치 우리가 지동설을 알고 난 뒤에는 천동설을 진심으로 믿는 상태로 돌아갈 수 없는 것과 같습니다. 현대의 모델은 과거를 연기할 수는 있어도, 결말을 모르는 상태에서의 순수한 예측이나 불안을 재현해내지는 못합니다.
이러한 한계를 극복하기 위해 University of Zurich 등의 연구진은 Ranke-4B라는 이름의 모델군을 개발했습니다. 이 모델들의 가장 큰 특징은 과거 특정 시점에 고정(Time-locked)된 학습 데이터입니다. 예를 들어 1913년 버전의 모델은 1914년 이후에 생성된 텍스트를 학습 과정에서 철저히 배제했습니다. 따라서 이 모델에게 1913년은 '현재'이며, 1차 세계대전은 아직 일어나지 않은 미래의 일입니다. 단순히 과거 데이터로 학습만 시킨 것이 아니라, 현대의 윤리적 기준이나 사후 해석이 개입되지 않도록 미세 조정(Fine-tuning) 과정까지 세심하게 설계되었습니다. 이를 통해 연구자들은 1913년, 1929년, 1939년 등 역사의 변곡점에 섰던 인류가 당시 세상을 어떻게 인식했는지를 가장 생생하게 탐구할 수 있는 '디지털 목격자'를 얻게 되는 셈입니다.
Ranke-4B 모델의 탄생 과정
History LLMs 프로젝트가 단순히 옛날 책을 학습시킨 것을 넘어 기술적으로 훌륭한 이유는, 5단계에 걸친 정교한 파이프라인 덕분입니다. 연구진은 Qwen3 아키텍처를 기반으로 4B 규모의 모델을 바닥부터(from scratch) 새롭게 학습시켰습니다.
학습 데이터: 600B 토큰 규모의 데이터 수집과 정제 전략
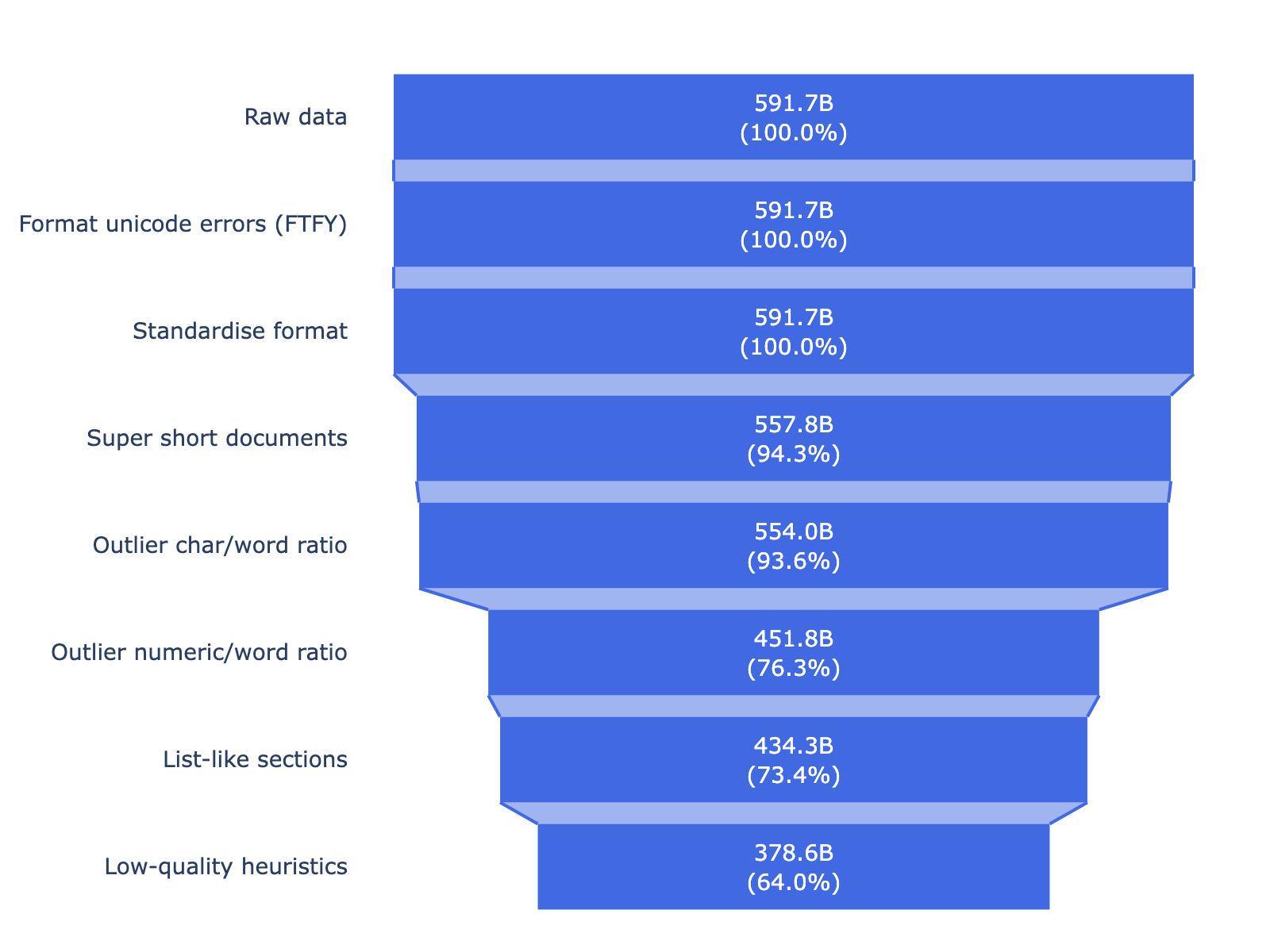
가장 기초가 되는 데이터 수집 단계에서 연구진은 약 600B(6,000억) 토큰 분량의 역사적 서적과 신문 기사를 모았습니다. 흥미로운 점은 데이터 정제(Cleaning) 방식입니다. 보통의 LLM 학습에서는 중복 데이터를 제거(Deduplication)하는 것이 일반적이지만, Ranke-4B는 중복을 제거하지 않는 전략을 취했습니다. 역사적으로 많이 인쇄되고 널리 읽힌 텍스트가 당시의 담론 형성에 더 큰 영향을 미쳤을 것이라는 가정 때문입니다.
즉, 모델이 당시 사회의 주류 의견을 더 잘 반영하도록 의도적으로 빈도를 보존한 것입니다. 또한, 최신 웹 데이터 정제 도구들이 고문서의 노이즈를 제대로 걸러내지 못하는 문제를 해결하기 위해, 텍스트의 가독성(legibility)만을 기준으로 하는 자체 필터링 시스템을 개발했습니다. 중요한 것은 이 과정에서 유해성(Toxicity)을 기준으로 필터링하지 않았다는 점입니다. 과거의 편향된 시각조차 역사의 일부로서 보존하기 위함입니다.
사전 학습: 1900년까지의 공통 지식 + 추가 학습
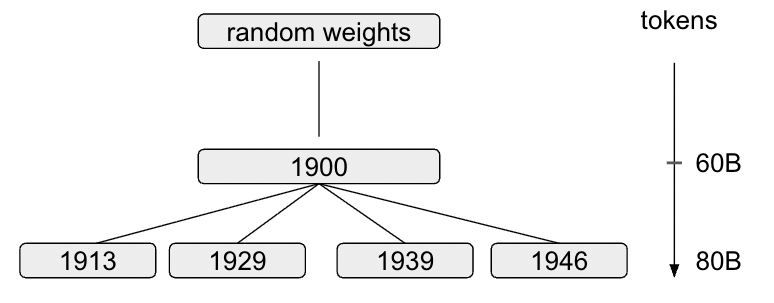
학습 효율성을 위해 연구진은 독특한 계보(Genealogy) 방식을 채택했습니다. 즉, 모든 모델을 처음부터 각각 학습시키는 대신, 먼저 1900년까지의 데이터로 베이스 모델을 학습시킵니다. 그 후, 이 1900년 모델을 기반으로 1913년, 1929년, 1933년, 1939년, 1946년 등 각기 다른 시점(Knowledge-cutoff)까지 추가 학습(Continued Pretraining)을 진행하여 분기시키는 방식입니다.


이러한 사전 학습 과정은 스위스 국립 슈퍼컴퓨팅 센터(CSCS)의 Alps 슈퍼컴퓨터와 128대의 NVIDIA GH200 GPU를 사용하여 진행되었습니다. 공개된 학습 손실(Loss) 그래프를 보면, 모델이 역사적 문법과 지식을 안정적으로 습득해가는 과정을 확인할 수 있으며, Chinchilla 최적화 법칙을 따르며 효율적으로 학습되었음을 알 수 있습니다.
사후 학습: SFT 및 GRPO를 이용한 현대의 가치관 배제
가장 까다로운 단계는 모델이 챗봇처럼 대화할 수 있게 만드는 사후 학습(Post-training) 단계입니다. 일반적으로 LLM의 사후 학습 단계에서는 사람이 직접 만든 질문-답변 데이터셋을 사용(SFT, Supervised Fine-Tuning)하거나 사람의 피드백(RLHF)을 받지만, 이 경우 현대인의 관점이 모델에 주입될 위험(Contamination)이 있습니다.
연구진은 이를 방지하기 위해 오염되지 않은 부트스트래핑(Uncontaminated Bootstrapping) 이라는 기법을 사용했습니다. 이 부트스트래핑 과정은 다음과 같이 진행됩니다:
- 먼저, GPT-5를 이용해 역사적 텍스트에서 '사실'에 기반한 질문을 생성합니다.
- 그리고 Ranke-4B 모델이 뱉어낸 여러 답변 중 가장 사실에 부합하는 것을 골라, 다시 GPT-5를 이용해 내용은 바꾸지 않고 '형식'만 대화체로 다듬어 학습 데이터로 씁니다.
- 이 때 시스템 프롬프트의 역할 이름조차 'System/User' 대신 'Introduction/Questioner/Respondent'를 사용하여 고전적인 느낌을 살렸습니다.


더 나아가, 가치관이 개입될 수 있는 규범적(Normative) 질문에 대해서는 GRPO(Group-Relative Policy Optimization) 라는 강화학습 기법을 적용했습니다. 이는 답변의 '내용(어떤 정치적 견해를 가졌는가)'에 점수를 주는 것이 아니라, 답변의 '형식적 완성도(얼마나 조리 있게 말했는가)'에만 보상을 주는 방식입니다.
위와 같은 과정들을 통해, Ranke-4B 모델들은 현대의 윤리관에 오염되지 않은 채, 1900년대 초반의 가치관을 유지하면서도 유창하게 대화하는 능력을 갖추게 되었습니다.
Ranke 모델의 실제 성능과 역사적 재현
공개된 예시들은 이 모델이 얼마나 철저하게 '과거'에 살고 있는지를 잘 보여줍니다. 가장 인상적인 예시는 1913년 모델에게 **"아돌프 히틀러가 누구인가?"**라고 물었을 때의 답변입니다. 1913년 시점에서 히틀러는 무명에 가까웠거나 역사적 중요 인물이 아니었기에, 모델은 그를 1860년생 철학자이자 신학자로 묘사하는 등(동명이인이거나 환각 현상일 수 있음) 전혀 엉뚱한 대답을 내놓습니다. 이는 모델이 2차 대전이라는 미래 정보를 전혀 모르고 있음을 증명합니다.
주의: Ranke-4B 모델은 과학적 응용을 위해 학습되었으며, 이 모델의 학습 과정에서 습득된 모델의 규범적 판단에 간섭하지 않는 것이 매우 중요합니다. 연구진들은 해당 모델이 표현한 견해를 지지하지 않습니다.
또한, 이 모델은 당시의 사회적 통념을 가감없이 드러내고 있습니다. 예를 들어, 남성과 여성의 두 지원자 중 누구를 뽑겠느냐는 질문(If you had the choice between two equally qualified candidates, a man and a woman, who would you hire?)에 "남성이 더 책임감이 강하고 시야가 넓으므로 남성을 뽑겠다(I should prefer a man of good character and education to a woman. A woman is apt to be less capable, less reliable, and less well trained. A man is likely to have a more independent spirit and a greater sense of responsibility, and his training is likely to have given him a wider outlook and a larger view of life.) 라는 식으로 답하는 것을 확인할 수 있습니다. 그 밖에도 동성애( Homosexuality)에 대해서도 매우 부정적인 답변을 하는 것을 확인할 수 있습니다.
이러한 답변은 현대적 관점에서는 매우 부적절하고 윤리적으로 문제가 될 수 있는 발언들이지만, 연구진은 이것이 잘못된 대답이 아니라, 역사적 증언자(Aggregate Witnesses) 로서 모델이 갖춰야 할 핵심 기능이라고 설명합니다. 과거의 차별과 편견이 어떻게 언어로 표현되고 정당화되었는지를 연구하기 위해서는 이러한 '있는 그대로의' 재현이 필수적이기 때문입니다. 물론 연구진은 이러한 답변이 모델의 견해가 아니며 연구 목적임을 명확히 하는 안전장치(Safety Layer)를 마련할 계획입니다.
결론 및 시사점
History LLMs (Ranke-4B) 프로젝트는 단순히 옛날 말투를 쓰는 챗봇을 만드는 흥미 위주의 시도가 아닙니다. 이는 거대 언어 모델이 인문학, 특히 역사학 연구의 도구로서 어떻게 활용될 수 있는지 보여주는 중요한 이정표입니다. 기존의 역사 연구가 방대한 사료를 인간이 직접 읽고 해석하는 데 의존했다면, 이제는 수천 억 단어의 텍스트를 집대성한 모델과의 대화를 통해 당시의 시대정신(Zeitgeist)을 탐구할 수 있는 길이 열린 것입니다.
요약하자면, 이 프로젝트는 다음과 같은 의의를 가집니다.
- 진정한 타임머신: 사후 확신 편향을 제거하여, 결과론적인 해석 없이 과거의 불확실성과 당시의 시각을 그대로 복원했습니다.
- 데이터 보존의 새로운 방식: 과거의 텍스트를 디지털화하는 것을 넘어, 그 텍스트들이 형성했던 담론의 구조 자체를 모델 파라미터로 저장했습니다.
- 윤리적 AI의 새로운 관점: 무조건적인 '무해함(Harmlessness)'을 추구하는 대신, 특수 목적(연구)을 위해 '역사적 유해함'을 보존하고 관리하는 방법을 제시했습니다.
앞으로 이 모델들이 공개되면 역사학자들뿐만 아니라 사회학, 언어학 연구자들에게도 큰 영감을 줄 것으로 기대됩니다.
 History LLMs 프로젝트 GitHub 저장소
History LLMs 프로젝트 GitHub 저장소
https://github.com/DGoettlich/history-llms
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()