
LangExtract 소개
최근 자연어처리(NLP) 분야에서 가장 주목받는 트렌드는 구조화되지 않은 텍스트에서 유용한 정보를 자동으로 추출하는 기술입니다. 특히 의료, 법률, 금융 등 다양한 산업에서 비정형 텍스트 데이터를 구조화된 형태로 정제하는 작업은 점점 더 중요해지고 있습니다. 이에 대응하기 위해 구글에서는 대규모 언어모델(LLM)의 능력을 활용하여 이 과제를 손쉽게 수행할 수 있도록 도와주는 도구인 LangExtract를 공개했습니다.
LangExtract는 사용자가 직접 정의한 지침(prompt)과 예시(example)를 기반으로, 긴 텍스트 문서에서 원하는 정보를 정확하게 추출하고, 이를 구조화된 형태로 반환하는 Python 기반의 라이브러리입니다. 무엇보다 눈에 띄는 점은, 단순히 모델에 질의하는 수준을 넘어서 정확한 출처 텍스트 위치를 매핑하고, 시각화까지 제공함으로써 출처 기반의 정밀한 추출과 검증을 동시에 만족시킬 수 있다는 것입니다.
또한 LangExtract는 Google의 Gemini 모델 시리즈와 같은 클라우드 기반 LLM은 물론, Ollama 등을 통한 로컬 LLM까지 폭넓게 지원하고 있어 다양한 환경에서 유연하게 사용할 수 있습니다. 사용자는 단 몇 줄의 코드만으로 복잡한 정보 추출 작업을 자동화할 수 있으며, 도메인에 특화된 추출도 가능하도록 설계되어 있습니다.
LangExtract는 단순한 텍스트 분류기나 키워드 추출 도구가 아닙니다. 정교한 프롬프트 설계, 예시 기반 few-shot 학습, 추출 위치 매핑, 대화형 시각화 등 다양한 기능이 포함된 강력한 추출 플랫폼이며, 특히 개발자나 연구자들이 빠르게 시제품을 만들거나 추출 프로토타입을 실험하기에 최적화되어 있습니다.
LangExtract는 일반적인 정보 추출 도구들과 비교했을 때 다음과 같은 차별점을 가집니다:
- spaCy, Stanza 등 전통적인 NLP 파이프라인 도구들은 사전 학습된 모델 기반으로 키워드, 개체명 등을 추출하지만, 문맥 기반의 복잡한 추론이나 사용자가 정의한 지침에 따른 구조화는 어렵습니다.
- LangChain, LlamaIndex 등 LLM 기반 프레임워크는 추론 및 검색 응용에 강점을 보이지만, LangExtract는 출처 기반 정보 추출에 특화되어 있고 시각화 기능까지 내장되어 있습니다.
- LLM API만 직접 사용하는 경우 프롬프트 설계와 예시 구성이 매우 중요하지만 복잡하며 반복 실험이 어렵습니다. LangExtract는 이를 템플릿화하고 추출 구조를 고정함으로써 재현성과 일관성을 보장합니다.
LangExtract의 주요 기능
사용자 정의 추출 프롬프트와 예시 기반 설계
LangExtract는 사용자가 추출하고 싶은 정보를 명확히 설명하는 프롬프트와 몇 개의 고품질 예시 데이터를 통해 모델이 어떤 방식으로 정보를 추출할지 학습합니다. 예를 들어, 셰익스피어의 ‘로미오와 줄리엣’ 텍스트에서 등장인물, 감정, 관계를 추출하고자 할 경우 다음과 같이 정의할 수 있습니다:
prompt = """
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.
"""
Gemini 및 다양한 LLM 지원
기본적으로 gemini-2.5-flash 모델을 추천하며, 복잡한 추론을 위해서는 gemini-2.5-pro 모델도 사용할 수 있습니다. API 키 설정만으로 간단히 사용할 수 있으며, Ollama, OpenAI GPT-4o 등 외부 또는 로컬 모델과도 연동이 가능합니다.
result = lx.extract(
text_or_documents="텍스트 입력 또는 문서 URL",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash"
)
추출된 결과의 시각화
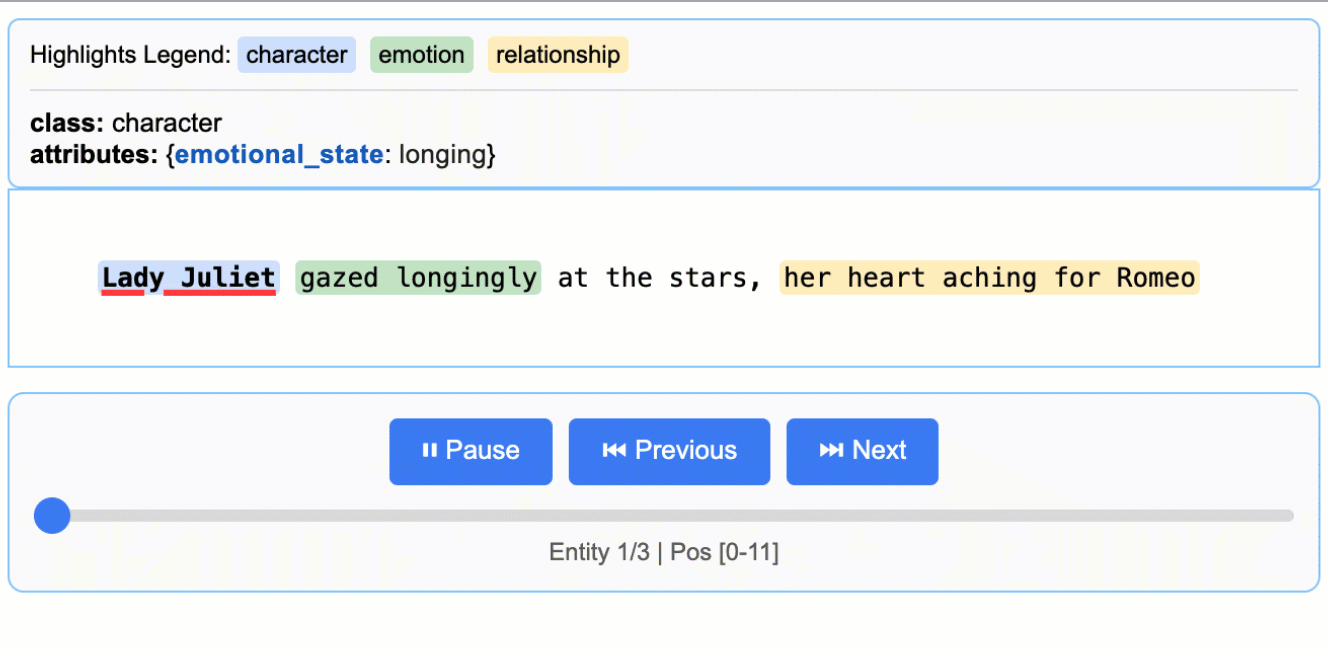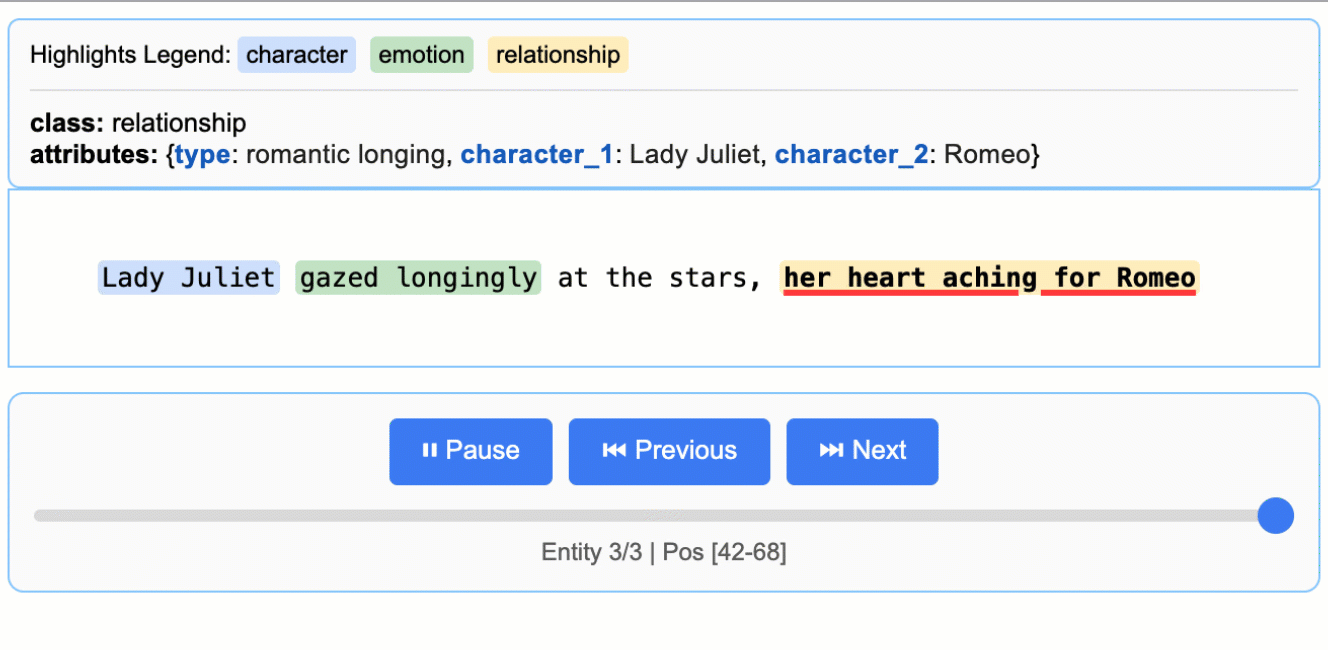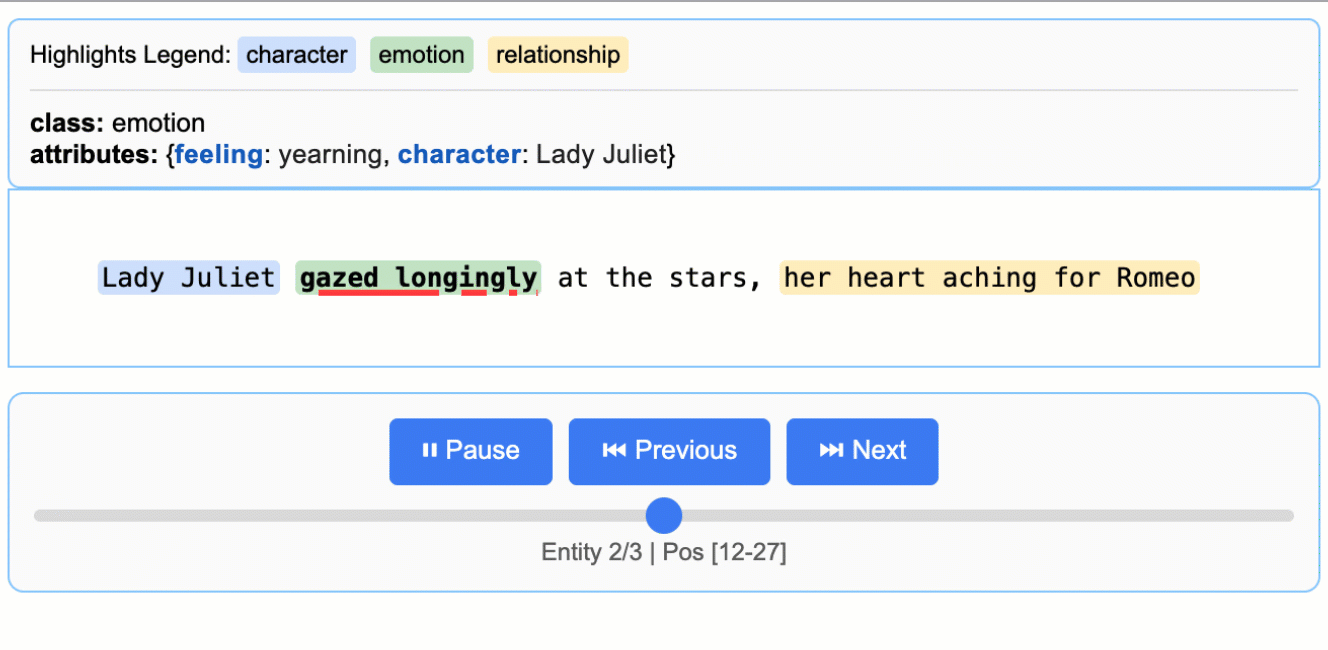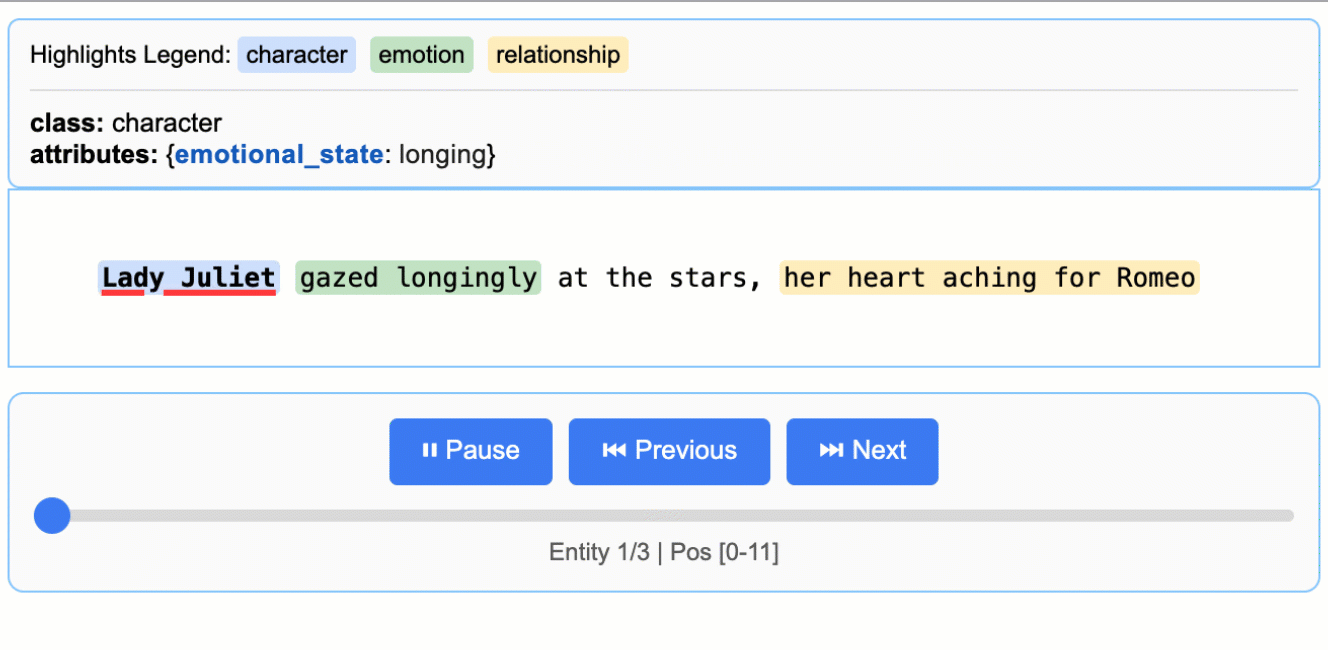
LangExtract는 추출 결과를 .jsonl 포맷으로 저장한 후, 이를 기반으로 상호작용 가능한 HTML 시각화 결과물을 생성합니다. 이를 통해 수천 개의 엔티티를 원문 문맥에서 바로 검토할 수 있으며, 데이터 검증 및 인사이트 발굴에 매우 유용합니다.
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)
대용량 문서 지원
LangExtract는 긴 문서를 다룰 때에도 성능 저하 없이 정보를 정확하게 추출할 수 있도록, 문서 조각화(chunking), 병렬 처리, 다중 패스 추출을 제공합니다. 예를 들어, gutenberg의 고전 문학 전체를 URL로 넣으면 자동으로 수백 개의 엔티티를 추출할 수 있습니다.
다양한 활용 예시 제공
- 문학 분석: 로미오와 줄리엣 전체 텍스트 분석 (예시)
- 의료 데이터: 약물명, 복용량, 용법 등 의료 개체 추출
- 방사선 보고서 분석: RadExtract 데모로 구조화된 리포트 자동 생성
설치 방법
PyPI에서 간편하게 설치할 수 있으며, 가상 환경을 생성한 뒤 설치하는 것을 권장합니다:
pip install langextract
개발 모드나 테스트, Docker 사용도 지원됩니다:
git clone https://github.com/google/langextract.git
cd langextract
pip install -e ".[dev]"
API Key 설정
Gemini, OpenAI 등의 클라우드 모델을 사용할 경우 API 키가 필요합니다. .env 파일을 통한 보안 관리가 권장되며, 환경 변수나 코드 내 직접 설정도 가능합니다.
export LANGEXTRACT_API_KEY="your-api-key"
라이선스
LangExtract 프로젝트는 Apache 2.0 라이선스로 공개되어 있으며, 상업적 사용에 제한이 없습니다. 단, 의료 등 민감한 도메인에서는 Health AI Developer Foundations Terms of Use도 적용되므로 주의가 필요합니다.
 LangExtract 프로젝트 GitHub 저장소
LangExtract 프로젝트 GitHub 저장소
https://github.com/google/langextract
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()