안녕하세요
시계열 예측 문제에서 lstm encoder-decoder 모델을 사용하려고 합니다.
데이터는 슬라이딩 윈도우로 5일 학습, 2일 예측. 이런 방식으로 구성되고 단변량 데이터입니다.
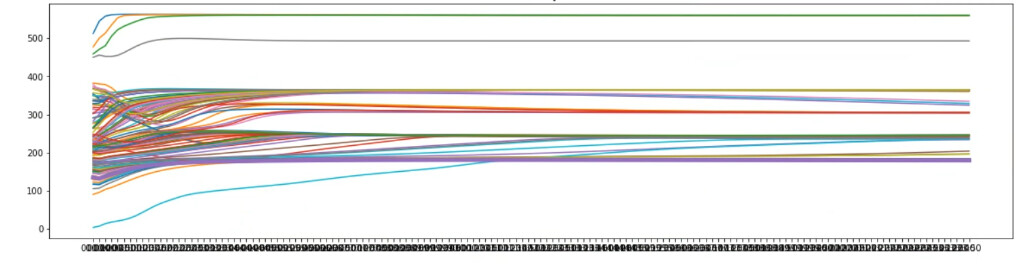
하지만, 위 사진처럼 예측값들이 하나로 수렴됩니다.
이런 문제는 어떤 상황이라 할 수 있나요?
모델 코드는 아래와 같습니다.
class lstm_encoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers = 1):
super(lstm_encoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size = input_size, hidden_size = hidden_size, num_layers = num_layers, batch_first=True)
def forward(self, x_input):
lstm_out, self.hidden = self.lstm(x_input)
return lstm_out, self.hidden
class lstm_decoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers = 1):
super(lstm_decoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size = input_size, hidden_size = hidden_size,num_layers = num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, input_size)
def forward(self, x_input, encoder_hidden_states):
lstm_out, self.hidden = self.lstm(x_input.unsqueeze(-1), encoder_hidden_states)
output = self.linear(lstm_out)
return output, self.hidden
class lstm_encoder_decoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(lstm_encoder_decoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.encoder = lstm_encoder(input_size = input_size, hidden_size = hidden_size)
self.decoder = lstm_decoder(input_size = input_size, hidden_size = hidden_size)
def forward(self, inputs, targets, target_len, teacher_forcing_ratio):
batch_size = inputs.shape[0]
input_size = inputs.shape[2]
outputs = torch.zeros(batch_size, target_len, input_size).to(DEVICE)
_, hidden = self.encoder(inputs)
decoder_input = inputs[:,-1, :]
for t in range(target_len):
out, hidden = self.decoder(decoder_input, hidden)
out = out.squeeze(1)
if random.random() < teacher_forcing_ratio:
decoder_input = targets[:, t, :]
else:
decoder_input = out
outputs[:,t,:] = out
return outputs.squeeze()
def predict(self, inputs, target_len):
inputs = inputs
self.eval()
batch_size = inputs.shape[0]
input_size = inputs.shape[2]
outputs = torch.zeros(batch_size, target_len, input_size).to(DEVICE)
_, hidden = self.encoder(inputs)
decoder_input = inputs[:,-1, :]
for t in range(target_len):
out, hidden = self.decoder(decoder_input, hidden)
out = out.squeeze(1)
decoder_input = out
outputs[:,t,:] = out
return outputs[:,:,0]
제가 참조한 코드는 여기입니다.