
LLMflation 소개
기술 혁신은 일반적으로 기초 자원의 비용 감소와 함께 이루어졌습니다. 예를 들어, 무어의 법칙(Moore's Law)과 데나드 확장 법칙(Dennard Scaling)은 컴퓨터 성능의 비약적인 향상을 설명하며 PC 혁명을 이끌었고, 에드홀름 법칙(Edholm's Law)은 네트워크 대역폭 증가로 인해 닷컴 붐(dotcom boom)을 가능하게 했습니다.
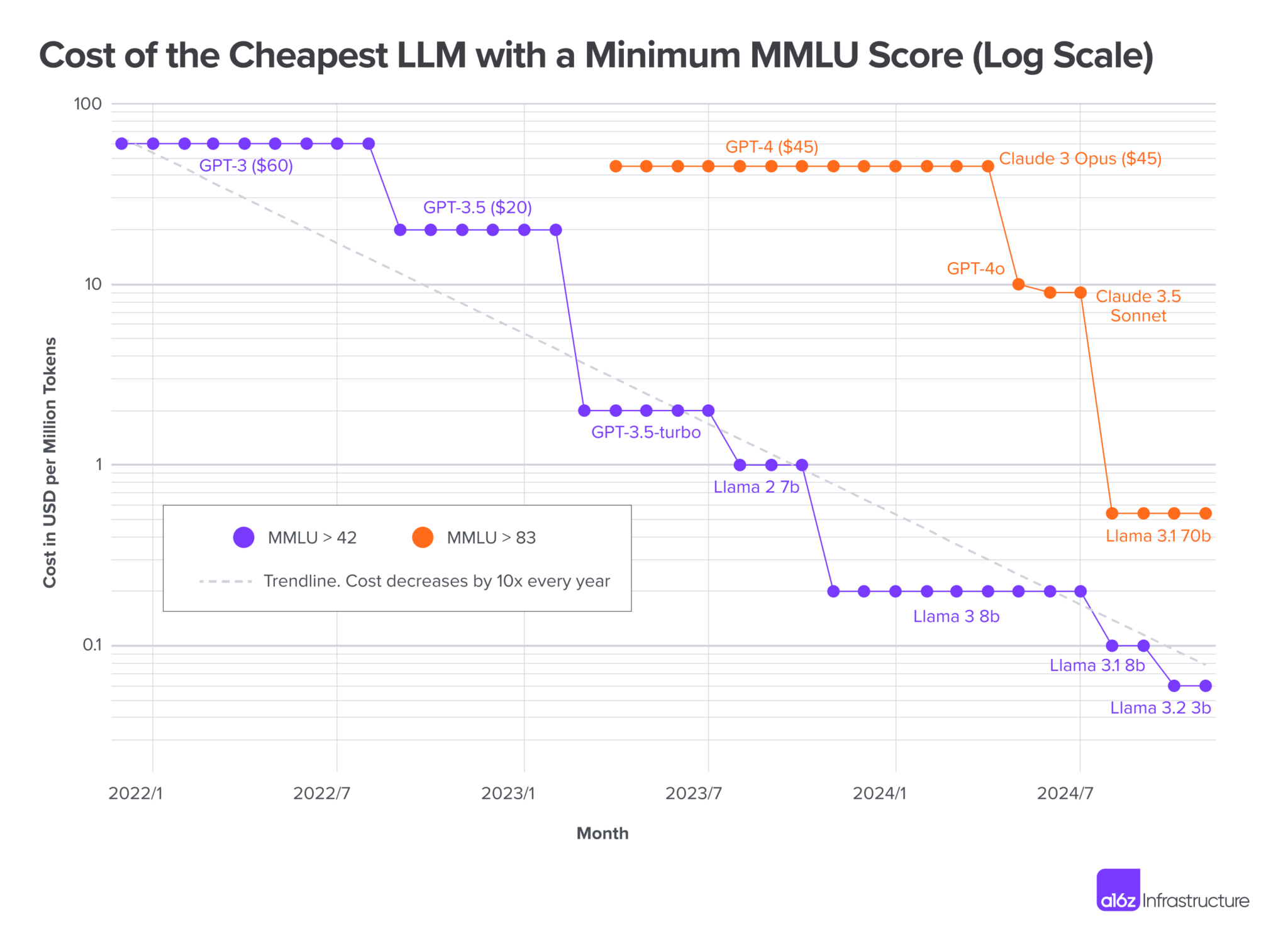
이와 유사하게, 대규모 언어 모델(LLM)의 추론 비용도 급격히 감소하고 있으며, 이를 LLMflation이라고 부릅니다. 현재 추세에 따르면, 동일한 성능의 LLM 추론 비용은 매년 약 10배씩 감소하고 있으며, 이는 AI 혁명의 지속적인 발전을 예고합니다.
LLMflation은 일정 비용으로 처리할 수 있는 토큰 수의 급격한 증가를 의미합니다. 예를 들어:
-
2021년 GPT-3는 100만 토큰당 $60로 MMLU(Massive Multitask Language Understanding) 점수 42를 달성했습니다.
-
2024년 Llama 3.2(3B)는 동일한 점수를 100만 토큰당 $0.06로 달성하며, 3년 만에 1,000배 비용 절감을 실현했습니다.

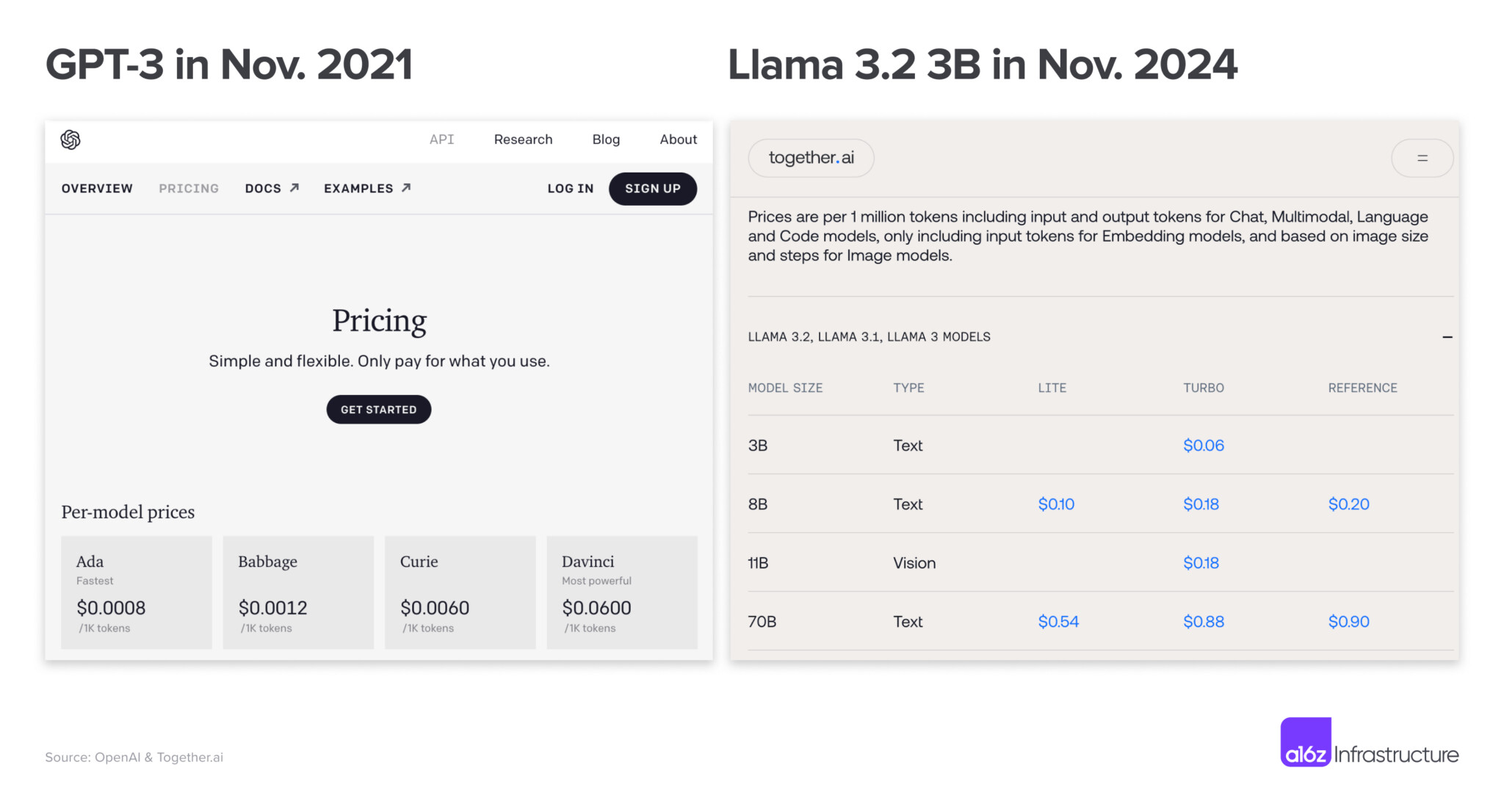
이 추세는 과거 PC 혁명이나 네트워크 혁신보다도 빠른 속도로 진행되고 있으며, 이는 AI 활용의 경제성을 크게 개선하고 있습니다. 이 글에서 LLM 비용 감소 분석은 다음과 같은 방법으로 이루어졌습니다:
- MMLU 점수 사용: 모델 성능을 비교하기 위해 MMLU 벤치마크를 사용했습니다.
- 역사적 가격 데이터 수집: OpenAI, Anthropic, Meta Llama 등 주요 모델 제공자의 데이터를 기반으로 추론 비용을 비교했습니다.
- 토큰 가격의 평균화: 입력 및 출력 토큰의 가격 차이를 평균화하여 계산했습니다.
- 로그 축적 분석: 연간 비용 감소율을 명확히 하기 위해 로그 그래프를 활용했습니다.
위와 같은 방법으로 분석해본 결과, 아래 그림과 같이 연간 10배 감소 추세를 나타내는 패턴이 확인되었습니다(Log Scale로 그려져있음에 유의해주세요):
LLM 비용 감소의 주요 원인
이러한 LLM 비용 감소를 주도하는 주요 원인은 아래 6가지 정도로 정리해볼 수 있습니다:
GPU의 비용/성능 향상 (Better cost/performance of the GPUs)
GPU 성능은 무어의 법칙(Moore’s Law)에 따라 트랜지스터 수가 지속적으로 증가하면서 큰 개선을 이루었습니다. 이로 인해 동일한 작업에서 비용 대비 성능이 대폭 향상되었습니다. 또한, GPU 구조적인 개선도 중요한 역할을 했습니다. 이러한 기술 발전은 LLM 추론 비용을 낮추는 데 핵심적 기여를 하고 있습니다.
모델 양자화 (Model Quantization)
LLM 추론 초기에는 16비트 정밀도를 사용했으나, 최근 NVIDIA의 Blackwell GPU와 같은 최신 하드웨어에서 4비트 양자화(4bit Quantization)가 일반화되고 있습니다. 이 변화는 최소 4배의 성능 향상을 가져왔으며, 데이터 이동량 감소와 단순화된 산술 연산 구조를 통해 더욱 큰 효율성을 얻을 수 있었습니다.
소프트웨어 최적화 (Software Optimization)
소프트웨어 측면에서의 개선은 다음과 같은 이점을 제공합니다:
- 계산 요구량 감소: 효율적인 알고리즘과 새로운 최적화 기법이 도입되어 모델이 요구하는 연산량이 줄어듭니다.
- 메모리 대역폭 병목현상 해소: 메모리 대역폭 문제는 이전의 주요 한계점이었으나, 이를 개선한 최적화 기술이 도입되어 성능이 더욱 향상되었습니다.
더 작은 모델 및 효율성 향상 (Smaller Models)
오늘날의 1B 규모의 모델이 3년 전의 175B 규모의 모델보다 더 나은 성능을 보여줍니다. 이러한 성과는 친칠라 확장 법칙(Chinchilla Scaling Law)을 초과하는 대규모 데이터셋을 사용한 학습 덕분에 가능했습니다. 모델이 더 적은 매개변수를 사용하면서도 더 높은 효율성을 제공하고 있습니다.
더 나은 지시 기반 튜닝(Better Instruction Tuning)
사전 학습 이후의 모델 개선에 대한 연구가 크게 진전되었습니다. 주요 기술은 다음과 같습니다:
- 인간 피드백 강화 학습(RLHF): 모델이 사람의 피드백을 통해 더 나은 응답을 생성하도록 학습합니다.
- 직접 선호 최적화(DPO): 사용자의 선호도를 직접 모델 학습에 반영하여 성능을 향상시킵니다.
이러한 기술은 모델의 정확성과 유용성을 크게 높이며, 추론 비용을 줄이는 데 기여하고 있습니다.
오픈소스 생태계
Meta, Mistral 등 다양한 조직이 오픈소스 모델을 제공하면서 경쟁이 촉진되었습니다. 이로 인해 다음과 같은 효과가 발생했습니다:
- 비용 절감: 낮은 비용의 모델-서비스 제공업체들이 등장하며, 가격이 전반적으로 하락했습니다.
- 생태계 강화: 오픈소스 모델은 혁신을 가속화하고, 기술의 상용화를 더욱 용이하게 만듭니다.
결론
이러한 LLMflation 현상은 AI 산업의 중요한 전환점으로, 지속적인 비용 절감을 통해 새로운 가능성을 열어주고 있습니다. 추론 비용이 계속 하락함에 따라, 대규모 언어 모델은 더 많은 사용자에게 접근 가능해지고, AI 기술의 발전 속도도 가속화될 것입니다.
 a16z의 LLMflation 글 원문
a16z의 LLMflation 글 원문
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()