On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
논문 소개
최근 몇 년 동안, LLM은 고품질 데이터 획득의 지속적인 문제를 해결하는 혁신적인 방법을 제공하면서 딥러닝 분야에서 큰 변화를 일으켰습니다. 고품질의 데이터가 좋은 성능의 NLP 모델을 구축하는데 중요한 역할을 하지만, 제한된 예산으로 구할 수 있는 데이터의 양은 한정되어 있을뿐만 아니라, 일부 데이터는 프라이버시 문제가 있어 사용하기 어렵습니다. 따라서 LLM을 사용한 합성 데이터(Synthetic Data)를 생성하는 것에 대한 관심은 높지만, 이렇게 생성한 합성 데이터는 얼마나 실제 데이터와 유사한지에 따라 전체적인 데이터셋과 모델 성능의 품질에 좋지 않은 영향을 미칠 수 있습니다.
하지만 합성 데이터는 모델 학습과 평가 과정을 자동화하여 인간의 개입을 최소화할 수 있으며, 이를 통해 더 넓은 범위의 응용 프로그램에 딥러닝 모델의 이점을 적용할 수 있습니다. 특히, 고품질의 합성 데이터는 다음 세대 LLM 개발에도 기여할 수 있습니다. 데이터 품질이 모델 학습의 효과성에 중요한 영향을 미친다는 점에서, LLM은 데이터를 적극적으로 "설계"하여 모델 학습의 효율성과 통제성을 크게 향상시킬 수 있습니다.
이번에 살펴볼 논문(On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey)은 현재까지의 LLM 기반 합성 데이터 생성, 큐레이션 및 평가의 현황을 종합적으로 연구하였습니다. LLM이 인간이 생성한 데이터를 대체하거나 보완할 수 있는 잠재력을 강조하면서, 관련 연구를 체계적으로 조직하여 기존 연구의 격차를 확인하고 향후 연구 방향을 제시합니다.
들어가며
문제 정의
이 논문에서는 사전 학습된 대규모 언어 모델 \mathcal{M} 을 사용하여 고품질 합성 데이터셋 \mathcal{D}_{gen} 을 생성하는 도전 과제에 대해서 살펴봅니다. 일반적으로는 아무것도 없는 상태에서 데이터를 생성하기 보다는 기존의 소규모 데이터나 라벨링되지 않은 입력 데이터셋 \mathcal{D}_{sup} 을 확장하기 위해 데이터 증강(Data Augmentation)을 수행하는 것이 일반적입니다. 이러한 데이터 증강 과정은 모델 \mathcal{M} 에 추론을 위해 사용한 프롬프트 p 에 의해 진행되며, 이러한 프롬프트 \mathcal{T} 는 질문답변(QA)이나 주석 달기 등과 같은 특정한 작업(Task)에 맞춰서 서로 다르게 정의됩니다. 지금까지 설명한 과정은 다음과 같이 표현할 수 있습니다:
\mathcal{D}_{gen} \leftarrow \mathcal{M}_{p}(\mathcal{T},\mathcal{D}_{sup})
합성 데이터 생성 작업 \mathcal{T} 는 주로 데이터 재작성, 질문 응답, 주석 달기 등의 생성 작업으로 구성됩니다. 데이터 주석 달기는 특히 널리 응용되는 합성 데이터 생성의 특수한 패러다임으로, 다양한 응용 분야에 걸쳐 광범위하게 적용될 수 있습니다.
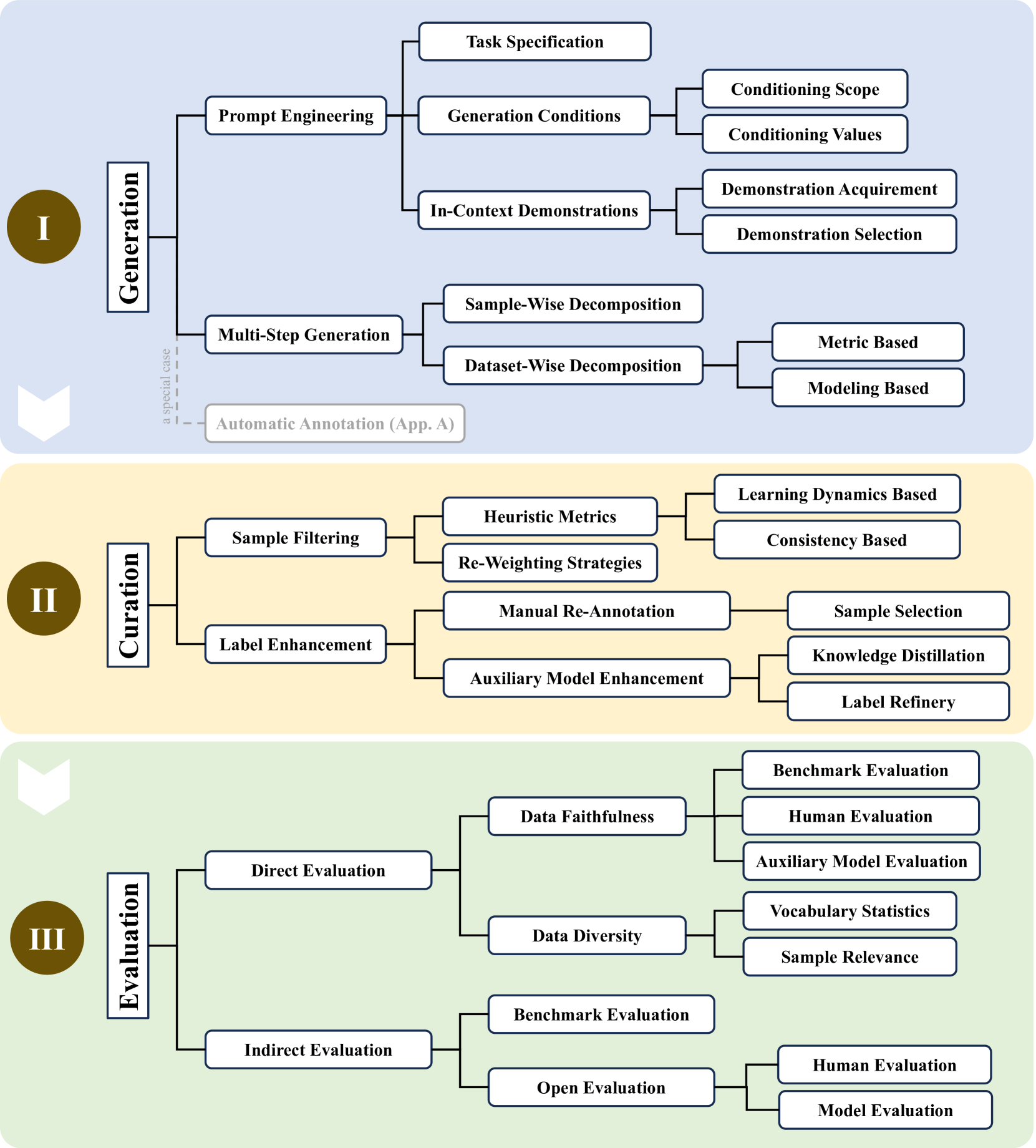
대규모 언어 모델(LLM) 기반 합성 데이터 생성, 큐레이션 및 평가의 분류 체계(Taxonomy)
생성 데이터 \mathcal{D}_{gen} 의 요구사항
고품질 합성 데이터를 생성하기 위해서는 데이터가 평가 지표와 긴밀하게 일치해야 합니다. 다양한 세부 작업(Downstream Task)에 따라 고품질 데이터의 기준이 다를 수 있지만, 대부분의 기존 연구에서는 신뢰성(Faithfulness)과 다양성(Diversity)이라는 두 가지 일반 요구사항을 충족하는 것을 목표로 합니다.
-
신뢰성(Faithfulness): 생성된 데이터가 논리적이고 문법적으로 일관되며, 사실 오류나 잘못된 라벨, 관련 없는 내용 등의 문제가 없어야 한다는 것을 의미합니다. LLM은 종종 환각 문제로 인해 노이즈가 포함된 결과를 생성할 수 있으며, 이는 특히 길고 복잡하거나 도메인 특화된 데이터를 생성할 때 더 두드러집니다.
-
다양성(Diversity): 생성된 데이터가 실제 데이터의 다양성을 반영하여 텍스트 길이, 주제, 작성 스타일 등의 차이를 나타내야 한다는 것을 의미합니다. 이는 모델 학습 또는 평가 중 과적합과 편향을 방지하기 위해 중요합니다. 하지만 합성 데이터를 생성하는 모델 \mathcal{M} 에 내재된 편향(inherent bias)으로 인해 통제되지 않은 생성 내용은 종종 단조롭고, 이는 생성된 데이터의 적용 가능성을 제한할 수 있습니다.
이러한 요구사항들을 충족하기 위해 다양한 기법이 연구되고 있으며, 다음의 워크플로우에서 각 방법들이 이 문제를 어떻게 해결하는지 살펴보겠습니다.
일반적인 워크플로우(Generic Workflow)
일반적인 워크플로우는 생성, 큐레이션 및 평가의 세 가지 주요 단계를 포함합니다. 이러한 단계는 특정 응용 프로그램의 요구 사항을 충족하는 고품질 합성 데이터를 생산하기 위해 협력합니다.
-
데이터 생성: LLM을 사용하여 신중하게 설계된 프롬프트를 기반으로 합성 데이터를 생성합니다. 프롬프트 엔지니어링과 다단계 생성과 같은 기술을 사용하여 생성된 데이터의 품질과 다양성을 향상시킵니다.
-
데이터 큐레이션: 생성된 데이터를 필터링하여 저품질 샘플을 제거하고 레이블을 향상시킵니다. 휴리스틱 메트릭, 샘플 재가중 및 레이블 정제 기술을 사용하여 데이터셋의 전반적인 품질을 보장합니다.
-
데이터 평가: 큐레이션된 데이터를 직접 및 간접 방법을 사용하여 신뢰성과 다양성을 평가합니다. 이를 통해 데이터가 다운스트림 작업에 적합하고 필요한 기준을 충족하는지 확인합니다.
데이터 생성과 큐레이션, 평가의 각 단계들에 대해서 하나씩 살펴보겠습니다.
데이터 생성(Data Generation) 단계
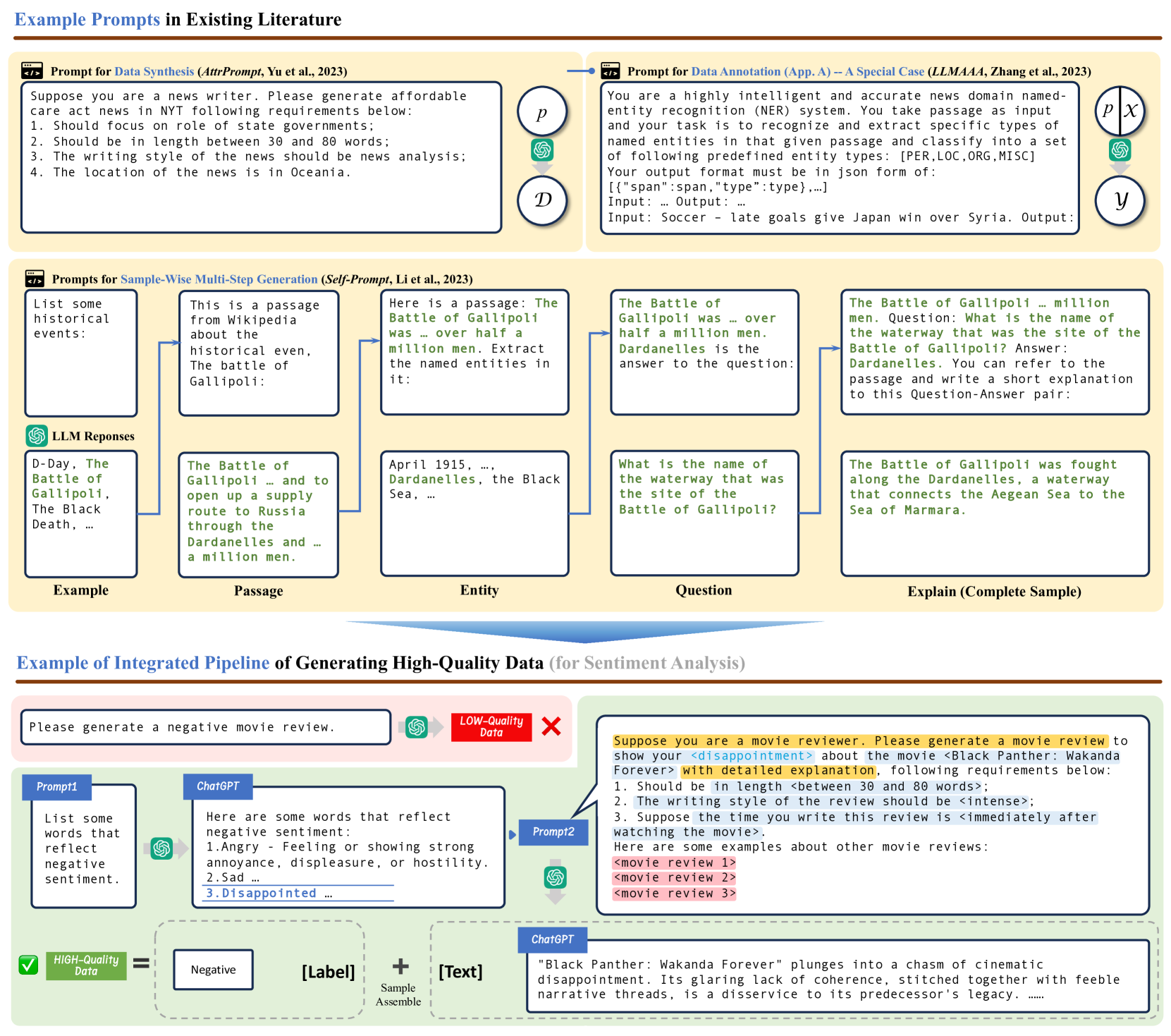
효과적인 합성 데이터 생성의 간략한 예시. 작업 명세(Task Specification)은 노란색, 작업 조건(Condition)은 파란색, 그리고 상황에 맞는 데모(In-Context Demonstration)는 빨간색으로 강조 표시되어 있으며,
<~> 표시는 전환 가능한 내용 표시
프롬프트 엔지니어링(Prompt Engineering), \mathcal{p}
LLM의 가장 큰 장점 중 하나는 사용자의 지시(instruction)를 따르는 능력입니다. 이는 합성 데이터 생성을 위한 큰 장점으로 작용하며, 프롬프트 엔지니어링을 통해 LLM의 이러한 특성을 최대한 활용할 수 있습니다. 프롬프트 엔지니어링은 LLM가 더 충실하고 다양한 데이터를 생성하도록 유도하는 데 사용됩니다.
경험적으로 효과적인 프롬프트는 일반적으로 3가지 핵심 요소(key elements)를 갖습니다. 각각은 작업 명세(task specification, e_{task}), 2) 생성 조건(generation condition, e_{condition}), 그리고 3) 예시(in-context demonstration, e_{task}) 이며, 이러한 핵심 요소들을 포함하는 템플릿 E 를 통해 작성한 프롬프트 p 는 다음과 같이 표현할 수 있습니다. 이 때, 생성 작업 \mathcal{T} 와 참고할 데이터셋(support dataset) \mathcal{D} 모두 프롬프트의 설계에 영향을 미칩니다:
p(\mathcal{T}, \mathcal{D}) \leftarrow E(e_{task}, e_{condition}, e_{demo})
이제 프롬프트 디자인 시에 고려해야 할 사항들을 살펴보겠습니다:
-
작업 명세(Task Specification): LLMs가 데이터 생성을 위한 올바른 컨텍스트를 설정하도록 돕습니다. 인간 작업자에게 데이터를 생성하기 위해 작업 목적이나 데이터에 대한 설명, 기타 배경 지식 등과 같은 필요한 맥락을 설명하는 것과 마찬가지로 LLM에게 이러한 설명을 하는 것은 매우 중요합니다. 예를들어,
"당신이 {ㅇㅇㅇ}라고 가정하십시오(suppose you are a {xxx}"와 같은 간단한 서두는 LLM 출력의 품질을 크게 향상시킬 수 있습니다. LLM이 수행해야 하는 작업에 대한 상세한 명세는 문맥 이해 및 데이터 생성 시에 특정한 분야의 지식(Domain Knowledge)가 필요한 경우 특히 중요합니다. 예를 들어, 외부 지식 그래프(External Knowledge Graph) 등을 활용하는 경우, LLM은 특정 도메인 주제에 대한 지식을 확보하여 생성하는 데이터의 충실도와 복잡성을 효과적으로 향상할 수 있습니다. -
조건부 프롬프트(Conditional Prompt): 조건부 프롬프트는 합성 데이터 생성 시 다양성을 확보하는데 중요합니다. 특히 높은 디코딩 온도(high decoding temperature)로 데이터 생성 시, LLM이 반복적인 출력이 발생하는 경우가 많기 때문에 일련의 조건을 키-값의 쌍(Key-Value Pair)로 명시하여 프롬프트에 추가합니다. 이를 통해 생성 결과 데이터의 유형을 명확하고 구체적으로 지정할 수 있습니다. 이러한 조건의 범위(Conditional Scope, \{c_1, c_2, ... c_n\}) 로는 주제나 길이, 스타일 등이 있을 수 있으며, 각 조건별로 구체적인 값을 입력합니다. 필요한 경우 외부의 지식 그래프를 통해 각 조건에 대해 알맞은 값들을 찾아서 입력하거나, 다양한 하위 주제들로 구성된 개념 트리(Concept Tree)를 사용하여 다양한 데이터를 생성하도록 합니다. 이러한 조건-값 쌍은 다음과 같이 표현할 수 있습니다:
e_{condition} = \{(c_1, v_1), (c_2, v_2), .., (c_n, v_n)\}
-
문맥 내 학습(In-Context Learning): LLM의 내재된 편향성(inherent bias) 때문에 단순히 과제를 명시하고 조건부 프롬프트를 작성하는 것만으로 고품질의 데이터를 생성하기는 어려울 수 있습니다. 이러한 경우 간단하면서도 효과적인 전략은 몇 가지 예시를 제공하는 것입니다. LLM은 주어진 예시들에서 암묵적 패턴을 파악하고 이를 통해 생성된 데이터의 충실도를 크게 향상시킬 수 있습니다. 하지만, 프롬프트의 길이와 데이터의 정합성과 같은 제약들 때문에 어떠한 예시를 제공하느냐가 매우 중요합니다. 예를 들어, 샘플을 무작위로 선택하는 것보다는 임베딩 공간에서 유사도를 기반으로 일관된 샘플을 선정하는 등의 프로세스를 추가하는 경우 생성 데이터의 품질이 높아질 수 있습니다.
지금까지 살펴본 프롬프트 엔지니어링(Prompt Engineering)과 관련하여, 본 논문에서 참고한 연구들은 다음과 같습니다:
https://www.pnas.org/doi/abs/10.1073/pnas.2305016120
여러 단계에 걸친 생성(Multi-Step Generation)
복잡한 데이터를 처리할 때는 하나의 프롬프트로 전체 데이터를 생성하는 것이 현실적이지 않을 수 있습니다. 이러한 경우에는 여러 단계에 걸친 생성 기법을 사용하는 것이 효과적입니다. 다단계 생성(Multi-Step Generation) 기법은 전체 생성 과정을 더 간단한 하위 작업들로 분해한 뒤, 각 단계별로 데이터를 생성하는 방법입니다. 예를 들어, 긴 텍스트나 논리적 추론이 필요한 데이터의 경우 샘플을 더 작은 조각으로 나누어 각 부분을 개별적으로 생성한 다음, 중간 단계에서의 생성 결과들을 이후 단계의 생성시 조건(task condition)으로 사용하는 식입니다. 이러한 다단계 생성을 k 번 수행한다고 했을 때, 다음과 같이 표현할 수 있습니다( i 는 수행 중인 단계를 나타내며, D_0 은 주어진 샘플 데이터셋(Support Dataset) D_{sup} 입니다.):
\mathcal{D}_i \leftarrow \mathcal{M}^{i}_{p_i}(\mathcal{T}_i, \mathcal{D}_{0:i-1}), i = 1,2, ... ,k
일반적으로 여러 단계에 걸친 생성 전략에는 2가지 전략들이 있습니다. 각각은 샘플 단위 분해(Sample-Wise Decomposition)와 데이터셋 단위 분해(Dataset-Wise Decomposition)이며, 각 전략은 다음과 같습니다:
-
샘플 단위 분해(Sample-Wise Decomposition): 샘플 단위 분해는 긴 텍스트나 논리적 추론과 같은 문제를 해결할 때 시도할 수 있는 가장 간단한 접근 방식입니다. 샘플 단위 분해는 주어진 샘플을 더 작은 덩어리로 나누고, 한 번에 각 샘플의 일부만 생성하는 방식입니다. 이러한 생성 과정의 반복인 이전에 생성한 콘텐츠에 따라 조절할 수 있으므로, 예를들어 대화 데이터를 생성할 때 LLM이 어시스턴트와 사용자의 역할을 번갈아 수행하면서 문맥에 따라 서로 응답하도록 유도할 수 있습니다. 이 전략을 통해 LLM이 요구사항을 더 잘 따르고 더 충실한 데이터를 생성하도록 돕습니다. 생각의 사슬(CoT, Chain-of-Thoughts)은 대표적인 샘플 단위 분해 전략 중 하나입니다. 이 전략을 사용하여 k 번에 걸쳐 생성하는 데이터 \mathcal{D}_{gen} 은 다음과 같이 표현할 수 있습니다:
\mathcal{D}_{gen} = (\mathcal{D}_1, \mathcal{D}_2, ..., \mathcal{D}_k)
-
데이터셋 단위 분해(Dataset-Wise Decomposition): 데이터셋 단위 분해는 전체 데이터셋의 다양성(diversity)과 도메인 커버리지(domain coverage)를 보장하기 위해 각 단계에서 조건을 동적으로 조정하는 전략입니다. 생성 시 각 단계에서 사용하는 조건을 동적으로 조정하여 전체 데이터셋이 올바른 방향으로 성장할 수 있도록 합니다. 예를들어, 도메인 공간을 트리 구조로 모델링한 뒤, 트리 탐색과 함께 각 단계별로 생성된 데이터를 지속적으로 개선하여 생성된 데이터의 전문화와 도메인 커버리지를 모두 촉진합니다. 이러한 과정은 다음과 같이 표현할 수 있습니다:
\mathcal{D}_{gen} = \bigcup^k_{i=1}\mathcal{D}_i
지금까지 살펴본 다단계 생성(Multi-Step Generation)과 관련하여, 본 논문에서 참고한 연구들은 다음과 같습니다:
데이터 큐레이션(Data Curation) 단계
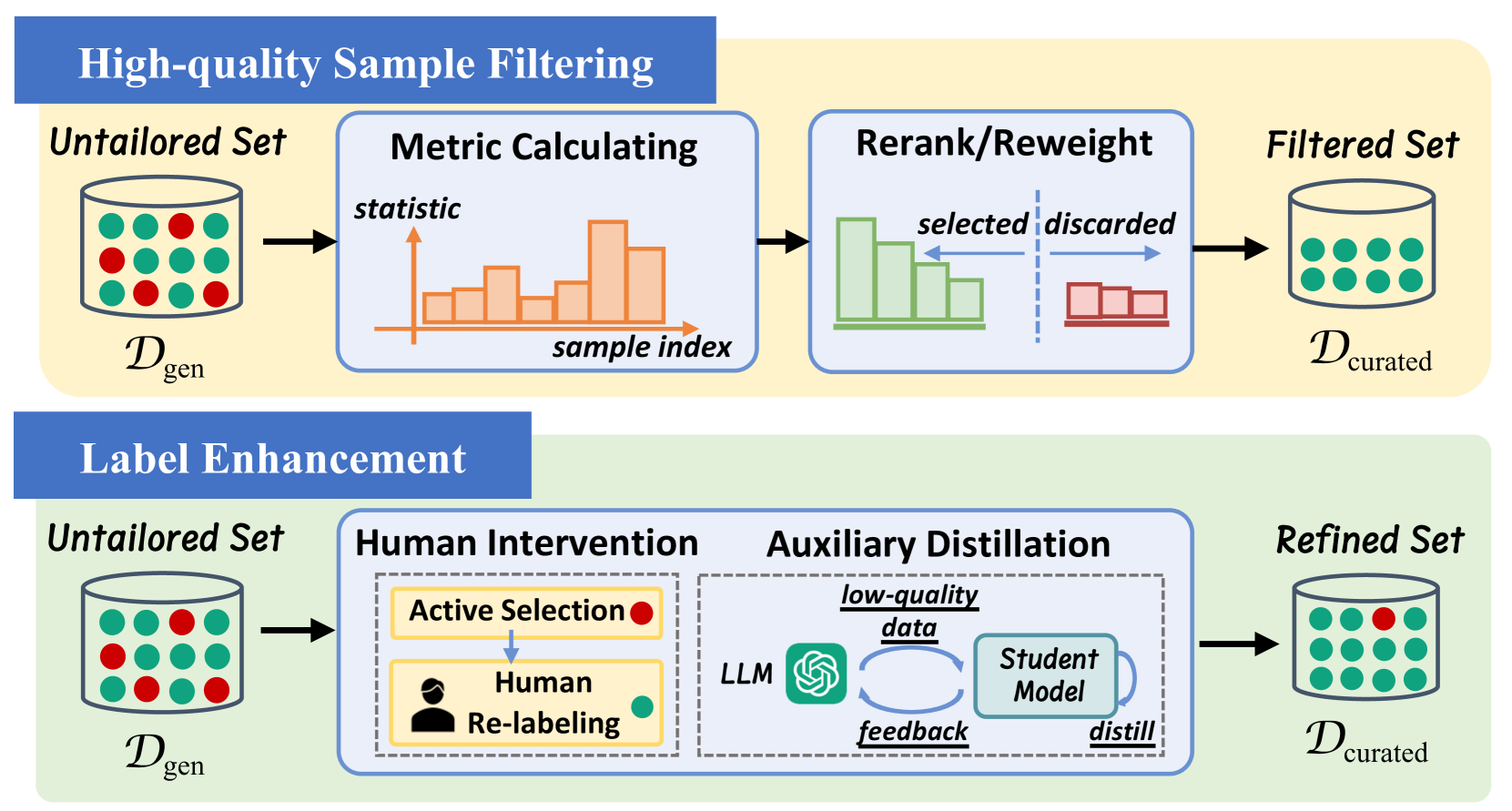
데이터 큐레이션(Data Curation)의 두 가지 주요한 접근 방식: 고품질 샘플 필터링(High-Quality Sample Filtering)과 레이블 강화(Label Enhancement)
고품질 샘플 필터링(High-Quality Sample Filtering)
이전 단계를 통해 생성한 데이터셋에서 다수의 노이즈를 비롯하여 무가치하거나 유해한 샘플이 포함될 수도 있습니다. 이렇게 잘못된 샘플들이 포함되는 경우 모델 학습에 부정적인 영향을 미칠 수 있습니다. 따라서, 이러한 샘플을 걸러내어 생성한 전체 데이터셋 \mathcal{D}_{gen} 보다 유용한 일부 부분 집합 \mathcal{D}_{curated} 를 얻는 것이 중요합니다. 이러한 샘플링 방법에는 휴리스틱한 기준(heuristic criteria)을 활용하는 방식과 가중치 재조정 함수(re-weighting function)를 설계하여 순위를 매기는 방식이 있습니다.
-
휴리스틱한 기준(Heuristic Metrics)을 사용한 샘플링: 이 방식은 샘플링을 위한 신뢰도 점수(confidence score)나 영향력 함수(influence function)와 같은 적절한 기준을 설계하는 것이 중요합니다. 이렇게 기준을 설계한 뒤 샘플들을 이 기준에 맞추어 정렬을 하고, 낮은 품질의 샘플을 제거하여 고품질의 데이터를 얻습니다. 이러한 기준을 생성할 때에는 논리적 일관성, 문법적 정확성, 태스크 관련성 등을 사용하며, 사전 학습된 모델이나 도메인 전문가의 피드백을 활용하는 방식으로 동작합니다.
-
가중치 재조정 함수(Sample Re-Weighting)를 사용한 샘플링: 이 방식은 모든 데이터는 가치있지만, 중요도가 다르다고 생각하고 접근하는 방식입니다. 따라서, 상세 작업(Downstream Task)에서 활용 시에 영향력이 있거나 올바르게 주석이 달린 샘플에 더 큰 가중치를 부여하여 샘플링합니다. 예를들어, 서로 다른 레이블 간의 미묘한 차이를 구분하기 위해 차별적 메타 학습 목표(Discriminative Meta-learning Objective)를 설계하는 방식 등이 여기에 해당합니다.
지금까지 살펴본 고품질 샘플 필터링(High-Quality Sample Filtering)과 관련하여, 본 논문에서 참고한 연구들은 다음과 같습니다:
레이블 강화(Label Enhancement)
생성된 데이터의 레이블 정확성은 모델 성능에 중요한 영향을 미칩니다. 생성 과정에서 잘못된 레이블이 달린 샘플은 학습 과정에서 모델을 잘못된 방향으로 유도할 수 있습니다. 확증 편향(Confirmation Bias)로 인해 생성 시점에 모델이 스스로의 실수를 식별하는 것은 현실적으로 어렵습니다. 이를 방지하기 위해 잘못된 주석을 수정하는 레이블 강화를 통한 데이터 큐레이션을 진행할 수 있습니다. 레이블 강화에는 인간의 개입(Human Intervention)을 통한 방식과 보조 모델(Auxiliary Model)을 사용하는 방식이 있습니다.
-
인간의 개입(Human Intervention)을 통한 레이블 강화: 가장 간단하면서도 효과적인 전략은 잘못된 레이블을 사람이 다시 작성하는 것입니다. 이러한 경우 라벨링 비용이 상당하게 발생할 수 있으며, 실제 배포 시에는 비현실적일 수 있다는 단점이 있습니다. 따라서, (앞에서 살펴본) 사람이 작성한 작업 명세(task specification)와 LLM이 생성한 데이터를 비교하는 등의 방법을 통해 가장 신뢰도가 낮은 샘플들을 먼저 선정하여 작업하는 방식 등이 제안되었습니다.
-
보조 모델(Auxiliary Model)을 사용한 레이블 강화: 라벨 작업 비용을 낮추기 위해서는 인간이 개입하지 않는 좀 더 실용적인 패러다임(pragmatic human-free paradigm)이 개발되었습니다. 사전 학습된 대형 모델을 통해 샘플의 품질을 높이는 지식 증류(Knowledge Distillation)와 같은 방법이 있으며, 이를 통해 생성된 샘플의 레이블을 정제하고 잘못된 주석을 수정할 수도 있습니다. 예를들어, 데이터 분할 학습(data-split training)과 교차 파티션 라벨링(cross-partition labeling)을 통해 다단계 증류 파이프라인을 설계하여 노이즈가 많은 샘플들에 오버피팅되는 것을 방지할 수 있습니다. LLM의 능력과 가용성이 확대됨에 따라 이러한 라벨 정제용 보조 학생 모델(auxiliary student model)을 도입이 점차 중요해지고 있습니다.
지금까지 살펴본 레이블 강화(Label Enhancement)와 관련하여, 본 논문에서 참고한 연구들은 다음과 같습니다:
데이터 평가(Data Evaluation) 단계
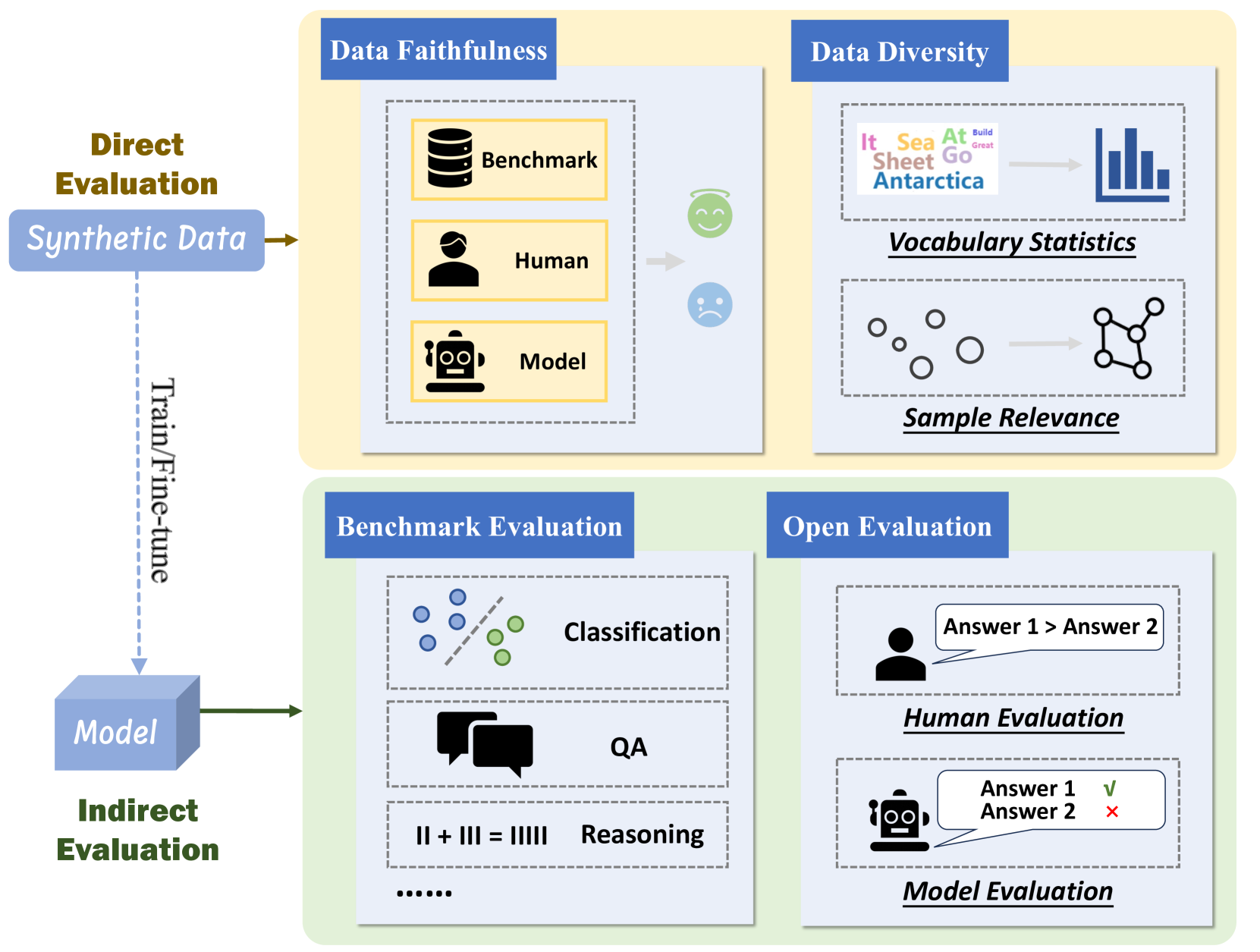
데이터 평가(Data Evaluation)의 두가지 주요한 접근 방식: 직접 평가(Direct methods)와 간접 평가(Indirect methods)
직접 평가(Direct Evaluation)
합성 데이터를 활용하기 전, 데이터가 잘 생성이 되었는지를 먼저 평가하는 것이 중요합니다. 직접 평가는 데이터의 논리적 일관성, 문법적 정확성, 태스크 관련성 등을 평가하는 것으로, 생성된 데이터의 품질을 즉시 확인할 수 있는 장점이 있습니다. 이러한 직접 평가는 크게 데이터 충실도(Data Faithfulness)와 데이터 다양성(Data Diversity)의 관점에서 평가할 수 있습니다.
-
데이터 충실도(Data Faithfulness) 관점에서의 평가: 충실도 관점의 가장 간단한 아이디어는 사람에게 평가를 받는 것입니다. 생성된 데이터의 일부 샘플을 인간 전문가에게 제공하여 적절한지 여부를 판단하고, 이에 따라 전체적인 데이터셋의 생성 품질을 추정할 수 있도록 하는 것입니다. 이론적으로 표본의 크기가 클수록 추정 결과가 정확하지만 비용이 많이 들기 때문에 데이터 큐레이션(Data Curation)에서 살펴봤던 것처럼 보조 모델을 활용할 수도 있습니다.
-
데이터 다양성(Data Diversity) 관점에서의 평가: 다양성 관점에서는 샘플에 포함된 어휘 통계(Vocabulary Statistics)와 샘플들 간의 관련성 계산(Sample Relevance Calculation)을 통해 정량화할 수 있습니다. 어휘 통계는 생성된 데이터셋에서 추출한 어휘집의 크기(vocabulary size)와 N-그램 빈도(N-gram frequency)를 활용하는 방식으로, 의미론적인 정보를 포착하는데는 어려움이 있습니다. 이를 해결하기 위해 코사인 유사도(cosine similarity) 등을 사용하여 샘플들 간의 상관관계를 측정하는 방식을 사용할 수 있습니다.
지금까지 살펴본 직접 평가(Direct Evaluation)와 관련하여, 본 논문에서 참고한 연구들은 다음과 같습니다:
간접 평가(Indirect Evaluation)
간접 평가는 합성 데이터로 학습된 모델의 성능을 평가하여 생성 데이터의 품질을 간접적으로 측정하는 방법입니다. 합성 데이터로 학습한 모델이 기존 데이터셋으로 학습된 모델과 비교하여 유사하거나 더 나은 성능을 보이는 경우, 생성된 데이터의 품질이 높다는 것을 의미합니다. 이러한 간접 평가 시에는 학습된 모델의 성능을 벤치마크로 평가(Benchmark Evaluation)하는 방법과 개방형 평가(Open Evaluation) 방법 등이 있습니다.
-
벤치마크를 사용하여 평가(Benchmark Evaluation)하는 방법: 최종적으로 모델을 적용하는 세부 작업(downstream task)과 관련한 벤치마크를 사용하여 평가하는 방법입니다. 예를 들어, TruthfulQA와 같은 벤치마크를 사용하여 모델이 참과 거짓을 잘 식별하는지를 평가해볼 수 있습니다. 또는, NIV2를 사용하여 여러 작업들에 걸쳐 언어 이해력과 추론 능력 등을 평가할 수 있습니다.
-
개방형으로 평가(Open Evaluation)하는 방법: 개방형 벤치마크(Open-ended Benchmark)의 경우에는 표준화된 답변이 없기 때문에 답변을 평가하기 쉽지 않습니다. 따라서 답변을 평가하기 위해 사람이나 보조 모델이 필요합니다. 예를 들어 Vicuna 모델이 생성한 샘플들을 평가하기 위해 GPT-4 기반의 자동 평가 프레임워크를 도입할 수 있습니다. 하지만, 평가에 사용하는 모델이 세부 작업에 충분한 지식이 부족한 경우에는 효과적인 평가가 어려울 수도 있습니다. 따라서 평가 목적으로 모델을 미세 조정(finetuning)하는 것이 필요할 수 있으나, 이는 아직 더 연구가 필요한 방법입니다.
간접 평가를 위해 사용하는 주요한 벤치마크 데이터셋(Benchmark Dataset)들은 다음과 같은 것들이 있습니다:
| Type | Benchmark Dataset | Subdataset Quantity | Partial Subdataset | Task | Ability | Domain/Data Source |
|---|---|---|---|---|---|---|
| Classification | SMS spam | 1 | SMS spam | Text Classification | Spam Detection | SMS |
| Classification | AG News | 1 | AG News | Text Classification | Topic Classification | News |
| Classification | IMDb | 1 | IMDb | Text Classification | Binary Sentiment Classification | Review |
| Classification | GoEmotions | 1 | GoEmotions | Text Classification | Sentiment Classification | Reddit Comments |
| Classification | CLINC150 | 1 | CLINC150 | Text Classification | Intent Detection | Human Annotation |
| Classification | BANKING77 | 1 | BANKING77 | Text Classification | Intent Detection | Bank |
| Classification | FewRel | 1 | FewRel | Text Classification | Relation Classification | Wikipedia |
| Classification | GLUE | 7 | QNLI | Natural Language Inference | Recognizing Textual Entailment | Wikipedia |
| RTE | Natural Language Inference | Recognizing Textual Entailment | News and Wikipedia | |||
| QA | AdversarialQA | 1 | AdversarialQA | Question Answering | Reading Comprehension | Wikipedia |
| QA | TruthfulQA | 1 | TruthfulQA | Question Answering | Honestness | Hard Data |
| Reasoning | MATH | 1 | MATH | mathematical reasoning | Complex Reasoning | Math |
| Reasoning | ToolBench | 1 | ToolBench | Trajectory Planning | Tool manipulation | Tool |
| - | NIV2 | 1616 | - | - | Language Understanding & Reasoning | Benchmark Collection/Human Annotation |
| - | BIG-bench | 204 | - | - | Language Understanding & Reasoning | Human Annotation |
지금까지 살펴본 간접 평가(Indirect Evaluation)와 관련하여, 본 논문에서 참고한 연구들은 다음과 같습니다:
이후 연구 방향
복잡한 태스크 분해
현재 다중 단계 생성 알고리즘은 모델의 태스크 요구사항 이해에 의존합니다. 향후에는 더 체계적인 조사와 계획 능력을 활성화하는 연구가 필요합니다. 이는 복잡한 데이터를 더 효과적으로 생성하고, 모델의 성능을 향상시키는 데 중요한 역할을 할 것입니다. 특히, 복잡한 데이터의 생성 과정에서 발생할 수 있는 다양한 문제를 해결하기 위해, 보다 정교한 태스크 분해 전략이 필요합니다.
지식 강화
LLM의 지식은 편향적일 수 있습니다. 이를 극복하기 위해 외부 지식 그래프와의 연결 또는 웹사이트로부터의 증강을 통한 자동 조건 제어가 필요합니다. 이는 LLM의 지식 기반을 확장하고, 보다 정확하고 신뢰할 수 있는 데이터를 생성하는 데 기여할 것입니다. 또한, 외부 지식의 통합은 모델의 학습 효과를 높이고, 다양한 도메인에서의 응용 가능성을 확장하는 데 도움이 될 것입니다.
대규모 언어 모델(LLM)과 소형 언어 모델(sLM) 간의 시너지
데이터 큐레이션을 위한 소형 도메인 모델의 활용이 중요해질 것입니다. 다양한 협업 모드를 탐구하여 데이터 생성 품질을 향상시키는 연구가 필요합니다. 대형 모델과 소형 모델 간의 협업을 통해, 데이터 생성 과정의 효율성을 높이고, 생성 데이터의 품질을 향상시킬 수 있습니다. 이를 통해, 더 나은 성능의 모델을 개발하고, 다양한 응용 분야에서의 적용 가능성을 확장할 수 있습니다.
인간-모델 협업
데이터 생성에서 인간의 개입은 필수적입니다. 인간-기계 협업을 위한 상호작용 시스템을 설계하여 효율적인 데이터 생산을 도모해야 합니다. 이는 인간의 전문 지식을 활용하여 데이터의 품질을 높이고, 생성 과정의 효율성을 극대화하는 데 기여할 것입니다. 또한, 인간-모델 협업을 통해 생성된 데이터의 신뢰성을 보장하고, 모델의 성능을 지속적으로 향상시킬 수 있습니다.
그 외 참고 연구
데이터 어노테이션(Data Annotation)
논문에서는 주로 일반적인 데이터 합성을 위한 기법들을 다뤘습니다. 어노테이션은 특정 샘플을 합성 조건으로 입력하는 합성의 기법 중 하나로 볼 수도 있지만, 일부만 사람으로 하여금 라벨링을 하게 하는 선택적 어노테이션(Selective Annotation)과 같은 기법에 대해서는 더 살펴볼 필요가 있습니다. 선택적 어노테이션의 핵심은 비싸지만 고품질의 사람이 생성한 데이터와 경제적이지만 상대적으로 낮은 품질의 LLM이 생성한 데이터 사이의 "비용 효율적인(cost-effective)" 분포를 정의하는 것입니다. 논문에서 살펴본 선택적 어노테이션에 대한 연구들은 다음과 같습니다:
https://www.sciencedirect.com/science/article/pii/S156625352300177X
튜닝 기법(Tuning Techniques)
모델 미세조정(Finetuning) 및 소프트 프롬프팅(Soft Prompting)을 비롯한 다양한 튜닝 기법들 또한 주요한 연구 분야입니다. 이러한 연구들은 생성 성능을 개선하는데 효과적이지만, LLM의 내부 구조에 대해서는 더 연구해야 할 부분이 있습니다. 논문에서 살펴본 튜닝 기법에 대한 기존의 연구들은 다음과 같습니다:
원문
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()