
Hunyuan-T1 소개
최근 대형 언어 모델의 사후 훈련 단계에서 강화 학습이 새로운 스케일링 패러다임을 선도하며 주목받고 있습니다. OpenAI의 O 시리즈 모델과 DeepSeek R1의 연이은 발표는 이러한 강화 학습의 중요성을 입증했습니다. 이러한 흐름 속에서, 텐센트의 Hunyuan 팀은 중간 규모의 Hunyuan 기반으로 한 추론 모델인 Hunyuan T1-Preview를 출시하였습니다.
Hunyuan-T1 은 Mamba 아키텍처를 기반으로 하여 추론 능력을 크게 향상시켜, 사용자들에게 신속하고 깊이 있는 추론 경험을 제공할 것으로 기대됩니다. Hunyuan-T1은 TurboS 빠른 추론 기반과 Mamba 아키텍처를 결합한 초대형 모델로서, 인간의 선호도에 맞게 최적화된 향상된 추론 능력을 제공합니다.
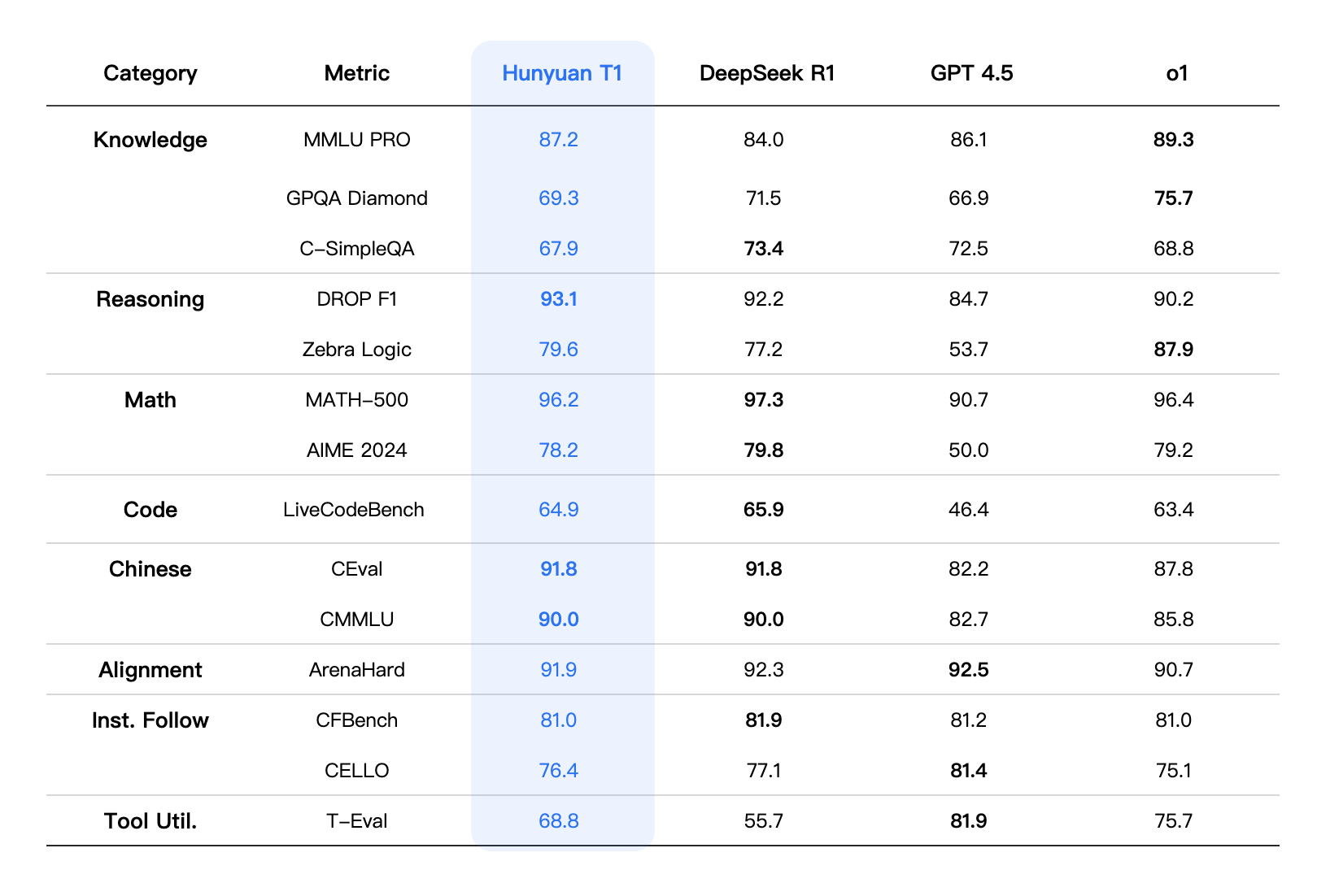
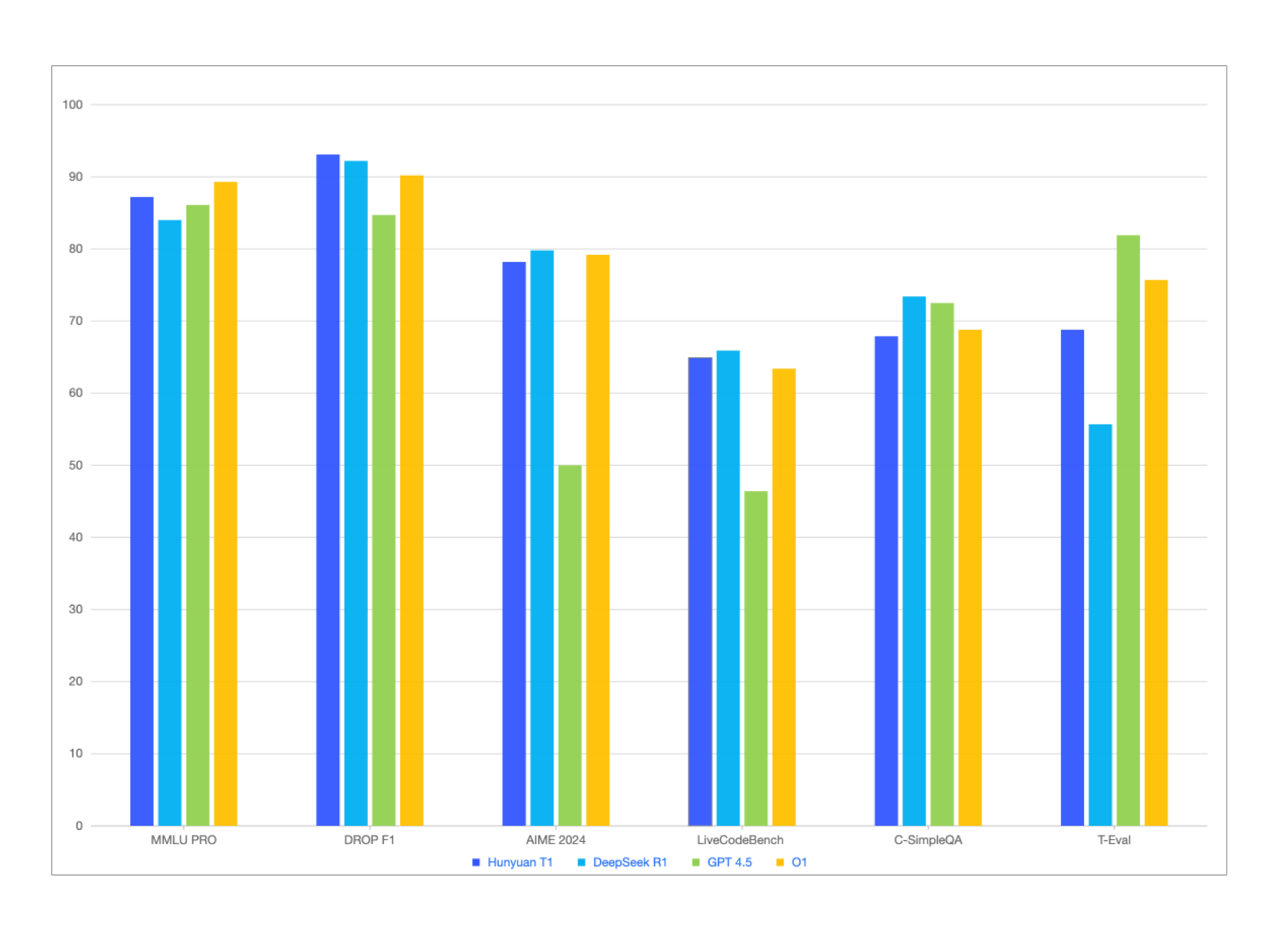
특히, TurboS의 장점인 긴 텍스트 처리 능력과 Mamba 아키텍처의 효율적인 긴 시퀀스 처리 능력을 결합하여, 긴 텍스트 추론 시 문맥 손실과 장거리 정보 의존성 문제를 효과적으로 해결합니다. 또한, 동일한 배포 조건에서 디코딩 속도가 2배 빨라졌습니다. 이러한 특성은 경쟁 모델인 DeepSeek-R1과 비교할 때도 우수한 성능을 나타냅니다.
Hunyuan-T1의 주요 특징
-
강화 학습 기반 사후 학습: 모델의 추론 능력을 향상시키고 인간의 선호도에 맞게 최적화하기 위해 전체 연산력의 96.7%를 RL 학습에 투자하였습니다.
-
광범위한 데이터셋 활용: 수학, 논리 추론, 과학, 코딩 등 다양한 분야의 데이터를 수집하여 모델의 다양한 추론 작업에 대한 우수한 성능을 보장합니다.
-
커리큘럼 학습 접근법: 데이터의 난이도를 단계적으로 증가시키고 모델의 컨텍스트 길이를 확장하여, 모델이 추론 능력을 향상시키면서도 토큰을 효율적으로 사용하는 방법을 학습하도록 했습니다.
-
강화 학습 전략 채택: 데이터 재생 및 주기적인 정책 재설정과 같은 클래식한 강화 학습 전략을 참고하여, 모델 훈련의 장기적인 안정성을 50% 이상 향상시켰습니다.
 Hunyuan-T1 출시 블로그
Hunyuan-T1 출시 블로그
https://llm.hunyuan.tencent.com/#/blog/hy-t1?lang=en
 Hunyuan-T1 사용 데모 (Web Chat)
Hunyuan-T1 사용 데모 (Web Chat)
https://llm.hunyuan.tencent.com/#/chat/hy-t1
Hunyuan-T1 사용 데모 ( Hugging Face Space)
Hugging Face Space)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()