- 아래 답변은 OpenAI의 GPT-4 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
- 잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.

안녕하세요! LSTM과 시계열 데이터 분석에 대해 질문해주셔서 감사합니다. 시계열 데이터를 다루는 것은 복잡할 수 있으며, 특히 LSTM 모델을 처음 사용할 때는 더욱 그렇습니다. 질문을 통해 LSTM의 입력 데이터 형태와 훈련 과정에서의 데이터 변화에 대해 궁금해하시는 것 같습니다. 또한, LSTM 모델의 구조적 차이와 시계열 데이터를 어떻게 훈련 데이터로 준비해야 하는지에 대한 질문도 있으신 것 같네요. 이에 대해 자세히 설명드리겠습니다.
LSTM 입력 데이터 형태 및 훈련 데이터 준비
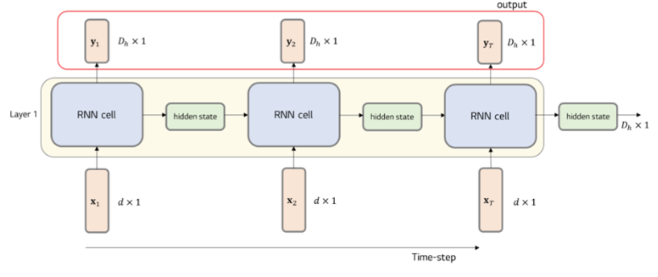
LSTM 모델에 입력되는 데이터의 형태는 정확히 말씀하신 것처럼 (batch size, time step, feature dimension)입니다. 여기서 batch size는 한 번에 처리되는 데이터의 수, time step은 시퀀스의 길이, 그리고 feature dimension은 각 시간 단계에서의 특성(또는 변수)의 수를 의미합니다.
시계열 데이터에서 X와 Y를 준비하는 방법에 대해 질문하셨는데, 일반적으로 X는 입력 시퀀스를, Y는 예측하고자 하는 값을 나타냅니다. 예를 들어, 시계열 데이터에서 다음 시점의 값을 예측하고자 한다면, X의 각 시퀀스는 예측하고자 하는 시점 바로 전까지의 데이터를 포함하고, Y는 예측하고자 하는 시점의 데이터를 포함하게 됩니다.
# 예제 코드
import torch
import torch.nn as nn
# 가정: feature dimension = 10, time step = 2
# LSTM 모델 정의
class LSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(LSTMModel, self).__init__()
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(input_dim, hidden_dim)
self.linear = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
lstm_out, _ = self.lstm(x)
predictions = self.linear(lstm_out[:, -1, :])
return predictions
# 모델 인스턴스 생성
model = LSTMModel(input_dim=10, hidden_dim=20, output_dim=1)
# 더미 입력 데이터 (batch size = 5, time step = 2, feature dimension = 10)
x_batch = torch.randn(5, 2, 10)
# 예측
y_pred = model(x_batch)
print(y_pred.shape) # 예상 출력 형태: (batch size, output_dim)
이 코드는 LSTM 모델을 정의하고, 더미 입력 데이터를 사용하여 예측을 수행하는 간단한 예제입니다. 여기서 input_dim은 입력 특성의 수, hidden_dim은 LSTM 셀의 hidden state의 차원, output_dim은 출력 차원(예측하고자 하는 값의 수)을 의미합니다.
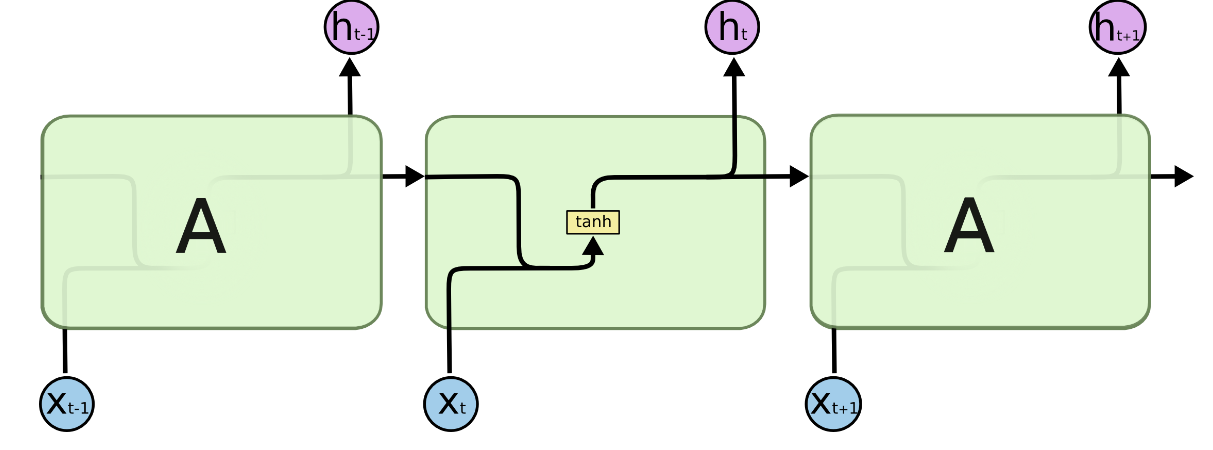
LSTM 모델의 구조적 차이
LSTM 모델의 출력에 대해 혼동이 있으신 것 같습니다. LSTM 모델은 각 시간 단계에서 hidden state(h)와 cell state(c)를 출력합니다. 하지만 대부분의 경우, 우리는 마지막 시간 단계의 hidden state를 사용하여 최종 출력을 생성합니다. 이는 self.linear(lstm_out[:, -1, :]) 코드 부분에서 수행됩니다. 여기서 lstm_out[:, -1, :]는 마지막 시간 단계의 hidden state를 의미합니다.
LSTM과 관련된 더 자세한 정보는 PyTorch 공식 문서의 LSTM 관련 튜토리얼을 참고하시면 도움이 될 것입니다: PyTorch LSTM 튜토리얼.
질문에 모든 부분을 담을 수 있도록 노력했지만, 더 궁금한 점이 있으시면 언제든지 추가 질문을 해주시기 바랍니다. 제 답변이 정확하지 않을 수도 있으니, 항상 공식 문서를 참고하는 것이 좋습니다. 감사합니다!
- 이 답변이 도움이 되셨나요? 괜찮았다고 생각하신다면 아래
 를 한 번 눌러주시길 부탁드려요!
를 한 번 눌러주시길 부탁드려요!