Movie Gen 소개
Movie Gen은 Meta에서 개발한 미디어 생성 모델로, 고해상도 1080p 비디오와 동기화된 오디오를 생성할 수 있는 모델입니다. 이 생성 모델은 다양한 미디어 생성 작업에서 우수한 성능을 발휘하며, 텍스트 프롬프트를 입력으로 받아 비디오 및 이미지를 생성하는 모델입니다. Movie Gen은 비디오 개인화 및 비디오 편집 기능도 포함하고 있어, 사용자 맞춤형 콘텐츠 생성이 가능합니다.
Movie Gen을 사용한 영상 생성 예시
텍스트로 독특한 동영상을 직접 만들어 보세요. Movie Gen은 최초로 고화질 동영상을 다양한 화면 비율로 생성할 수 있습니다.

텍스트 입력 요약: 한 소녀가 연을 들고 해변을 가로질러 달리고 있습니다. 소녀는 청바지와 노란색 티셔츠를 입고 있습니다. 태양이 내리쬐고 있습니다.
Text input summary: A girl is running across a beach and holding a kite. She's wearing jean shorts and a yellow t-shirt. The sun is shining down.
텍스트 입력 요약: 분홍색 선글라스를 쓴 나무늘보가 수영장에 있는 도넛 수레 위에 누워 있습니다. 나무늘보는 열대 음료를 들고 있습니다. 세상은 열대입니다. 햇빛이 그림자를 드리웁니다.
Text input summary: A sloth with pink sunglasses lays on a donut float in a pool. The sloth is holding a tropical drink. The world is tropical. The sunlight casts a shadow.
Movie Gen을 사용한 영상 편집 예시
Movie Gen을 사용하여 스타일과 전환부터 세밀한 편집까지의 정밀한 동영상 편집을 텍스트 입력으로 할 수 있습니다.

Movie Gen을 사용한 개인화된 영상 생성 예시
Movie Gen의 최첨단 모델을 사용하여 이미지를 업로드하고 개인화된 동영상으로 변환하여 사람의 정체성과 움직임을 보존하는 개인 맞춤형 동영상을 만들 수 있습니다.

텍스트 입력 요약: 한 남자가 무지개 벽지가 있는 실험실에서 과학 실험을 하고 있습니다. 남자는 심각한 표정을 짓고 안경을 쓰고 있습니다. 그는 주머니에 펜이 달린 흰색 실험복을 입고 있습니다. 남자가 유리 비커에 액체를 붓자 하얀 연기 구름이 피어오릅니다.
Text input summary: A man is doing a scientific experiment in a lab with rainbow wallpaper. The man has a serious expression and is wearing glasses. He is wearing a white lab coat with a pen in the pocket. The man pours liquid into a glass beaker and a cloud of white smoke blooms.
텍스트 입력 요약: 한 여성이 나무 패널로 된 방에서 이젤 위에 캔버스를 그립니다. 여성은 흰색 셔츠를 입고 있습니다. 그녀는 차분한 표정으로 작업에 집중하고 있습니다. 그녀의 발밑에는 새끼 곰 한 마리가 서 있습니다. 조명은 차분합니다.
Text input summary: A woman paints a canvas on an easel, in a wood-paneled room. The woman is wearing a white shirt. She has a calm expression as she concentrates on her work. A baby bear cub stands at her feet. The lighting is cool.
Movie Gen을 사용한 음향 효과 및 사운드 트랙 생성 예시

텍스트 입력: 음악이 배경에서 재생되는 가운데 절벽과 사람을 향해 비가 쏟아집니다.
Text input: Rain pours against the cliff and the person, with music playing in the background.
텍스트 입력: 기타 음악과 함께 ATV 엔진이 굉음을 내며 가속합니다.
Text input: ATV engine roars and accelerates, with guitar music.
Movie Gen 모델의 주요 구조
Movie Gen 모델의 구조는 고화질의 비디오와 동기화된 오디오를 생성할 수 있는 고도화된 AI 시스템으로 설계되어 있습니다. 기본 구조는 트랜스포머(Transformer) 아키텍처를 중심으로 하며, 이미지를 생성하는 것뿐만 아니라 비디오, 오디오 생성까지 다양한 미디어 작업을 처리할 수 있는 능력을 가지고 있습니다. Movie Gen은 특히 텍스트-비디오 생성, 비디오 개인화, 비디오 편집, 비디오-오디오 및 텍스트-오디오 생성에서 최첨단 기술을 적용합니다. Movie Gen 모델의 구조와 관련하여 각 부분을 살펴보겠습니다:
이미지 및 비디오 생성 백본
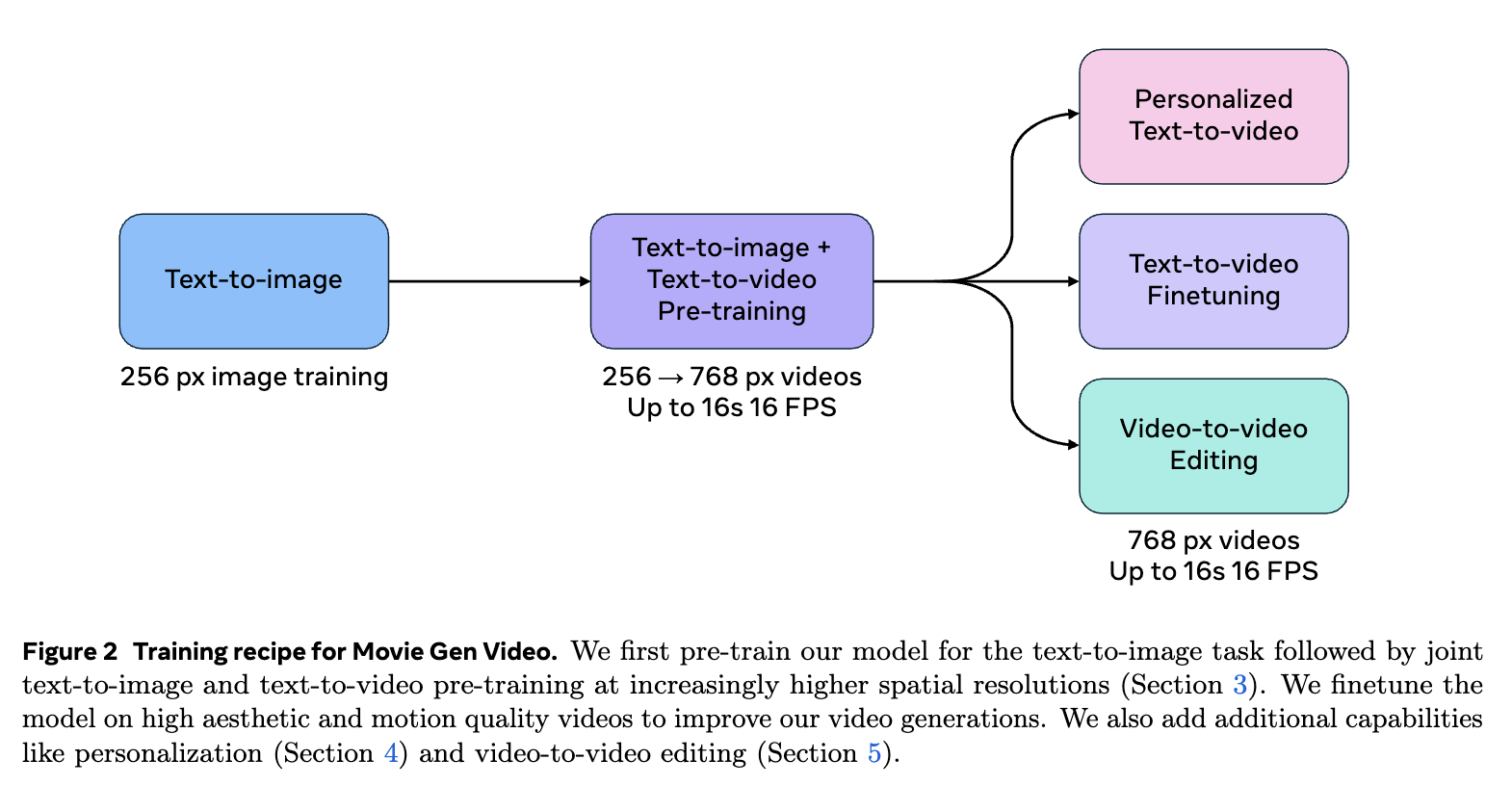
Movie Gen의 백본 구조는 텍스트로부터 이미지를 생성하는 능력과 비디오를 생성하는 능력을 모두 포함합니다. 트랜스포머 기반의 이 모델은 텍스트 프롬프트를 입력으로 받아, 고해상도 이미지를 생성하거나 여러 RGB 프레임을 조합하여 비디오를 생성합니다. 특히 이 모델은 이미지와 비디오 데이터를 동시에 처리할 수 있으며, 이를 통해 학습된 비디오는 모션 및 장면의 변화를 자연스럽게 표현합니다.
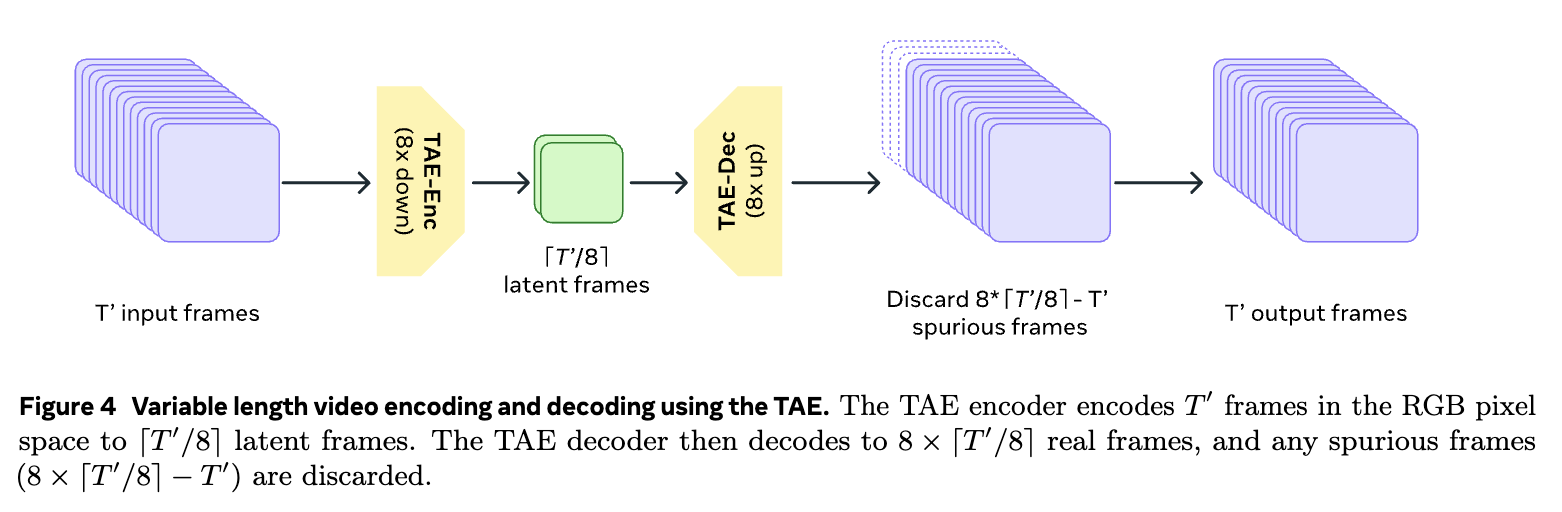
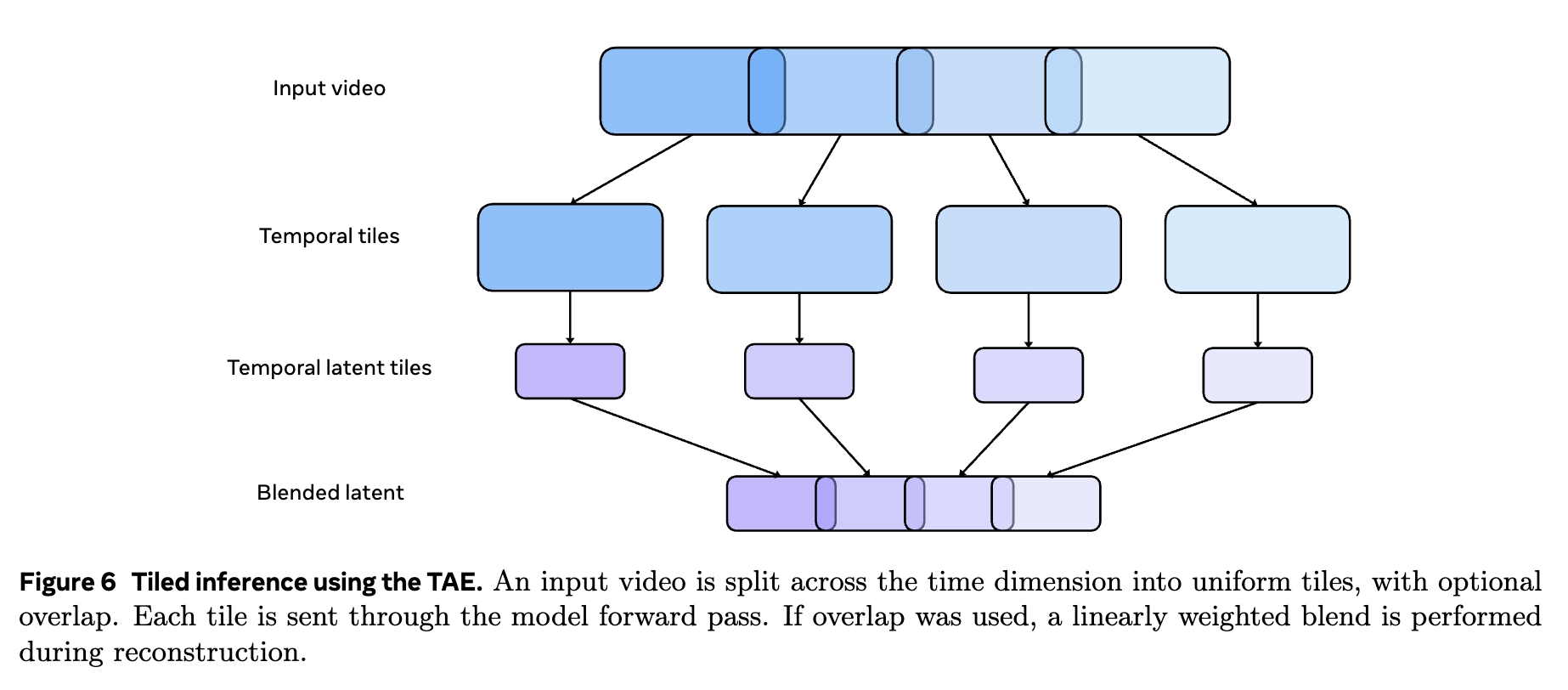
TAE(Temporal Autoencoder, 시간적 오토인코더)
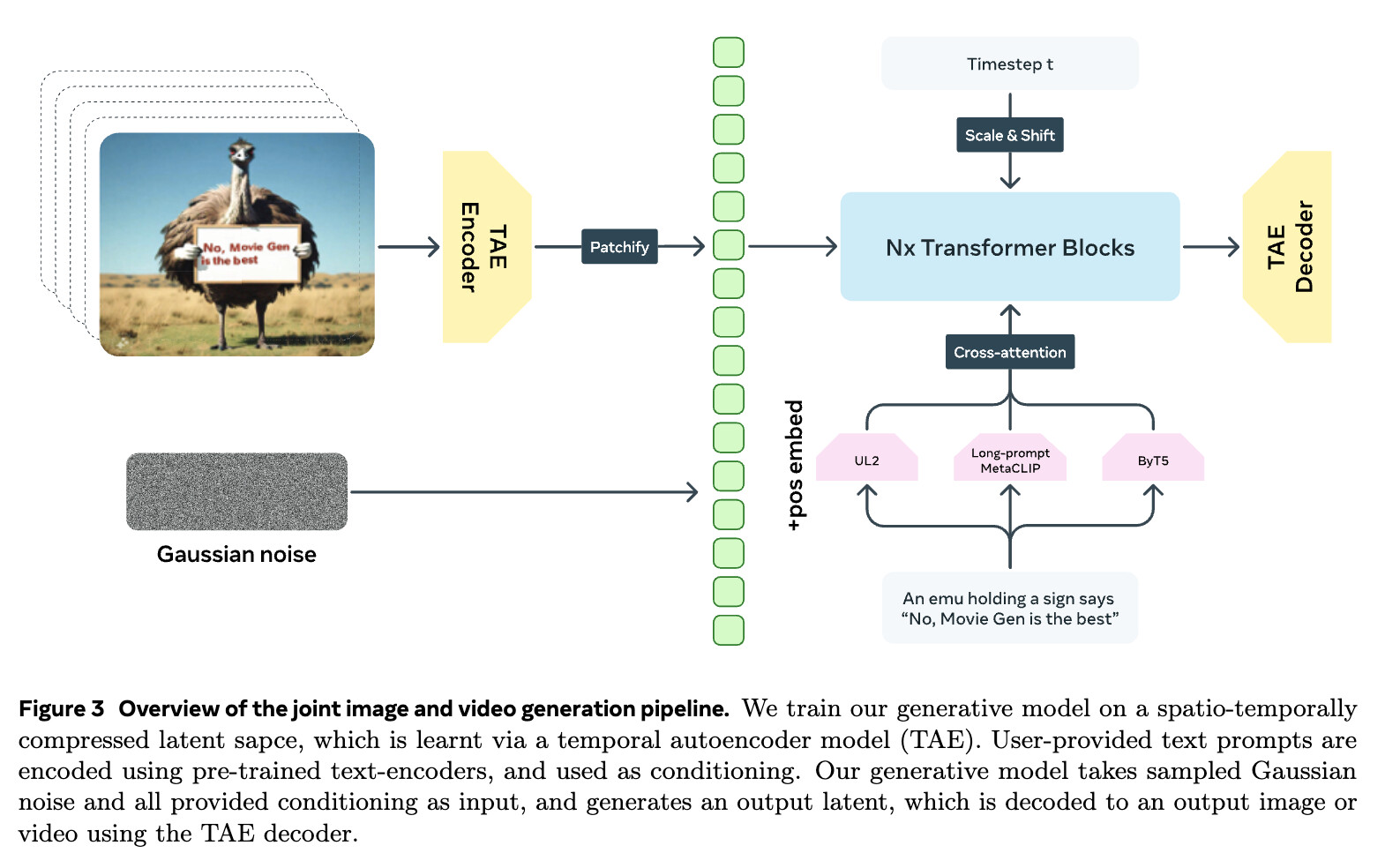
TAE(시간적 오토인코더)는 이미지 및 비디오를 시간적 및 공간적 압축을 담당하는 주요 구성요소입니다. TAE는 이미지 및 비디오 데이터를 잠재 공간(latent space)에 매핑하여 트랜스포머 모델로 하여금 처리하도록 하는 역할을 하며, 이를 통해 고해상도 비디오나 긴 비디오 시퀀스를 효과적으로 처리할 수 있습니다. TAE는 VAE(Variational Autoencoder, 변분 오토인코더)를 기반으로 설계되어 있으며, RGB 이미지나 비디오 프레임을 잠재 공간으로 압축한 후 다시 디코딩하여 이미지나 비디오로 복원합니다. 이 과정에서 시간적 압축을 통해 효율적으로 처리하는 방식으로, 프레임의 일관성을 유지하면서 해상도 비디오 및 긴 비디오 시퀀스를 생성할 수 있습니다.
학습 목표 (Training Objective)
Movie Gen은 플로우 매칭(Flow Matching) 기법을 사용하여 학습됩니다. 이 방법을 통해 모델은 주어진 비디오의 모션을 예측하고, 이를 기반으로 비디오 프레임 간의 변화율(velocity)을 학습합니다. 이 과정에서 트랜스포머는 입력된 텍스트 프롬프트와 잠재 벡터를 사용하여 자연스럽고 일관된 비디오를 생성하게 됩니다.
Movie Gen의 텍스트-이미지 및 텍스트-비디오 생성
모델 학습 및 추론
Movie Gen은 다양한 데이터셋을 활용해 훈련됩니다. 먼저 256px 저해상도 이미지로 사전 학습을 진행하고, 이후 더 높은 해상도의 이미지와 비디오 데이터를 사용하여 모델을 미세 조정합니다. 텍스트 임베딩은 주어진 텍스트 프롬프트를 기반으로 생성되며, 이를 바탕으로 비디오가 생성됩니다. 추론 과정에서는 텍스트와 노이즈 데이터를 받아 이를 고해상도 비디오로 변환합니다.
성능 향상 방법
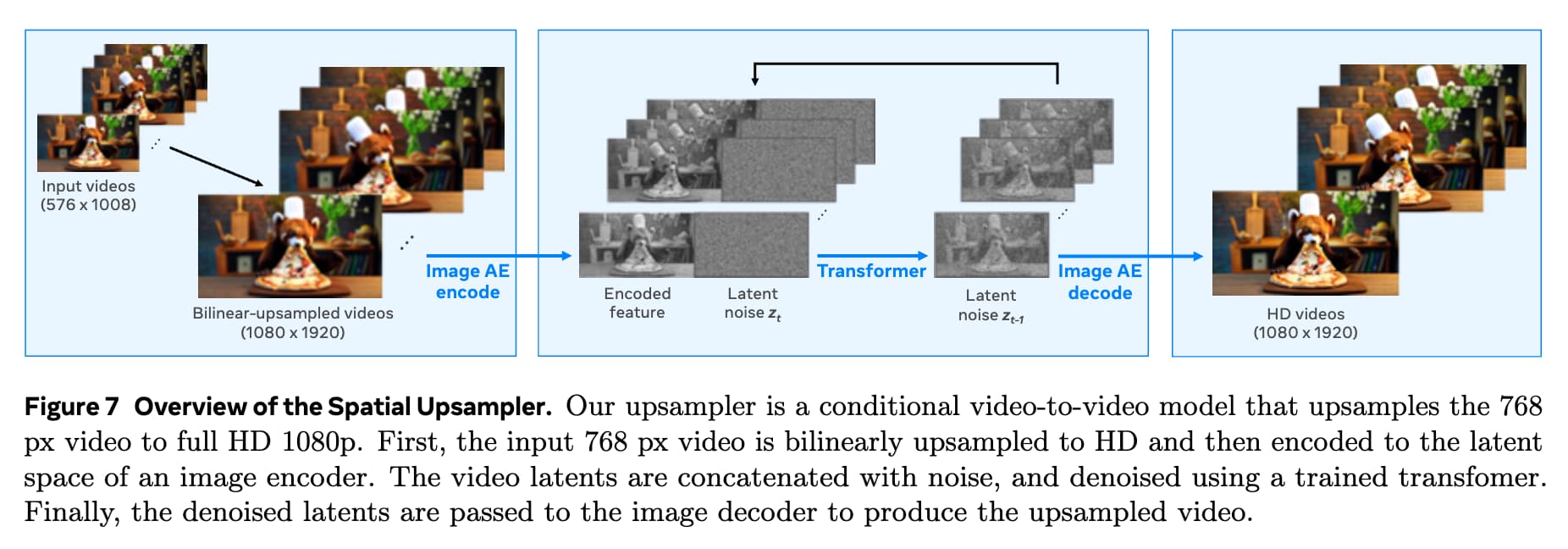
Movie Gen은 공간적 업스케일링(Spatial Upscaling)을 통해 고해상도 비디오를 생성할 수 있습니다. 기본적으로 모델은 768px 해상도의 비디오를 생성하며, 이를 1080p HD 해상도로 업스케일할 수 있습니다. 이러한 과정을 통해 더 높은 해상도의 비디오가 생성되는 과정을 설명합니다.
오디오 생성 및 확장 모델
텍스트-오디오 및 비디오-오디오 생성
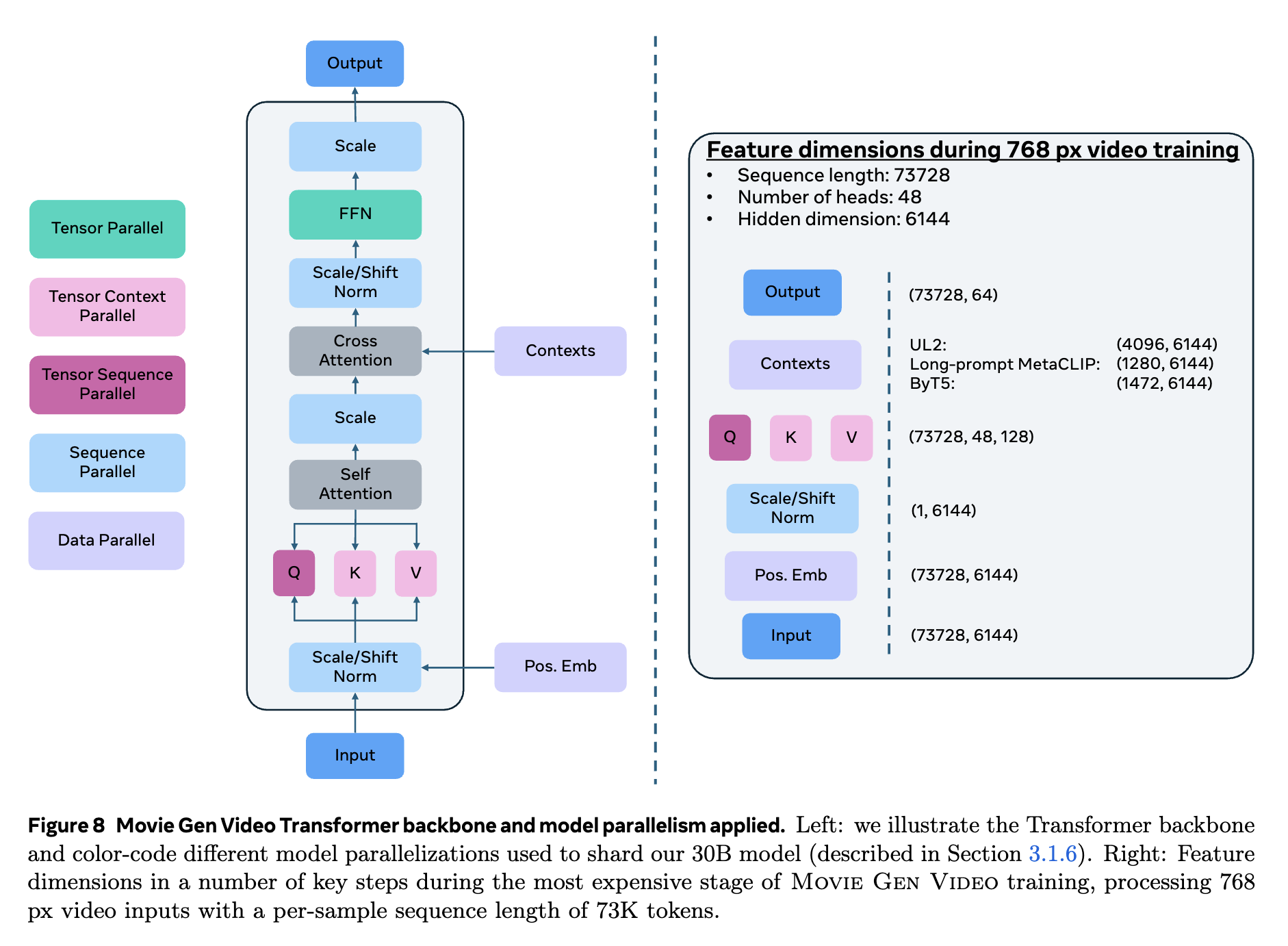
Movie Gen은 비디오와 동기화된 오디오를 생성할 수 있는 능력도 가지고 있습니다. 텍스트 또는 비디오 프롬프트를 입력받아 이에 맞는 사운드를 생성하며, 48kHz 고품질의 사운드를 제공합니다. 이를 통해 생성된 비디오는 시각적 장면과 자연스럽게 맞아떨어지는 배경음과 효과음을 가질 수 있습니다.
오디오 확장 및 영화음악 생성
Movie Gen 오디오 모델은 텍스트-오디오 및 비디오-오디오 생성뿐만 아니라, 긴 비디오에 맞는 배경음악을 생성하는 확장 기능도 포함하고 있습니다. 이 기능은 비디오의 분위기나 모션에 맞추어 배경음과 효과음을 자연스럽게 조합하는 데 사용됩니다.
비디오 개인화 및 편집 기능
개인화된 비디오 생성
Movie Gen은 개인화된 비디오 생성 기능을 지원합니다. 이를 통해 사용자가 제공한 이미지를 기반으로 맞춤형 비디오를 생성할 수 있습니다. 예를 들어, 사용자가 제공한 얼굴 이미지를 텍스트 프롬프트와 결합하여 그 인물이 특정 장면에서 행동하는 비디오를 생성할 수 있습니다. 이 과정에서 인물의 정체성은 유지되며, 다양한 상황을 기반으로 맞춤형 콘텐츠가 생성됩니다.
비디오 편집 기능
Movie Gen은 비디오 편집 기능도 제공합니다. 사용자는 텍스트 프롬프트를 입력하여 기존 비디오를 수정하거나, 생성된 비디오에서 특정 부분을 변경할 수 있습니다. 예를 들어 배경을 변경하거나 특정 요소를 추가 및 제거하는 작업이 가능합니다.
평가 및 비교
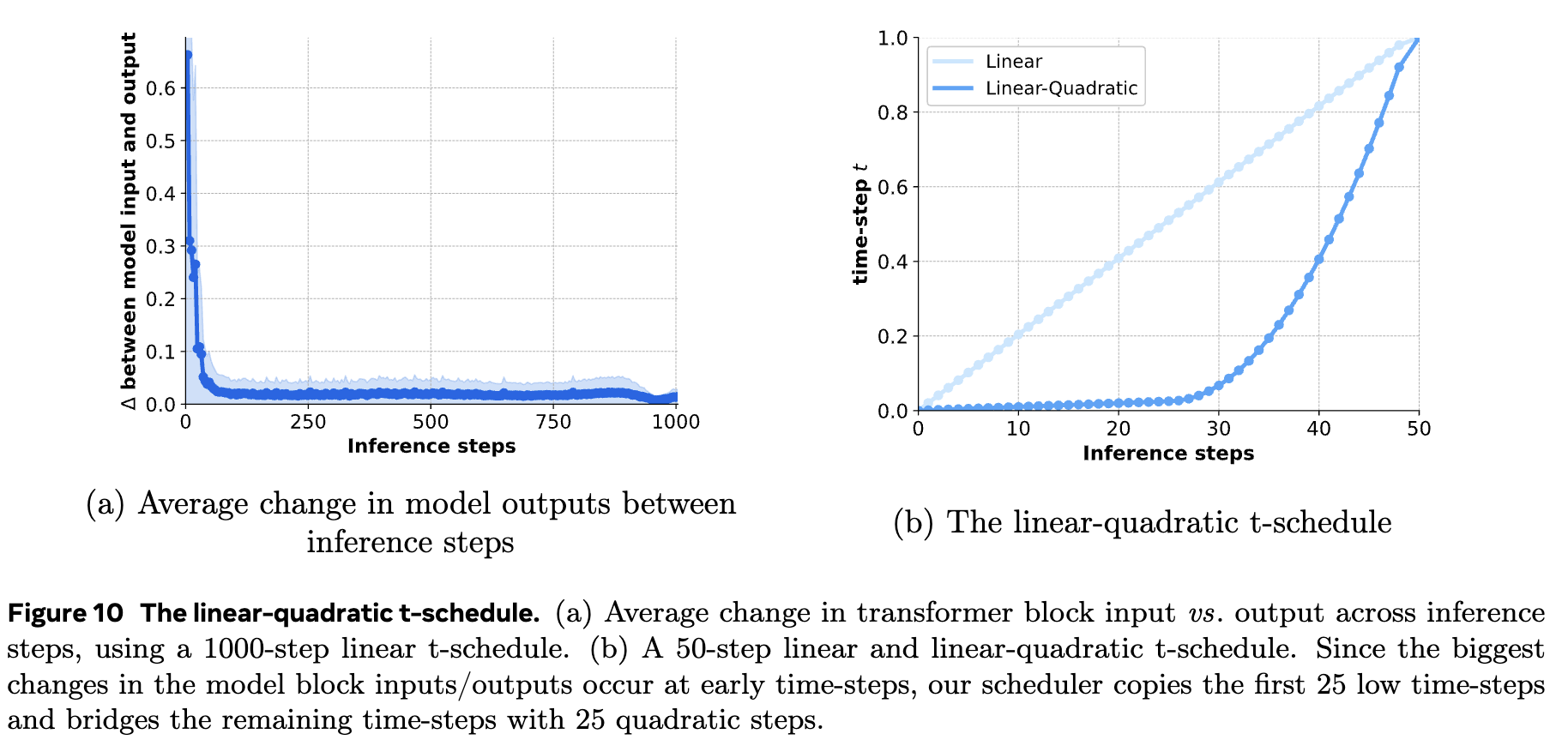
Movie Gen은 다양한 평가 지표를 사용하여 성능을 측정합니다. 특히 인간 평가자들이 비디오의 일관성, 자연스러운 모션, 텍스트와의 일치성을 평가합니다. 이 과정을 통해 모델의 성능을 정량화할 수 있습니다.
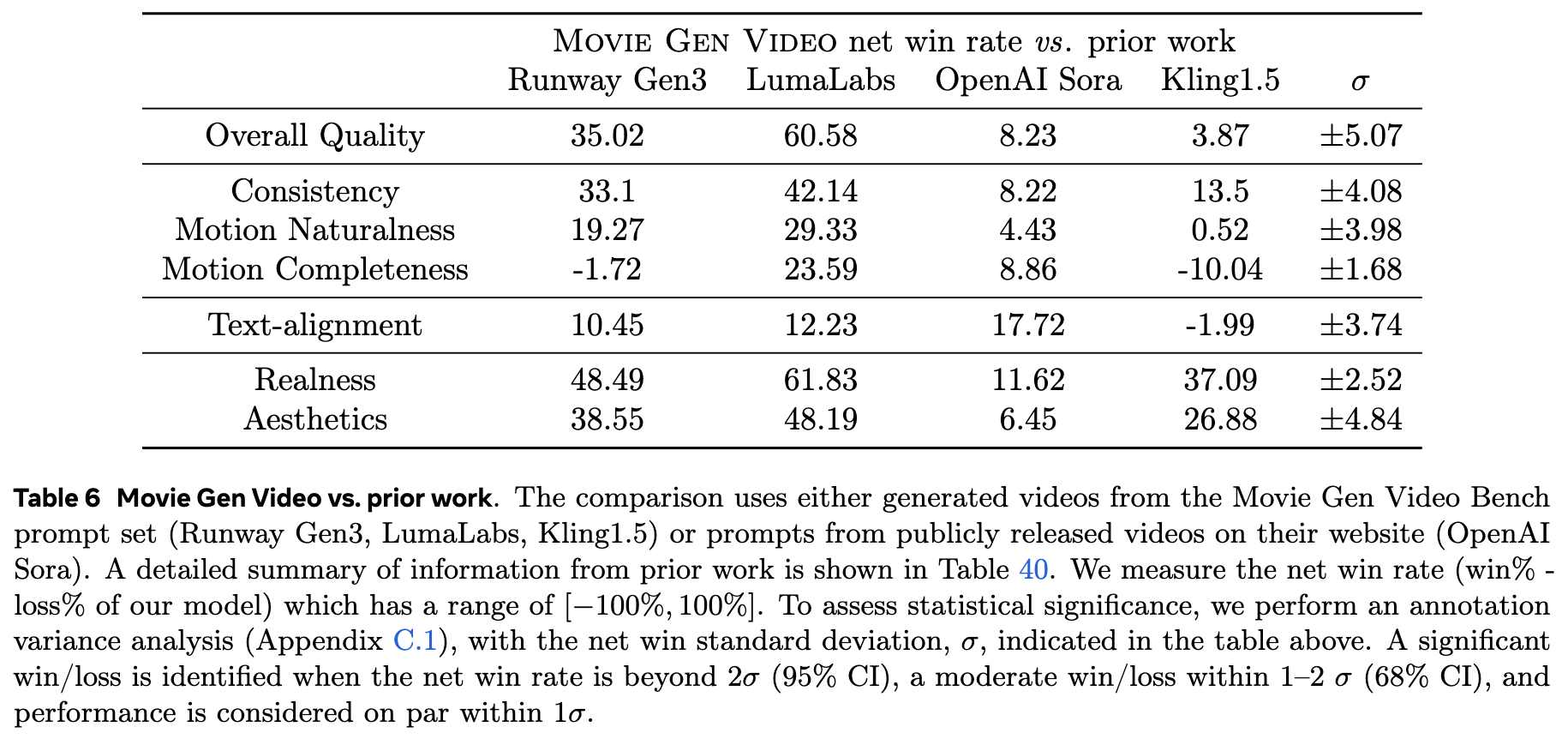

Movie Gen은 기존의 상업적 시스템인 Runway Gen3, LumaLabs, OpenAI Sora 등과 비교하여 우수한 성능을 보였습니다. 특히 텍스트 프롬프트와의 일치성, 비디오의 모션 일관성, 자연스러움 면에서 뛰어난 성능을 발휘했습니다.
 Meta AI의 Movie Gen 모델 소개 글
Meta AI의 Movie Gen 모델 소개 글
 Movie Gen 연구 논문 읽기
Movie Gen 연구 논문 읽기
https://ai.meta.com/static-resource/movie-gen-research-paper
 Movie Gen으로 생성한 예시 영상들 (YouTube Playlist)
Movie Gen으로 생성한 예시 영상들 (YouTube Playlist)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()