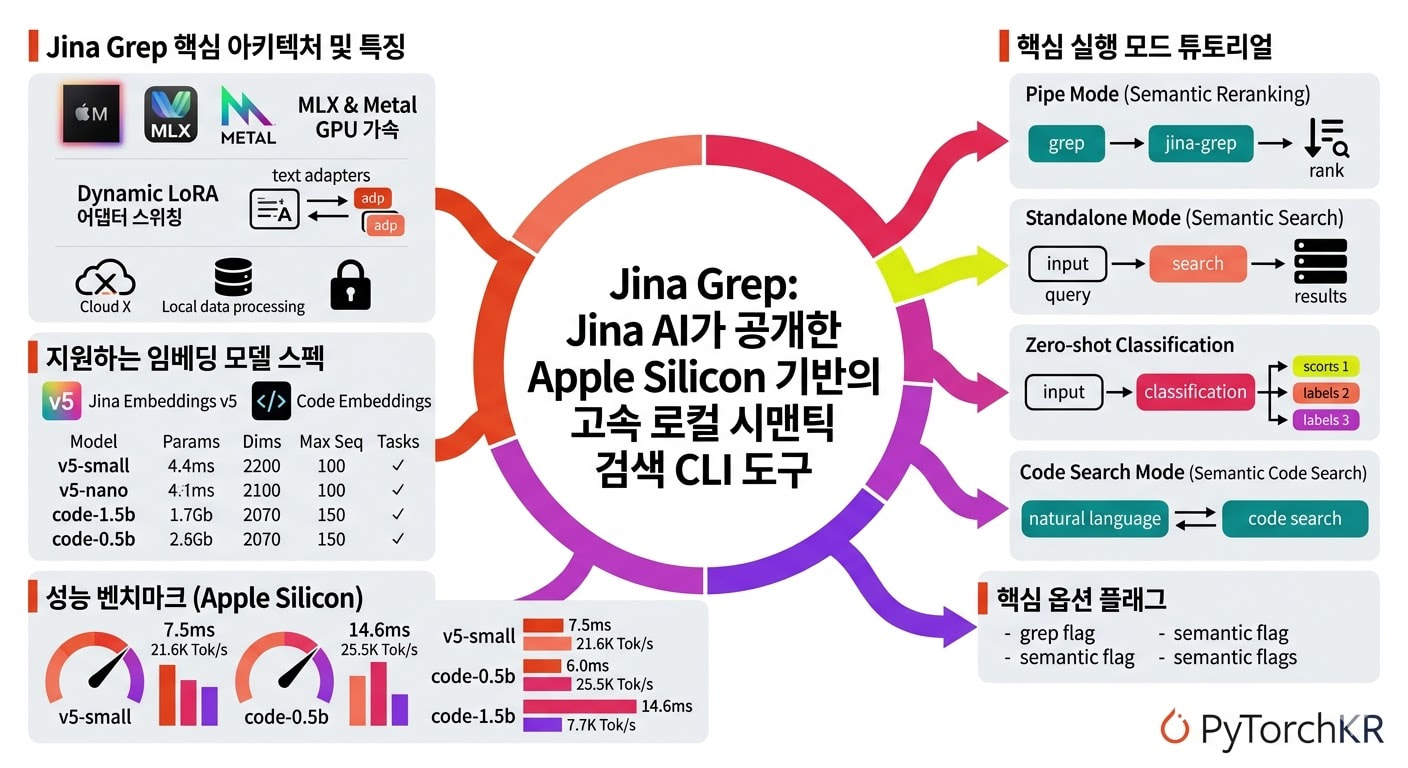
jina-grep 소개
최근 소프트웨어 개발 환경에서는 단순한 문자열 일치를 넘어 코드의 의미(Semantics)를 파악하여 검색하는 시맨틱 검색의 중요성이 점차 커지고 있습니다. 기존의 터미널 명령어인 grep은 정규 표현식이나 정확한 단어 일치에 의존해야 했기 때문에, 변수명이나 주석이 다르게 작성되어 있으면 원하는 코드를 찾기 어려웠습니다. 이러한 한계를 극복하기 위해 Jina AI에서 새롭게 공개한 오픈소스 도구가 바로 jina-grep입니다.
jina-grep는 Jina AI의 최신 임베딩 모델인 Jina Embeddings v5를 활용하여 로컬 환경에서 자연어 기반의 의미론적 검색을 수행할 수 있게 해주는 강력한 커맨드라인 인터페이스(CLI) 도구입니다. 개발자는 "데이터베이스 연결 풀링(database connection pooling)"이나 "메모리 누수(memory leak)"와 같은 자연어를 입력하여, 해당 의미나 문맥을 담고 있는 코드 라인이나 텍스트 문서를 정확하게 찾아낼 수 있습니다. 이는 거대한 코드베이스를 탐색하거나 복잡한 디버깅을 수행할 때 작업 효율을 비약적으로 향상시켜 줍니다.
가장 눈에 띄는 기술적 특징은 Apple Silicon 아키텍처에 완벽하게 최적화되어 있다는 점입니다. 무거운 PyTorch 런타임이나 Transformers 라이브러리에 전혀 의존하지 않으며, Apple의 자체 머신러닝 프레임워크인 MLX를 기반으로 순수하게 Metal GPU 위에서 동작합니다.
특히, 텍스트 모델의 경우 단일 베이스 모델을 메모리 상에 올려두고 필요에 따라 동적 LoRA 어댑터 스위칭(Dynamic LoRA adapter switching) 을 수행하여 단 20ms 만에 작업 컨텍스트를 전환하는 놀라운 효율성을 보여줍니다. 클라우드 API를 호출하지 않고 로컬에서 모든 처리가 이루어지므로, 민감한 사내 코드가 외부로 유출될 우려 또한 전혀 없습니다.
Jina Grep vs. 기존 검색 도구 비교
전통적인 grep 명령어는 어휘적(Lexical) 일치에 기반합니다. 예를 들어 터미널에서 grep "error"를 실행하면 정확히 "error"라는 문자열이 포함된 줄만 반환하며, "exception"이나 "failure"라고 적힌 코드는 찾아내지 못합니다.
반면 jina-grep는 의미론적(Semantic) 일치를 수행합니다. "error handling logic"이라는 자연어 문장으로 검색하면, try-except 블록이나 fallback 메커니즘이 구현된 코드를 문맥적으로 이해하여 찾아냅니다. 또한 기존 grep 결과물을 파이프(|)로 받아와 AI 유사도 순으로 재정렬해주는 하이브리드 기능을 제공하므로, 기존의 익숙한 워크플로우를 해치지 않으면서 AI 검색의 장점만을 추가로 취할 수 있습니다.
jina-grep의 주요 특징
지원하는 임베딩 모델 및 세부 스펙
jina-grep는 Jina Embeddings v5 아키텍처 및 코드 전용 모델을 지원합니다. 이 모델들은 MLX 체크포인트 형태로 제공되며 온디맨드(On-demand)로 필요할 때만 로드됩니다.
| Model | Params | Dims | Max Seq | Tasks |
|---|---|---|---|---|
| jina-embeddings-v5-small | 677M | 1024 | 32768 | retrieval, text-matching, clustering, classification |
| jina-embeddings-v5-nano | 239M | 768 | 8192 | retrieval, text-matching, clustering, classification |
| jina-code-embeddings-1.5b | 1.54B | 1536 | 32768 | nl2code, code2code, code2nl, code2completion, qa |
| jina-code-embeddings-0.5b | 0.49B | 896 | 32768 | nl2code, code2code, code2nl, code2completion, qa |
참고: 코드 전용 모델(1.5b, 0.5b)은 동적 어댑터 스위칭 대신 **인스트럭션 프리픽스(Instruction prefixes)**가 포함된 단일 체크포인트를 사용합니다.
두 가지 서버 실행 아키텍처: Serverless vs Persistent
jina-grep는 사용자의 작업 환경과 빈도에 맞춰 두 가지 유연한 실행 방식을 제공합니다:
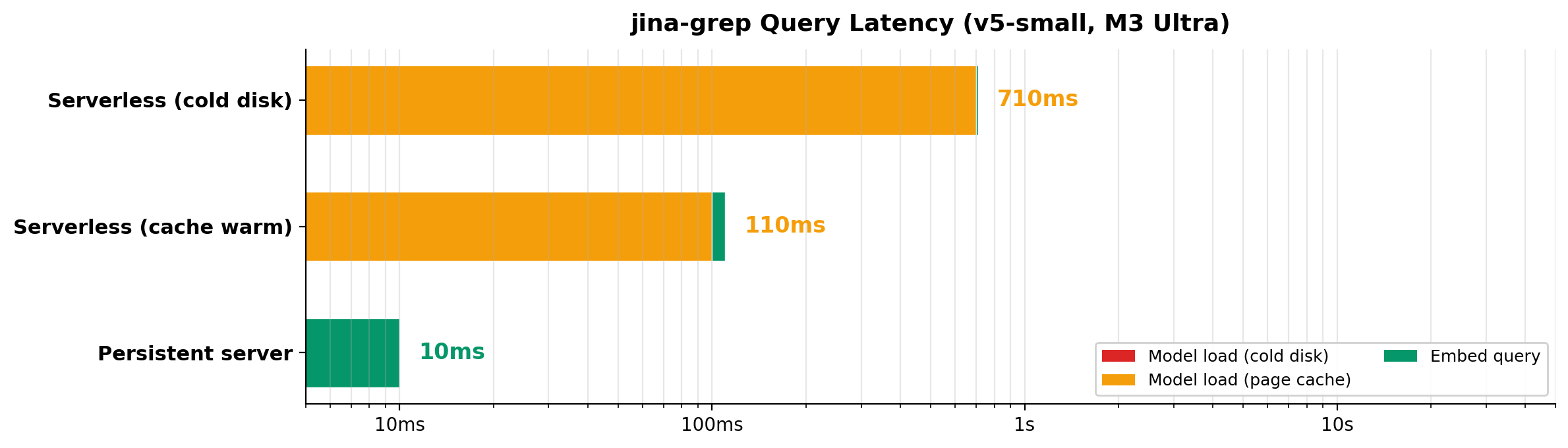
서버리스 모드 (Serverless - 기본값) 는 별도의 백그라운드 서버 프로세스 없이 쿼리를 실행할 때 즉시 모델을 로드하고, 처리 후 바로 종료합니다. MLX가 메모리 매핑(mmap)을 통해 가중치를 로드하므로, macOS는 프로세스가 종료된 후에도 모델 데이터를 페이지 캐시(Page cache)에 유지하여 후속 실행 속도를 높입니다. 간헐적인 검색이나 CI/CD 스크립트 실행에 적합합니다.
영구 서버 모드 (Persistent server) 는 임베딩 모델을 GPU 메모리에 상주시킨 상태로 서버를 유지하여 매 쿼리마다 약 10ms의 초고속 응답 속도를 보장합니다. 대화형 세션이나 많은 양의 배치 워크로드를 처리할 때 이상적입니다. 특히, 사용자가 서버리스 모드로 명령어를 실행하더라도 백그라운드에 영구 서버가 띄워져 있다면, HTTP를 통해 자동으로 이를 감지하고 연결하여 리소스를 낭비하지 않습니다.
서버 모드는 다음과 같이 실행 가능합니다:
jina-grep serve start # 백그라운드에서 영구 서버 시작
jina-grep serve stop # 작업 완료 후 안전한 서버 종료
jina-grep 설치 및 사용법
필요 환경 및 설치 방법
jina-grep 도구는 Python 3.10 이상이 설치된 macOS (Apple Silicon 탑재 기기) 환경에서 동작합니다. 가상 환경을 깨끗하게 관리하기 위해 uv 패키지 매니저 사용이 권장됩니다.
# 가상 환경 생성 및 활성화
uv venv .venv && source .venv/bin/activate
# 저장소의 코드를 로컬 모드로 설치
uv pip install -e .
jina-grep의 4가지 핵심 실행 모드
파이프 모드 (Semantic Reranking)
기존 grep 검색 결과를 파이프라인(|)으로 넘겨받아 의미론적으로 랭킹을 재정렬합니다. 정규식으로 1차 필터링을 한 뒤 AI로 정밀하게 2차 검색을 할 때 유용합니다.
# error가 들어간 줄을 찾은 뒤, 에러 핸들링 로직과 가장 유사한 순으로 재정렬 출력
grep -rn "error" src/ | jina-grep "error handling logic"
독립 실행 모드 (Standalone Search)
grep을 거치지 않고 직접 디렉토리나 파일을 지정하여 즉시 자연어 검색을 수행합니다:
# 현재 디렉토리에서 재귀적(-r)으로 데이터베이스 연결 관련 로직 검색
jina-grep -r "database connection pooling" .
제로샷 분류 모드 (Zero-shot Classification)
-e (또는 -f로 파일 지정) 플래그를 사용하여 여러 개의 레이블(카테고리)을 지정하면, 입력된 텍스트나 코드가 어느 레이블에 가장 적합한지 분류해 줍니다:
# src/ 폴더의 코드를 4가지 레이블 중 하나로 자동 분류
jina-grep -e "database" -e "error handling" -e "data processing" -e "configuration" src/
코드 검색 모드 (Code Search)
--model 옵션을 통해 코드 전용 모델을 불러오고, --task로 코드 기반의 구체적인 작업을 지정할 수 있습니다:
# 자연어를 코드로 검색 (기본 task: nl2code)
jina-grep --model jina-code-embeddings-1.5b "retry with exponential backoff" src/
# 특정 함수와 의미적으로 유사한 코드를 검색 (code2code)
jina-grep --model jina-code-embeddings-0.5b --task code2code "def fetch_data():" src/
jina-grep 사용법: 주요 옵션 플래그 정리
기존 grep 사용자의 편의를 위해 익숙한 플래그와 AI 특화 옵션을 모두 제공합니다:
-
grep호환 플래그:-r,-R(디렉토리 재귀 검색)-l(매칭된 파일명만 출력)-L(매칭되지 않은 파일명 출력)-c(파일별 매칭 횟수 출력)-n(줄 번호 표시, 기본값)-H/--no-filename(파일명 표시 여부 지정)-A,-B,-C(매칭 전/후 컨텍스트 줄 수 지정)
-
jina-grep특화 시맨틱 플래그:--threshold: 코사인 유사도 컷오프 임계값 (예:0.3)--top-k: 한 번에 보여줄 최대 결과 수 지정--model: 사용할 임베딩 모델 강제 지정--task: 수행할 세부 작업 지정 (retrieval,text-matching,nl2code등)
jina-grep의 성능 벤치마크 (Apple Silicon 기준)
PyTorch의 오버헤드를 완전히 걷어내고 MLX와 Metal GPU에 직접 최적화된 결과, 로컬 환경임에도 압도적인 처리 속도를 자랑합니다:
라이선스
jina-grep 프로젝트는 상업적 이용 및 수정이 자유로운 Apache-2.0 License로 공개 및 배포 되고 있습니다.
 Jina AI 공식 홈페이지
Jina AI 공식 홈페이지
 jina-grep 프로젝트 GitHub 저장소
jina-grep 프로젝트 GitHub 저장소
더 읽어보기
-
Apple, macOS 환경에서 Apple Intelligence의 Foundation Model에 접근할 수 있는 Python SDK 공개
-
mlx-vlm: M5와 같은 Apple Silicon에 최적화된 MLX 기반 시각-언어 모델(VLM) 추론 및 파인튜닝 도구
-
Lightning Whisper MLX: Whisper.cpp보다 10배 빠른 Apple Silicon(M1/M2/M3 등)용 Whisper 구현체
-
CodeRunner: LLM의 코드를 안전하게 로컬에서 처리하는 프로젝트 (feat. Apple Container)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()