- 이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요!

- 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다!

HyperRouter: HyperNetwork를 통한 효율적인 학습 및 추론을 위한 희소 전문가 혼합 모델(Towards Efficient Training and Inference of Sparse Mixture of Experts via HyperNetwork)
개요
-
최근 Transformer 모델과 그 변형들이 자연어 처리, 컴퓨터 비전, 강화 학습 등 다양한 분야에서 큰 성공을 거두고 있습니다. 이러한 모델들의 규모를 키우는 것이 주요한 발전 방향으로 자리 잡았지만, 이는 높은 계산 비용을 요구합니다.
-
Sparse Mixture-of-Experts (SMoE) 방식은 효율성과 성능 모두를 개선하고 있지만, 모든 전문가 네트워크가 유사한 표현을 학습하게 되는 경우가 있습니다. 이러한 경우 전체적인 모델의 효율성이 제한되는 '표현 붕괴'라는 문제가 발생합니다.
-
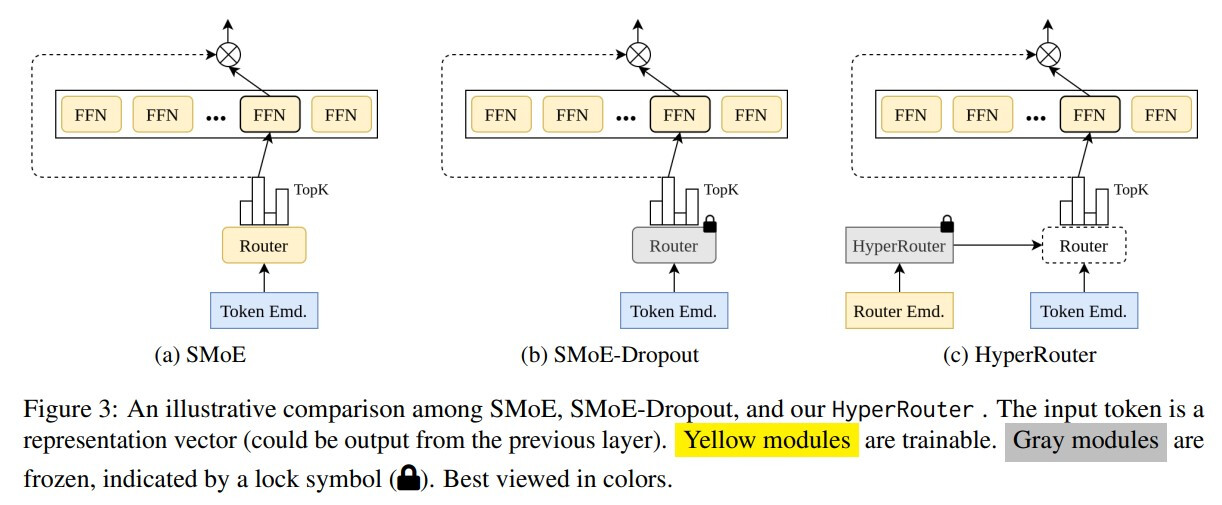
HyperRouter는 SMoE 접근 방식을 사용하면서 라우터의 매개변수를 동적으로 생성하는 방식을 취하고 있습니다. 이는 라우팅 정책을 효율적으로 개선하여 다양한 작업에서 기존 방법보다 개선된 성능을 보입니다.
HyperRouter 소개 및 특장점
-
기존의 SMoE(Sparse Mixture-of-Experts) 방법은 토큰을 전문가 네트워크 중 하나 이상으로 라우팅하는 라우터를 사용합니다. 이 방식은 학습 및 평가 과정에서 상당한 리소스를 요구하며, 고정된 라우터 사용으로 인해 모델의 표현 능력이 제한될 수 있습니다.
-
HyperRouter는 고정된 HyperNetwork와 학습 가능한 라우터 임베딩을 함께 사용하여 라우터의 매개변수를 동적으로 생성합니다. 이를 통해 학습 과정에서 라우팅 정책을 개선하고 표현 붕괴 문제를 완화하는 것을 목표로 합니다.
-
HyperRouter는 학습 과정에서 활성화된 전문가 네트워크의 수를 점차적으로 증가함으로써 효율성을 향상시키는 방법을 사용합니다. 이렇게 하면 기존 SMoE 라우팅 전략과 비교하여 더 나은 성능과 효율성을 제공하며, 같은 수의 전문가를 사용하는 경우에도 더 나은 성능을 보입니다.
HyperRouter의 동작 원리 및 구조
-
SMoE(Sparse Mixture-of-Experts) 학습 시에 라우터 R(·) 와 N개의 전문가 네트워크 {E_i(·)}N_i=1 를 사용합니다. HyperRouter는 이러한 구조에 하이퍼네트워크 H(·) 를 추가하여 라우터의 매개변수를 생성합니다.
-
이 과정에서 HyperNetwork는 고정되어 있으며, 라우터 임베딩은 학습 가능합니다. 이를 통해 효율적인 훈련과 추론이 가능합니다.
실험 및 결과
-
다양한 NLP 작업에서 HyperRouter의 우수성을 입증하기 위해 광범위한 실험을 실시했습니다. 이러한 실험은 HyperRouter가 기존의 SMoE 라우팅 전략보다 우수한 성능과 효율성을 제공한다는 것을 보여줍니다.
-
하지만 논문에서 제공하는 실험은 중간 규모의 데이터셋과 작은 TransformerXL 모델로 제한되어 있으며, 더 큰 모델과 데이터셋에서의 추가적인 실증 평가가 필요합니다.
결론
-
HyperRouter는 SMoE의 두 극단 사이에서 균형을 이루는 새로운 접근 방법을 제시하고 있습니다. 이를 통해 라우팅 정책을 개선하고 기존 SMoE 훈련의 표현 붕괴 문제를 완화할 수 있을 것으로 기대합니다. 또한, 전처리 및 미세 조정 작업에서 기존 전략보다 효율적이고 효과적인 훈련 및 추론을 가능하게 합니다.
-
이 연구는 대규모 언어 모델의 효율적인 훈련과 추론에 중요한 기여를 하며, 라우팅 전략의 발전을 이끌 것으로 기대합니다.
더 읽어보기
논문 (OpenReview)
GitHub 저장소
https://github.com/giangdip2410/hyperrouter