
연구 요약
기초적인 텍스트를 생성하던 GPT-2와 같은 모델에서부터 복잡한 수시간짜리의 머신러닝 연구 프로젝트를 자율적으로 수행하기까지, 지난 5년간 최첨단 인공지능 시스템(AI System)의 성능은 극적으로 발전해왔습니다. 이러한 인공지능의 능력을 잘 측정하는 것은, 인공지능에 필요한 위험 완화 조치를 결정하기 위해서도 필요합니다. 하지만, 기존의 벤치마크들은 몇 가지 한계를 가지고 있습니다. 예를 들어, 경제적 가치보다는 인공적인 작업을 평가하는 방식으로 구성되어 있으며, 사람보다 상대적으로 어려워하는 작업들을 기준으로 선정되어 있어 사람의 능력과의 비교에서 편향을 초래합니다. 무엇보다 개별 벤치마크는 빠르게 포화되고 있어, 능력이 크게 다른 모델들 간의 의미있는 비교를 어렵게 합니다.
이러한 문제를 해결하기 위해 이번에 살펴볼 연구에서는 50% 작업 완료 시간 한계(50%-task-completion time horizon) 를 제안하고 있습니다. 이 지표는 인공지능 모델이 50%의 성공률로 완료할 수 있는 작업을 찾고, 해당 작업을 사람이 수행할 때 얼마나 시간이 걸리는지를 측정하는 지표입니다. 즉, 모델이 주어진 모든 작업을 완벽하게 수행하기는 어렵기 때문에, 모델이 일정한 확률(예. 50%)로 완료할 수 있는 작업을 찾은 뒤, 사람이 해당 작업을 수행하는데 걸리는 시간을 측정함으로써 현실 세계에서의 인공지능 능력을 직관적으로 알 수 있습니다.

이 연구에서는 크게 3가지 데이터셋을 사용하여 성공률과 시간을 측정하였습니다:
- HCAST의 일부: 1분에서 약 30시간까지 다양한 소프트웨어 작업 97개
- RE-Bench: 8시간 분량의 어려운 기계 학습 연구 엔지니어링 작업 7개
- Software Atomic Actions (SWAA): 소프트웨어 개발자가 수행하는 1초에서 30초 사이의 단일 단계 작업 66개
모든 작업은 연속 점수 또는 이진 임계값으로 자동 채점됩니다. 대부분의 벤치마크와 마찬가지로, 이 세 작업 셋은 제한된 시간 내에 신뢰성 있게 완수할 수 있는, 추가적인 문맥 정보가 필요없는 단위 작업로 구성되어 있습니다. 또한, 포함된 각 작업들은 인간이 각 작업을 최소 한 번 이상 성공적으로 수행함으로써 작업의 실현 가능성을 확인하였습니다.

이 중 새로 제작한 SWAA 데이터셋은 짧은 작업들로로 이뤄져있는데, 이는 실제 지적 노동의 일부가 1분 미만의 단일 단계 행동들로 구성됨을 관찰하여 만든 것입니다. 예를 들어, credentials.txt, installation_notes.txt, main.py, launcher_win.exe 와 같은 예시들 중, 비밀번호가 있을 가능성이 가장 높은 파일을 찾는 것과 같은 문제들로 구성되어 있습니다. SWAA 데이터셋은 모델 성능에 편향되지 않도록 실험 전 작성하였습니다.
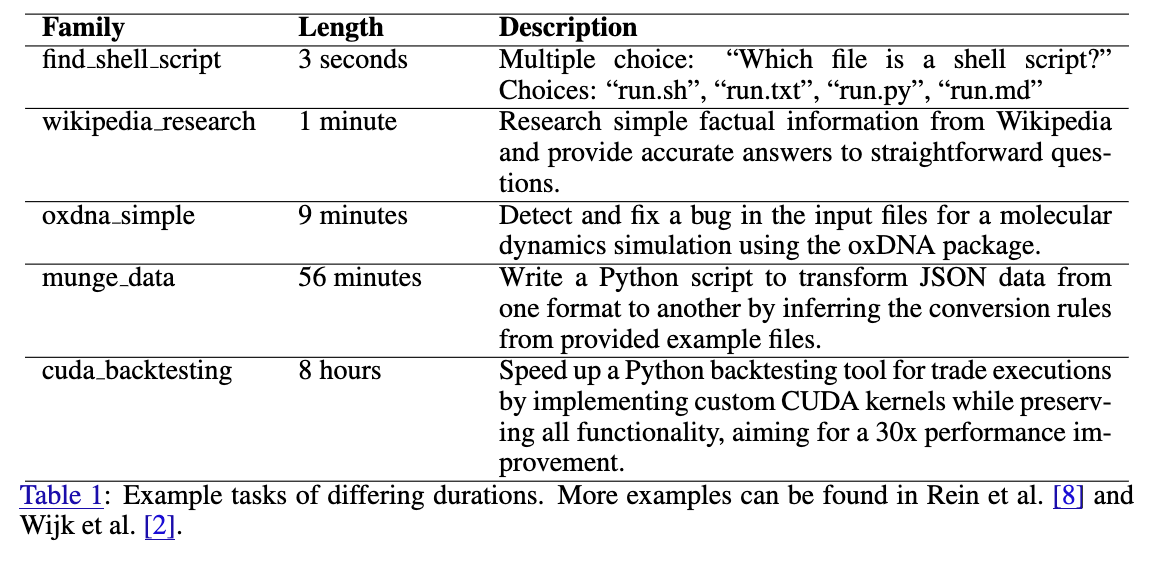
위 표는 다양한 길이의 작업에 대한 일부 예시입니다. 실제 데이터셋은 다양한 길이로 구성되어 있으며, 1분 미만의 작업은 전문 소프트웨어 엔지니어링에 필요한 지식을 측정합니다. 1분 작업은 위키피디아의 기본 질문에 답하는 정도의 작업이며, 10분 정도의 작업은 실제 소프트웨어 프로젝트의 가장 쉬운 의미 있는 단계를 나타냅니다. 1시간 정도면 독립적인 경제적 가치가 있는 프로젝트로 간주될 수 있으며, 8시간이면 의미 있는 소프트웨어 프로젝트로 볼 수 있습니다.
인공지능 모델의 성능과 비교하기 위해, 관련 도메인 전문가인 인간 “베이스라이너(Baseliner)”들의 성능과 작업 소요 시간도 함께 측정하였습니다. “베이스라이너(Baseliner)”는 사이버 보안 및 머신러닝, 소프트웨어 공학 분야의 숙련된 전문가들로 구성되어 있으며, 대다수는 세계 100대 대학을 졸업했습니다. 평균적으로 5년 가량의 경력을 갖고 있으며, 소프트웨어 공학 분야의 베이스라이너가 머신러닝 또는 사이버 보안의 베이스라이너보다 더 많은 경험을 갖고 있습니다. 최종적으로 2,529시간의 800회 이상의 베이스라인을 사용하였으며, 여기에는 HCAST 및 Re-Bench 558건(중 286건 성공)과 SWAA 249건(중 236건 성공)이 포함되어 있습니다.
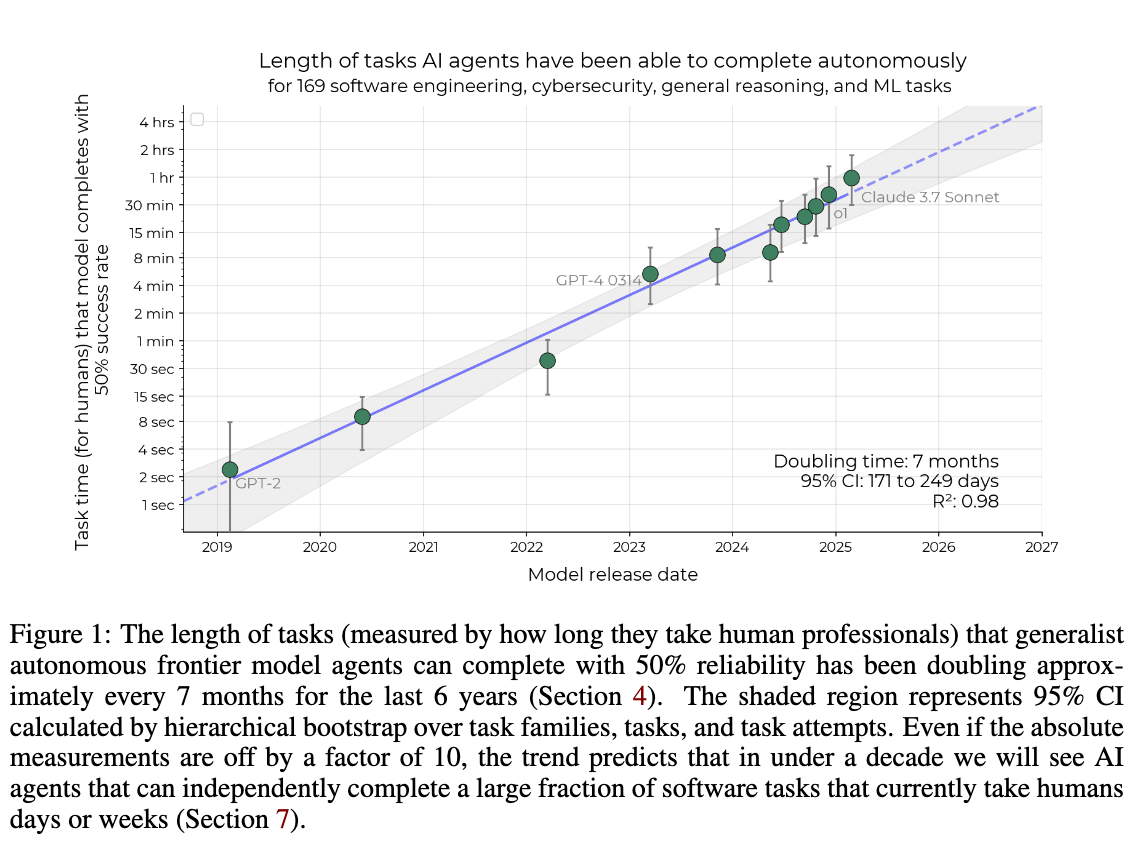
실험 결과, "50% 작업 완료 시간 한계(50%-task-completion time horizon)" 지표는 2019년부터 2024년 사이 기하급수적으로 증가하였으며, 대략 7개월마다 두 배로 증가하는 것을 확인할 수 있었습니다. 인간이 작업을 완료하는 데 걸리는 시간과 AI 모델의 성공률은 음의 상관관계를 보여, 작업 난이도를 반영하는 지표로서 유효함을 확인하였습니다.
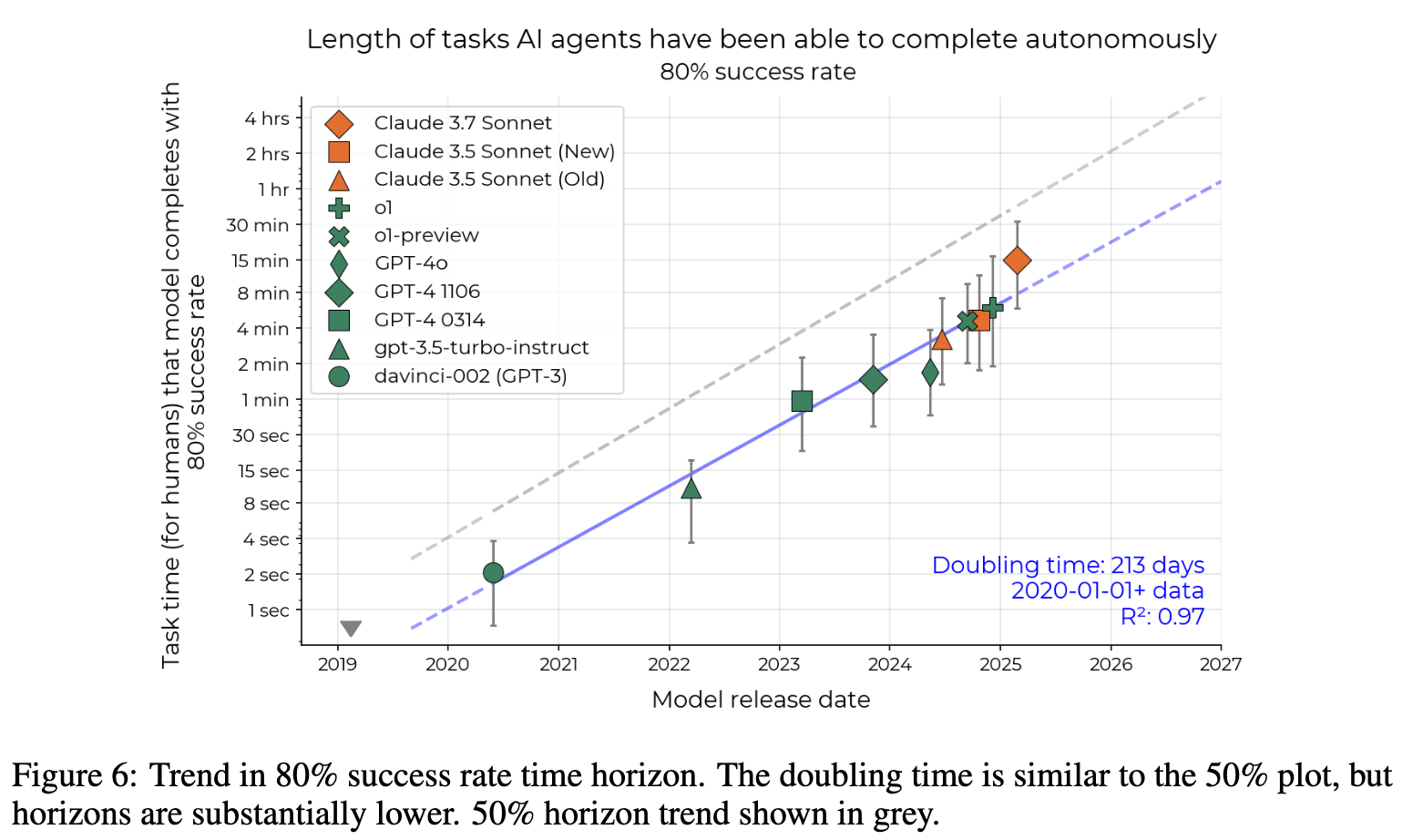
80% 성공률 기준 실험에서도 유사한 지수적 추세가 관찰되었으나, 약 5배 짧게 나타났습니다. 그 외에도 SWE-bench Verified 및 실제 PR 작업과의 비교 실험을 통해, 이러한 성능 추세가 다양한 작업 분포에서도 견고하게 유지됨을 확인하였습니다.
이러한 시간 한계 측정은 인간의 문맥 이해 및 숙련도, 작업 분포 등 여러 요인에 영향을 받으며, 모델 성능 향상과 외부 타당성 문제, 그리고 미래 예측의 불확실성에 대한 한계가 존재할 수 있습니다. 따라서 향후 연구에서는 더 많은 모델 평가, 정교한 베이스라인 측정, 그리고 현실적인 작업 분포 적용을 통해 결과의 신뢰성과 일반화를 높이는 방향으로 진행할 것입니다.
 Measuring AI Ability to Complete Long Tasks 논문
Measuring AI Ability to Complete Long Tasks 논문
 METR(Model Evaluation & Threat Research) 홈페이지
METR(Model Evaluation & Threat Research) 홈페이지
 실험에 사용한 데이터셋 일부 및 코드 저장소
실험에 사용한 데이터셋 일부 및 코드 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()