Subterranean Agent 소개
복잡한 업무 매뉴얼을 처음 배우는 신입 직원을 떠올려 봅시다. 처음에는 매 단계마다 두꺼운 매뉴얼을 펼쳐 "이 상황에서는 다음에 무엇을 해야 하지?"를 확인하며 일을 처리합니다. 하지만 몇 달이 지나 같은 절차를 수백 번 반복하고 나면, 더 이상 매뉴얼을 들춰보지 않습니다. 절차가 머릿속에 체화되어 고객과 자연스럽게 대화하면서도 정해진 흐름을 자연스럽게 따라가게 됩니다.
이 논문은 LLM 기반 에이전트에서도 똑같은 일을 할 수 있는지 묻습니다. 즉, 매 턴마다 외부 오케스트레이터가 절차를 주입하는 대신, 업무 절차 자체를 작은 모델의 가중치(weights)에 컴파일(compile)해서 모델이 절차를 체화한 채 사용자와 직접 대화하게 만들 수 있는지를 실증적으로 검증합니다. 저자들은 이렇게 절차가 가중치 속으로 숨어들어간 에이전트를 지하 에이전트(Subterranean Agent) 라고 부릅니다. 논문은 멜버른 대학교(University of Melbourne) 등에 소속된 Simon Dennis 연구팀이 작성했으며, 여행 예약, Zoom 기술 지원, 보험 청구라는 세 가지 실제 업무 도메인에서 이 접근법을 검증합니다.
에이전트 오케스트레이션의 시대, 그리고 그 청구서
최근 몇 년간 LLM 에이전트 프레임워크는 폭발적으로 성장했습니다. LangGraph, CrewAI, Google ADK, OpenAI Agents SDK, Semantic Kernel, Strands, LlamaIndex를 모두 합치면 GitHub 스타가 290{,}000 개를 넘습니다. 이 프레임워크들은 세부 구현은 달라도 한 가지 공통된 패턴을 공유합니다. 바로 LLM 위에 외부 오케스트레이터(orchestrator)를 두고, 매 턴마다 지시문을 주입하고 다음 행동을 라우팅(routing)하는 구조입니다.
그런데 이 연구팀의 선행 연구(Dennis et al., 2026a)는 흥미로운 사실을 보였습니다. 정해진 절차를 따르는 작업(procedural task)에서는, 오케스트레이션이라는 복잡한 구조 없이 그냥 전체 절차를 프론티어 모델의 시스템 프롬프트에 통째로 넣어주고 모델이 스스로 진행하게(self-orchestrate) 하는 것만으로도 거의 완벽한 품질(5 점 만점에 4.53 에서 5.00 )이 나온다는 것입니다. 오케스트레이터가 오히려 발목을 잡고 있었던 셈입니다.
하지만 이 in-context 방식에도 명확한 청구서가 따라붙습니다. 첫째, 모든 대화에 비싼 프론티어 모델이 필요합니다. 둘째, 절차 전체가 매 API 호출의 프롬프트에 실리므로 토큰 소비량이 크게 부풀어 오릅니다. 셋째, 그만큼 컨텍스트 윈도우(context window) 용량을 잡아먹습니다. 넷째, 회사의 독점적인 업무 절차가 외부 모델 제공사에 그대로 노출됩니다.
기존 접근법과 그 한계
문제를 정리하면, 절차적 작업을 처리하는 기존 방식은 크게 두 갈래로 나뉘고 둘 다 단점이 분명합니다.
오케스트레이션 프레임워크 는 가장 널리 쓰이는 방식이지만, 신뢰성 비용이 잘 문서화되어 있습니다. 한 연구는 멀티 에이전트 시스템의 실패 모드를 14 가지로 분류했고, 다른 연구는 연쇄 실패(cascading failure)가 주요 병목임을 보였으며, 또 다른 연구는 60\% 의 pass@1 성능을 보이는 에이전트가 여러 번 시도했을 때 일관성은 25\% 에 그친다는 점을 지적했습니다. 구조적으로 보면 오케스트레이터는 각 노드의 지역적 맥락만 보고 응답을 생성하기 때문에 추론이 파편화되고, 라우팅 결정 지점마다 새로운 실패 모드가 생기며, 템플릿 주입 때문에 모델의 자연스러운 대화 스타일이 제약됩니다.
in-context 프롬프팅 은 품질은 가장 높지만, 앞서 본 것처럼 매 대화마다 프론티어 모델을 호출해야 하고 토큰 비용과 절차 노출 문제를 안고 있습니다.
그렇다면 세 번째 길, 절차를 작은 파인튜닝 모델의 가중치에 컴파일하는 방법은 어떨까요? 사실 이 기법 자체는 새롭지 않습니다. SimpleTOD, FireAct, SynTOD, WorkflowLLM, Agent Lumos 같은 선행 연구들이 이미 에이전트 능력을 모델 가중치로 컴파일하는 데 성공했고, 그중 일부는 프론티어 모델에 견줄 만한 품질을 달성했습니다. 그런데도 정작 개발자들의 선택은 압도적으로 오케스트레이션 쪽으로 기울었습니다. 위 컴파일 논문들의 GitHub 스타를 모두 합쳐도 약 3{,}000 개로, 오케스트레이션 프레임워크보다 약 100\times 적은 관심을 받았을 뿐입니다.
이 연구의 발상 전환: 무엇이 가중치에, 무엇이 프롬프트에 속하는가
저자들의 질문은 단순합니다. "기법이 작동하는 것이 증명되었는데, 왜 아무도 절차를 가중치에 컴파일하지 않는가?" 연구팀은 개발자들이 컴파일을 외면하는 이유를 세 가지 인식된 장벽(perceived barrier), 즉 품질, 비용, 유연성으로 정리하고, 각각이 실제로는 통념보다 훨씬 작은 장벽임을 실증적으로 보입니다.
선행 컴파일 연구들이 "기법이 작동한다"는 것을 보였다면, 이 논문은 그동안 아무도 측정하지 않은 세 가지를 처음으로 정량화한다는 점에서 차별화됩니다. (1) 컴파일이 오케스트레이션이나 in-context 대비 얼마나 추론 비용을 줄이는지, (2) 재컴파일 사이클이 실제로 얼마나 걸리는지, 그리고 (3) 동일 모델 오케스트레이터와 프론티어 모델 베이스라인을 모두 대조해 모델 용량 효과와 컴파일 자체의 효과를 분리한 것입니다.
이 연구를 관통하는 핵심 원칙은 다음 한 문장으로 요약됩니다. "지속적인 구조(persistent structure)는 가중치에, 일시적인 상태(transient state)는 프롬프트에 속한다." 즉 한 대화의 컨텍스트를 넘어 계속 유지되어야 하는 업무 절차는 모델 가중치에 영구적으로 새겨 넣고, 그 대화에서만 의미 있는 사용자 이름이나 예약 날짜 같은 일시적 정보만 프롬프트에 담자는 것입니다.
워크플로우를 가중치로 컴파일하는 방법
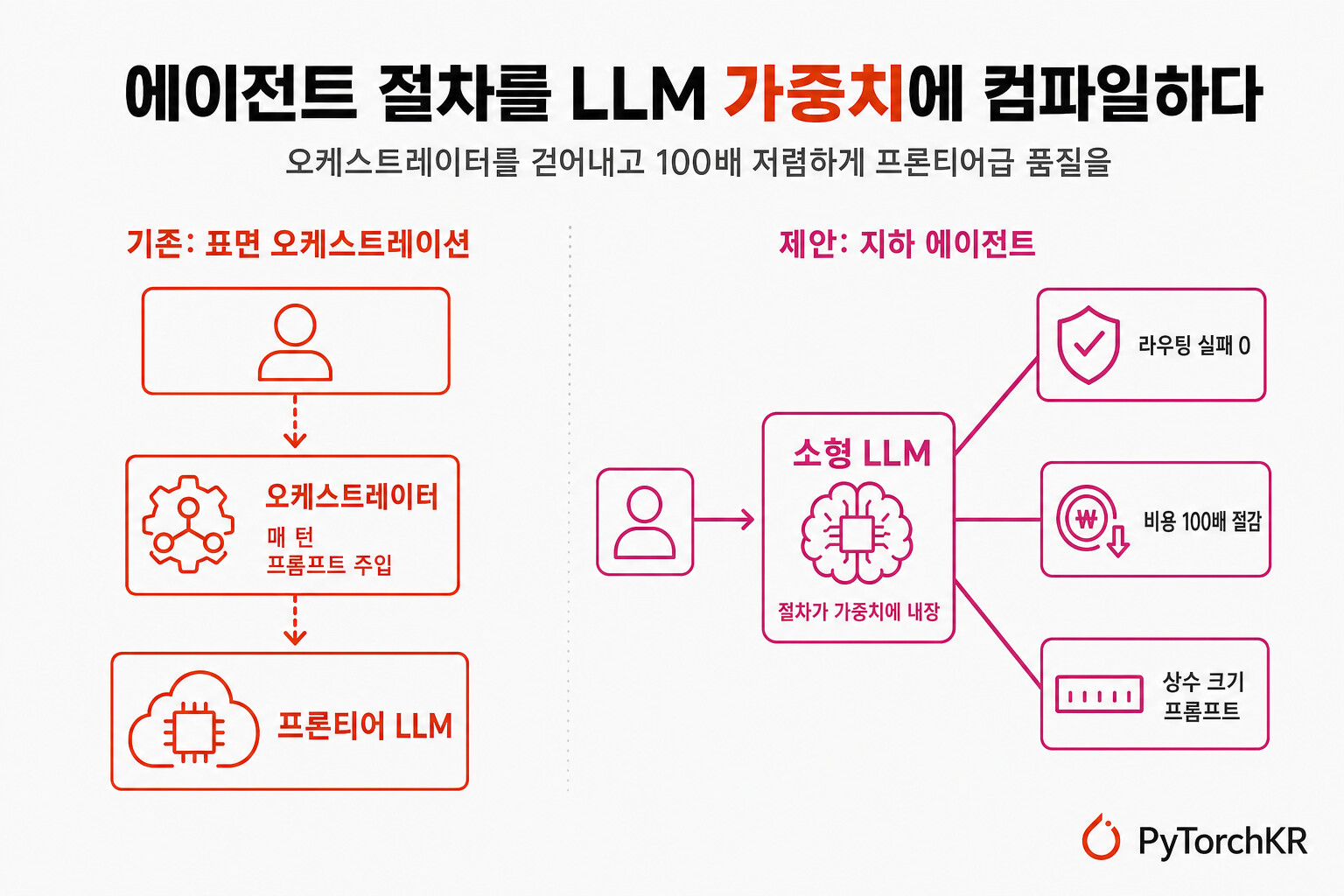
표면 오케스트레이션 vs 지하 에이전트
두 아키텍처의 차이는 "오케스트레이터가 런타임에 존재하느냐"로 갈립니다.
표면 오케스트레이션(surface orchestration) 에서는 사용자와 LLM 사이에 오케스트레이터가 끼어듭니다. 매 턴마다 오케스트레이터가 프롬프트를 주입하고 LLM의 출력을 파싱하며 다음 노드를 결정합니다. 오케스트레이터는 런타임 내내 LLM 위에 군림합니다.
지하 에이전트(subterranean agent) 에서는 오케스트레이터가 오직 학습 데이터를 생성하는 동안에만 사용됩니다. 런타임에는 사용자가 LLM과 직접 대화하며, 절차는 이미 LLM의 가중치 속에 컴파일되어 있습니다. 모델은 명시적인 지시 없이, 학습으로 익힌 통계적 규칙성을 통해 절차를 암묵적으로 따라갑니다. 별도의 인터프리터(interpreter)가 필요 없으며, 모델이 곧 절차의 실행기입니다. 마치 신입 직원이 매뉴얼을 체화하고 나면 더 이상 매뉴얼을 펼치지 않는 것과 같습니다.
절차를 방향 그래프로 표현하기
연구팀은 업무 절차를 방향 그래프(directed graph) F = (N, E, n_0, T) 로 표현합니다.
- N : 노드(node). 각 노드는 역할(에이전트 또는 사용자)과 프롬프트 템플릿을 가집니다.
- E \subseteq N \times N \times C : 엣지(edge). 조건부 전이를 나타내며 선택적 조건 C 를 가질 수 있습니다.
- n_0 \in N : 시작 노드.
- T \subseteq N : 종료 노드(성공, 포기, 에스컬레이션).
이 그래프가 곧 "매뉴얼"입니다. 각 노드는 대화의 한 턴에 해당하고, 엣지는 대화가 어떤 조건에서 다음 단계로 넘어가는지를 정의합니다.
컴파일 파이프라인 4단계
지하 에이전트를 만드는 과정은 네 단계로 이루어집니다.
- 절차 정의: 업무 절차를 노드(턴)와 엣지(전이)를 가진 플로우차트(flowchart)로 정의합니다.
- 합성 대화 생성: 플로우차트의 유효한 경로들을 따라가며 합성 대화(synthetic conversation)를 생성합니다. 이때 경로 하나와 시나리오 변수(목적지, 예산, 사용자 성향, 청구 유형 등)를 샘플링한 뒤, Claude Sonnet 4.5가 각 노드의 프롬프트 템플릿과 전체 대화 기록을 보고 턴 단위로 대화를 만들어 냅니다.
- 전체 파라미터 파인튜닝: 생성된 대화로 LLM의 모든 파라미터를 업데이트합니다.
- 오케스트레이션 없이 배포: 모델이 스스로 절차를 진행하도록 학습되었으므로, 런타임에는 오케스트레이터 없이 배포합니다.
여기서 핵심은 추론 시점의 모델은 절차 주석이 전혀 없는 순수한 자연 대화만 본다는 점입니다. 절차의 구조는 대화가 흘러가는 방식 속에 암묵적으로 녹아 있을 뿐입니다. 추론 시점에 모델이 받는 시스템 프롬프트는 "You are a helpful travel booking assistant" 같은 최소한의 한 줄뿐이며, 절차 지시문이나 플로우차트 상태, 라우팅 로직은 일절 주입되지 않습니다.
왜 LoRA가 아니라 전체 파라미터 파인튜닝인가
이 대목은 직관에 반할 수 있습니다. 요즘은 대부분 LoRA(Low-Rank Adaptation) 같은 파라미터 효율적 파인튜닝(PEFT)을 쓰는데, 왜 비용이 더 큰 전체 파인튜닝(full fine-tuning)을 고집할까요?
저자들의 답은 명확합니다. 절차를 체화한다는 것은 모델의 암묵적인 상태 추적(state-tracking) 행동을 바꾸는 일이며, 이는 단순히 말투를 맞추는 스타일 정렬(stylistic alignment)보다 훨씬 깊은 변화이기 때문입니다. 동반 연구(Dennis et al., 2026b)는 LoRA의 랭크(rank)를 16 부터 128 까지 체계적으로 바꿔가며 실험했는데, 저랭크(low-rank) 방법은 절차적 작업에서 전체 파인튜닝의 성능에 근접하지 못했습니다. 이 연구의 제목이 "Procedural knowledge is not low-rank" 인 것처럼, 절차적 지식은 본질적으로 저랭크로 압축되지 않는다는 것입니다.
평가 방법론
세 실험은 두 가지 공통 베이스라인(baseline)을 공유합니다.
- LangGraph 오케스트레이터: 가장 널리 쓰이는 에이전트 프레임워크인 LangGraph(2026년 3월 기준 약 30 K 스타)로 Claude Sonnet 4.5를 오케스트레이션합니다. 플로우차트의 각 노드가 LangGraph 그래프 노드에 매핑되고, 결정 허브에서는 LLM 분류기가 다음 엣지를 고릅니다. 이것이 프론티어 모델 베이스라인이며, 3 B 컴파일 모델보다 약 70\times 더 많은 파라미터를 가집니다.
- in-context 베이스라인: Claude Sonnet 4.5에게 직렬화된 전체 플로우차트를 시스템 프롬프트로 주고 턴당 한 번의 API 호출로 스스로 진행하게 합니다. 프론티어 모델이 도달할 수 있는 품질의 상한선(upper bound) 역할을 합니다.
평가에는 도메인마다 조건당 n = 200 개의 시나리오를 사용했습니다. 사용자 역할은 Claude Sonnet 4.5 기반의 동적 사용자 시뮬레이터(user simulator)가 맡으며, 이 시뮬레이터는 플로우차트를 전혀 모른 채 주어진 선호와 성향을 가진 고객을 연기합니다.
품질 평가는 approach-agnostic LLM-as-judge 방식을 따릅니다. Claude Sonnet 4.5가 어떤 시스템이 만든 대화인지 모르는 상태에서 다음 다섯 가지 기준을 1 에서 5 점 척도로 채점합니다.
- Task Success: 절차를 올바르게 끝까지 수행해 적절한 종료 상태에 도달했는가
- Information Accuracy: 사용자가 제공한 정보를 정확히 사용하고 유지했는가
- Consistency: 대화 전반에서 모순 없이 일관된 상태를 유지했는가
- Graceful Handling: 변경, 모호함, 엣지 케이스를 얼마나 매끄럽게 처리했는가
- Naturalness: 숙련된 사람 상담원과 대화하는 것처럼 자연스러운가
Claude가 데이터 생성자이자 심사자라는 자기 선호 편향(self-preference bias)을 우려해, 모든 대화를 독립적인 GPT-4.1 심사자로 동일한 루브릭(rubric)을 사용해 재채점했습니다. GPT-4.1 심사자는 세 도메인 전반에서 in-context 품질의 83 에서 99\% 라는 비슷한 결과를 냈고, 핵심 결론(컴파일 모델이 동일 모델 오케스트레이터를 압도하고, in-context가 선두)은 심사자 선택과 무관하게 유지되었습니다. 통계 분석에는 Wilcoxon signed-rank 검정과 Mann-Whitney U 검정, Cohen's d 효과 크기, 부트스트랩 95\% 신뢰구간을 사용하고, 다섯 기준에 Holm-Bonferroni 보정(\alpha = 0.05 )을 적용했습니다.
장벽 1: 품질, 작은 모델이 정말 프론티어를 따라잡는가
실험 1: 여행 예약 (3B 모델)
첫 실험은 동일 모델 비교(same-model comparison) 라는 점이 핵심입니다. 같은 Qwen 2.5 3B Instruct를 베이스로, (1) 컴파일한 지하 에이전트와 (2) 같은 모델에 명시적 플로우차트 상태 추적을 붙인 표면 오케스트레이터를 비교하면, 모델 용량 차이를 배제하고 컴파일 자체의 효과만 분리해 낼 수 있습니다. 여기에 (3) LangGraph 오케스트레이터와 (4) in-context 베이스라인을 더해 네 조건을 평가했습니다.
학습에는 여행 플로우차트(노드 14 개, 결정 허브 3 개, 고유 경로 86 개)에서 생성한 합성 대화 2{,}125 개를 사용했고(학습 1{,}912 개), RTX 5090 한 장에서 전체 파라미터를 20 에포크(\sim 3.5 시간) 학습했습니다.
| 기준 | 3B 지하 | 3B 오케스트레이터 | LangGraph | in-context |
|---|---|---|---|---|
| Task Success | 4.11 | 3.93 | 4.17 | 4.53 |
| Info. Accuracy | 4.75 | 4.69 | 4.21 | 4.64 |
| Consistency | 4.34 | 4.12 | 4.32 | 4.96 |
| Graceful Handling | 4.07 | 3.87 | 4.62 | 4.96 |
| Naturalness | 4.12 | 3.96 | 4.84 | 5.00 |
컴파일은 도움이 됩니다. 3B 지하 에이전트는 동일 모델 오케스트레이터를 다섯 기준 모두에서 앞섰고, 그중 네 기준에서 통계적으로 유의했습니다. Task Success(\Delta = +0.18 ), Consistency(\Delta = +0.22 ), Graceful Handling(\Delta = +0.20 ), Naturalness(\Delta = +0.17 ) 모두 p < 0.001 이었습니다. 같은 모델, 같은 절차인데 아키텍처만 바꿨을 뿐인데도 품질이 올라간 것입니다.
다만 한계도 드러났습니다. in-context 베이스라인과 비교하면 Information Accuracy는 102\% 로 오히려 앞섰지만, Graceful Handling과 Naturalness는 약 82\% 에 그쳤습니다. 3B 모델이 절차는 학습했지만, 예상치 못한 엣지 케이스를 자연스럽게 다룰 만한 표현 능력은 부족했던 것입니다. 이는 더 큰 모델로의 확장을 시사합니다.
실험 2: Zoom 기술 지원 (8B 모델)
여행에서 드러난 Graceful Handling과 Naturalness 격차를 메우기 위해, 연구팀은 Qwen3-8B로 확장하고 학습 데이터를 크게 늘렸습니다. Zoom 지원은 또 다른 도전 과제를 던집니다. 바로 제품 특화 지식(product-specific knowledge) 입니다. 모델은 단순히 절차 구조만이 아니라 Zoom의 UI, 설정 메뉴, 흔한 오류 코드 같은 도메인 지식까지 가중치에 내장해야 합니다.
학습 데이터는 파이프라인을 서로 다른 시드(42 부터 49 )로 여덟 번 돌려 6{,}264 개의 대화로 늘렸고(같은 경로라도 시드에 따라 다른 대화가 나오므로 중복 제거가 불필요), 8개의 A100에서 DeepSpeed ZeRO-3로 전체 파인튜닝했습니다.
| 기준 | 8B 지하 | LangGraph | in-context |
|---|---|---|---|
| Task Success | 4.50 | 4.62 | 4.92 |
| Info. Accuracy | 4.26 | 4.75 | 4.92 |
| Consistency | 4.42 | 4.55 | 5.00 |
| Graceful Handling | 4.62 | 4.52 | 5.00 |
| Naturalness | 4.87 | 4.64 | 5.00 |
격차가 극적으로 좁혀졌습니다. 8B 모델은 Graceful Handling에서 in-context의 92\% (3B는 82\% ), Naturalness에서 97\% (3B는 82\% )를 달성했습니다. 심지어 Naturalness는 LangGraph 오케스트레이터(4.87 vs 4.64 , p < 0.001 )를 앞섰습니다. 남은 격차는 Information Accuracy(87\% )에 집중되었는데, 이는 절차 추종이 아니라 폭넓은 세계 지식(world knowledge)이 병목인 영역입니다.
실험 3: 보험 청구 처리 (8B 모델, 55개 노드)
여행과 Zoom의 14 노드 절차는 중간 정도의 복잡도입니다. 보험 청구는 노드 55 개, 결정 허브 6 개, 고유 경로 2{,}381 개로 다른 도메인보다 거의 4\times 큽니다. 문서 요청에서 검토로 갔다가 다시 요청으로 돌아오는 중첩 루프(nested loop)와, 보장 결정이 합의 옵션을 제약하는 단계 간 의존성(cross-phase dependency)까지 있어, 컴파일이 훨씬 복잡한 워크플로우로 확장되는지를 시험합니다.
학습에는 이 55 노드 플로우차트에서 생성한 합성 대화 3{,}000 개(학습 2{,}700 개)를 사용했고, Zoom과 동일하게 8개의 A100에서 DeepSpeed ZeRO-3로 전체 파인튜닝했습니다. 다만 절차가 더 큰 만큼 노드별 특화 행동과 긴 대화 궤적을 익히기 위해 에포크는 Zoom의 10 회보다 많은 20 회를 돌렸습니다.
| 기준 | in-context | LangGraph | 8B 지하 |
|---|---|---|---|
| Task Success | 4.78 | 4.42 | 4.47 |
| Info. Accuracy | 4.78 | 4.45 | 4.40 |
| Consistency | 4.82 | 4.39 | 4.51 |
| Graceful Handling | 4.96 | 4.38 | 4.81 |
| Naturalness | 5.00 | 4.58 | 4.92 |
8B 컴파일 모델은 in-context 품질의 92 에서 98\% 를 달성하며, 컴파일이 훨씬 큰 절차에도 확장됨을 입증했습니다. 특히 LangGraph 오케스트레이터를 Graceful Handling(4.81 vs 4.38 ), Naturalness(4.92 vs 4.58 ), Consistency(4.51 vs 4.39 )에서 앞섰습니다. 두 기준(p < 0.001 )에서 약 70\times 큰 프론티어 모델을 작은 컴파일 모델이 능가한 것입니다.
효율성과 실패 모드
품질만큼이나 흥미로운 것은 실패율입니다. 심사자가 Task Success를 3 점 이하로 준 대화를 실패로 정의했을 때, 결과는 다음과 같습니다.
| 도메인 | 지하 에이전트 실패율 | LangGraph 실패율 |
|---|---|---|
| 여행 (3B) | 5.5\% | 24.0\% |
| Zoom (8B) | 11.0\% | 9.0\% |
| 보험 (8B) | 9.0\% | 17.0\% |
여행에서 LangGraph의 실패율이 24\% 로 높은 것은 결정 허브에서의 라우팅 오류 때문입니다. 그런데 컴파일 모델은 이 실패 모드를 구조적으로 제거합니다. 라우팅이라는 단계 자체가 없으므로 라우팅 실패도 있을 수 없는 것입니다. Zoom만 두 방식이 비슷했고, 여행과 보험에서는 컴파일 모델이 분명히 낮은 실패율을 보였습니다.
논문이 공개한 여행 대화 예시가 이를 잘 보여줍니다. 지하 에이전트는 5 번째 턴에 여행 옵션을 제시하고 7 번째 턴에 예약을 확정한 반면, 오케스트레이터는 날짜와 선호를 묻는 같은 질문을 4, 6, 8 번째 턴에서 세 번이나 반복한 뒤 14 번째 턴에야 옵션을 제시했습니다. 현재 노드의 지역적 맥락만 보고 응답을 생성하느라 전체 대화 흐름을 놓친 것입니다.
지연 시간(latency)에서도 자가 호스팅(self-hosting)의 이점이 드러났습니다. 보험 도메인에서 컴파일 모델은 43.2 초, LangGraph는 120.8 초로 약 2.8\times 빨랐습니다. LangGraph는 6 개의 결정 허브마다 추가 API 호출을 하고, 55 노드 절차가 매 프롬프트를 부풀리기 때문입니다.
흥미로운 부수 효과도 있습니다. 컴파일 모델은 학습 데이터로부터 "인터뷰 스타일(interview style)" 을 익혔습니다. 한 턴에 하나의 집중된 질문만 던지고 사용자 응답을 기다린 뒤 다음으로 넘어가는 방식으로, 전체 턴의 64\% 가 정확히 하나의 질문만 담고 있었습니다. 반면 현재 노드 템플릿에 묶인 LangGraph 오케스트레이터는 한 턴에 여러 질문을 욱여넣곤 했습니다. 대화당 총 단어 수는 비슷했으므로(\sim 1{,}200 에서 1{,}400 단어), 같은 정보를 주고받되 다른 크기로 잘라 전달한 셈입니다. 한 턴 한 질문 리듬은 더 명확한 감사 추적(audit trail)을 남기고 사용자의 인지 부하를 줄일 수 있습니다.
장벽 2: 비용, 자가 호스팅까지 따지면 정말 더 싼가
비용 절감은 서로 독립적인 두 요소가 곱해져 발생합니다.
토큰당 단가. 컴파일된 지하 에이전트는 프론티어 API가 아니라 상용 GPU 하드웨어에서 자가 호스팅됩니다. 연구팀은 8B 모델을 시간당 \$2.50 의 예약형 클라우드 A100 80GB에서 vLLM으로 배치 추론(batched inference)했습니다. 공개 벤치마크 기준 처리량으로 환산하면 입력 \sim \$0.05 /M 토큰, 출력 \sim \$0.23 /M 토큰이 나오는데, Claude Sonnet 4.5의 공개 단가인 입력 \$3 /M, 출력 \$15 /M과 비교하면 토큰당 약 65\times 저렴합니다.
토큰 사용량. in-context 베이스라인은 매 턴 시스템 프롬프트에 직렬화된 절차를 포함해야 하므로, 절차가 복잡할수록 오버헤드가 커집니다. 여행(14 노드)은 약 2\times , 보험(55 노드)은 약 7\times 입니다. 반면 컴파일 모델의 프롬프트는 절차 복잡도와 무관하게 상수 크기(constant-size) 이므로 이 오버헤드가 통째로 사라집니다.
| 도메인 | in-context | LangGraph | 지하 에이전트 | in-context/지하 비율 |
|---|---|---|---|---|
| 여행 (14 노드) | \$0.133 | \$0.077 | \$0.0010 | 128\times |
| Zoom (14 노드) | \$0.103 | \$0.054 | \$0.0003 | 296\times |
| 보험 (55 노드) | \$0.327 | \$0.174 | \$0.0007 | 462\times |
두 요소가 곱해지면서 대화당 비용은 in-context 대비 128 에서 462\times 저렴해집니다. 결정적으로 이 격차는 절차가 복잡할수록 커집니다. 가장 복잡한 보험에서 격차가 가장 컸다는 점이 이 접근법의 핵심 가치입니다. LangGraph 오케스트레이터와 비교해도 77 에서 249\times 저렴합니다.
물론 컴파일에는 일회성 비용이 듭니다. 데이터 생성에 약 \$40 , 파인튜닝 컴퓨팅에 약 \$10 에서 40 으로 합계 \$50 에서 80 정도입니다. 하지만 이 비용은 모든 도메인에서 500 회 대화 이내에 손익분기점(break-even) 을 넘고, 10{,}000 회 이상이면 대화당 \$0.01 미만의 추가 비용으로 희석됩니다.
장벽 3: 유연성, 절차가 바뀌면 처음부터 다시 학습해야 하는가
마지막 장벽은 "절차가 바뀔 때마다 모델을 처음부터 재학습해야 하니 너무 느리다"는 통념입니다. 컴파일 모델은 분명히 재학습(recompile)이 필요하지만, 파이프라인의 세 단계가 모두 깔끔하게 병렬화됩니다.
- 데이터 생성: Claude Sonnet 4.5가 새 플로우차트를 순회하며 약 1{,}600 개의 합성 대화를 만듭니다. 대화들이 독립적이라 API 호출이 병렬화되며, 적절한 동시성으로 15 에서 30 분이면 끝납니다.
- 파인튜닝: 8B 모델은 H200 한 장의 메모리(\sim 96 GB)에 전체 정밀도로 들어가므로 샤딩이 필요 없고, 8개의 H200으로 데이터 병렬화하면 12 에포크를 10 에서 15 분으로 압축합니다.
- 평가: 50 시나리오 vLLM 배치 스팟 체크는 따뜻하게 켜둔 추론 서버에서 약 5 분이면 됩니다.
완전히 최적화된 사이클은 30 에서 50 분에 끝납니다. 이는 대규모 애플리케이션의 CI/CD 빌드에 맞먹는 시간이지, 패러다임을 갈아엎어야 할 만큼의 장벽이 아닙니다. 8-GPU 클러스터가 없는 실무자라도 A100 80GB 한 장으로 약 3 에서 4 시간이면 재컴파일할 수 있습니다.
같은 상황, 다른 대화: 구체적 비교
수치만으로는 와닿지 않으니, 논문이 제시한 실제 Zoom 지원 대화를 비교해 보겠습니다. 시나리오는 "Zoom 회의 중 오디오가 간헐적으로 끊기고 연결 표시줄이 노란색/빨간색으로 바뀌는" 상황입니다.
8B 지하 에이전트 는 한 번에 한 가지씩 진단 단계를 안내합니다.
Agent: 대역폭 관련 문제 같네요. WiFi를 쓰시나요, 이더넷을 쓰시나요? 그리고 이 문제가 모든 회의에서 발생하나요, 특정 회의에서만 발생하나요?
User: WiFi를 씁니다. 대부분의 회의에서 발생하는데, 참가자가 많을 때 더 심해요.
Agent: 좋은 단서네요. 참가자가 많으면 더 많은 비디오 스트림이 대역폭을 두고 경쟁합니다. 몇 가지 해봅시다. 1단계: Zoom 설정의 비디오 메뉴에서 "HD 비디오"를 꺼 주세요. 대역폭 사용량이 크게 줄어듭니다.
이어서 통계 패널 확인, 배경 소음 억제 설정, 이더넷 연결 권유로 자연스럽게 흘러가며 12 턴 만에 해결에 도달합니다. 도메인 특화 학습 덕에 Zoom의 실제 UI 경로를 정확히 안내합니다.
반면 Claude 오케스트레이터 는 현재 노드 템플릿에 묶여 한 턴에 네 가지 제안을 한꺼번에 쏟아냅니다. 그런데 그중에는 "음악가를 위한 원본 사운드 사용(use original sound for musicians)" 이라는 잘못된 조언이 섞여 있었고, 사용자가 "그건 오히려 일반 통화 품질을 떨어뜨리지 않나요?"라고 되묻자 모델은 "맞습니다, 그 제안은 특정 용도를 위한 것이었습니다" 라며 곧바로 철회해야 했습니다. 한 턴에 정보를 몰아넣는 오케스트레이터의 노드 단위 생성이 부정확한 조언과 어색한 대화 흐름으로 이어진 것입니다.
이 차이는 앞서 본 구조적 분석과 정확히 맞아떨어집니다. 지하 에이전트는 내장된 가중치를 통해 절차 전체를 통합적으로(holistically) 추론하고, 라우팅 실패가 구조적으로 0이며, 자연스러운 학습 데이터에서 빚어진 제약 없는 응답을 내놓습니다. 이 구조적 이점들이 약 70\times 의 파라미터 용량 격차를 메워 줍니다.
한계점 및 시사점
이 연구의 결론을 솔직하게 보면, 컴파일이 모든 면에서 프론티어를 이긴 것은 아닙니다. Information Accuracy처럼 폭넓은 세계 지식이 필요한 영역에서는 in-context 프론티어 모델에 여전히 뒤집니다. 또한 절차가 바뀌면 일시적 정보 갱신만으로 끝나는 in-context와 달리 재컴파일이 필요하므로, 절차가 시시각각 바뀌는 환경보다는 안정적으로 운영되는 업무 절차에 더 적합합니다.
그럼에도 이 논문의 메시지는 분명합니다. 개발자들이 컴파일을 외면하게 만든 세 장벽이 모두 통념보다 훨씬 작다는 것입니다. 품질 격차는 프론티어 대비 2 에서 13\% 로 작고, 비용 격차는 두 자릿수 배율로 실무자에게 유리하며 절차가 복잡할수록 더 벌어집니다. 유연성 격차는 패러다임의 전환이 아니라 한 번의 배포 사이클일 뿐입니다.
결국 이 연구는 무엇을 어디에 두어야 하는가에 대한 깔끔한 원칙을 제시합니다. 한 대화의 컨텍스트를 넘어 지속되어야 하는 절차적 지식은 가중치에 컴파일하는 것이 자연스러운 해법이며, "지속적인 구조는 가중치에, 일시적인 상태는 프롬프트에" 속한다는 것입니다. 290,000개의 스타가 향한 오케스트레이션의 시대에, 절차를 모델 깊숙한 곳으로 숨겨 보내자는 이 제안이 얼마나 호응을 얻을지 지켜볼 만합니다.
 Compiling Agentic Workflows into LLM Weights: Near-Frontier Quality at Two Orders of Magnitude Less Cost 논문
Compiling Agentic Workflows into LLM Weights: Near-Frontier Quality at Two Orders of Magnitude Less Cost 논문
WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Language Models 관련 논문
FireAct: Toward Language Agent Fine-tuning 관련 논문
 LangGraph GitHub 저장소
LangGraph GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()