
Segment Anything Model 3 (SAM 3) 개요
인공지능(AI) 기술의 급격한 발전 속에서 컴퓨터 비전(Computer Vision) 분야는 단순한 객체 감지(Object Detection)를 넘어 이미지 내의 모든 요소를 픽셀 단위로 이해하고 분할(Segmentation)하는 방향으로 진화하고 있습니다. 특히 Meta(메타)의 FAIR(Fundamental AI Research) 팀이 주도하는 'Segment Anything' 프로젝트는 이러한 흐름의 최전선에 있으며, 최근 공개된 Segment Anything Model 3 (SAM 3) 는 기존 모델들이 해결하지 못했던 '개방형 어휘(Open-Vocabulary)에 기반한 개념적 분할'이라는 난제를 해결함으로써 범용 비전 모델의 새로운 이정표를 세웠습니다.
Segmentation Task의 역사적 맥락과 한계점
이미지 분할은 입력 이미지의 각 픽셀을 특정 클래스(예: 사람, 자동차, 배경)로 분류하는 작업으로, 자율 주행, 의료 영상 분석, 로보틱스 등 다양한 산업의 기반 기술로 활용됩니다. 전통적인 딥러닝 기반의 분할 모델들은 COCO나 ImageNet과 같은 데이터셋에 정의된 고정된 클래스 목록(Fixed Class List)에 대해서만 학습되었습니다. 이러한 폐쇄형(Closed-set) 접근 방식은 모델이 학습하지 않은 새로운 객체나 추상적인 개념을 인식하지 못한다는 근본적인 한계를 지니고 있었습니다. 예를 들어, "바퀴"를 학습한 모델은 "자전거 바퀴"와 "자동차 바퀴"를 구분할 수 있지만, "오래된 녹슨 금속 부품"이라는 추상적인 텍스트 쿼리에는 대응하지 못하는 경우가 많았습니다.

2023년 공개된 초기 SAM(Segment Anythin Model)은 이러한 문제에 대해 '프롬프트 가능한 분할(Promptable Segmentation)'이라는 새로운 패러다임을 제시했습니다. 점(Point), 박스(Box)와 같은 기하학적 프롬프트를 통해 사용자가 원하는 대상을 지정하면, 클래스 정보 없이도 해당 객체를 정밀하게 분할하는 제로샷(Zero-shot) 일반화 능력을 보여주었습니다. 이어 출시된 SAM 2는 이를 동영상 영역으로 확장하여 시간적 연속성을 가진 객체 추적 및 분할을 가능하게 했습니다. 그러나 SAM 1과 SAM 2는 여전히 텍스트와 같은 고차원적인 의미 정보를 직접 이해하는 데에는 한계가 있었습니다. 이들 모델은 "어디(Where)"를 분할해야 하는지는 시각적 힌트를 통해 알 수 있었지만, "무엇(What)"을 분할해야 하는지 언어적으로 이해하는 능력은 결여되어 있었습니다.
SAM 3의 등장 배경: Promptable Concept Segmentation (PCS)

SAM 3는 이러한 '의미론적 이해(Semantic Understanding)'의 공백을 메우기 위해 등장했습니다. Meta 연구진은 이를 위해 **Promptable Concept Segmentation (PCS)**이라는 새로운 과제를 정의했습니다. PCS는 이미지나 비디오 내에서 텍스트(명사구)나 이미지 예시(Exemplar)로 주어지는 '개념(Concept)'에 해당하는 모든 객체 인스턴스를 찾아내고, 분할하며, 비디오의 경우 추적까지 수행하는 통합적인 작업입니다. 이는 기존의 단일 객체 분할(PVS: Promptable Visual Segmentation)이 사용자가 지정한 특정 위치의 객체 하나만을 분할했던 것과는 대조적입니다.
SAM 3는 "영상 속의 모든 줄무늬 고양이를 찾아줘"와 같은 집합적이고 개념적인 요청을 처리할 수 있습니다. 이는 모델이 단순한 시각적 유사성을 넘어 텍스트가 지칭하는 의미론적 범주를 이해하고, 이를 이미지 내의 시각적 특징과 매핑해야 함을 의미합니다. 이러한 능력은 검색 기반의 비전 애플리케이션, 자동화된 미디어 편집 도구, 그리고 로보틱스 분야에서 인간과 AI 간의 상호작용 효율성을 획기적으로 높일 수 있는 잠재력을 가지고 있습니다.
SAM 3 아키텍처: 통합과 분리의 엔지니어링


SAM 3의 아키텍처 설계 철학은 '통합(Unification)'과 '분리(Decoupling)'의 조화로 요약될 수 있습니다. 이미지 수준의 탐지기(Detector)와 비디오 수준의 추적기(Tracker)가 하나의 거대한 백본을 공유하면서도, 각 모듈은 서로 간섭하지 않고 고유의 역할에 집중하도록 설계되었습니다. 이는 대규모 모델의 효율성을 확보하면서도 복잡한 다중 작업을 수행하기 위한 고도의 엔지니어링 결과물입니다.
Perception Encoder (PE): 시각과 언어의 정렬된 임베딩
SAM 3의 가장 근본적인 변화는 백본 네트워크의 교체입니다. SAM 2가 MAE(Masked Autoencoder) 기반의 Hiera와 같은 비전 특화 인코더를 사용했던 것과 달리, SAM 3는 Meta가 개발한 Perception Encoder (PE) 를 채택했습니다. PE는 단순한 시각적 특징 추출기가 아니라, 대규모 이미지-텍스트 쌍을 통해 사전 학습되어 시각 정보와 언어 정보가 동일한 임베딩 공간에 정렬(Aligned)되도록 학습된 모델입니다.
소프트웨어 엔지니어의 관점에서 볼 때, 이는 입력 데이터의 전처리 및 특징 추출 단계에서부터 멀티모달(Multimodal) 처리가 내재화되어 있음을 의미합니다. 텍스트 인코더와 이미지 인코더가 별도로 동작하지 않고, "붉은색 모자"라는 텍스트 임베딩과 실제 이미지 내의 붉은색 모자 영역의 피처 벡터가 수학적으로 높은 유사도를 가지게 됩니다. 이러한 구조적 특성 덕분에 SAM 3는 추가적인 복잡한 매핑 레이어 없이도 텍스트 프롬프트에 즉각적으로 반응할 수 있으며, 이는 제로샷 성능 향상의 결정적인 요인이 됩니다.
Detector와 Presence Head: 인식(Recognition)과 위치 추정(Localization)의 분리
SAM 3의 Detector는 DETR(DEtection TRansformer) 아키텍처를 기반으로 하지만, 개방형 어휘 처리를 위해 중요한 구조적 변경이 적용되었습니다. 일반적인 객체 탐지 모델은 "객체가 무엇인가(Class)"와 "어디에 있는가(Box/Mask)"를 동시에 예측합니다. 그러나 수만 가지의 개념을 다루는 개방형 어휘 환경에서는, 이미지에 존재하지 않는 개념에 대해서도 모델이 억지로 위치를 찾아내려는 '환각(Hallucination)' 현상이 빈번하게 발생합니다.
이 문제를 해결하기 위해 SAM 3는 Presence Head라는 독창적인 모듈을 도입하여 인식과 위치 추정 과정을 분리했습니다.
- Presence Prediction (Global): 모델은 먼저 입력된 텍스트 프롬프트(개념)가 해당 이미지 전체에 존재하는지 여부(P(\text{Presence}))를 판단하는 전역적인 점수를 예측합니다. 이는 이미지 전체의 문맥을 고려하는 작업입니다.
- Localization Prediction (Local): 개별 객체 쿼리(Object Query)들은 "만약 그 개념이 존재한다면, 구체적으로 어디에 위치하는가?"라는 국소적인 문제(P(\text{Local}|\text{Presence}))에 집중합니다.
최종적인 객체 점수는 이 두 확률의 곱으로 계산됩니다. 이러한 분리 설계는 하드 네거티브(Hard Negative), 즉 이미지에 존재하지 않지만 혼동하기 쉬운 개념들을 효과적으로 필터링하는 역할을 합니다. 예를 들어, '사과'가 없는 이미지에 '붉은 공'이 있을 때, 기존 모델은 이를 사과로 오탐지할 가능성이 높지만, Presence Head는 이미지 전반의 문맥을 파악하여 '사과'라는 개념 자체가 부재함을 먼저 판단함으로써 오탐지를 방지합니다.
Tracker: 메모리 기반의 시공간 추적 시스템
비디오 처리를 담당하는 Tracker 모듈은 SAM 2에서 검증된 메모리 뱅크(Memory Bank)와 메모리 어텐션(Memory Attention) 메커니즘을 계승하여 발전시켰습니다. 비디오 데이터는 시간축(Temporal Axis)을 포함하므로, 객체는 프레임마다 모양이 변하거나, 가려지거나(Occlusion), 화면 밖으로 사라졌다 다시 나타날 수 있습니다. SAM 3는 이를 처리하기 위해 Masklet이라는 시공간적 단위를 사용합니다.
-
초기화 및 전파: 첫 프레임에서 Detector가 찾아낸 객체 정보는 메모리 뱅크에 저장됩니다. 이후 프레임에서는 Tracker가 이 메모리 정보를 참조(Query)하여 현재 프레임에서의 객체 위치를 예측하고 마스크를 전파(Propagate)합니다.
-
매칭 및 ID 유지: 새로운 객체가 등장하거나 기존 객체가 재등장하는 상황을 처리하기 위해, SAM 3는 매 프레임마다 Detector를 실행하고, 그 결과를 Tracker의 예측값과 매칭(Matching)합니다. 이때 시각적 유사성과 공간적 겹침(IoU) 정보를 종합적으로 활용하여 객체의 고유 ID를 유지합니다.
-
모듈간 결합: Detector와 Tracker가 Perception Encoder를 공유하는 구조(Tightly Coupled)는 메모리 효율성을 높일 뿐만 아니라, 강력한 이미지 인식 능력이 비디오 추적의 견고함을 뒷받침하는 시너지 효과를 냅니다.
SAM 3의 데이터 엔진과 SA-Co 벤치마크

최신 AI 모델의 성능은 아키텍처뿐만 아니라 학습 데이터의 품질과 양에 의해 결정됩니다. Meta는 SAM 3를 위해 기존의 데이터 구축 방식을 혁신한 데이터 엔진(Data Engine)을 개발했으며, 이를 통해 전례 없는 규모의 고품질 데이터셋을 구축했습니다.
4단계 데이터 엔진 파이프라인
SAM 3의 데이터 엔진은 "인간과 AI의 협업(Human-AI Collaboration)"을 통해 데이터 구축의 효율성과 품질을 동시에 달성하는 전략을 취했습니다. 이 과정은 크게 아래와 같은 4단계로 구분됩니다:
-
1단계. Media Curation: 웹상의 편향된 이미지뿐만 아니라 다양한 도메인(의료, 수중, 문서 등)을 아우르는 광범위한 미디어 소스를 확보하여 모델의 일반화 능력을 제고했습니다.
-
2단계. Label Curation: 온톨로지(Ontology)와 LLM을 활용하여 단순 객체명을 넘어 복잡한 명사구를 생성했습니다. 특히 모델 학습에 필수적인 하드 네거티브(Hard Negative) 라벨을 의도적으로 생성하여 모델의 변별력을 강화했습니다.
-
3단계. Label Verification: 미세 조정된 Llama 기반 VLM을 **AI 검증자(AI Verifier)**로 활용하여 생성된 마스크의 품질과 포괄성(Exhaustivity)을 1차 검증했습니다. 이는 인간 작업자의 부하를 줄이고 전체 파이프라인의 처리량(Throughput)을 획기적으로 높였습니다.
-
4단계. Video Annotation: 앞선 단계의 프로세스를 비디오 데이터로 확장하여 시공간적 일관성을 가진 마스크 데이터(Masklet)를 구축했습니다.
이 데이터 엔진을 통해 구축된 데이터셋은 약 400만 개의 고유 개념과 5,200만 개의 마스크를 포함하고 있으며, 합성 데이터까지 포함할 경우 3,800만 개의 구문과 14억 개의 마스크라는 압도적인 규모를 자랑합니다.10 특히 AI 검증자의 도입은 인간 검수자 대비 약 5배 빠른 속도로 네거티브 프롬프트를 처리할 수 있게 하여, 데이터 구축 비용과 시간을 획기적으로 단축시켰습니다.
SA-Co 벤치마크: 개방형 어휘 분할의 새로운 표준
Meta는 구축된 데이터의 일부를 정제하여 **Segment Anything with Concepts (SA-Co)**라는 새로운 벤치마크를 공개했습니다. SA-Co는 약 20만 7천 개의 고유 개념을 포함하고 있으며, 이는 LVIS와 같은 기존 벤치마크 대비 50배 이상 방대한 어휘 규모입니다. SA-Co는 모델이 얼마나 다양한 개념을 이해하고 정확하게 분할할 수 있는지를 측정하는 'Promptable Concept Segmentation' 성능 평가의 골드 스탠다드(Gold Standard)가 될 것입니다. SA-Co 데이터셋은 SA-Co/Gold, SA-Co/Silver 및 비디오 벤치마킹을 위한 SA-Co/VEval 등의 하위 집합으로 구성되어 있으며, 각각 다른 수준의 검증 강도를 가지고 있어 연구 목적에 맞게 활용될 수 있습니다.

SA-Co 데이터셋은 Hugging Face와 Roboflow에서 다운로드 받을 수 있습니다:
-
SA-Co/Gold 데이터셋: Hugging Face Link, Roboflow Link
-
SA-Co/Silver 데이터셋: Hugging Face Link, Roboflow Link
-
SA-Co/VEval 데이터셋: Hugging Face Link, Roboflow Link
더 상세한 내용은 SAM 3 GitHub 저장소 README 문서의 SA-Co 데이터셋 섹션을 참고해주세요.
성능 평가 및 기술적 사양

가장 주목할 만한 성과는 제로샷(Zero-shot) 성능입니다. SAM 3는 LVIS 데이터셋 기준 제로샷 마스크 AP(Average Precision) 47.0을 기록했습니다. 이는 기존 최고 성능 모델의 38.5 대비 약 22% 향상된 수치입니다. 또한, 자체 구축한 SA-Co 벤치마크에서는 기존 시스템 대비 2배 이상의 성능 향상을 입증했습니다.

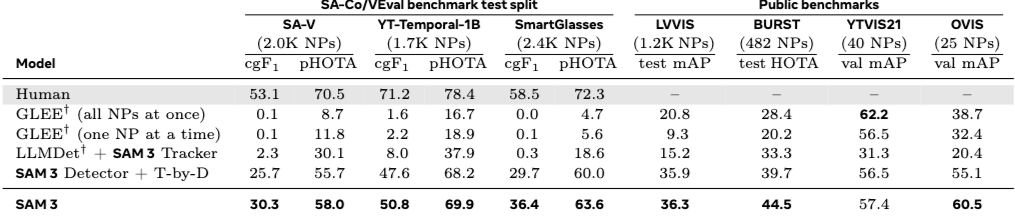
| 평가 지표 | SAM 3 성능 | 기존 SOTA 모델 | 비고 |
|---|---|---|---|
| LVIS Zero-shot Mask AP | 47.0 | 38.5 | 약 22% 성능 향상 |
| SA-Co Benchmark | 2x Gain | - | 기존 시스템 대비 2배 성능 |
| SA-V Test (Video) | 30.3 cgF1 | - | 비디오 PCS 성능의 새로운 기준 |
이러한 수치는 SAM 3가 별도의 파인 튜닝 없이도 현업의 다양한 도메인(자연, 제조, 의료 등)에 즉시 투입되어 유의미한 결과를 낼 수 있음을 시사합니다. 이는 엔지니어링 관점에서 모델 배포 및 유지보수에 드는 비용(TCO, Total Cost of Ownership)을 크게 낮출 수 있는 요인입니다.
추론 속도 및 하드웨어 요구사항

고성능 모델은 필연적으로 높은 연산 비용을 수반하지만, SAM 3는 최적화된 아키텍처를 통해 실용적인 수준의 추론 속도를 달성했습니다.
-
추론 속도: NVIDIA H200 GPU 기준으로 100개 이상의 객체가 포함된 단일 이미지를 처리하는 데 약 30ms가 소요됩니다. 이는 초당 약 33프레임을 처리할 수 있는 속도로, 실시간 애플리케이션에도 충분히 적용 가능한 수준입니다.
-
비디오 처리: 비디오 추론 시 지연 시간(Latency)은 추적하는 객체의 수에 선형적으로 비례(Linear Scaling)하여 증가합니다. 실험 결과, 약 5개의 객체를 동시에 추적할 때까지는 실시간 처리가 가능한 수준(Near Real-time)을 유지하는 것으로 나타났습니다.
-
VRAM 요구사항: SAM 3는 약 840M 파라매터 규모의 모델로, 파일 크기는 약 3.44GB입니다. 추론을 위해서는 모델 가중치뿐만 아니라 중간 연산 결과(Activation)를 저장할 메모리가 필요하므로, 최소 24GB 이상의 VRAM을 갖춘 GPU(예: RTX 3090/4090, A10G)가 권장됩니다. 특히 비디오 처리 시에는 메모리 뱅크가 VRAM을 추가로 점유하므로, A100이나 H100과 같은 서버급 GPU 환경이 안정적입니다. 소비자용 GPU에서 구동할 경우, FP16이나 INT8 양자화(Quantization) 기술을 적용하거나 배치 사이즈를 줄이는 최적화가 필수적입니다.
SAM 3 설치 및 환경 설정
SAM 3는 PyTorch 기반으로 구현되어 있으며, 최신 기능을 활용하기 위해 Python 3.12 이상, PyTorch 2.7 이상, CUDA 12.6 이상의 환경을 권장합니다. 하드웨어 가속을 위해 NVIDIA GPU 드라이버와 CUDA 툴킷의 버전 호환성을 사전에 확인해야 합니다.
# Conda 가상 환경 생성 및 활성화
conda create -n sam3 python=3.12
conda activate sam3
# PyTorch 및 관련 라이브러리 설치 (CUDA 버전 확인 필수)
pip install torch==2.7.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# SAM 3 공식 저장소 복제(Clone) 및 설치
git clone https://github.com/facebookresearch/sam3.git
cd sam3
pip install -e .
Hugging Face나 Meta의 공식 라이브러리를 통해 모델을 로드하고 추론을 수행하는 기본적인 파이프라인은 아래 예시 코드를 참고해주세요. 텍스트 프롬프트를 사용하여 이미지를 분할하는 예시입니다:
import torch
from PIL import Image
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
# 1. 모델 로드 및 GPU 할당
# VRAM 용량에 따라 device 설정을 'cuda' 또는 'cpu'로 변경
device = "cuda" if torch.cuda.is_available() else "cpu"
model = build_sam3_image_model().to(device)
processor = Sam3Processor(model)
# 2. 이미지 전처리 및 상태 초기화
image_path = "example_image.jpg"
image = Image.open(image_path).convert("RGB")
# 이미지를 모델 입력 형식으로 변환하고 인코더를 실행하여 특징 추출
inference_state = processor.set_image(image)
# 3. 텍스트 프롬프트를 통한 추론 수행 (PCS)
# "a striped cat", "red car wheel" 등 구체적인 텍스트 입력 가능
text_prompt = "a striped cat"
output = processor.set_text_prompt(
state=inference_state,
prompt=text_prompt
)
# 4. 결과 파싱
masks = output["masks"] # 분할된 마스크 (Boolean or Probability Map)
boxes = output["boxes"] # 객체 경계 상자 (Bounding Boxes)
scores = output["scores"] # 모델의 확신도 (Confidence Scores)
print(f"Detected {len(masks)} objects matching '{text_prompt}'.")
배포 및 최적화 전략
실제 프로덕션 환경에 SAM 3를 배포할 때는 단순한 코드 실행을 넘어 시스템 아키텍처 관점에서의 최적화가 필요합니다. 주로 고려해야 할 사항은 다음과 같습니다:
-
비동기 처리 아키텍처: SAM 3의 추론 시간(30ms+)은 웹 서비스의 관점에서는 다소 무거울 수 있습니다. 따라서 사용자 요청을 직접 처리하기보다는 Celery, Redis Queue, Kafka 등을 활용한 비동기 작업 큐(Task Queue) 방식을 도입하는 것이 좋습니다. 프론트엔드에서는 요청 ID만 반환하고, 백그라운드 워커(Worker)가 GPU 자원을 점유하며 순차적으로 추론을 수행한 뒤 결과를 저장소에 업데이트하는 패턴이 권장됩니다.
-
메모리 관리 및 배치 처리:
inference_state객체는 이미지의 고차원 피처 맵을 저장하므로 메모리를 많이 점유합니다. 추론이 완료된 후에는 반드시 리소스를 해제해야 합니다. 또한, 실시간 스트리밍이 아닌 일괄 처리 작업의 경우,torch.utils.data.DataLoader를 활용하여 적절한 크기의 배치(Batch) 단위로 추론을 수행하면 GPU의 처리량을 극대화할 수 있습니다. -
모델 최적화 (Quantization & Compilation):
torch.compile기능을 활용하여 모델의 계산 그래프를 최적화하거나, TensorRT와 같은 추론 전용 엔진으로 변환하여 지연 시간을 줄일 수 있습니다. 또한, FP32(32비트 부동소수점) 대신 FP16(16비트)이나 BF16을 사용하면 성능 저하를 최소화하면서도 메모리 사용량을 절반으로 줄이고 연산 속도를 높일 수 있습니다.
SAM 3 Agent: MLLM과의 결합


SAM 3는 단독으로도 강력하지만, 멀티모달 대규모 언어 모델(MLLM)과 결합될 때 SAM 3 Agent로서 더욱 복잡하고 지능적인 작업을 수행할 수 있습니다. MLLM은 사용자의 모호하거나 복잡한 자연어 명령(예: "식탁 위에 있는 물건 중 아이가 만지면 위험한 것을 찾아줘")을 해석하여 SAM 3가 이해할 수 있는 구체적인 명사구 프롬프트(예: "칼", "뜨거운 냄비")로 변환하고, SAM 3가 반환한 마스크 정보를 다시 논리적으로 분석하여 최종 답변을 도출합니다. 따라서 LangChain이나 LlamaIndex와 같은 프레임워크를 사용하여 SAM 3를 하나의 '도구(Tool)'로 MLLM에 연동함으로써 고도화된 시각적 추론 시스템을 구축할 수 있습니다.

향후 전망
Meta의 SAM 3는 컴퓨터 비전 분야에서 오랫동안 난제로 여겨졌던 '개방형 개념 분할'을 실현함으로써 기술적 도약을 이루어냈습니다. 인식과 위치 추정의 분리, Perception Encoder의 도입, 그리고 혁신적인 데이터 엔진을 통해 달성한 성능은 학술적인 가치를 넘어 산업 현장에서의 즉각적인 활용 가능성을 시사합니다.
SAM 3는 강력한 도구이자 기회입니다. 복잡한 데이터 라벨링과 모델 학습 과정 없이도, 텍스트 프롬프트 하나만으로 최고 수준의 시각 인식 기능을 애플리케이션에 통합할 수 있게 되었습니다. 이는 미디어 편집, 보안 관제, 로보틱스, 데이터 분석 등 다양한 도메인에서 새로운 서비스와 기능을 창출하는 촉매제가 될 것입니다. 물론 높은 하드웨어 요구사항과 최적화 이슈는 여전히 존재하지만, 하드웨어의 발전과 경량화 기술의 연구가 병행됨에 따라 이러한 진입 장벽은 점차 낮아질 것입니다.
향후 SAM 3는 단순한 인식 도구를 넘어, 물리적 세계를 이해하고 상호작용하는 AI 에이전트의 핵심 '눈'으로 자리 잡을 것으로 기대합니다.
 Meta Segment Anything Model 3 (SAM 3) 홈페이지
Meta Segment Anything Model 3 (SAM 3) 홈페이지
 Meta Segment Anything Model 3 (SAM 3) 소개 블로그
Meta Segment Anything Model 3 (SAM 3) 소개 블로그
 Segment Anything Model 3) 사용해보기 (Playgroumd)
Segment Anything Model 3) 사용해보기 (Playgroumd)
 Meta Segment Anything Model 3 GitHub 저장소
Meta Segment Anything Model 3 GitHub 저장소
https://github.com/facebookresearch/sam3
 Meta Segment Anything Model 3 다운로드
Meta Segment Anything Model 3 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()