
임베딩 및 정적 임베딩 모델 소개
임베딩(Embeddings)은 자연어 처리(NLP)에서 매우 유용한 도구로, 텍스트, 이미지, 오디오 등 복잡한 데이터를 고정된 크기의 벡터로 변환해 다양한 작업에 활용됩니다. 기존 임베딩 모델들은 뛰어난 성능을 제공하지만, 주로 트랜스포머 기반 구조로 인해 고비용, 느린 추론 속도라는 한계를 가지고 있었습니다.
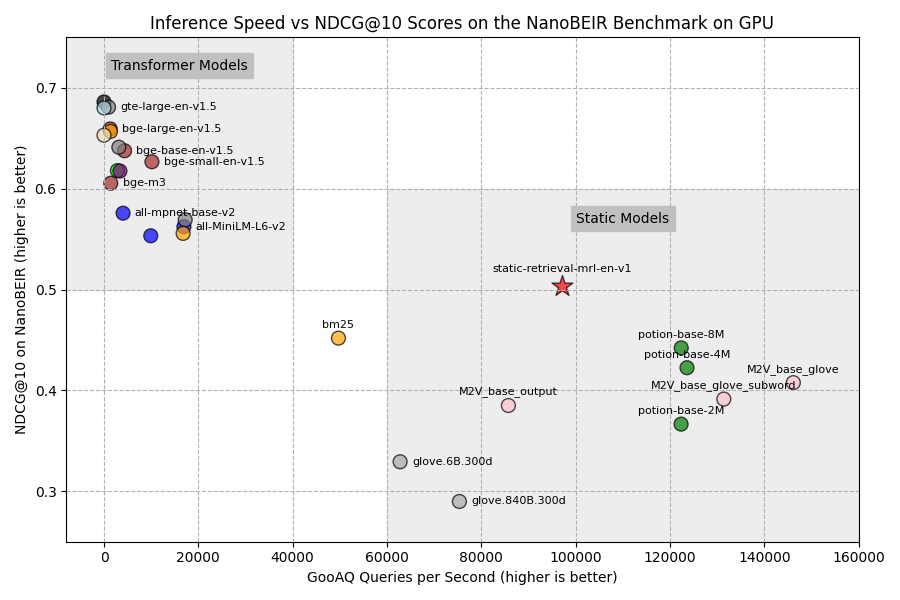
Hugging Face는 최신 학습 기술을 사용해 **정적 임베딩 모델(Static Embedding Model)**을 재조명하고, 트랜스포머 없이도 효율적이고 빠른 임베딩 모델을 만들 수 있음을 입증했습니다. 여기에는 대조학습(Contrastive Learning)과 MRL(Matryoshka Representation Learning) 같은 혁신적인 기법이 적용되었습니다.
Hugging Face가 제안한 이 방법으로 학습된 모델은 CPU에서 기존의 SotA(State-of-the-Art) 임베딩 모델보다 100배 ~ 400배 가량 빠르게 동작합니다. 이 모델은 85% 이상의 성능을 유지하며 저전력 장치, 브라우저 내 실행, 엣지 컴퓨팅, 임베디드 애플리케이션에서 유용하게 사용할 수 있습니다.
| 모델 | 속도(비교 기준) | 성능 유지율 |
|---|---|---|
| All-MPNET-base-v2 | 1x | 100% |
| Multilingual-E5-small | 1x | 100% |
| Static Retrieval 모델 | 100x~400x | 85% 이상 |
정적 임베딩 모델은 트랜스포머 기반 모델의 복잡한 연산을 단순화해, 토큰을 사전에서 찾는 수준의 연산으로 대체합니다. 이를 통해 초고속 추론이 가능해졌습니다.
정적 임베딩 모델(Static Embedding Model)의 주요 특징
- 고속 추론: CPU에서 100~400배 빠른 속도로 실행.
- 낮은 리소스 사용: 엣지 디바이스나 브라우저에서도 사용 가능.
- 현대적 학습 기법:
- 대조학습: 임베딩 간의 유사도를 학습.
- MRL: 임베딩 벡터를 작은 차원으로 줄여도 성능 유지.
- 다양한 데이터셋 활용: 30개의 학습 데이터셋과 13개의 평가 데이터셋 사용.
정적 임베딩 모델(Static Embedding Model)의 사용 방법
모델 사용은 Hugging Face의 Sentence Transformers 라이브러리를 통해 간단히 구현할 수 있습니다.
영어 전용 모델
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/static-retrieval-mrl-en-v1", device="cpu")
sentences = ["예제 문장 1", "예제 문장 2", "예제 문장 3"]
embeddings = model.encode(sentences)
print(embeddings.shape)
다국어 유사성 모델
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/static-similarity-mrl-multilingual-v1", device="cpu")
sentences = ["문장 A", "문장 B", "문장 C"]
embeddings = model.encode(sentences)
print(embeddings.shape)
라이선스
Hugging Face가 공개한 영어 모델(sentence-transformers/static-retrieval-mrl-en-v1) 및 다국어 모델(sentence-transformers/static-similarity-mrl-multilingual-v1)은 Apache 2.0 License 하에 공개되어 있습니다. 상업적 사용에도 제약이 없습니다.
 정적 임베딩 모델 소개 블로그 글
정적 임베딩 모델 소개 블로그 글 
static-retrieval-mrl-en-v1 영문 모델
static-similarity-mrl-multilingual-v1 다국어 모델
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()