다른 글 에서 문의 드렸던 내용에 이어서 문의 드립니다.
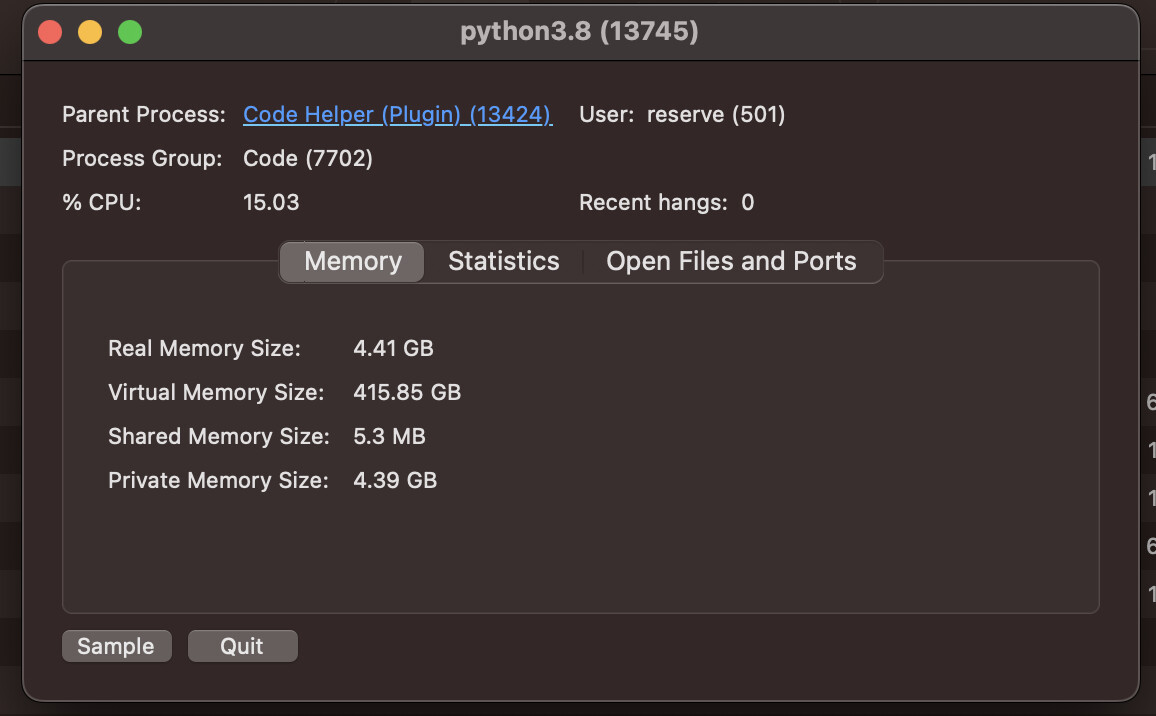
M1 Mac mini 16GB 를 이용해서 하기와 같이 실행했으나, Error가 발생해서요. 어떤 부분이 문제인지 도움 부탁 드립니다.
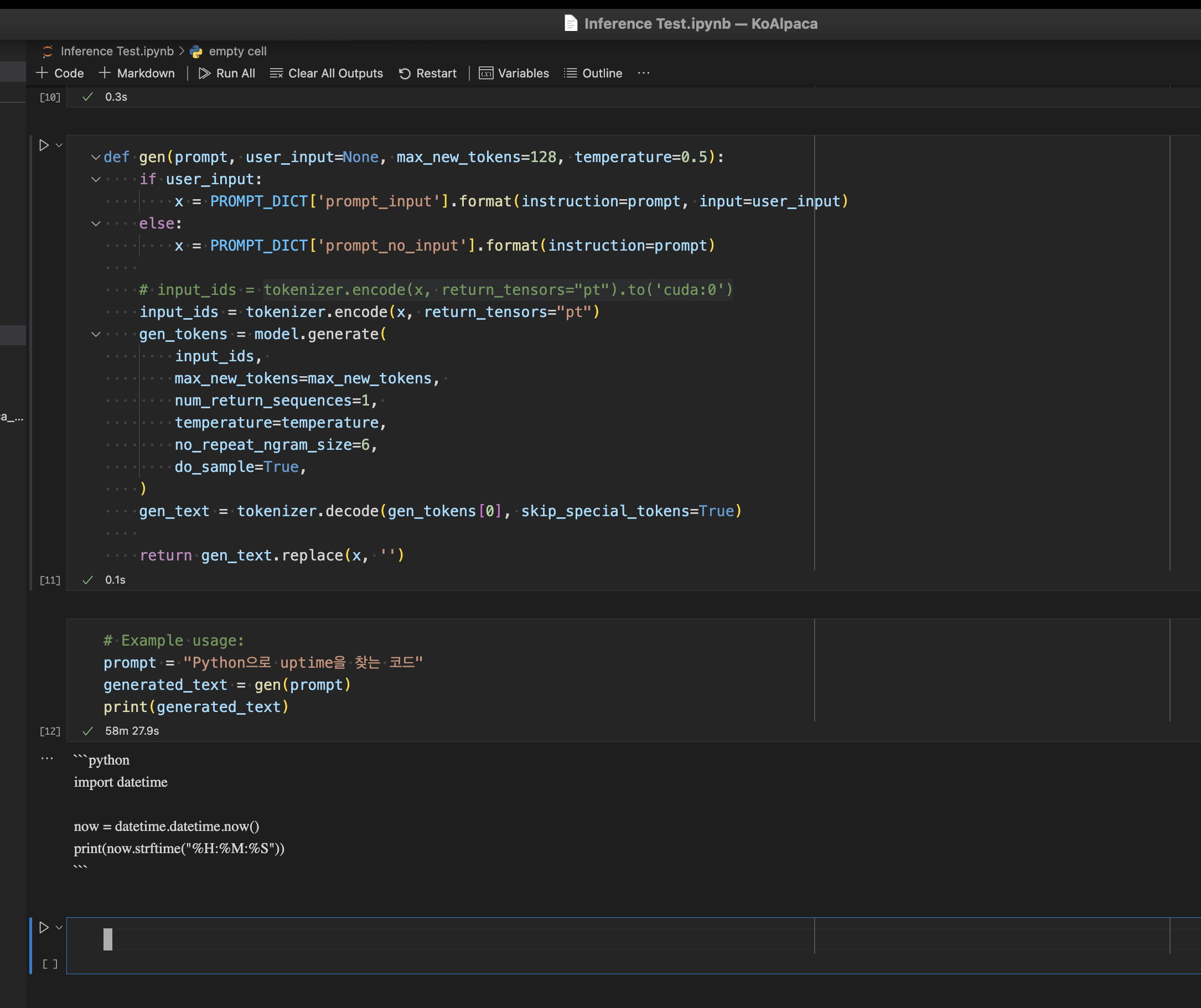
작성 코드는 하기와 같습니다.
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
device = torch.device("mps")
tokenizer = LlamaTokenizer.from_pretrained("beomi/KoAlpaca")
model = LlamaForCausalLM.from_pretrained("beomi/KoAlpaca").to(device)
Error는 아래와 같이 발생했습니다.
Canceled future for execute_request message before replies were done
The Kernel crashed while executing code in the the current cell or a previous cell. Please review the code in the cell(s) to identify a possible cause of the failure. Click [here](https://aka.ms/vscodeJupyterKernelCrash) for more info. View Jupyter [log](command:jupyter.viewOutput) for further details.
참고로 cerebras 1.3B model 같은 경우에는 AutoModelForCausalLM과 AutoTokenizer를 이용해서 모델을 불러오고 Generate 하는데에 문제가 없습니다.
맥북은 거의 터미널 용도로만 쓰고 있어서;;; 저도 @mozzipa 님 글 보고 시도해보고 있습니다 ㅎㅎ
M2 MacBook Air (8core, 24GB memory)에서 코드를 돌려보고 있는데요,
작성하신 것처럼 mps 장치로 모델 불러오는 것에는 성공했는데 tokenizer.encode(x, return_tensors="pt").to('mps')를 호출하면 아래처럼 mps 장치를 지원하지 않는 연산 에러가 발생하더라구요
NotImplementedError: The operator 'aten::cumsum.out' is not currently implemented for the MPS device. If you want this op to be added in priority during the prototype phase of this feature, please comment on General MPS op coverage tracking issue · Issue #77764 · pytorch/pytorch · GitHub. As a temporary fix, you can set the environment variable PYTORCH_ENABLE_MPS_FALLBACK=1 to use the CPU as a fallback for this op. WARNING: this will be slower than running natively on MPS.
아래 답변은 OpenAI의 GPT-4 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
안녕하세요! M1 Mac에서 발생하는 문제를 살펴보겠습니다.
먼저, 코드에서 torch.device("mps")를 사용하고 있는데, 이는 Metal Performance Shaders에 대한 지원을 의미합니다. 하지만 현재 PyTorch는 Metal Performance Shaders를 지원하지 않습니다. 따라서, torch.device("cpu")를 사용하여 CPU로 연산을 수행해야 합니다.
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
device = torch.device("cpu")
tokenizer = LlamaTokenizer.from_pretrained("beomi/KoAlpaca")
model = LlamaForCausalLM.from_pretrained("beomi/KoAlpaca").to(device)
또한, 코드에서 사용하신 LlamaForCausalLM과 LlamaTokenizer는 올바른 클래스 이름이 아닙니다. 올바른 클래스 이름은 GPT2LMHeadModel과 GPT2Tokenizer입니다. 따라서 코드를 다음과 같이 수정해야 합니다.
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
device = torch.device("cpu")
tokenizer = GPT2Tokenizer.from_pretrained("beomi/KoAlpaca")
model = GPT2LMHeadModel.from_pretrained("beomi/KoAlpaca").to(device)
수정된 코드를 사용하여 문제가 해결되는지 확인해보시기 바랍니다. 만약 여전히 문제가 발생한다면 추가적인 정보를 제공해주시면 더 도움을 드리겠습니다.