
Llama 4 소개
Meta가 드디어 Llama 4 모델 3종(Scout / Maverick / Behemoth)을 출시하고, 이 중 Scout와 Maverick을 먼저 공개했습니다. Llama 4 Scout와 Maverick은 텍스트와 이미지를 동시에 이해하는 네이티브 멀티모달 모델(Native Multimodal Model)이며, 기존보다 더 적은 파라미터로 GPT-4o, Gemini 2.0 등을 압도하는 성능을 보이고 있습니다. 무엇보다 오픈 가중치(Open Weight)로 공개되어 누구나 다운로드 받아 활용할 수 있는 공개 모델(Open Model)입니다.
Llama 4는 총 3가지 모델로 구성되어 있습니다:
| 모델 | 파라미터 (활성/전체) | 특이점 | 주요 비교 대상 |
|---|---|---|---|
| Llama 4 Scout | 17B / 109B | 10M 토큰 컨텍스트 윈도우, 1 GPU 가능 | Mistral 3.1, Gemini 2.0 Lite |
| Llama 4 Maverick | 17B / 400B | 128 experts, GPT-4o보다 뛰어난 성능 | GPT-4o, Gemini 2.0 |
| Llama 4 Behemoth | 288B / 2T | 학습 중, 다른 모델의 티처 역할 | GPT-4.5, Claude 3.7 |
Scout는 10M의 긴 컨텍스트 윈도우를 갖췄으며, 단일 H100 GPU에서 구동 가능합니다. Maverick은 1417 ELO 점수로 LMArena 기준 GPT-4o를 능가하며, DeepSeek v3.1과 비슷한 수준의 코딩·추론 성능을 절반의 파라미터로 달성합니다. 가장 큰 Behemoth 모델은 아직 학습 중이지만 현재까지의 성능만으로도 GPT-4.5, Claude Sonnet 3.7, Gemini 2.0 Pro를 능가하는 성능을 보이고 있습니다.
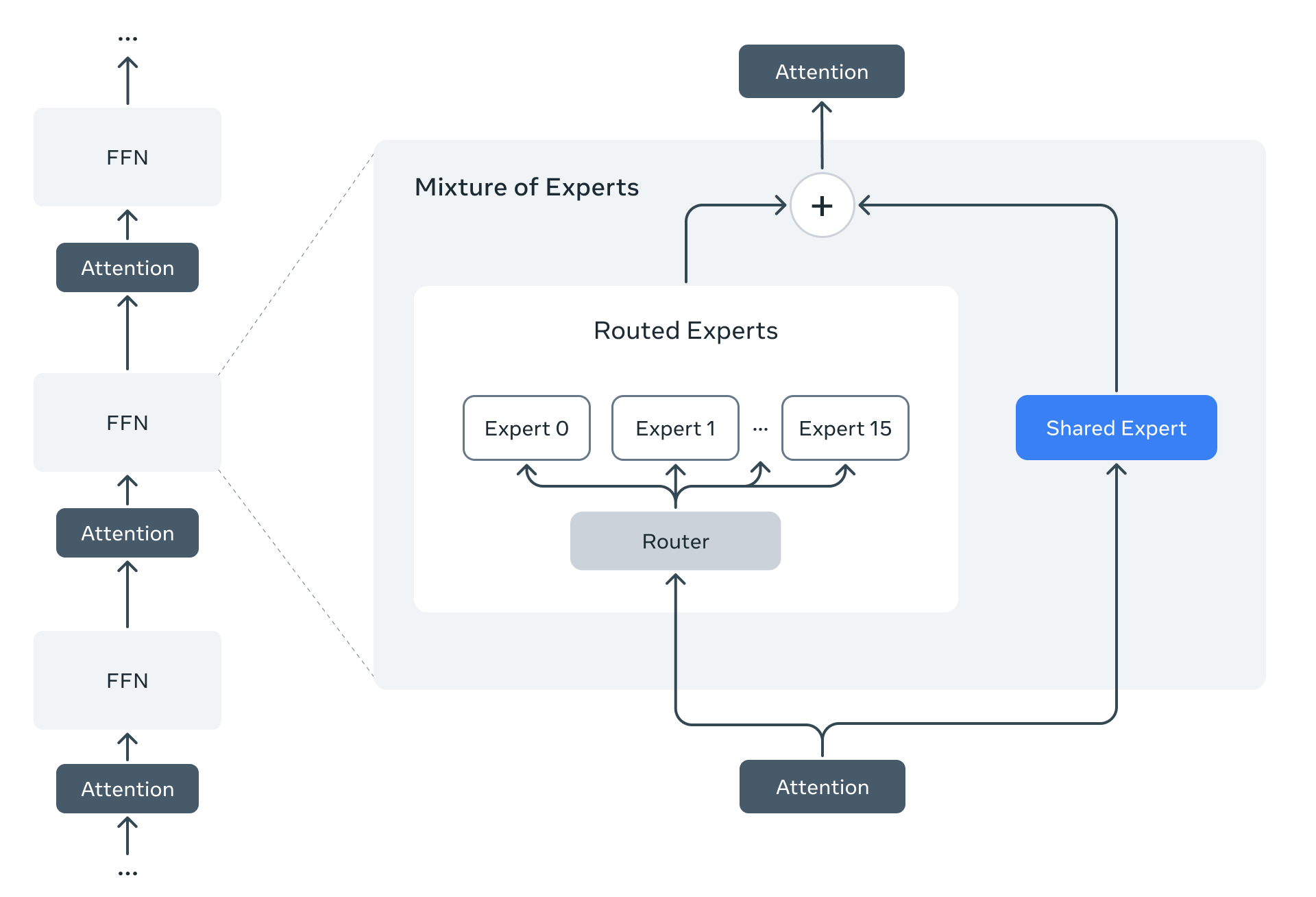
Scout와 Maverick 모두 MoE(Mixture-of-Experts) 구조를 기반으로 하고 있으며, 다양한 언어와 이미지, 비디오 데이터를 함께 학습한 네이티브 멀티모달 모델입니다. 이 두 모델은 모두 오픈 가중치(Open Weight)로 공개되어 Hugging Face 및 Meta 공식 사이트에서 다운로드할 수 있습니다.
Llama 4 Scout 소개
Llama 4 Scout: 10M Context Windows의 더 작고(?) 똑똑한 멀티모달 LLM
Llama 4 Scout는 Llama 4 시리즈 중 가장 작고 가벼운 모델입니다. 이 모델은 단일 H100 GPU에서 실행 가능하며, 1천만(10M) 토큰 컨텍스트 윈도우를 처리하고, 이미지와 텍스트를 동시에 이해하는 멀티모달 모델입니다.
Llama 4 Scout는 다음과 같은 특징을 가진 Multimodal MoE(Mixture-of-Experts) 구조 기반 모델입니다:
- 17B 활성 파라미터, 총 109B 파라미터
- 16개의 전문가(Experts) 중 일부만 활성화
- 단일 NVIDIA H100 GPU(Int4 양자화)로도 구동 가능
- 최대 10,000,000 토큰의 컨텍스트 윈도우
- 텍스트, 이미지, 비디오 데이터까지 함께 학습한 네이티브 멀티모달
기존의 Llama 3가 128K 토큰까지 지원했던 것에 비해, Scout는 무려 80배 더 긴 문맥을 처리할 수 있어 대규모 문서 요약, 코드베이스 분석 등 다양한 실제 활용에 매우 유리합니다.
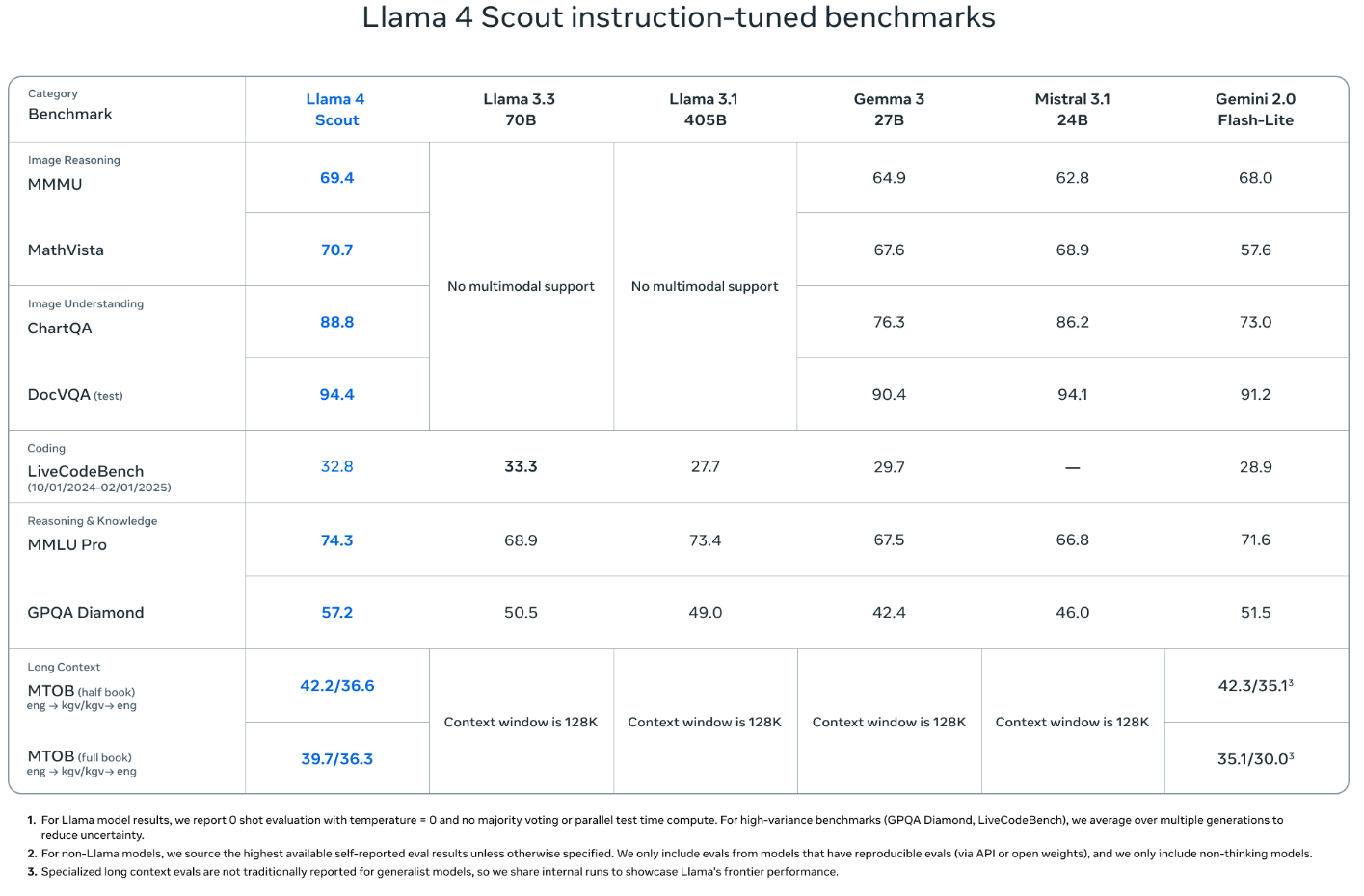
Llama 4 Scout 모델의 주요 특징
- iRoPE 아키텍처: 포지션 임베딩 없이 interleaved attention을 사용해 더 긴 문맥 일반화
- 멀티모달 처리: 이미지 48장까지 프리트레인, 최대 8장까지 멀티이미지 실험 지원
- 이미지 그라운딩: 특정 영역을 인식해 질문에 정답 도출 → VQA 향상
- 높은 다국어 처리력: 200개 언어 학습, 100개 언어는 각각 10억 토큰 이상 학습
- FP8 기반 훈련: 연산량 대비 고성능 유지
Llama 4 Scout 사용 예시
다음은 Llama 4 Scout 모델 사용 예시입니다:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-4-Scout")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-4-Scout")
inputs = tokenizer("문서 5개를 기반으로 요약해줘:", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=1000)
print(tokenizer.decode(outputs[0]))
Llama 4 Maverick 소개
Llama 4 Maverick: GPT-4o와 유사한 성능의 공개 모델
Llama 4 Maverick은 17B 활성 파라미터에 128개의 expert를 갖춘 멀티모달 모델로, GPT-4o와 동급 혹은 그 이상이면서도 파라미터는 절반 이하, 그리고 완전한 오픈 가중치 제공이라는 특징을 갖습니다. Llama 4 Maverick은 Llama 4 시리즈 중 가장 큰 Behemoth 모델의 Codistillation을 통해 탄생시킨 고성능 멀티모달 모델입니다.
Llama 4 Maverick 모델의 주요 특징은 다음과 같습니다:
- 17B 활성 파라미터, 400B 총 파라미터
- 128 experts, MoE 구조 기반
- 멀티모달 이해 (텍스트+이미지), 고난이도 reasoning 및 코딩 성능
- LMArena 기준 ELO 1417점으로 GPT-4o 상회
- GPT-4o, Gemini 2.0 Flash를 대부분 벤치마크에서 능가
특히, 다양한 실제 사용 시나리오(이미지 기반 질의응답, 멀티턴 대화, 창의적 글쓰기, 고난도 수학·코딩)에 최적화된 범용 assistant 모델입니다.
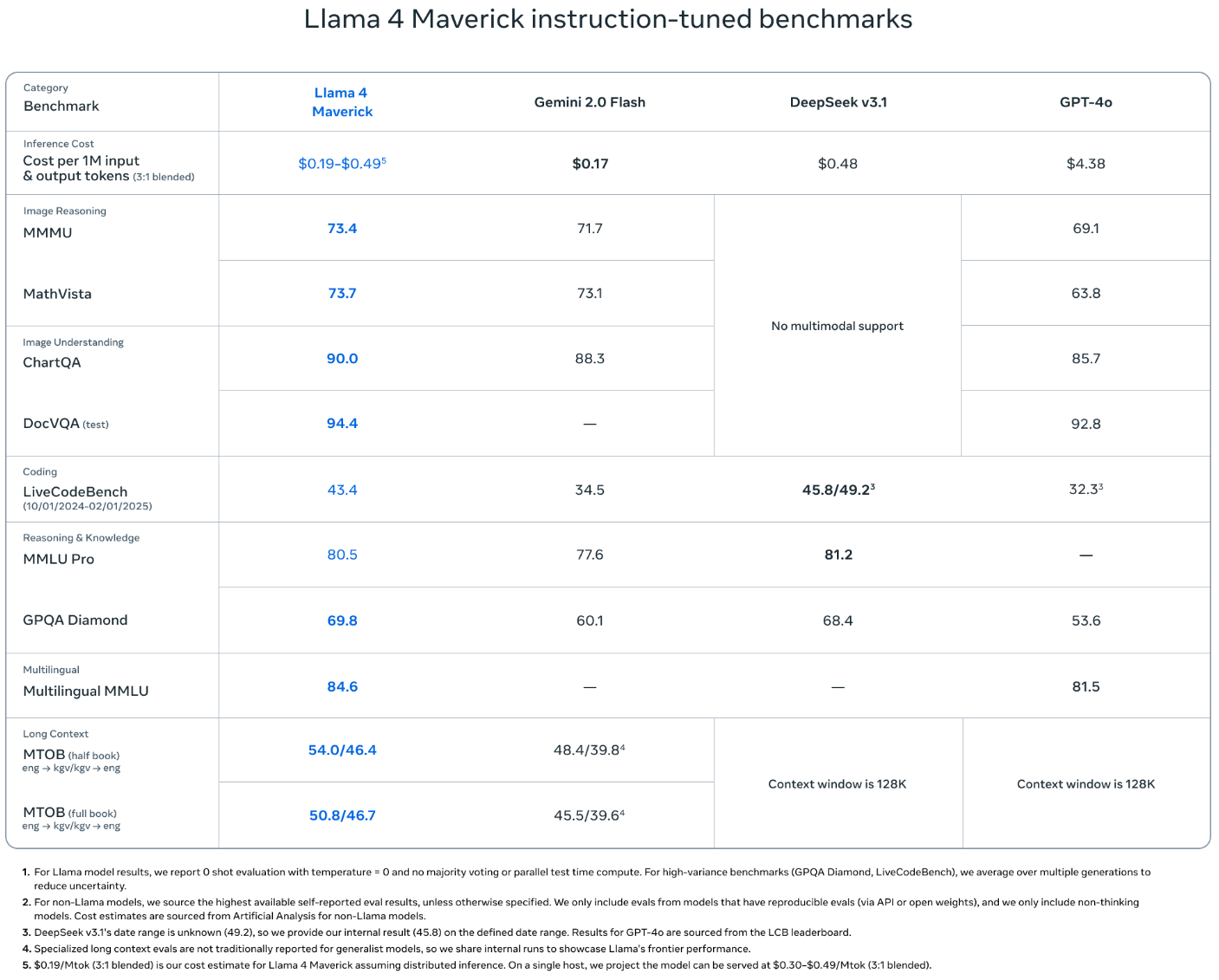
Llama 4 Maverick 모델의 주요 특징
- 고밀도 MoE 구조: 각 토큰은 공유 expert 1개 + routed expert 1개만 사용 → 메모리 절약 + 연산 최적화
- 멀티모달 훈련: 48장 이미지까지 학습, 포스트트레인에서 8장 실험 가능
- 연속형 Online RL 학습: 지속적인 RL 학습과 데이터 난이도 필터링 → 성능 및 일관성 확보
- 코딩, 추론, 수학 도메인에 최적화: GPT-4.5 수준의 Behemoth로부터 지식 전이
- 지속 가능한 inference: 단일 H100 DGX에서 구동 가능하며, 분산 Inference도 용이
Llama 4 Maverick 사용 예시
다음은 Llama 4 Maverick 모델 사용 예시입니다:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-4-Maverick")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-4-Maverick")
query = "다음 이미지를 보고 텍스트로 설명해주세요:"
# 이미지 입력 및 multimodal 처리 로직 필요 (transformers pipeline 참고)
Llama 4 Behemoth 소개
Llama 4 Maverick: 2T 규모의 초거대 Multimodal MoE 모델
Llama 4 Behemoth는 Llama 4 시리즈 중 가장 큰 모델로, 총 2조(2T) 규모의 파라매터를 갖는 Multimodal MoE(Mixture-of-Experts) 모델입니다. 아직 학습 중으로 이번에 공개되지는 않았지만, GPT-4.5, Claude 3.7, Gemini 2.0 Pro 같은 경쟁 모델을 여러 벤치마크에서 앞서고 있는 성능을 보이고 있습니다.
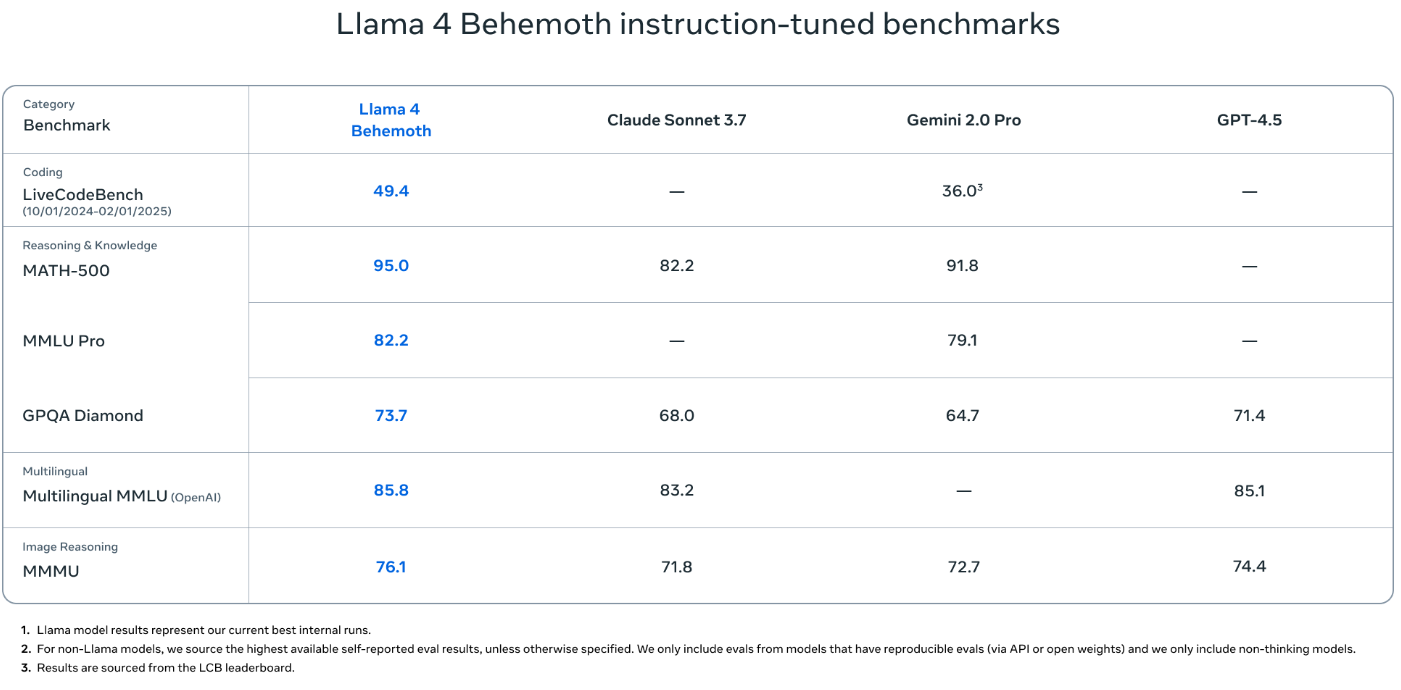
Behemoth는 Llama 4 시리즈에서 티처 모델(Teacher Model)의 역할을 수행합니다. Scout와 Maverick은 Behemoth의 출력값(soft/hard targets)을 기반으로 코디스틸링(co-distillation)되어 학습하였습니다. 아직 공개 전 모델로, 대략적인 스펙은 다음과 같습니다:
- 288B 활성 파라미터
- 2T(2조) 총 파라미터
- 16 Experts 구성의 MoE 아키텍처
- 멀티모달 지원 (텍스트 + 이미지)
 Llama 홈페이지
Llama 홈페이지
 Llama 4 출시 블로그
Llama 4 출시 블로그 

 Llama 4 Scout 및 Maverick 모델 다운로드
Llama 4 Scout 및 Maverick 모델 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()