
KGGen 소개
KGGen은 일반 텍스트(Plain Text)에서 고품질의 지식 그래프(Knowledge Graph, KG)를 자동으로 추출하기 위해 설계된 최신 오픈소스 프레임워크입니다. 2025년 NeurIPS(Neural Information Processing Systems) 컨퍼런스에서 스탠퍼드 대학교(Stanford University)와 토론토 대학교(University of Toronto) 연구진이 발표한 이 도구는 기존 지식 그래프 구축 방식의 한계를 극복하는 데 중점을 두고 있습니다.
최근 LLM(대규모 언어 모델)을 활용한 RAG(검색 증강 생성) 시스템이 보편화되면서, 단순한 텍스트 검색을 넘어 데이터 간의 관계를 구조화한 지식 그래프의 중요성이 급격히 대두되고 있습니다. 하지만 위키데이터(Wikidata)와 같이 사람이 직접 구축한 고품질 지식 그래프는 그 수가 매우 제한적이며, 특정 도메인에 맞는 그래프를 처음부터 구축하려면 막대한 비용이 소요됩니다. 반면, OpenIE와 같은 기존의 자동화된 추출 도구들은 텍스트를 그대로 트리플(Triple) 형태로 변환하는 데 그쳐, 노드 간의 연결이 끊어지거나 의미 없이 중복된 정보가 양산되는 희소성(Sparsity) 문제를 안고 있었습니다.
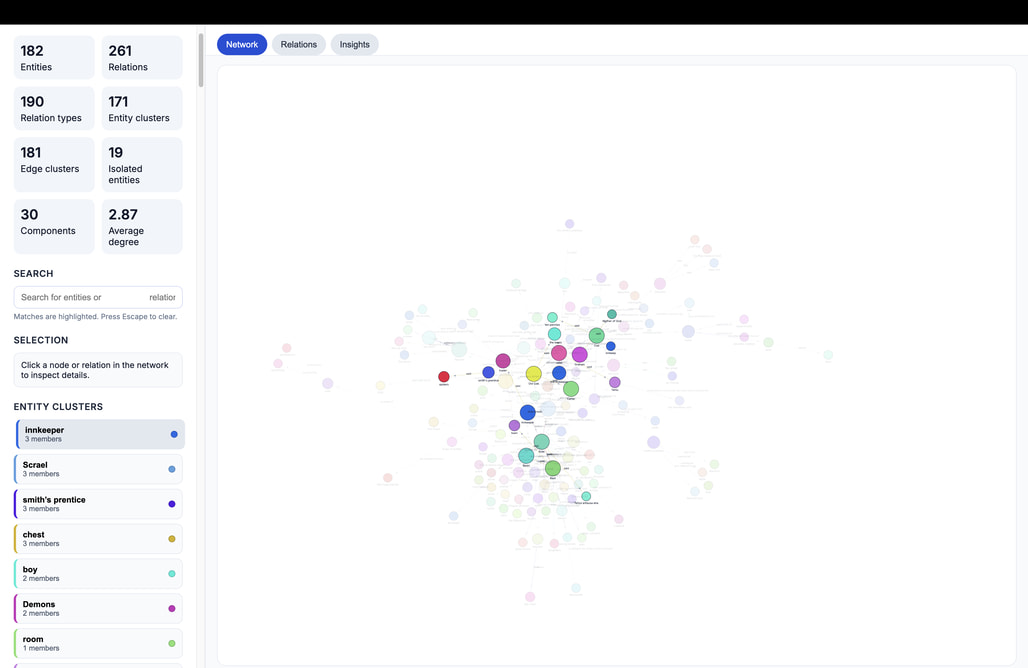
KGGen은 이러한 문제를 해결하기 위해 LLM 기반의 추출과 사후 클러스터링을 통한 엔티티 해결(Entity Resolution) 기술을 결합했습니다. 텍스트에서 추출된 수많은 엔티티와 관계들을 의미적으로 분석하여, 같은 대상을 지칭하는 노드들을 하나로 통합함으로써 밀도 높고 유용한 지식 그래프를 생성합니다.
또한, 이 프로젝트는 LiteLLM을 통해 다양한 모델(OpenAI, Gemini 등)을 지원하고 DSPy를 활용하여 구조화된 출력을 보장함으로써 개발자가 쉽게 통합하여 사용할 수 있도록 설계되었습니다. 이를 통해 "Winter Olympics"와 "Olympic Winter Games"를 동일한 엔티티로 통합하고, 의미가 유사한 관계들을 하나로 묶어 밀도 높고 연결성이 뛰어난 그래프를 생성합니다.
KGGen vs. 기존 기술(GraphRAG, OpenIE) 비교
KGGen 연구진은 KGGen의 성능을 검증하기 위해 대표적인 지식 그래프 추출 도구인 OpenIE 및 Microsoft의 GraphRAG와 심층적인 비교 분석을 수행했습니다.
먼저 KGGen과 OpenIE를 비교하면, OpenIE는 구문 분석(Dependency Parse)에 의존하기 때문에 "it", "they", "are"와 같이 문맥 없는 대명사나 일반 동사가 노드로 생성되는 경우가 많습니다. 이는 그래프의 품질을 떨어뜨리고 유용한 정보를 찾기 어렵게 만듭니다. 반면 KGGen은 의미 기반의 통합을 통해 명확한 엔티티만을 남깁니다.
또한, Microsoft의 GraphRAG와 비교해보면, GraphRAG는 문서들을 커뮤니티(Community)로 묶고 이를 요약(Summary)하는 방식에 강점이 있지만, 개별 관계(Relation)를 세밀하게 재사용하거나 통합하는 데에는 약점을 보였습니다.
실험 결과, 텍스트 데이터가 늘어날수록 KGGen은 관계 타입(Relation Type) 하나를 평균 10회 이상 재사용하며 구조화된 지식을 형성했지만, GraphRAG는 관계 타입이 데이터 양에 비례하여 계속 늘어나며 그래프가 희소(Sparse)해지는 경향을 보였습니다.
| 특징 | KGGen | Microsoft GraphRAG | OpenIE |
|---|---|---|---|
| 핵심 접근법 | LLM 추출 + 엔티티 해결(Resolution) | LLM 추출 + 커뮤니티 요약(Summary) | 구문 분석(Dependency Parse) |
| 그래프 품질 | 동의어 통합으로 고밀도 유지 | 관계 유형 중복으로 인해 희소(Sparse) | 무의미한 노드 다수, 연결성 부족 |
| 처리 속도(1M 자) | 551초 (추출+해결 포함) | 2,319초 (추출 단계만) | 빠르지만 품질 낮음 |
| 비용 효율성 | 관계 재사용률 높음 (일반화됨) | 관계 재사용률 낮음 (단순 나열) | - |
KGGen 방법론: 추출-집계-해결의 3단계 파이프라인
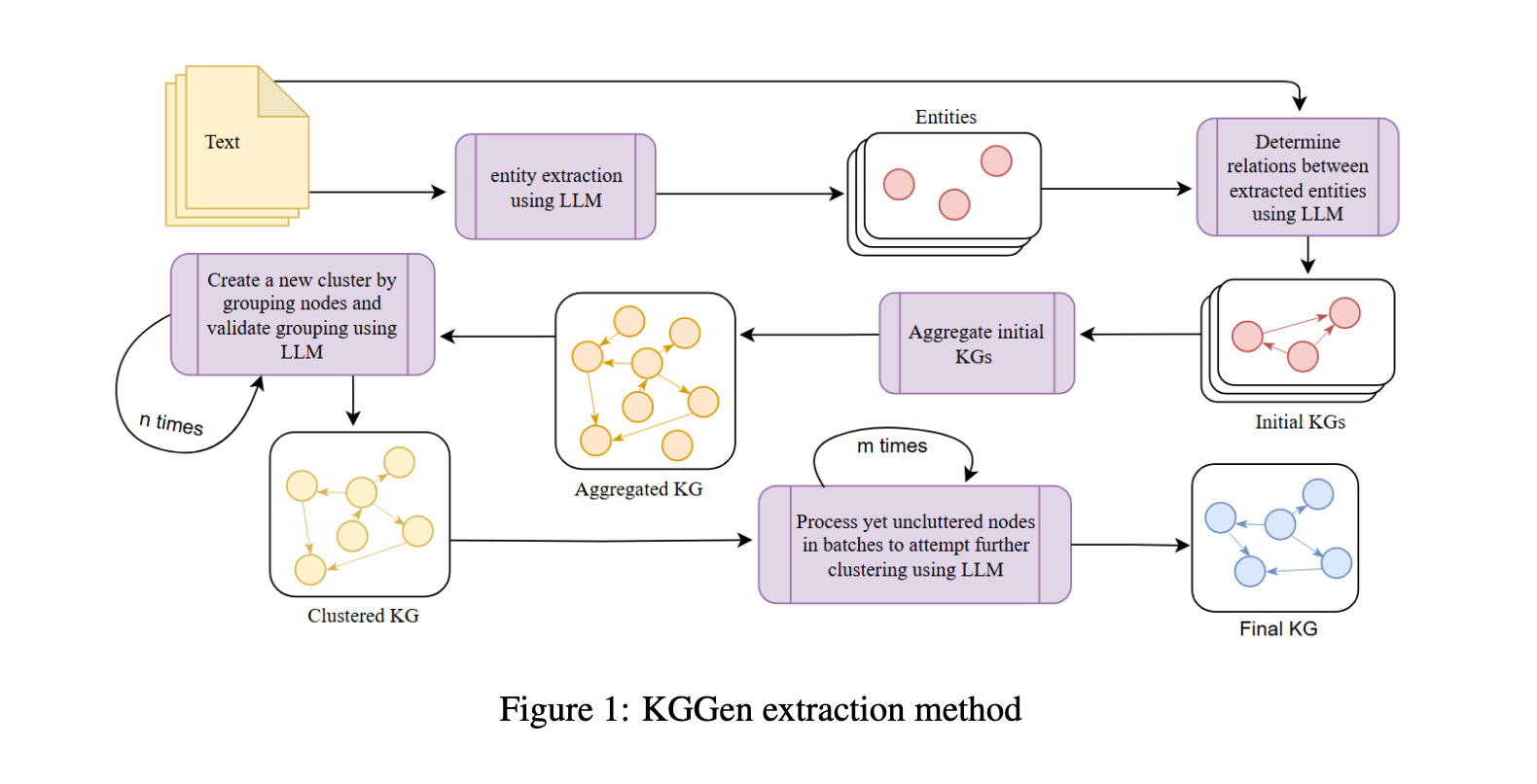
KGGen의 동작 과정은 크게 추출(Extraction), 집계(Aggregation), 해결(Resolution)의 3단계 파이프라인으로 구성되며, 특히 '해결' 단계가 이 프레임워크의 핵심 차별점입니다.
1단계: 엔티티 및 관계 추출 (Entity and Relation Extraction)
첫 번째 단계는 비구조화된 텍스트 원본을 읽고 초기 형태의 지식 그래프를 생성하는 과정입니다. 연구진은 이 과정에서 구글의 Gemini 2.0 Flash 와 같은 LLM을 활용하여 구조화된 출력을 얻어냈습니다9. 단순한 프롬프팅 대신 DSPy 프레임워크의 시그니처(Signature) 기능을 활용하여 LLM이 명확한 데이터 구조를 반환하도록 제어합니다.
추출 과정은 정확성을 높이기 위해 크게 두 단계로 세분화됩니다. 먼저 LLM이 텍스트 전체를 읽고 핵심 엔티티(Entity) 목록을 추출합니다. 그 다음, 원본 텍스트와 앞서 추출된 엔티티 목록을 다시 LLM에 입력하여, 해당 엔티티들 사이의 주어-서술어-목적어(Subject-Predicate-Object) 관계를 추출합니다. 이렇게 엔티티를 먼저 확정한 뒤 관계를 연결하는 방식은 LLM이 존재하지 않는 엔티티를 환각(Hallucination)으로 생성하거나 관계를 잘못 연결하는 오류를 줄여줍니다.
2단계: 집계 (Aggregation)
개별 텍스트 청크(Chunk)에서 추출된 수많은 미니 그래프들을 하나의 거대한 그래프로 통합하는 단계입니다. 이 과정에서는 모든 텍스트를 소문자로 변환하는 등의 기본적인 정규화(Normalization)를 수행하여 텍스트가 완전히 동일한 엔티티와 엣지를 1차적으로 병합합니다. 이 단계는 LLM을 사용하지 않고 알고리즘적으로 수행되어 중복을 줄이는 기초 작업을 담당합니다.
3단계: 엔티티 및 엣지 해결 (Entity and Edge Resolution)
KGGen의 가장 핵심적인 혁신은 바로 이 '해결(Resolution)' 단계에 있습니다. 추출된 그래프는 여전히 "소설가"와 "작가", 또는 "미국"과 "USA"처럼 표기는 다르지만 의미가 같은 노드들로 인해 파편화되어 있을 가능성이 높습니다. KGGen은 이를 해결하기 위해 임베딩 기반 클러스터링과 LLM 기반의 의미론적 중복 제거를 결합한 하이브리드 방식을 사용합니다:
-
임베딩 및 클러스터링 (Semantic Clustering): 그래프 내의 모든 노드와 엣지를 S-BERT(Sentence-BERT) 모델을 사용하여 벡터로 변환한 뒤, K-Means 알고리즘을 통해 의미적으로 유사한 항목들을 클러스터링합니다. 각 클러스터 내에서는 다시 BM25와 시멘틱 검색을 결합하여 가장 유사한 상위 k 개(논문에서는 16개)의 아이템을 선별합니다.
-
LLM 기반 중복 제거 (De-duplication): 각 클러스터 내에서 가장 유사한 항목들을 후보군으로 선별하여 LLM에게 "이들이 문법적 변형이나 약어 등을 포함하여 의미상 동일한 대상인가?"라고 질의합니다. 만약 LLM이 중복이라고 판단하면, 위키데이터의 '별칭(Alias)' 시스템처럼 이들을 가장 잘 대표하는 정규형(Canonical Representative) 하나로 통합합니다. 예를 들어, "Olympic Winter Games", "Winter Olympics", "winter Olympic games"라는 세 개의 노드가 있다면 이를 **"Winter Olympics"**라는 하나의 노드로 합칩니다.
-
반복 수행 (Iterative Process): 위 과정들을 반복적으로 수행하며 그래프의 중복을 최소화하고 연결성을 극대화합니다.
KGGen 성능 평가: MINE (Measure of Information in Nodes and Edges) 벤치마크
기존에는 텍스트에서 추출된 지식 그래프의 품질을 평가할 적절한 기준이 없었습니다. 연구진은 이를 해결하기 위해 MINE(Measure of Information in Nodes and Edges) 이라는 새로운 벤치마크를 제안했습니다. MINE은 크게 정보 보존 능력을 평가하는 MINE-1과 실제 RAG 성능을 평가하는 MINE-2로 나뉩니다.
MINE-1: 정보 보존(Knowledge Retention) 능력 평가
MINE-1은 추출기가 짧은 텍스트(약 1페이지 분량)에서 얼마나 많은 정보를 손실 없이 그래프로 변환했는지를 측정합니다.
MINE-1 벤치마크의 데이터셋은 다양한 주제(예술, 과학, 기술, 역사 등)를 다루는 100개의 아티클과, 각 아티클에 포함된 15개의 핵심 사실(Fact)로 구성됩니다. 이를 활용하여 추출된 지식 그래프에서 해당 사실을 복원할 수 있는지 확인합니다. 구체적으로는 사실(Fact)을 임베딩하여 그래프 내에서 가장 유사한 노드와 그 주변 2-hop 이웃 노드들을 검색한 뒤, LLM에게 이 서브그래프만으로 해당 사실을 추론할 수 있는지(1 또는 0) 판단하게 합니다.
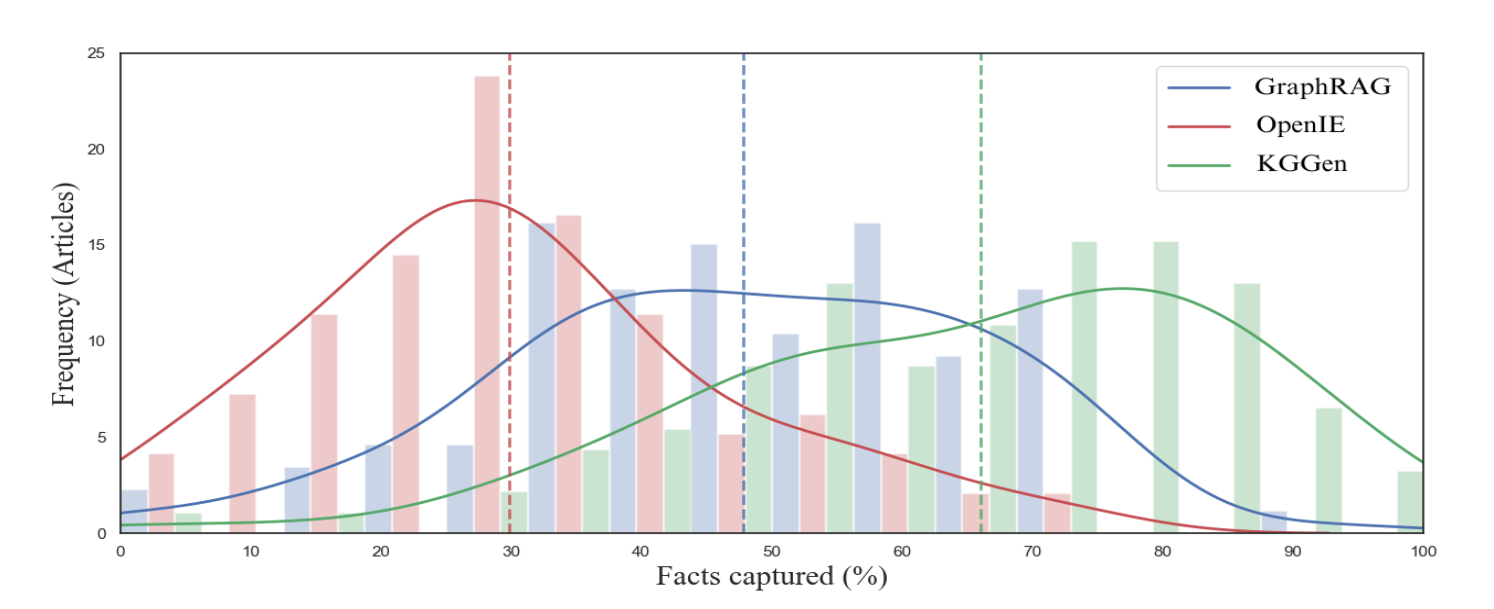
100개의 기사에서 각각 15개의 핵심 사실(Fact)을 정의하고, 생성된 KG만을 이용하여 이 사실들을 다시 추론할 수 있는지 검증했습니다. 평가 결과, KGGen은 평균 66.07%의 정보를 보존하여 GraphRAG(47.80%)와 OpenIE(29.84%)를 압도했습니다.
MINE-2: 대규모 말뭉치에서의 RAG 성능 평가(Downstream RAG Performance)
MINE-2는 WikiQA 데이터셋을 기반으로, 수백만 토큰 규모의 텍스트 데이터베이스에서 생성된 지식 그래프가 실제 질의응답(QA) 시스템에서 얼마나 유용한지를 평가합니다.
MINE-2 벤치마크는 질문과 가장 관련성 높은 트리플들을 검색하여 문맥(Context)으로 제공하고, LLM이 정답을 맞히는지 확인합니다. 이때 검색된 트리플이 원본 텍스트의 어느 청크에서 왔는지 추적할 수 있어야 하므로, 이를 지원하지 않는 OpenIE는 비교에서 제외되었습니다.
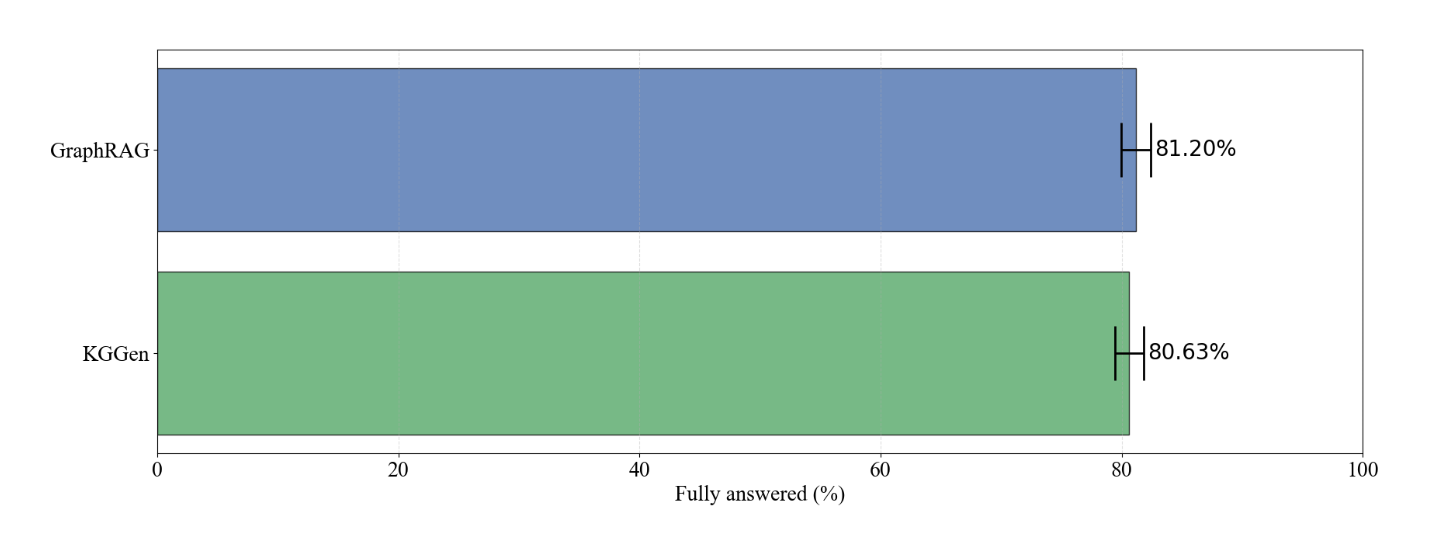
질문에 대한 답변 정확도를 측정한 결과, KGGen은 GraphRAG와 대등한 수준의 높은 검색 정확도를 기록하면서도 훨씬 더 적은 비용과 간결한 그래프 구조로 이를 달성했습니다.
KGGen 설치 및 사용 방법
KGGen은 Python 패키지로 제공되며 pip install kg-gen 명령어로 쉽게 설치할 수 있습니다. LiteLLM을 기반으로 하여 OpenAI의 GPT-4o, Google의 Gemini 등 다양한 모델을 백엔드로 사용할 수 있습니다.
pip install kg-gen
설치 후에는 다음과 같이 Python 코드에서 불러와 사용할 수 있습니다:
from kg_gen import KGGen
# 1. KGGen 초기화 (원하는 모델 지정 가능)
kg = KGGen(
model="openai/gpt-4o", # 또는 "gemini/gemini-1.5-pro" 등
temperature=0.0,
api_key="YOUR_API_KEY"
)
# 2. 텍스트에서 그래프 생성 (클러스터링 옵션 활성화)
text_input = "Apple Inc. was founded by Steve Jobs. The company is headquartered in Cupertino."
graph = kg.generate(
input_data=text_input,
cluster=True # 엔티티 해결(Resolution) 기능 활성화
)
# 3. 대용량 텍스트 처리 (청크 단위 처리)
large_graph = kg.generate(
input_data=large_text_content,
chunk_size=5000, # 5000자 단위로 나누어 처리
cluster=True
)
print(graph)
KGGen은 단일 텍스트 문자열뿐만 아니라, 대화형 메시지 리스트(List[Message]) 형태의 입력도 처리할 수 있어 챗봇 로그 분석 등에도 유용합니다.
 KGGen 논문: Extracting Knowledge Graphs from Plain Text with Language Models
KGGen 논문: Extracting Knowledge Graphs from Plain Text with Language Models
 KGGen 프로젝트 GitHub 저장소
KGGen 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()