
Kimi K2.5 소개: 차세대 에이전트 지능의 서막
Moonshot AI(Kimi Team)가 공개한 Kimi K2.5는 범용 에이전트 지능(General Agentic Intelligence)을 실현하기 위해 설계된 최신 오픈소스 멀티모달 모델입니다. 기존의 대규모 언어 모델(LLM)들이 텍스트 처리에 주력하고 시각적 기능을 부가적인 요소로 취급했던 것과 달리, Kimi K2.5는 설계 초기 단계부터 텍스트와 비전(Vision)이라는 두 가지 모달리티를 완벽하게 통합하고 공동으로 최적화하는 데 주력했습니다. Kimi K2.5 모델은 약 1.5조(1.5T) 토큰에 달하는 방대한 시각-텍스트 혼합 데이터를 통해 사전 학습되었으며, 이를 통해 언어 능력과 시각적 이해 능력이 서로를 강화하는 구조를 갖추고 있습니다.
특히 Kimi K2.5는 단순히 모델의 성능을 높이는 것을 넘어, 복잡한 현실 세계의 문제를 해결하기 위해 에이전트 스웜(Agent Swarm) 이라는 혁신적인 병렬 처리 프레임워크를 도입했습니다. 이는 기존의 순차적인 작업 처리 방식이 가진 한계를 극복하고, 복잡한 과제를 하위 문제로 분해하여 동시에 해결함으로써 추론 속도와 정확도를 획기적으로 향상시킨 기술입니다.
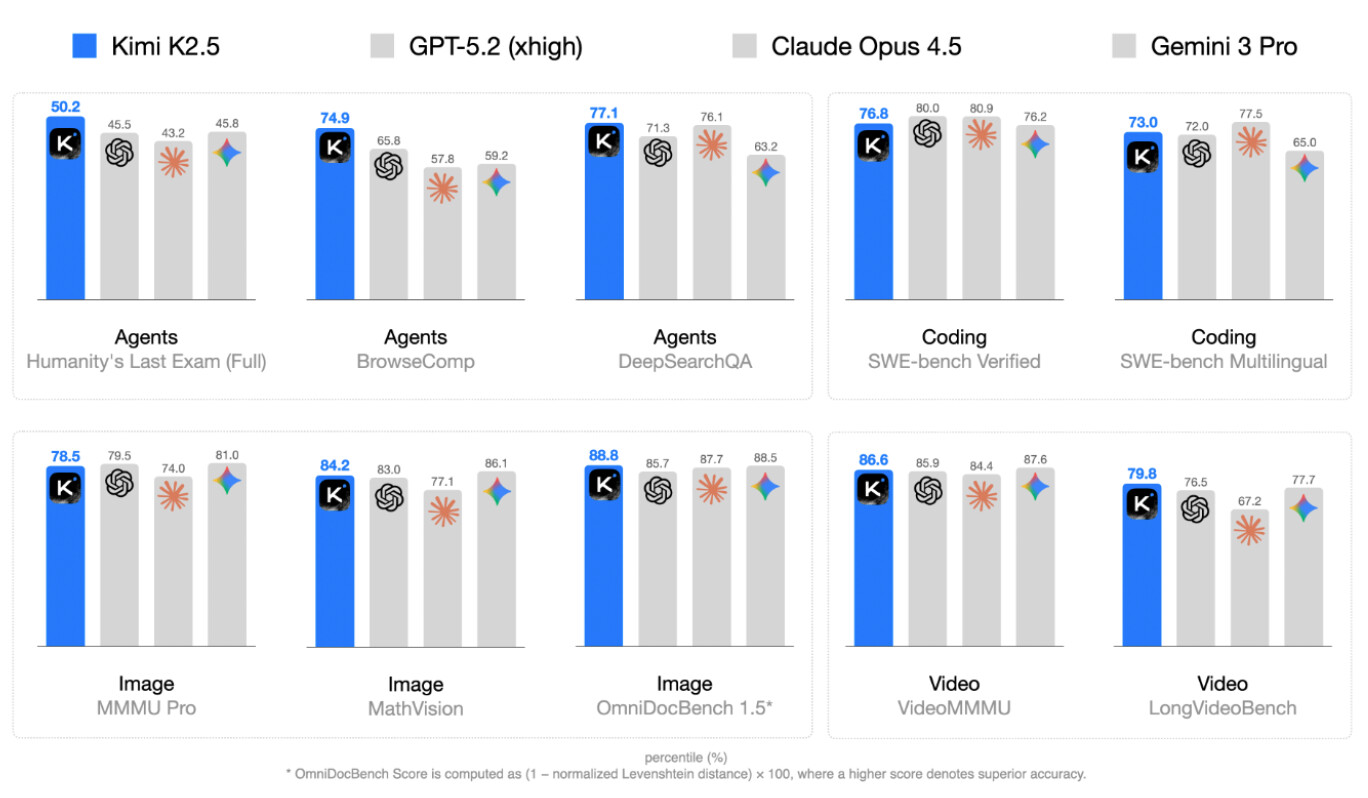
이러한 기술적 진보를 바탕으로 Kimi K2.5는 코딩, 시각적 추론, 긴 비디오 이해 등 다양한 벤치마크에서 GPT-5.2나 Claude Opus 4.5와 같은 최상위 모델들과 대등하거나 더 뛰어난 성능을 입증하고 있습니다.
텍스트와 비전의 공동 최적화 (Joint Optimization of Text and Vision)
Kimi K2.5의 가장 핵심적인 철학은 텍스트와 시각 정보가 서로 충돌하는 것이 아니라 상호 보완적으로 작용해야 한다는 점입니다. 이를 구현하기 위해 연구팀은 기존의 관행을 뒤엎는 새로운 학습 전략과 아키텍처를 적용했습니다.
네이티브 멀티모달 사전 학습 (Native Multimodal Pre-Training)
일반적으로 멀티모달 모델을 학습시킬 때, 텍스트로만 사전 학습된 LLM에 학습 후반부에 시각적 데이터를 대량으로 주입하는 Late Fusion 방식을 사용하곤 합니다. 그러나 Kimi 팀의 연구 결과, 이러한 방식은 갑작스러운 데이터 분포의 변화로 인해 기존에 학습된 텍스트 능력을 일시적으로 저하시키는 '딥-앤-리커버(dip-and-recover)' 현상을 초래한다는 것이 밝혀졌습니다.
이에 따라 Kimi K2.5는 학습 초기 단계부터 텍스트와 시각 토큰을 일정한 비율로 혼합하여 학습시키는 Early Fusion 전략을 채택했습니다. 그 결과, 놀랍게도 시각 데이터의 비율이 50% 이상으로 높을 때보다 약 10% 정도의 적당한 수준일 때, 그리고 이를 초기부터 꾸준히 학습시킬 때, 고정된 토큰 예산 내에서 모델이 두 모달리티 간의 균형 잡힌 표현을 훨씬 더 효과적으로 습득한다는 사실이 확인되었습니다.
MoonViT-3D: 통합된 시공간 인코더
Kimi K2.5는 이미지와 비디오를 구분 없이 처리할 수 있는 MoonViT-3D 인코더를 탑재하고 있습니다. 이 인코더는 SigLIP을 기반으로 초기화되었으며, NaViT의 패치 패킹(Patch n' Pack) 전략을 차용하여 다양한 해상도의 이미지를 원본 그대로 처리합니다. 특히 비디오 처리에 있어서는 시간 차원을 공간 차원과 유사하게 취급하여, 연속된 프레임을 하나의 시공간 볼륨으로 묶어 처리합니다.
여기에 4배의 시간적 압축(Temporal Pooling) 기술을 더해, 동일한 문맥 창(Context Window) 내에서 기존 모델 대비 4배 더 긴 비디오를 처리할 수 있게 되었습니다. 이러한 설계 덕분에 정지 이미지에서 학습한 지식이 동적인 비디오 이해로 자연스럽게 전이되며, 별도의 비디오 전용 모듈 없이도 뛰어난 비디오 이해 성능을 발휘합니다.
사후 학습(Post-Traning)의 혁신: Zero-Vision SFT와 공동 RL
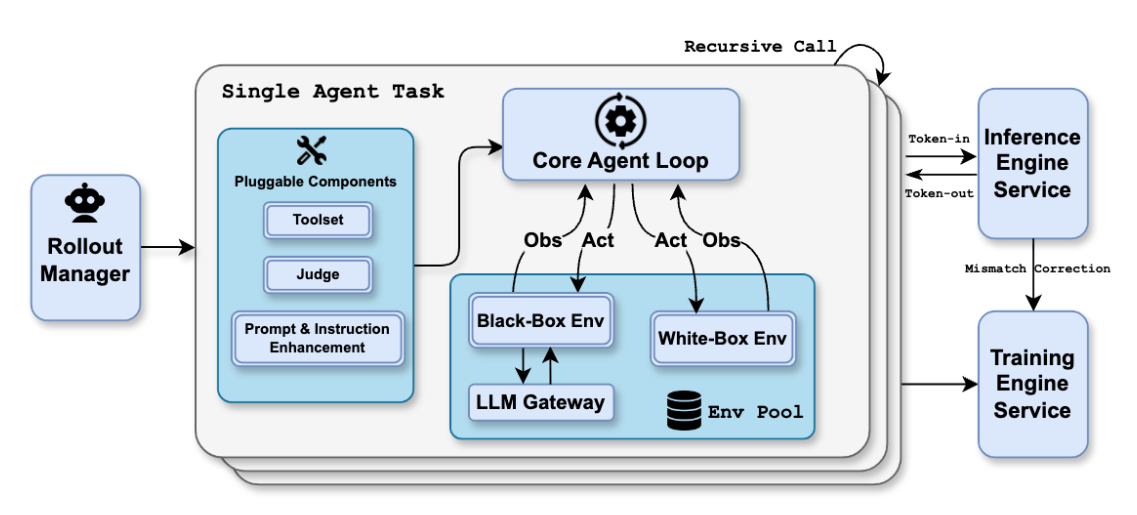
사전 학습(Pre-Training) 이후의 사후 학습(Post-Training) 과정에서도 Kimi K2.5는 독창적인 접근법을 보여줍니다. 일반적으로 시각적 도구 사용 능력을 키우기 위해서는 사람이 레이블링한 시각적 SFT(Supervised Fine-Tuning) 데이터를 사용합니다. 하지만 Kimi 팀은 텍스트 데이터만으로도 시각적 에이전트 능력을 깨울 수 있다는 Zero-Vision SFT 방법론을 제안했습니다.
Zero-Vision SFT (Zero-Vision Supervised Fine-Tuning)
Zero-Vision SFT 기법은 이미지 자르기, 회전, 픽셀 계산 등의 시각적 조작을 실제 이미지가 아닌 텍스트 기반의 프로그래밍 코드(IPython) 연산으로 추상화하여 학습시키는 것입니다. 즉, 모델에게 이미지를 보여주는 대신 "이미지의 특정 좌표를 잘라내라"는 명령을 코드로 수행하는 법을 텍스트로 가르치는 방식입니다.
놀랍게도 이러한 텍스트 기반 훈련만으로도 모델은 실제 시각적 작업에서 객체의 크기를 픽셀 단위로 추정하거나 위치를 찾아내는 능력을 갖추게 되었습니다. 오히려 설익은 시각적 궤적을 포함한 데이터를 사용하는 것보다 텍스트 전용 SFT가 일반화 성능 면에서 더 우수하다는 결과가 도출되었습니다.
공동 멀티모달 강화학습 (Joint Multimodal RL)
Zero-Vision SFT로 기초 체력을 다진 후, 모델은 텍스트와 비전 작업 모두를 아우르는 공동 강화학습(RL) 단계에 진입합니다. 여기서 주목할 점은 시각적 작업에 대한 강화학습이 단순히 시각 능력만 높이는 것이 아니라, 순수 텍스트 추론 능력까지 향상시킨다는 것입니다. 시각적 RL을 통해 모델이 구조화된 정보를 추출하고 불확실성을 줄이는 훈련을 하게 되며, 이것이 MMLU-Pro나 GPQA-Diamond 같은 텍스트 벤치마크 점수의 상승으로 이어졌습니다. 이는 시각 훈련이 텍스트 지능을 부트스트랩(Bootstrap)하고, 텍스트 지능이 다시 시각적 추론을 정교화하는 양방향 강화 효과를 입증합니다.
Agent Swarm: 병렬 에이전트 오케스트레이션
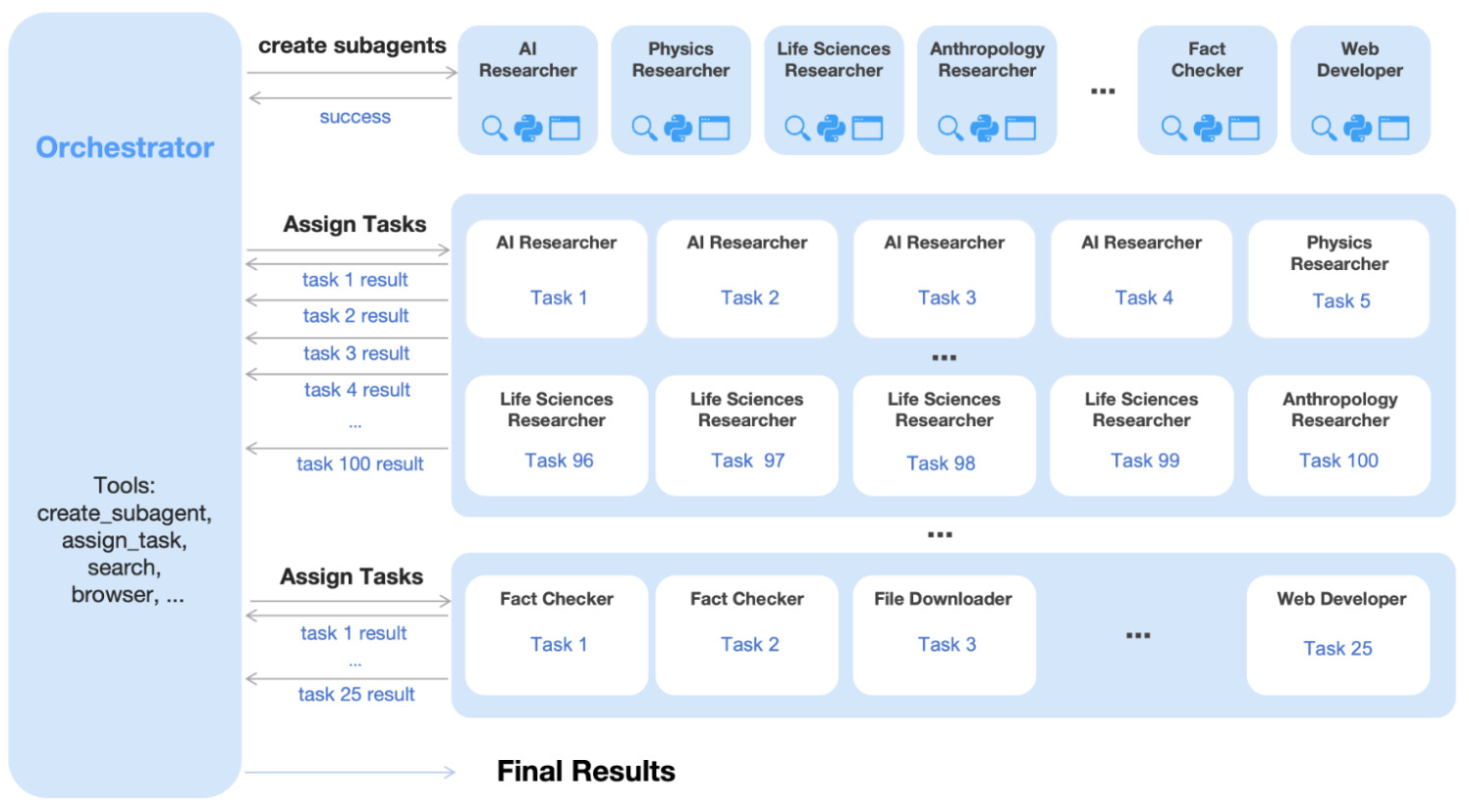
Kimi K2.5 기술의 백미는 단연 Agent Swarm입니다. 기존의 에이전트 시스템은 도구 호출과 추론을 한 단계씩 순차적으로 수행하는 방식을 따랐습니다. 이 방식은 작업이 복잡해질수록 추론 단계가 길어지고, 앞단계의 오류가 누적되며, 전체 문맥이 길어져 연산 비용이 급증하는 치명적인 단점이 있었습니다.
동적 분해와 병렬 실행
Agent Swarm은 이러한 순차적 실행의 병목을 해소하기 위해 오케스트레이터(Orchestrator) 및 하위 에이전트(Sub-agents) 구조를 도입했습니다. 오케스트레이터는 사용자로부터 복잡한 작업을 입력받으면, 이를 즉시 해결하려 하지 않고 여러 개의 작은 하위 문제로 분해합니다. 그리고 각 문제를 해결할 수 있는 전문화된 하위 에이전트를 동적으로 생성(Instantiate)하여 작업을 병렬로 할당합니다.
예를 들어, 24시간 분량의 게임 플레이 영상을 분석해야 한다면, 오케스트레이터는 32개의 하위 에이전트를 생성하여 각각에게 1시간씩의 영상을 분석하게 시킵니다.
PARL (Parallel-Agent Reinforcement Learning)
이러한 병렬 구조를 효과적으로 학습시키기 위해 PARL이라는 새로운 강화학습 패러다임을 적용했습니다. PARL에서는 하위 에이전트들을 고정(Freeze)된 상태로 두고, 오케스트레이터만 학습시킵니다. 이는 다중 에이전트 학습에서 흔히 발생하는 신용 할당(Credit Assignment) 문제, 즉 결과가 잘못되었을 때 누구의 탓인지 모호해지는 문제를 해결하기 위함입니다. 오케스트레이터는 전체 작업의 성공 여부뿐만 아니라, 얼마나 효과적으로 병렬화를 수행했는지(Critical Steps 단축 여부)에 따라 보상을 받습니다.
능동적 문맥 관리 (Proactive Context Management)
Agent Swarm은 긴 문맥을 처리하는 데 있어서도 혁신적입니다. 기존 모델들은 문맥 창이 꽉 차면 과거 정보를 단순히 잘라내거나(Truncation) 요약하는 수동적인 방식을 사용했습니다. 반면 Agent Swarm은 작업을 하위 에이전트에게 위임함으로써 메인 문맥을 깨끗하게 유지합니다. 하위 에이전트는 자신만의 독립적인 문맥(Working Memory) 안에서 복잡한 추론을 수행하고, 최종적으로 정제된 결과만을 오케스트레이터에게 반환합니다.
이를 통해 전체 시스템은 정보를 잃지 않으면서도 매우 긴 호흡의 작업을 효율적으로 처리할 수 있게 됩니다. 실제로 'Black Myth: Wukong' 게임의 24시간 플레이 영상을 분석하는 데 있어, Agent Swarm은 40GB에 달하는 데이터를 병렬로 처리하여 타임라인과 하이라이트 클립이 포함된 웹페이지를 성공적으로 생성해냈습니다.
학습 인프라와 효율성
Kimi K2.5의 학습에는 대규모 인프라와 효율적인 최적화 기술이 뒷받침되었습니다. 특히 멀티모달 데이터 학습 시 이미지 해상도와 개수의 차이로 인해 발생하는 GPU 간 연산 불균형 문제를 해결하기 위해 DEP(Decoupled Encoder Process) 기법을 도입했습니다. DEP는 비전 인코더의 연산과 메인 LLM 백본의 학습 과정을 분리하여, 비전 데이터를 처리할 때 모든 GPU에 부하를 균등하게 재분배합니다. 이를 통해 텍스트 전용 학습 대비 90% 수준의 높은 학습 효율성을 달성했습니다.
또한, 추론 시 토큰 사용량을 최적화하기 위해 Toggle이라는 학습 휴리스틱을 사용했습니다. 이는 토큰 예산에 제약을 두는 단계와 제약을 두지 않는 단계를 번갈아 가며 학습하는 방식으로, 모델 성능 저하 없이 출력 토큰 양을 25~30% 줄이는 효과를 거두었습니다. 이는 불필요한 생각의 연쇄(CoT, Chain-of-Thought)를 줄이고 핵심적인 추론에 집중하게 만듭니다.
결론 및 성과
Kimi K2.5는 텍스트와 비전의 진정한 통합, 그리고 병렬 에이전트 아키텍처를 통해 범용 AI의 새로운 가능성을 보여주었습니다. 수학 벤치마크인 AIME 2025에서는 96.1%를 기록하며 최고 수준의 성능을 입증했고, 코딩 능력 평가인 SWE-Bench Verified에서도 76.8%로 독보적인 성과를 거두었습니다.
특히, Agent Swarm을 적용한 에이전트 검색 벤치마크(BrowseComp)에서는 단일 에이전트 대비 17.8% 향상된 78.4%의 성능을 기록하며, 복잡한 정보 탐색과 종합 능력이 크게 향상되었음을 증명했습니다. Moonshot AI는 이러한 기술적 성과를 커뮤니티와 공유하기 위해 Kimi K2.5의 모델 체크포인트를 오픈소스로 공개했습니다.
 Kimi K2.5 출시 블로그
Kimi K2.5 출시 블로그
Kimi K2.5 기술 문서 (Technical Report)
 Kimi K2.5 프로젝트 GitHub 저장소
Kimi K2.5 프로젝트 GitHub 저장소
 Kimi K2.5 모델 다운로드
Kimi K2.5 모델 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()