
초전도체 연구에서의 LLM 평가 개요
연구 소개 및 연구 배경
인공지능(AI)은 이메일 작성, 이미지 편집, 웹 정보 요약 등 일상적인 작업에서 이미 널리 활용되고 있습니다. 하지만 과학 연구 분야에서 AI가 전문가 수준의 정확하고 포괄적인 답변을 제공할 수 있는지는 여전히 열린 질문으로 남아 있습니다. 특히 복잡하고 빠르게 진화하는 전문 분야에서는 극도로 높은 정확성이 요구되기 때문입니다.
Google Research와 Cornell University, Harvard University 연구진은 Proceedings of the National Academy of Sciences (PNAS)에 "Expert evaluation of LLM world models: A high-Tc superconductivity case study"라는 논문을 발표했습니다. 이 연구는 대규모 언어 모델(Large Language Model, LLM)의 세계 모델(world model)이 응집 물질 물리학(condensed matter physics) 분야의 전문가 수준 질문에 답할 수 있는지를 평가한 것입니다. 연구팀은 6개의 LLM에 고온 초전도체(high-temperature superconductor)에 대한 고수준 질문을 던지고, 전문가 패널이 다양한 기준에 따라 응답을 채점하는 방식으로 평가를 수행했습니다.
이전 관련 연구에서도 Google 연구진은 LLM이 여러 과학 분야에서 기본적인 분석 작업을 수행할 수 있는지 평가한 바 있습니다. 이 연구에서는 생물다양성부터 응집 물질 물리학, 단백질 서열 분석까지 6개 과학 분야의 LLM 평가 벤치마크인 CURIE를 소개했습니다. 또한 LLM을 활용한 표와 그림 해석, 양자역학 방정식 풀이, 엔지니어링 시뮬레이션 문제 해결 등 다양한 방향의 연구도 함께 진행되고 있습니다.
Google 내부에서도 AI를 과학 연구 가속화에 활용하려는 다양한 시도가 이루어지고 있습니다. 새로운 가설 생성을 위한 사고 파트너로서의 AI, 전문가 수준의 과학 소프트웨어를 작성하는 에이전트, 그리고 단일 세포 분석을 위한 AI 기반 모델 등이 그 예입니다.
연구 배경: 고온 초전도체의 미해결 문제
왜 초전도체인가
이 연구에서는 LLM이 심층적인 연구 능력과 경쟁하는 이론들 사이에서 균형 잡힌 시각을 제공할 수 있는지를 탐구하기 위해, 고온 초전도체 분야를 선택했습니다. 고온 초전도성은 1987년 노벨상을 수상한 발견 이후 응집 물질 물리학에서 여전히 열린 연구 영역입니다.
연구팀은 구리 화합물의 한 종류인 큐프레이트(cuprate)에 초점을 맞추었습니다. 큐프레이트는 기존 초전도체 물질보다 훨씬 높은 온도에서 전자를 전기 저항 없이 전도할 수 있는데, 가장 높은 임계 온도가 약 -140도 정도입니다. 이 현상의 근본 메커니즘을 이해하면 유사한 특성을 가진 새로운 화합물을 발견하고, 더 높은 온도에서 작동하는 초전도체를 개발하여 응용 범위를 넓히는 데 기여할 수 있습니다.
기존 연구의 어려움
수십 년에 걸쳐 물리학자들은 초전도성을 유발하는 양자역학적 특성을 탐구하기 위해 수천 편의 연구를 발표했습니다. 여러 경쟁 이론이 제안되었고, 서로 다른 연구 그룹들이 이를 추구하고 있습니다. 이렇게 방대한 문헌 속에서 지식 체계를 탐색하는 것은 새로운 세대의 연구자들에게 극도로 어려운 일입니다. 이 분야에 입문하는 학생들에게는 출판된 연구에 대해 중립적인 관점을 가진 지식 있는 튜터가 큰 도움이 될 것입니다.

실험 설계: 6개 LLM에 대한 전문가 평가
데이터 소스에 따른 비교
연구팀은 데이터 소스의 차이가 미치는 영향을 비교하기 위해, 웹 전체에 접근 가능한 4개 모델과 선별된(curated) 데이터베이스만을 사용하는 2개의 폐쇄형 시스템을 평가했습니다.
폐쇄형 시스템의 경우, 고온 초전도성 분야의 세계적인 전문가 12명이 해당 분야의 개요를 제공하는 15편의 과학 리뷰 논문을 선정하여 품질이 검증된 초기 소스 자료로 활용했습니다. 반면 웹 기반 모델 4개는 765편의 오픈 액세스 실험 논문과 1,553편의 오픈 액세스 이론 논문을 포함한 전체 인터넷에 접근할 수 있었습니다.
평가 질문과 채점 방식
전문가 패널은 모델의 심층적인 분야 지식을 테스트하기 위해 67개의 질문을 작성했습니다. 예를 들어, "LSCO에서 리프시츠 전이(Lifshitz transition)는 어떤 도핑 수준에서 발생하는가?" 또는 "큐프레이트에서 양자 임계점(quantum critical point) 시나리오를 뒷받침하는 증거는 무엇인가?" 같은 질문이 포함되었습니다.
평가 대상 LLM은 총 6개로, GPT-4o, Perplexity, Claude 3.5, Gemini Advanced Pro 1.5, Google NotebookLM, 그리고 맞춤형 검색 증강 생성(Retrieval-Augmented Generation, RAG) 시스템이었습니다. 블라인드 리뷰(masked review) 방식으로 각 전문가가 6개 평가 지표에 대해 0~2점 척도로 채점했습니다.
6가지 평가 지표:
| 지표 | 설명 |
|---|---|
| 균형 잡힌 관점(Balanced perspective) | 다양한 과학적 관점을 고려했는지 |
| 포괄성(Comprehensiveness) | 관련 실험을 빠뜨리지 않고 사실적 깊이가 있는지 |
| 간결성(Conciseness) | 간결하고 명확한 답변을 제공했는지 |
| 근거(Evidence) | 근거와 출처 자료 링크로 뒷받침되는지 |
| 시각 자료 관련성(Visual relevance) | 제공된 이미지의 품질 (이미지를 일관되게 포함한 2개 LLM에 해당) |
| 정성적 피드백(Qualitative feedback) | 전문가의 자유 형식 의견 |
주요 실험 결과
NotebookLM의 우수한 성과
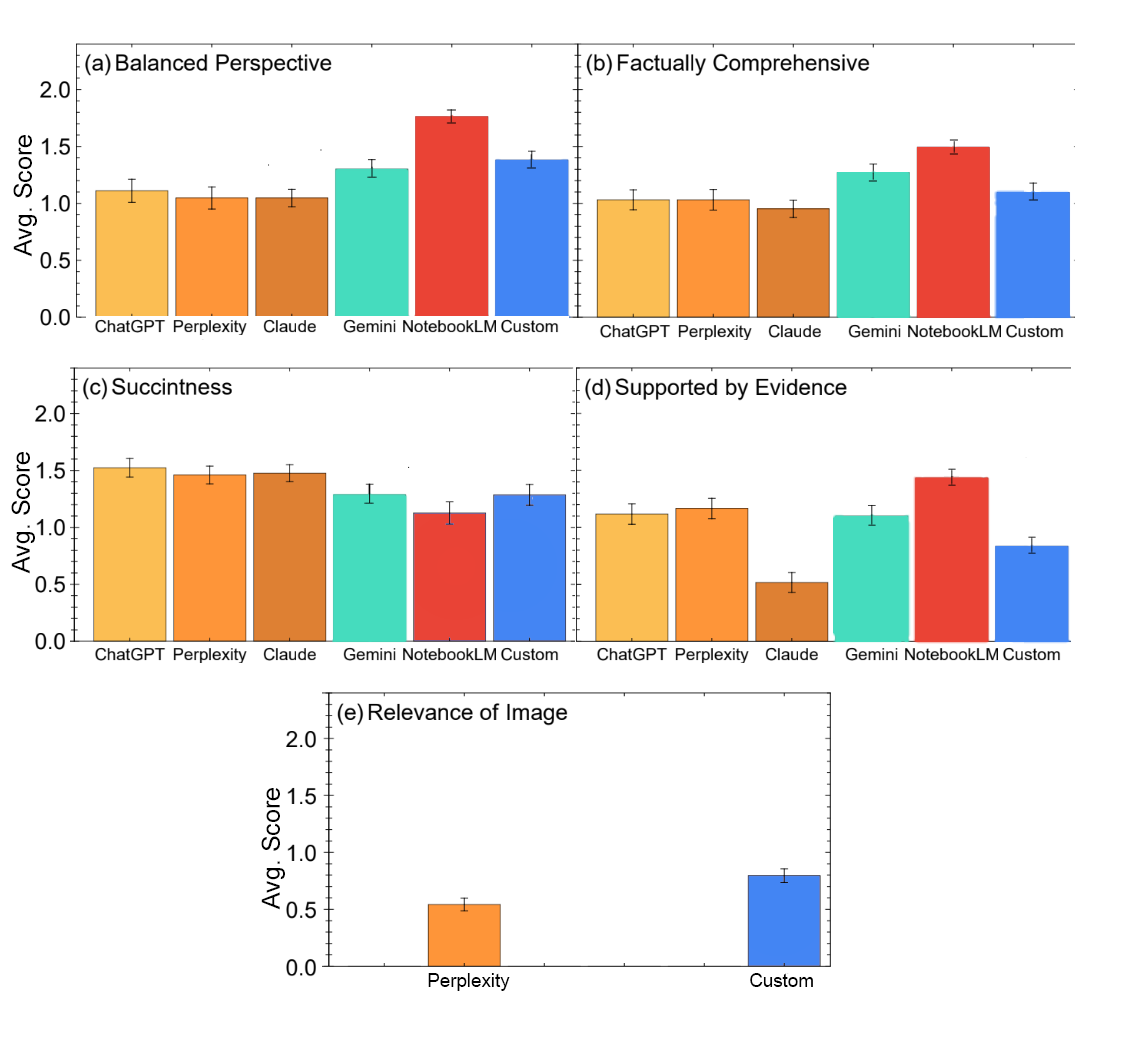
6개 LLM 가운데 NotebookLM이 블라인드 테스트의 대부분의 측면에서 두드러진 성과를 보였습니다. NotebookLM은 사용자가 제공한 문서 라이브러리(이 연구에서는 실험 논문과 리뷰 논문을 포함한 1,726개의 출처)를 기반으로 질문에 답변하는 제품입니다. 전체 성능 기준으로 두 번째로 높은 점수를 받은 것은 동일한 소스를 포함한 맞춤형 RAG 시스템이었습니다.
NotebookLM, Gemini, 맞춤형 RAG 시스템이 관점의 균형성과 포괄적인 답변 제공 부문에서 상위 3위를 차지했습니다. NotebookLM은 가장 간결하지는 않았지만 근거 제공 부문에서 가장 높은 점수를 받았습니다. 시각 자료의 관련성 점수는 전반적으로 낮았으며, 맞춤형 RAG 시스템이 이미지를 제공한 다른 LLM인 Perplexity보다 높은 점수를 기록했습니다.
선별된 데이터 소스의 중요성
이 사례 연구에서 여러 중요한 결론이 도출되었습니다. 선별된 실험 문헌 데이터베이스를 활용한 두 모델, 즉 NotebookLM과 맞춤형 도구가 필터링되지 않은 인터넷 데이터로 학습한 LLM보다 우수한 성과를 보였습니다. 특히 개방형 웹 소스에 의존하는 모델들은 확립된 이론과 고도로 추측적인 이론을 혼합하는 경향이 있었습니다.
LLM의 한계와 개선 방향
2024년 12월 기준으로 평가된 LLM들은 시간적, 맥락적 이해에서도 약점을 드러냈습니다. 예를 들어, 제안된 가설이 이후에 반증되었음을 인식하지 못하는 경우가 많았습니다. 또한 초기 질문에 사용된 정확한 표현이 포함되지 않은 관련 논문을 누락하는 경우도 빈번했습니다.
결과는 LLM이 표와 이미지를 더 잘 이해해야 할 필요성을 광범위하게 보여줍니다. 과학 논문은 이러한 형식을 많이 사용하기 때문입니다. 평가 대상 중 2개 모델이 일관되게 이미지를 참조했지만, 실제 시각적 분석보다는 이미지 캡션에 더 의존하는 경향이 있었습니다. 이미지, 플롯, 스케일 바 해석을 포함한 시각적 추론 능력 향상은 향후 개선의 주요 방향입니다.
향후 전망: 신뢰할 수 있는 AI 연구 파트너를 향해
신뢰할 수 있는 AI 연구 파트너가 실현된다면, 새로운 대학원생이 기존 과학 문헌을 빠르게 파악하는 데 도움을 주고 항상 이용 가능한 사고 파트너 역할을 할 수 있을 것입니다. 또한 경험 많은 과학자들이 새로운 연구 방향을 발견하는 데도 기여할 수 있습니다.
현재의 한계에도 불구하고, 이번 연구 결과는 LLM이 열린 연구 질문을 포함한 복잡한 분야에서도 전문성에 도달할 수 있음을 시사합니다. 다만 전문 분야에서 모델의 역량을 평가하려면, 전문 지식이 필수적이면서도 희소한 자격을 갖춘 전문가에 의존해야 합니다. 연구팀은 이 분야의 연구를 계속하고 있으며, 2026년 4월 ICLR 2026에서 응집 물질 이론 분야의 LLM을 더 엄격하게 평가하는 CMT-benchmark를 발표할 예정입니다.
이번 연구는 물리학 전문가들의 상당한 시간과 분석이 필요했으며, 연구팀은 이러한 노력에서 얻은 통찰이 과학적 발전을 가속화하기 위한 신뢰할 수 있는 AI 도구의 발전에 기여하기를 기대하고 있습니다.
 Expert evaluation of LLM world models: A high-T_c superconductivity case study 논문
Expert evaluation of LLM world models: A high-T_c superconductivity case study 논문

Testing LLMs on superconductivity research questions 소개 블로그
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()