
jina-embeddings-v3 모델 소개
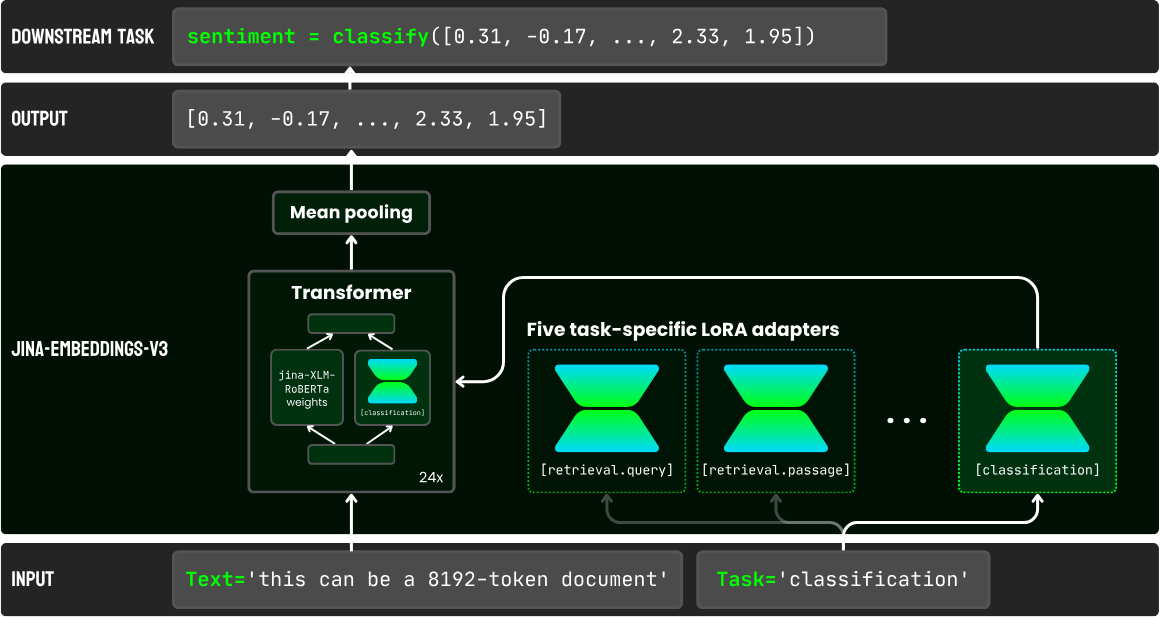
jina-embeddings-v3는 Jina AI가 개발한 다국어 및 다중 작업 텍스트 임베딩 모델로, 다양한 자연어 처리(NLP) 애플리케이션에 적합합니다. 이 모델은 Jina-XLM-RoBERTa 아키텍처를 기반으로 하며, **Rotary Position Embeddings (RoPE)**를 통해 최대 8192 토큰의 긴 입력 시퀀스를 처리할 수 있습니다. 또한, LoRA 어댑터를 통해 작업별 임베딩 생성을 지원합니다.
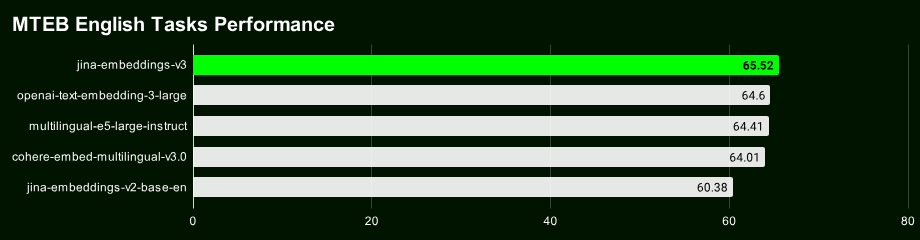
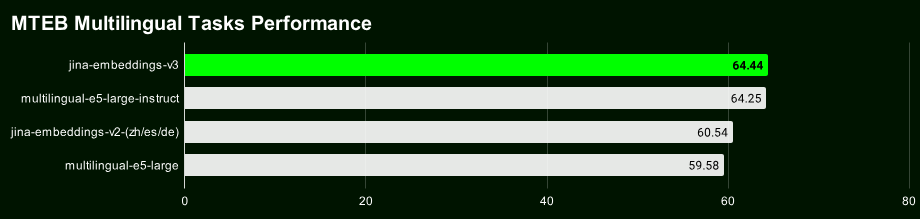
jina-embeddings-v3 모델을 사용하려면 Jina 임베딩 API를 사용하거나 Transformers 패키지를 통해 직접 통합할 수 있습니다. 이번에 Jina AI에서 공개한 임베딩 모델은 100개 언어를 지원하지만, 아랍어, 중국어, 영어, 프랑스어, 독일어, 한국어, 러시아어, 스페인어 등의 30개 언어에 특히 최적화되어 있습니다.
| Feature | Description |
|---|---|
| Base | jina-XLM-RoBERTa |
| Parameters Base | 559M |
| Parameters w/ LoRA | 572M |
| Max input tokens | 8192 |
| Max output dimensions | 1024 |
| Layers | 24 |
| Vocabulary | 250K |
| Supported languages | 89 |
| Attention | FlashAttention2, also works w/o |
| Pooling | Mean pooling |
jina-embeddings-v3 모델의 주요 기능은 다음과 같습니다:
- 확장된 시퀀스 길이: RoPE를 사용하여 최대 8192 토큰의 시퀀스를 지원합니다.
- 작업별 임베딩:
task인자를 통해 다양한 작업에 맞게 임베딩을 커스터마이징할 수 있습니다:retrieval.query: 비대칭 검색 작업에서 쿼리 임베딩에 사용.retrieval.passage: 비대칭 검색 작업에서 패시지 임베딩에 사용.separation: 클러스터링 및 재순위 매기기 작업에 사용.classification: 분류 작업에 사용.text-matching: 두 텍스트 간 유사성을 측정하는 작업(예: STS 또는 대칭 검색 작업)에 사용.
- Matryoshka 임베딩: 32에서 1024 차원까지의 유연한 임베딩 크기를 제공하며, 애플리케이션 요구에 맞게 조정할 수 있습니다.
사용법 및 Mean Pooling
이 모델을 효과적으로 사용하려면 mean pooling을 사용하는 것이 권장됩니다. 이는 문장 또는 문단 수준에서 토큰 임베딩의 평균을 내는 방식으로, 높은 품질의 문장 임베딩을 제공합니다:
Mean Pooling 코드 예시:
import torch
from transformers import AutoTokenizer, AutoModel
# 토크나이저 및 모델 초기화
tokenizer = AutoTokenizer.from_pretrained("jinaai/jina-embeddings-v3")
model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
# 입력 문장
sentences = ["How is the weather today?", "What is the current weather like today?"]
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt")
# Mean pooling 및 정규화 수행
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input["attention_mask"])
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
Ampere, Ada, 또는 Hopper와 같은 더 큰 GPU 모델을 사용하려면 FlashAttention-2와 같은 추가 패키지를 설치(예. pip install flash-attn --no-build-isolation)하여 성능을 향상시킬 수 있습니다.
또한, ONNX를 사용하여 효율적인 추론을 할 수 있습니다. 아래는 ONNX 통합을 위한 코드 예시입니다:
import onnxruntime
from transformers import AutoTokenizer
# 토크나이저 및 모델 구성 불러오기
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v3')
input_text = tokenizer('sample text', return_tensors='np')
# ONNX 세션 및 입력 준비
session = onnxruntime.InferenceSession('jina-embeddings-v3/onnx/model.onnx')
outputs = session.run(None, {'input_ids': input_text['input_ids']})
또한, 벡터 데이터베이스인 Qdrant, Milvus, Haystack과 긴밀히 협력하여 jina-embeddings-v3의 통합을 완료했습니다. Jina AI Search Foundation API를 통한 사용법을 비롯하여 다양한 Vector DB와의 사용법은 다음 URL들을 참고해주세요:
https://docs.pinecone.io/models/jina-embeddings-v3
라이선스
jina-embeedings-v3 모델은 CC BY-NC 4.0 라이선스 하에 제공되며, AWS 및 Azure와 같은 플랫폼에서 사용 가능합니다. 상업적 사용을 원할 경우 Jina AI에 문의하세요.
 JINA AI의 소개 글
JINA AI의 소개 글
jina-embeddings-v3 기술 문서
 jina-embeddings-v3 모델 가중치
jina-embeddings-v3 모델 가중치
https://huggingface.co/jinaai/jina-embeddings-v3
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()