'대규모 언어 모델(LLM)을 위한 데이터셋들에 대한 종합적인 연구' 소개

대규모 언어 모델(LLM)은 자연어 처리와 인공지능 연구의 핵심 요소로 자리잡고 있으며, 그 성능은 사용된 데이터셋에 크게 의존합니다. LLM의 성능을 극대화하기 위해서는 고품질의 데이터셋이 필수적이며, 다양한 도메인과 태스크에 적합한 데이터셋이 필요합니다. 하지만 지금까지 LLM에서 사용되는 데이터셋에 대한 체계적인 연구가 부족했던 상황입니다. 대규모 언어 모델을 위한 데이터셋: 종합적인 연구(Datasets for Large Language Models: A Comprehensive Survey) 라는 제목의 이 논문은 LLM 데이터셋을 다각도로 분석하고 분류하여 연구자와 개발자에게 중요한 참고자료를 제공합니다. 다양한 언어와 도메인에 걸쳐 방대한 양의 데이터를 다루며, 현재와 미래의 연구 방향성을 제시하고 있습니다.
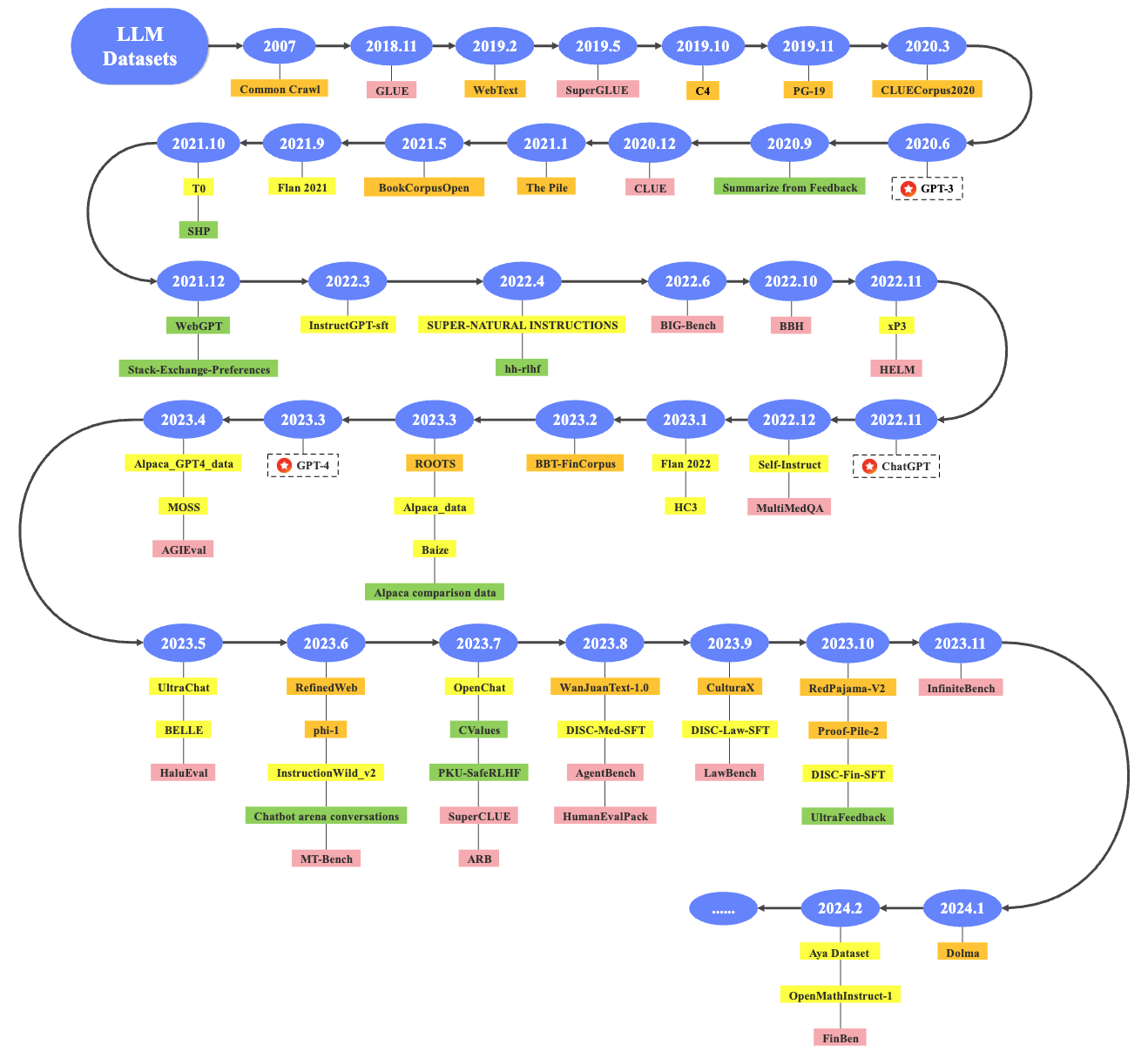
이 논문은 LLM 발전에 중요한 역할을 하는 데이터셋에 대한 종합적인 분석을 제공하고 있습니다. 최근 몇 년간 OpenAI의 ChatGPT, Meta의 LLaMA, Google의 PaLM 등과 같은 다양한 LLM이 공개되었으며, 이들은 수십억 개에서 수백억 개의 파라미터를 갖춘 모델들입니다. 이들 모델은 대규모 데이터를 기반으로 학습되어 자연어 이해 및 생성 능력을 크게 향상시켰습니다. 그러나 이러한 모델의 성공 이면에는 그 기반이 되는 데이터셋이 있습니다. 모델이 학습한 데이터셋의 크기, 품질, 다양성이 모델의 성능을 크게 좌우하기 때문에, 고품질의 데이터셋을 수집하고 정제하는 과정은 매우 중요합니다.
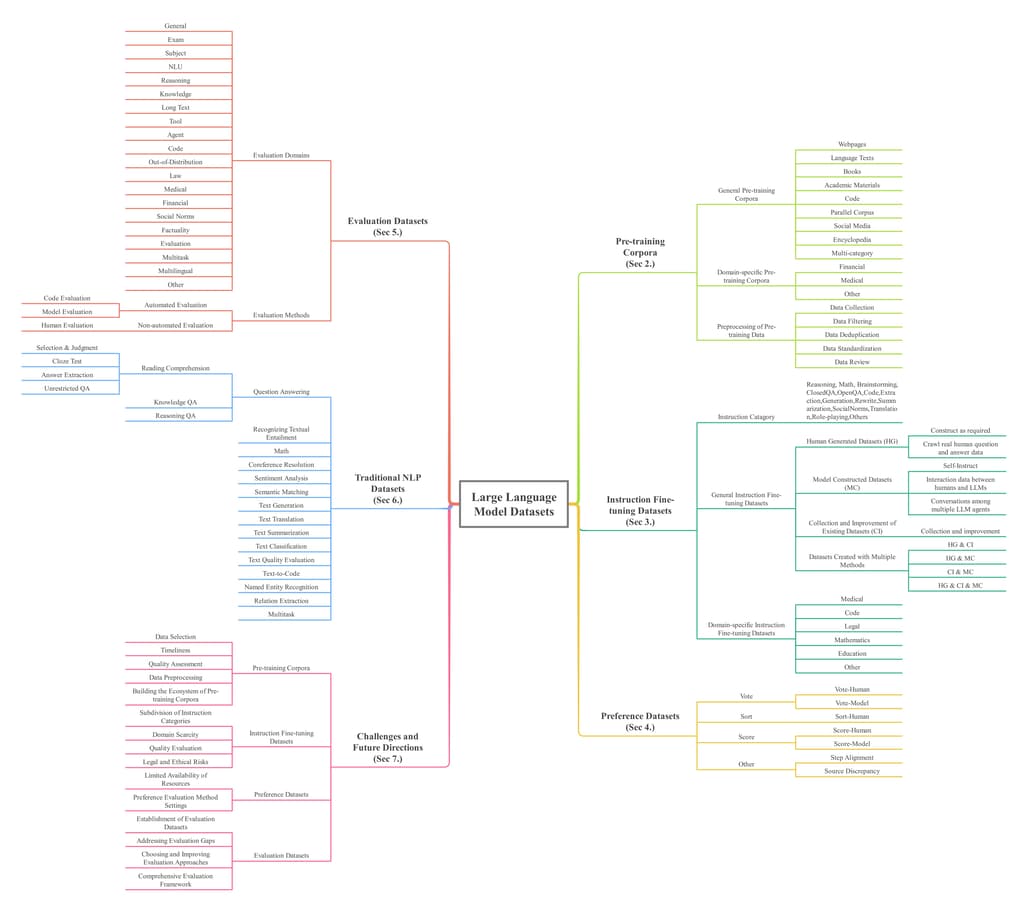
LLM에서 사용되는 데이터셋은 크게 다섯 가지로 분류할 수 있습니다. 첫 번째는 사전 학습 데이터셋으로, 웹페이지, 서적, 소셜 미디어, 코드와 같은 방대한 텍스트 데이터를 포함합니다. 두 번째는 지시 미세 조정 데이터셋으로, 특정 태스크에 맞춘 질문 및 답변 데이터를 통해 모델의 성능을 높입니다. 세 번째는 선호도 데이터셋으로, 모델이 더 나은 답변을 생성하도록 인간의 선호도 데이터를 반영합니다. 네 번째는 평가 데이터셋으로, 모델의 성능을 다각도로 평가하기 위한 데이터셋입니다. 마지막으로 전통적인 NLP 데이터셋은 기존의 자연어 처리 연구에서 사용되던 질문 응답, 감정 분석, 텍스트 요약 등 다양한 태스크를 다룹니다.
사전 학습 코퍼스(Pre-training Corpora)

사전 학습 코퍼스(Pre-training Corpora) 은 LLM이 방대한 양의 텍스트 데이터를 학습하여 자연어 처리 능력을 얻는 데 사용됩니다. 이 데이터셋은 웹페이지, 서적, 소셜 미디어, 코드, 학술 자료 등 다양한 출처에서 수집된 데이터를 포함하며, 각 출처마다 고유한 특성과 역할이 있습니다. 예를 들어, 웹페이지 데이터는 방대한 정보와 다양한 주제를 다루고 있어 모델이 일반적인 언어 능력을 학습하는 데 유리합니다. 반면, 서적 데이터는 문법적으로 더 정확하고 길이가 긴 텍스트를 제공하여 모델이 더 깊이 있는 언어 이해 능력을 학습할 수 있도록 돕습니다.
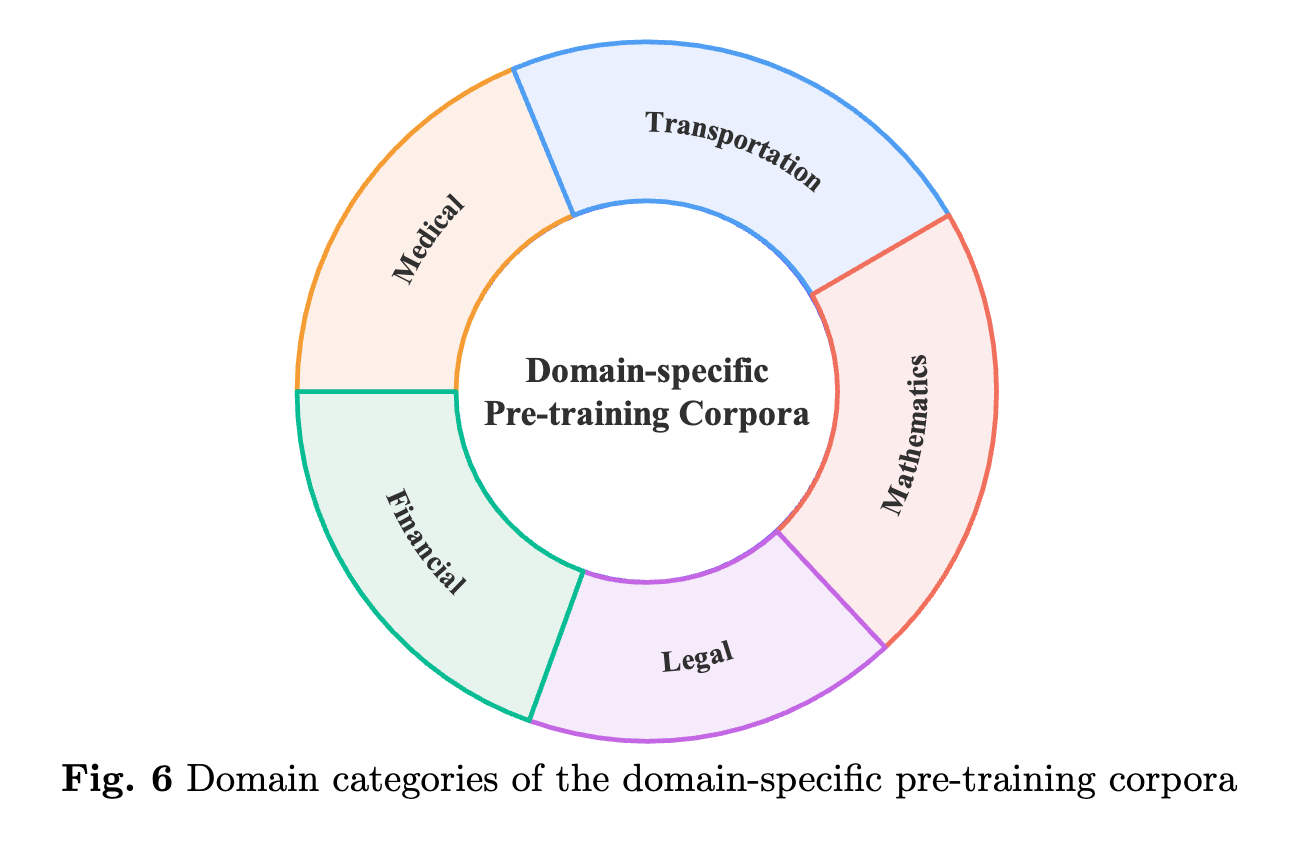
사전 학습 데이터셋은 또한 특정 도메인에 특화된 데이터를 포함할 수 있습니다. 예를 들어, 금융, 의료, 법률과 같은 도메인에서는 해당 분야의 전문 용어와 문서 형식이 중요하게 다뤄지며, 이를 통해 모델이 특정 분야에서 높은 성능을 발휘할 수 있게 됩니다. 이러한 도메인 특화 데이터셋은 모델이 더 나은 성능을 발휘할 수 있도록 돕는 중요한 역할을 합니다. 예를 들어, 의료 도메인의 경우, PubMed Central과 같은 데이터셋이 사용되며, 여기에는 생의학 분야의 논문과 연구 결과가 포함됩니다.
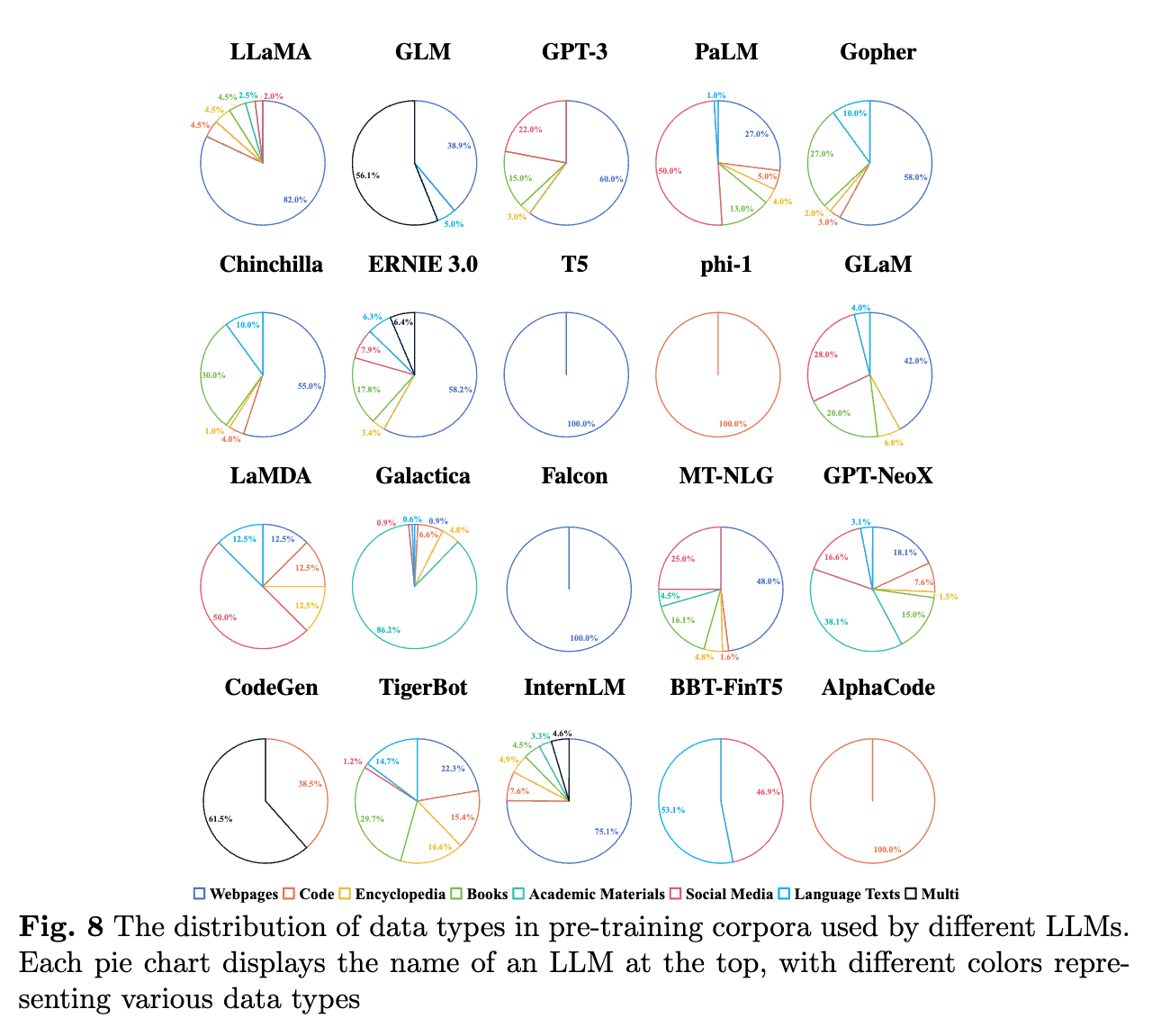
사전 학습 데이터셋은 크기뿐만 아니라 데이터의 품질도 매우 중요합니다. 대규모 데이터셋을 사용한다고 해서 항상 성능이 좋은 것은 아니며, 데이터의 품질, 특히 노이즈나 중복된 데이터의 제거가 필수적입니다. 데이터 필터링과 전처리 과정에서 저품질 데이터를 제거하고, 중복 데이터를 제거하여 데이터셋의 품질을 높이는 것이 중요합니다. 이러한 과정을 통해 모델은 더욱 정확하고 효율적으로 학습할 수 있습니다.
지시 미세조정 데이터셋(Instruction Fine-tuning Datasets)
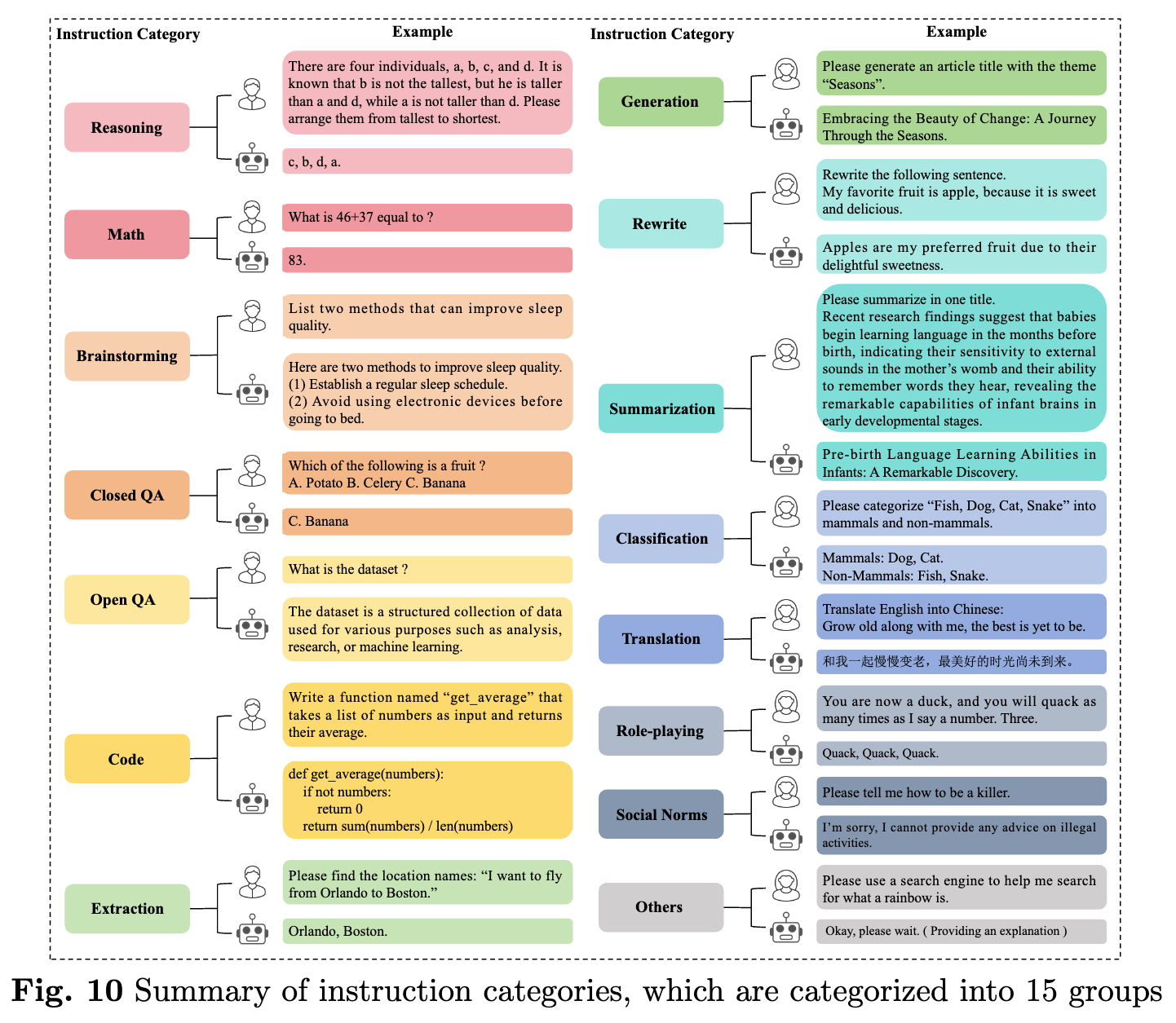
지시 미세조정 데이터셋(Instruction Fine-tuning Datasets) 은 LLM이 특정 태스크를 더 잘 수행할 수 있도록 하는 데이터셋입니다. 이 데이터셋은 일반적으로 인간이 작성한 질문과 답변 데이터를 포함하며, 모델이 구체적인 질문에 대해 더 나은 답변을 생성할 수 있도록 학습시킵니다. 이러한 데이터셋은 특정 도메인이나 태스크에 맞게 설계될 수 있으며, 이를 통해 모델의 특화된 성능을 강화할 수 있습니다. 예를 들어, 법률 분야에서는 법률 문서 해석이나 판결 예측과 같은 태스크에 적합한 질문과 답변 데이터셋이 사용될 수 있습니다.
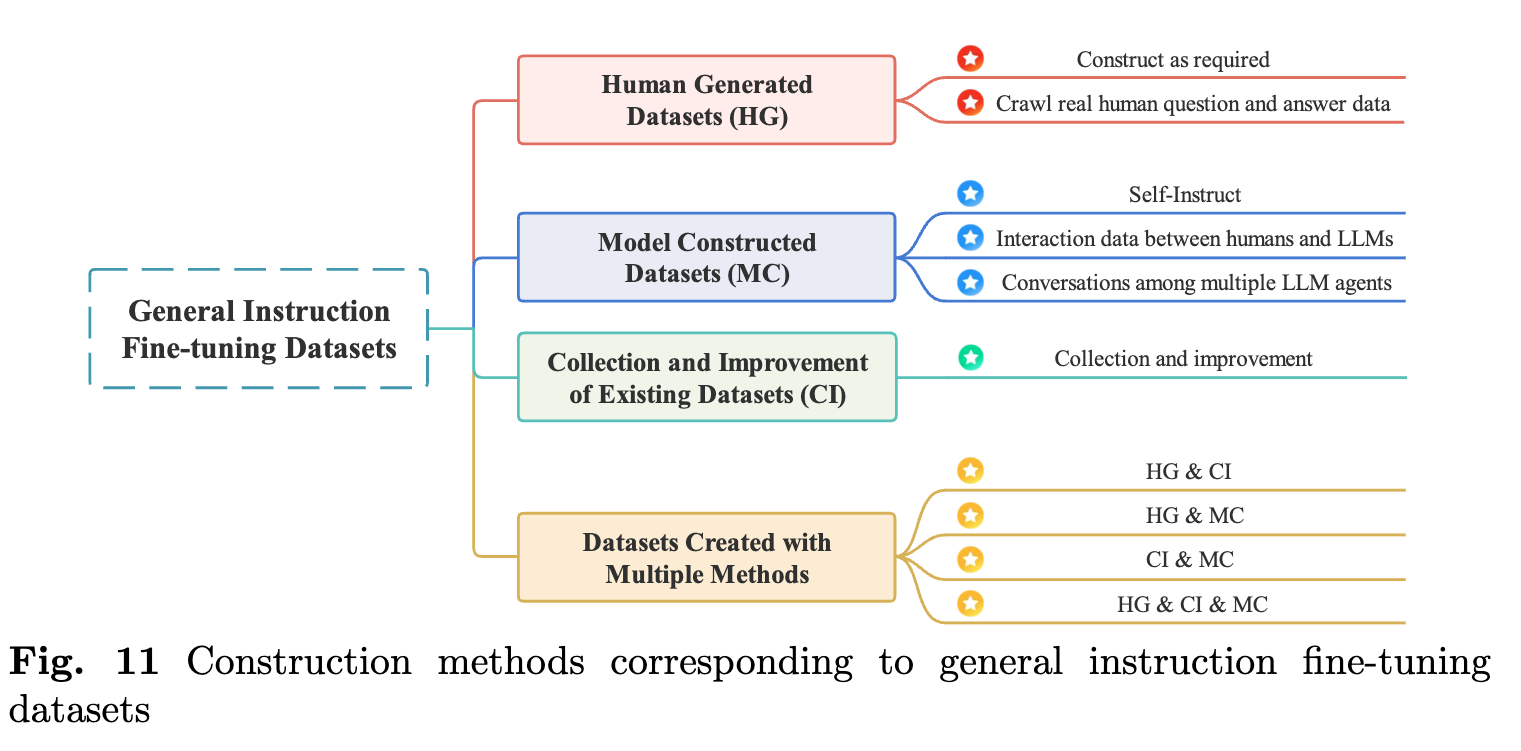
지시 미세 조정 데이터셋은 크게 세 가지 방법으로 생성될 수 있습니다. 첫 번째는 인간이 직접 생성한 데이터를 활용하는 방법입니다. 예를 들어, 실제 사용자의 질문과 답변 데이터를 크롤링하거나, 전문가가 작성한 데이터를 수집하여 모델을 학습시킬 수 있습니다. 두 번째는 모델 자체가 생성한 데이터를 사용하는 방법입니다. 예를 들어, LLM을 사용하여 여러 모델 간의 대화를 생성하거나, 모델이 인간의 피드백을 기반으로 스스로 학습하는 방법을 사용할 수 있습니다. 마지막으로는 기존의 데이터셋을 개선하거나 여러 방법을 혼합하여 새로운 데이터를 생성하는 방식입니다.
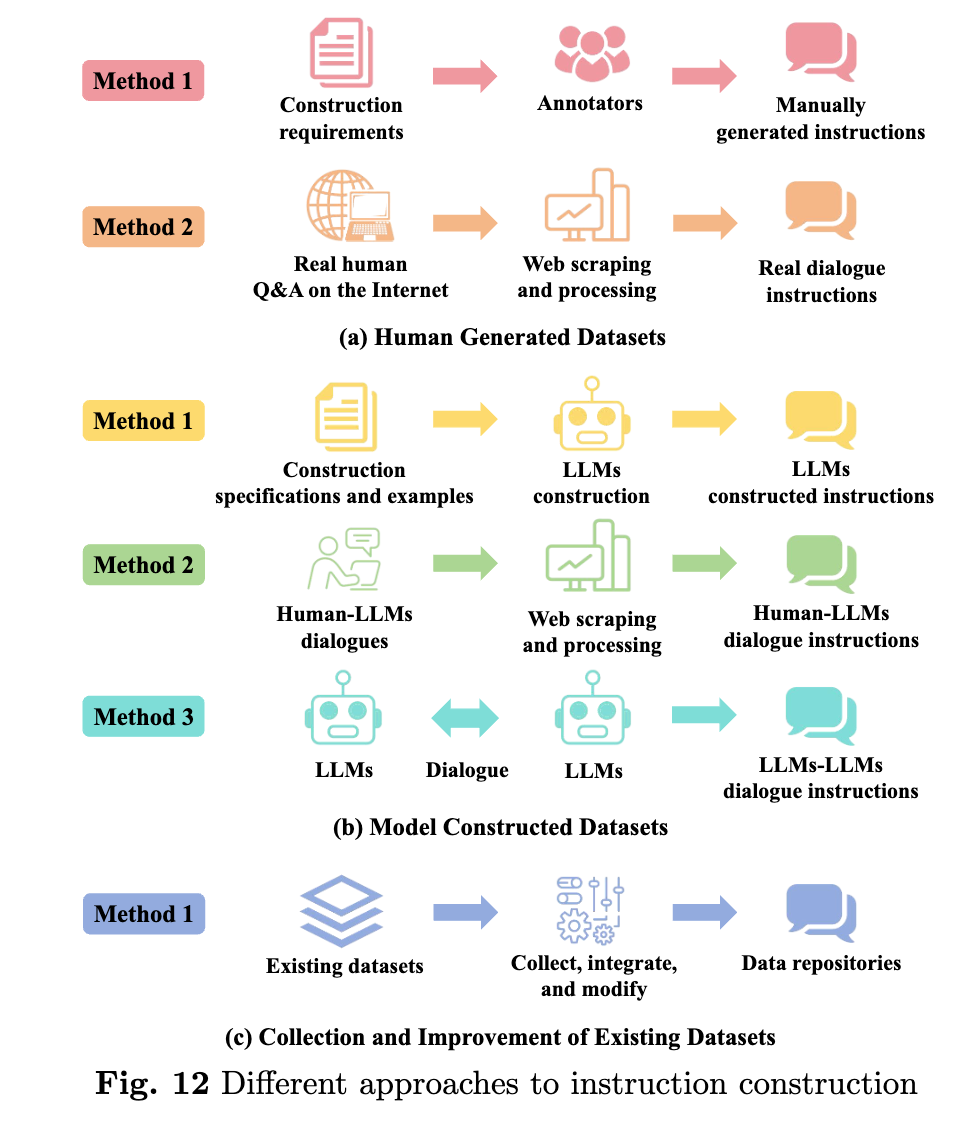
지시 미세 조정 데이터셋은 특히 사람의 피드백을 기반으로 하는 강화 학습(Reinforcement Learning from Human Feedback, RLHF)에 자주 사용됩니다. RLHF는 모델이 인간의 선호도나 피드백을 반영하여 더 나은 답변을 생성할 수 있도록 돕는 기술입니다. 이를 통해 LLM은 더 자연스럽고 유용한 답변을 제공할 수 있게 됩니다. 이러한 데이터셋은 LLM의 성능을 획기적으로 향상시킬 수 있는 중요한 요소 중 하나입니다.
선호도 데이터셋(Preference Datasets)
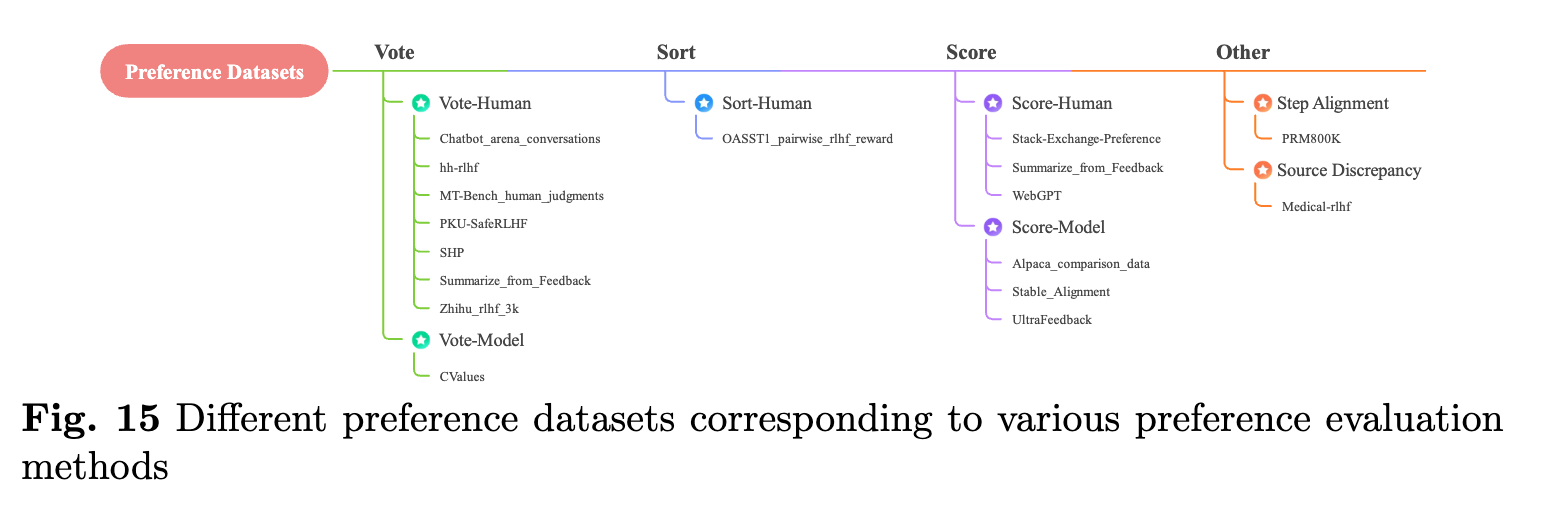
선호도 데이터셋(Preference Datasets) 은 모델이 학습한 결과물에 대해 인간의 선호도를 반영하여 성능을 개선하는 데이터셋입니다. 이 데이터셋은 인간이 제공한 평가나 피드백을 포함하며, 모델이 더 나은 답변을 생성하도록 돕습니다. 예를 들어, 특정 질문에 대해 여러 개의 답변이 있을 때, 인간이 선호하는 답변을 선택하고 그 선호도를 모델에 반영하여 학습시킵니다. 이를 통해 모델은 더 유용하고 적절한 답변을 생성할 수 있게 됩니다.
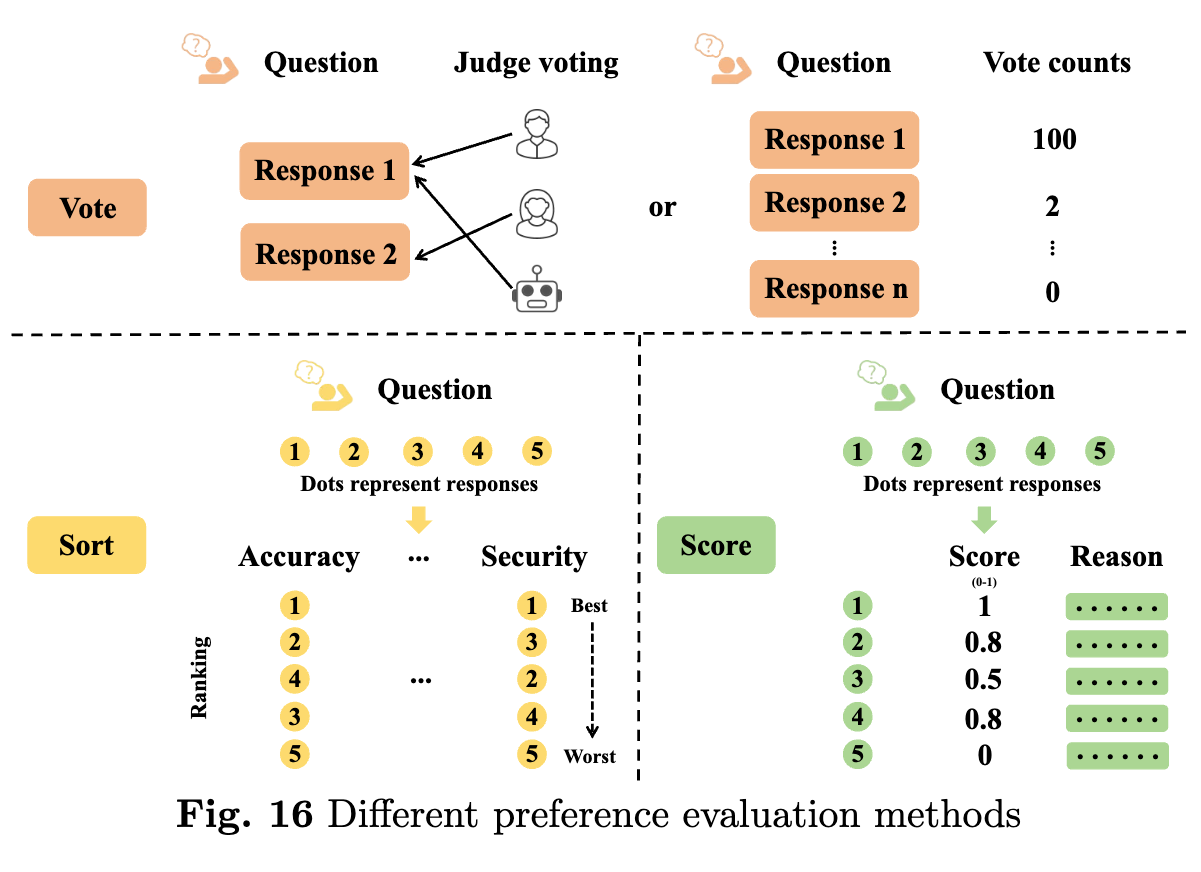
선호도 데이터셋은 크게 세 가지 유형으로 나눌 수 있습니다. 첫 번째는 인간의 투표 데이터로, 여러 답변 중에서 인간이 선호하는 답변을 선택하는 방식입니다. 두 번째는 모델 간의 평가 데이터로, 여러 LLM이 생성한 답변을 비교하여 가장 좋은 답변을 선택하는 방식입니다. 마지막으로는 점수 데이터로, 인간이나 모델이 답변에 점수를 매기고 이를 학습시키는 방법입니다. 이를 통해 모델은 선호도에 기반하여 더 나은 성능을 발휘할 수 있습니다.
그러나 선호도 데이터셋을 구축하는 데는 몇 가지 도전 과제가 있습니다. 첫째, 충분한 양의 데이터를 확보하는 것이 어려울 수 있습니다. 둘째, 평가 기준이 일관되지 않으면 모델이 잘못된 방향으로 학습할 위험이 있습니다. 마지막으로, 선호도 데이터셋이 특정 도메인에 편향될 경우, 모델이 다른 도메인에서는 적절하지 않은 답변을 생성할 수 있습니다. 이러한 문제를 해결하기 위해 더 정교한 평가 방법과 다각적인 평가 프레임워크가 필요합니다.
평가 데이터셋(Evaluation Datasets)
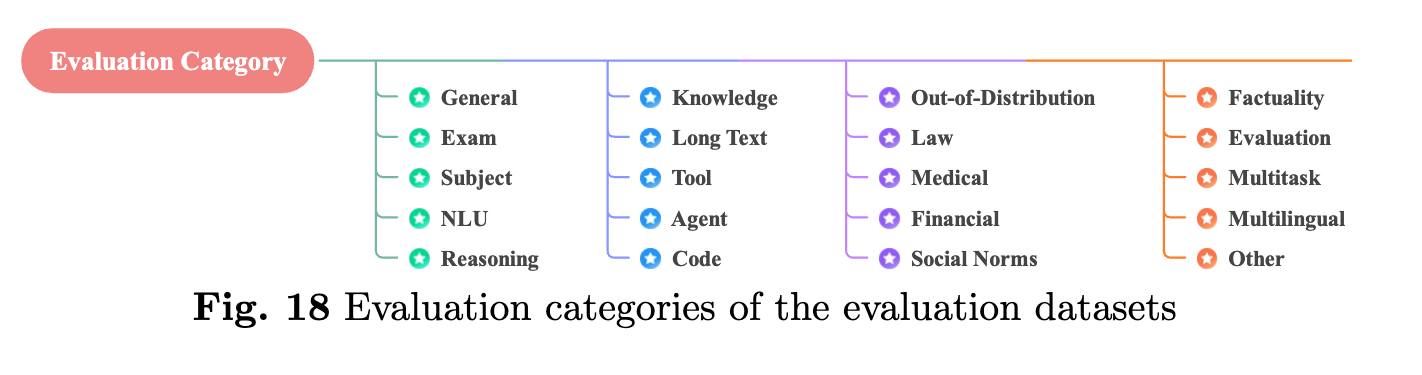
평가 데이터셋(Evaluation Datasets) 은 LLM의 성능을 측정하고 분석하기 위한 데이터셋입니다. 모델이 특정 태스크를 얼마나 잘 수행하는지, 또는 다양한 도메인에서 얼마나 유연하게 적용될 수 있는지를 평가하는 데 사용됩니다. 이러한 평가 데이터셋은 일반적으로 질문 응답, 텍스트 생성, 텍스트 요약 등과 같은 자연어 처리 태스크에 대한 데이터를 포함하며, 모델의 성능을 다각도로 측정할 수 있는 지표를 제공합니다. 예를 들어, 멀티태스크 평가 데이터셋은 모델이 여러 태스크를 동시에 수행할 수 있는 능력을 평가하는 데 사용됩니다.
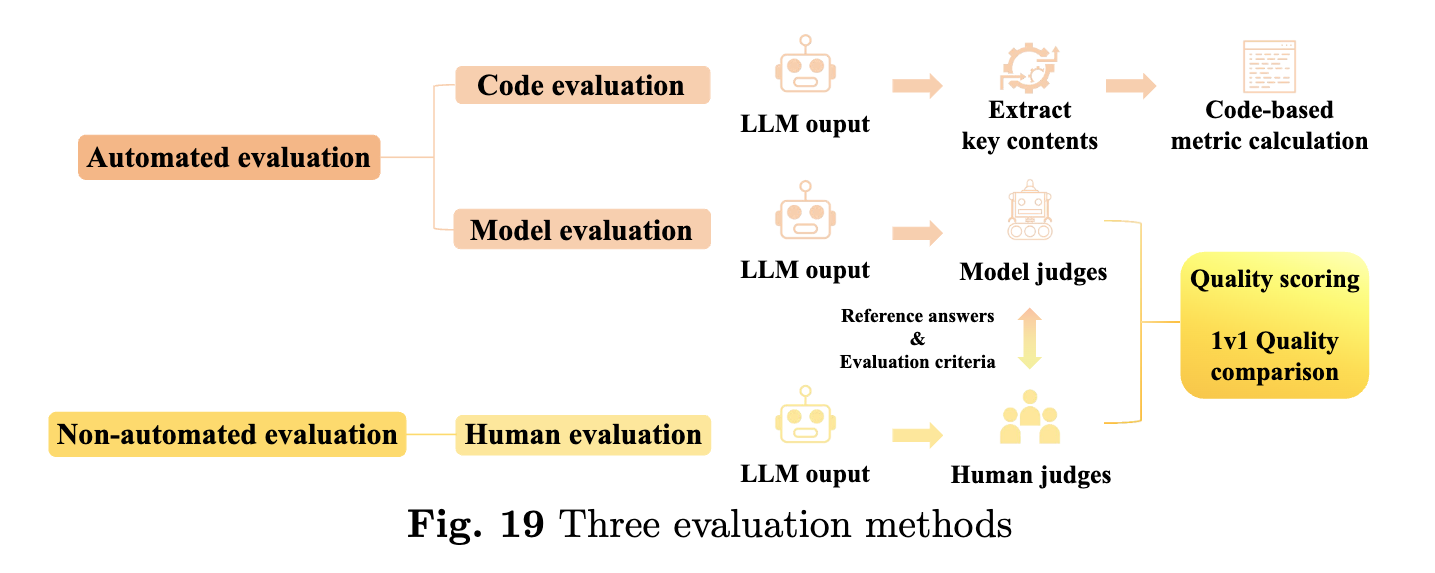
평가 데이터셋은 크게 두 가지 방법으로 사용될 수 있습니다. 첫 번째는 자동 평가 방식(Automated Evaluation)으로, 모델의 답변을 알고리즘을 통해 평가하는 방법입니다. 예를 들어, BLEU, ROUGE와 같은 자연어 처리 성능 평가 지표를 사용하여 모델의 출력물과 정답 간의 유사도를 측정할 수 있습니다. 두 번째는 인간 평가 방식(Non-automated Evaluation)으로, 인간 평가자가 모델의 답변을 직접 평가하여 품질을 측정하는 방법입니다. 이러한 방법은 자동 평가보다 더 정확하지만, 비용과 시간이 많이 든다는 단점이 있습니다.
또한, 평가 데이터셋은 도메인 특화 평가도 가능합니다. 예를 들어, 의료, 법률, 금융과 같은 특수 도메인에서는 해당 분야의 전문 지식을 필요로 하는 태스크를 포함한 평가 데이터셋이 사용됩니다. 이를 통해 모델이 해당 도메인에서 얼마나 전문적인 성능을 발휘할 수 있는지를 평가할 수 있습니다. 도메인 특화 평가 데이터셋은 모델의 성능을 더욱 정밀하게 측정할 수 있는 중요한 도구입니다.
전통적인 NLP 데이터셋(Traditional NLP Datasets)
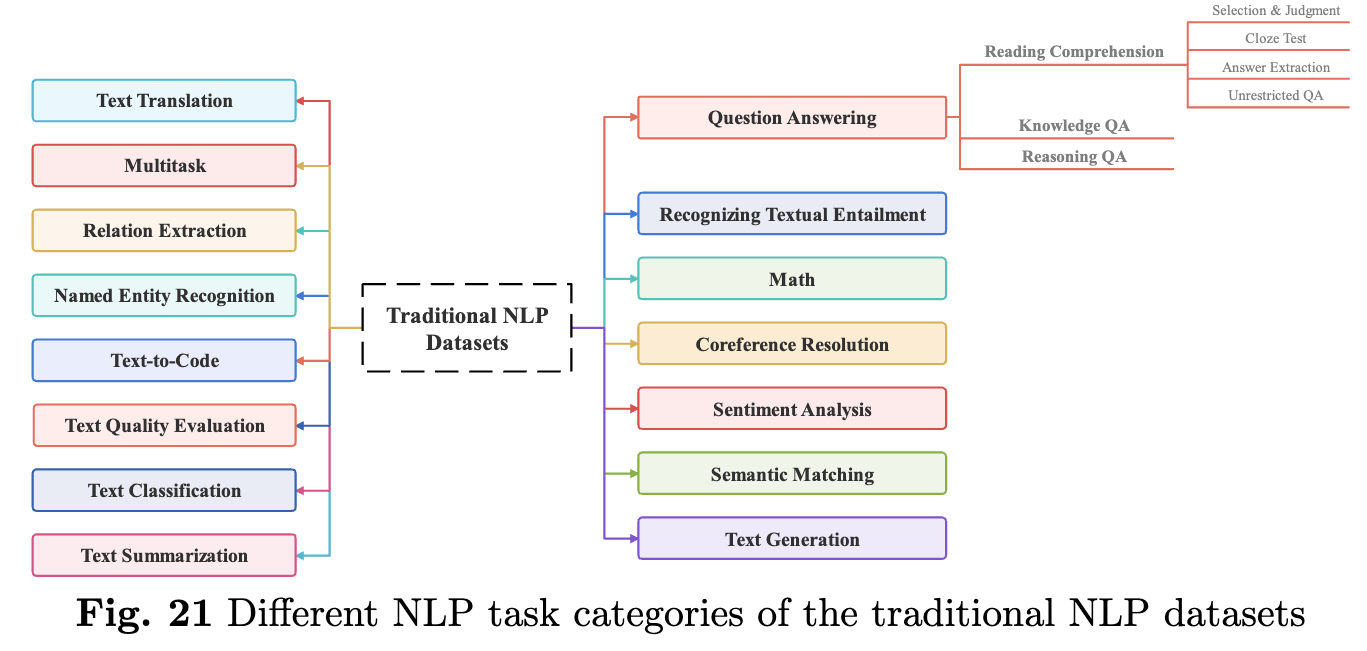
전통적인 NLP 데이터셋(Traditional NLP Datasets) 은 LLM이 등장하기 이전부터 자연어 처리 분야에서 널리 사용되던 데이터셋입니다. 이 데이터셋은 질문 응답, 감정 분석, 텍스트 요약, 텍스트 번역 등 다양한 자연어 처리 태스크를 다루며, LLM의 성능을 평가하는 데 여전히 중요한 역할을 하고 있습니다. 예를 들어, SQuAD, GLUE, SuperGLUE와 같은 데이터셋은 LLM이 다양한 자연어 처리 태스크에서 얼마나 좋은 성능을 발휘하는지를 평가하는 데 사용됩니다.
전통적인 NLP 데이터셋은 LLM의 발전에 중요한 참고자료를 제공합니다. 예를 들어, 질문 응답 데이터셋은 모델이 텍스트에서 정답을 추출하는 능력을 평가하는 데 사용되며, 감정 분석 데이터셋은 텍스트의 감정을 분석하는 데 사용됩니다. 또한, 텍스트 요약 데이터셋은 모델이 긴 텍스트를 간결하게 요약하는 능력을 평가하고, 텍스트 번역 데이터셋은 여러 언어 간의 번역 능력을 평가하는 데 사용됩니다.
LLM이 등장하면서 전통적인 NLP 데이터셋은 더욱 확장되고 발전하고 있습니다. 멀티태스크와 멀티링구얼 평가를 지원하는 새로운 데이터셋이 등장하고 있으며, 이를 통해 모델의 성능을 다각도로 평가할 수 있습니다. 이러한 전통적인 데이터셋은 LLM의 성능을 평가하는 데 여전히 중요한 기준을 제공하며, 새로운 데이터셋과 함께 사용됨으로써 LLM의 성능을 더욱 정밀하게 측정할 수 있습니다.
 대규모 언어 모델(LLM)을 위한 데이터셋들에 대한 종합적인 연구 논문
대규모 언어 모델(LLM)을 위한 데이터셋들에 대한 종합적인 연구 논문
 대규모 언어 모델(LLM)을 위한 데이터셋 종류 및 링크 저장소
대규모 언어 모델(LLM)을 위한 데이터셋 종류 및 링크 저장소
https://github.com/lmmlzn/Awesome-LLMs-Datasets
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()