Mini-SGLang 소개
Mini-SGLang은 최신 대규모 언어 모델(LLM) 서빙 시스템의 복잡성을 해소하고 그 원리를 명확히 보여주기 위해 설계된 SGLang의 경량화 버전입니다. 약 5,000줄의 간결한 Python 코드베이스로 구성되어 있어 연구자와 개발자가 LLM 추론 엔진의 내부 동작을 쉽게 이해하고 수정할 수 있는 투명한 레퍼런스를 제공합니다.
LLM 서빙 기술은 KV 캐시 관리, 스케줄링, 병렬 처리 등 복잡한 엔지니어링의 집약체입니다. Mini-SGLang은 이러한 복잡함을 걷어내면서도 SGLang이 자랑하는 고성능 추론 능력의 핵심을 유지합니다. 단순히 교육용에 그치지 않고, 최신 최적화 기술들이 적용된 실제로 작동하는 고성능 추론 엔진으로서의 역할도 충분히 수행합니다.
이 프로젝트는 고성능 추론 프레임워크인 SGLang의 "핵심 기술"을 누구나 쉽게 접근하고 분석할 수 있도록 하는 데 목적이 있습니다. 복잡한 프로덕션 레벨의 코드를 파헤치지 않고도, Radix Attention이나 Chunked Prefill과 같은 고급 서빙 기술이 실제로 어떻게 구현되는지 학습할 수 있는 최적의 도구입니다.
SGLang과의 비교
SGLang과 Mini-SGLang은 동일한 핵심 철학을 공유하지만, 그 지향점에서 차이가 있습니다. 먼저 SGLang은 대규모 프로덕션 환경을 위해 설계되었습니다. 수백 개의 GPU를 아우르는 분산 처리, 다양한 모델 아키텍처 지원, 복잡한 기능(비전 모델 등)을 모두 포함하며, 전 세계적으로 400,000개 이상의 GPU에서 사용되는 업계 표준급 엔진입니다.
이에 비해 Mini-SGLang은 코드의 가독성과 교육적 가치에 중점을 둡니다. 복잡한 의존성을 제거하고 핵심 로직(약 5,000라인)에 집중하여, 개발자가 하루 만에 전체 구조를 파악할 수 있도록 설계되었습니다. 하지만 성능을 희생하지 않았으며, 단일 노드나 소규모 클러스터 환경에서는 SGLang에 버금가는 처리량을 제공합니다.
Mini-SGLang의 주요 특징
Mini-SGLang은 코드 라인 수는 적지만, SGLang의 고성능을 뒷받침하는 핵심 기술들을 모두 구현하고 있습니다.
자동 접두사(Prefix) 캐싱을 위한 Radix Cache
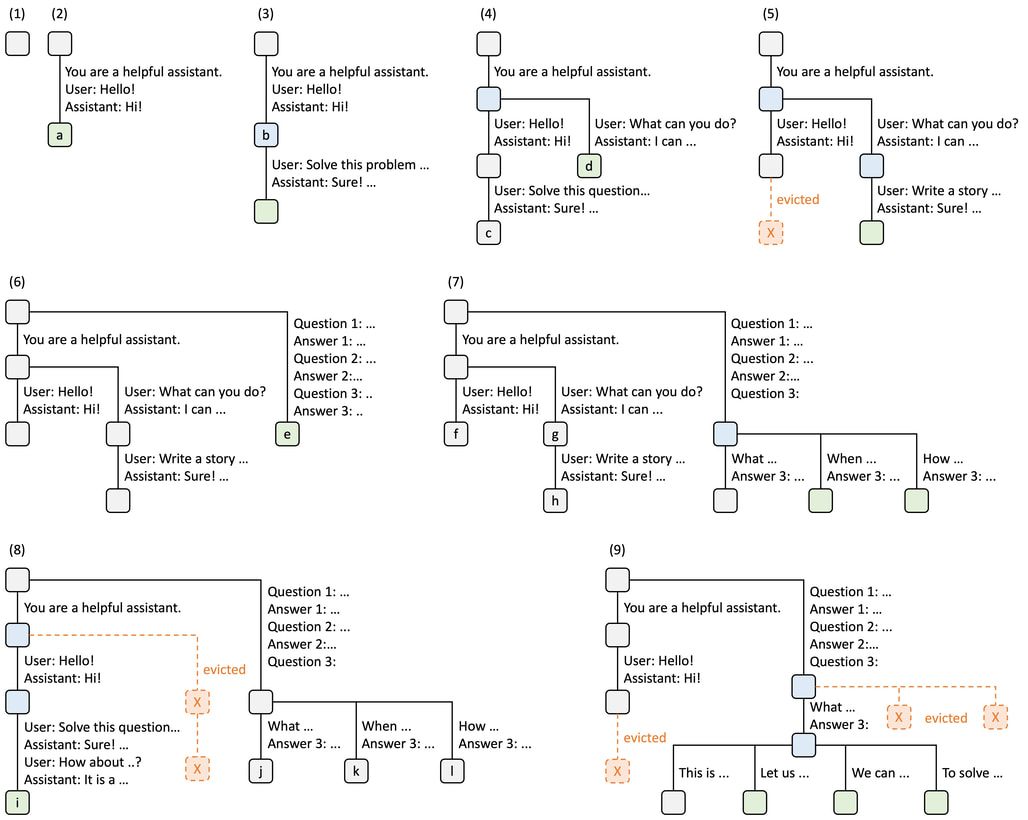
LMSYS 블로그에 소개된 Radix Attention 소개
대부분의 LLM 추론 엔진은 요청이 끝나면 KV 캐시(Key-Value Cache)를 버리지만, Mini-SGLang은 SGLang과 같이 이를 Radix Tree(Trie) 구조로 관리하여 유지합니다. 즉, Mini-SGLang은 프롬프트의 토큰들을 트리 노드에 매핑하여 저장합니다. 새로운 요청이 들어오면 트리를 검색하여 일치하는 접두사(Prefix)가 있는지 확인하고, 존재한다면 해당 부분의 KV 캐시를 재사용합니다.
이렇게 Radix Cache를 사용하면 다중 턴 대화(Multi-turn chat)나 시스템 프롬프트를 공유하는 여러 요청을 처리할 때 연산량을 획기적으로 줄여줍니다. 또한, LRU(Least Recently Used) 알고리즘을 사용하여 GPU 메모리가 부족할 때 가장 오래된 캐시부터 자동으로 정리합니다.
기본적으로는 Radix Cache를 사용하는 --cache radix 옵션이 켜져있으며, 사용하지 않으려면 --cache naive를 추가하여 실행합니다.
청크 단위로 쪼개어 프리필 (Chunked Prefill)
Mini-SGLang은 Sarathi-Serve에서 도입한 청크 단위의 프리필(Chunked Prefill) 기능을 기본적으로 활성화하여 사용합니다. 이 기능은 긴 문맥(Context)을 처리할 때 발생할 수 있는 메모리 부족(OOM, Out-of-Memory) 문제와 성능 저하를 방지하기 위해, 청크 단위의 프리필(Prefill)을 수행하는 것입니다. 이 기능은 특히 입력 프롬프트가 매우 길 경우, 이를 한 번에 처리하지 않고 작은 청크(Chunk) 단위로 나누어 처리하면서 성능을 높입니다.
청크 단위의 프리필을 사용하면 Mini-SGLang은 긴 입력을 처리하는 동안에도 짧은 디코딩(Decode) 요청을 사이사이에 끼워 넣을 수 있어(Interleaving), 전체적인 시스템의 응답성(Latency)을 유지할 수 있습니다. 또한, 피크 메모리 사용량을 줄여 더 큰 배치 크기를 허용합니다.
청크의 크기는 Mini-SGLang 실행 시 --max-prefill-length n 옵션으로 설정할 수 있습니다. 단, n을 매우 작은 값(예: 128)으로 설정하는 것은 성능 저하를 초래할 수 있으므로 권장하지 않습니다.
CPU/GPU를 최대한 사용하기 위한 연산-스케줄링 중첩 (Overlap Scheduling)

LMSYS 블로그에 소개된 Overlap Scheduling
CPU 오버헤드를 더욱 줄이기 위해 Mini-SGLang은 NanoFlow에서 제안된 오버랩 스케줄링(Overlap Scheduling) 기법을 채택합니다. 이 접근법은 CPU 스케줄링 오버헤드를 GPU 연산과 중첩시켜 전체 시스템 처리량을 향상시킵니다.
좀 더 상세하게는 CPU와 GPU가 쉴 새 없이 일하도록 병렬화하기 위해, GPU가 현재 배치(Batch N)를 연산하는 동안, CPU는 놀지 않고 다음 배치(Batch N+1)를 위한 데이터를 준비하고 스케줄링합니다. 이러한 방식으로 스케줄링에 소요되는 CPU 오버헤드를 GPU 연산 시간 뒤로 숨겨(Hide), 전체적인 처리량(Throughput)을 극대화합니다.
필요하다면 개발자는 환경 변수 MINISGL_DISABLE_OVERLAP_SCHEDULING=1로 이 기능을 비활성화하여 효과를 비교할 수 있습니다.
여러 GPU에 나누어 처리하는 텐서 병렬화 (Tensor Parallelism)
하나의 GPU 메모리에 담기지 않는 거대 모델을 여러 GPU에 나누어 싣고 동시에 연산합니다. 이는 행렬 곱셈(Matrix Multiplication)과 같은 연산을 여러 GPU로 분할(Row/Column Parallel)하여 수행하고, 결과를 NCCL을 통해 빠르게 합칩니다. 개발자는 Mini-SGLang 실행 시 --tp <GPU 개수> 옵션으로 간단하게 활성화할 수 있습니다.
GPU 성능 향상을 위한 최적화된 커널 (Optimized Kernels)
Mini-SGLang은 Python 코드의 오버헤드를 줄이고 GPU 성능을 극한으로 끌어올리기 위해 최적화된 CUDA 커널을 사용합니다. 이를 위해 FlashAttention 및 FlashInfer를 포함한 고성능 어텐션 커널을 통합합니다. 또한, 효율성을 극대화하기 위해 Mini-SGLang은 프리필(Prefill) 및 디코딩(Decoding) 단계에 서로 다른 백엔드를 사용할 수 있도록 지원합니다. 예를 들어 NVIDIA Hopper GPU에서는 기본적으로 프리필에 FlashAttention3, 디코딩에 FlashInfer가 사용됩니다.
Mini-SGLang 실행 시 --attn 옵션을 사용하여 백엔드를 지정할 수 있습니다. 두 값이 제공된 경우(예: --attn fa3,fi), 첫 번째 값은 프리필 백엔드를, 두 번째 값은 디코딩 백엔드를 지정합니다.
Mini-SGLang의 성능 벤치마크
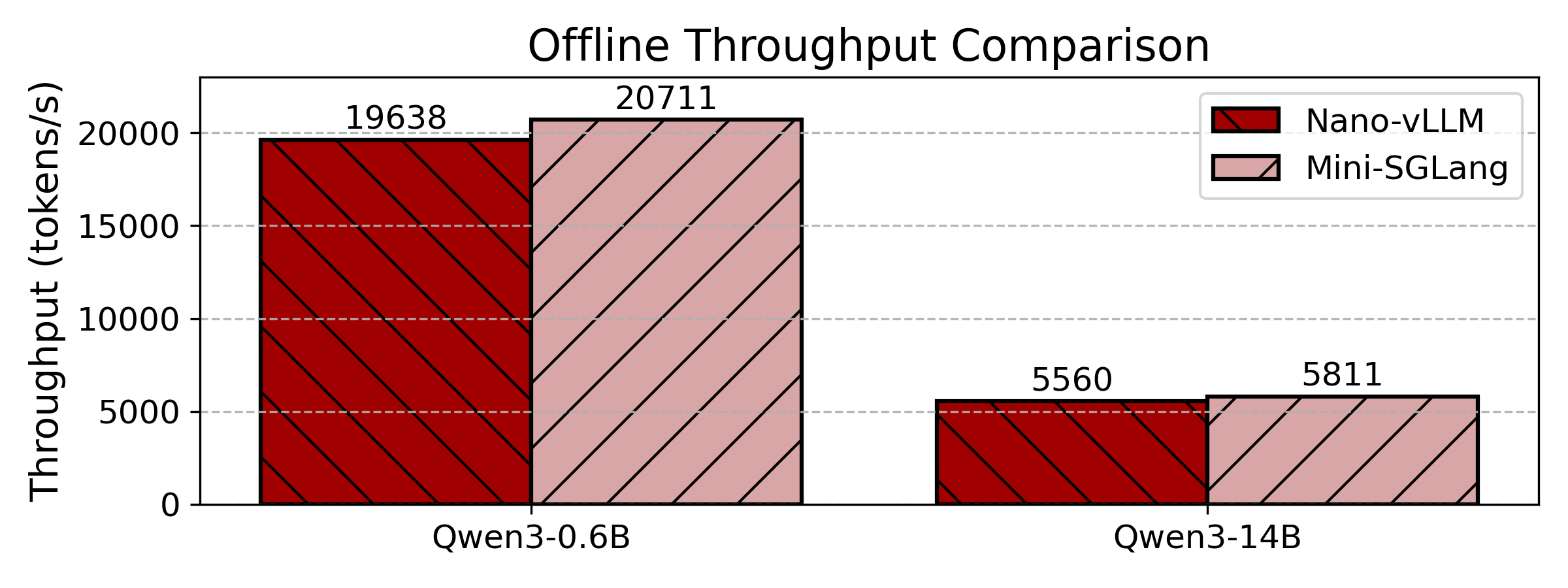
Mini-SGLang은 경량화 버전임에도 불구하고 강력한 성능을 보여줍니다. 다음은 오프라인 및 온라인 추론 환경에서의 벤치마크 결과입니다.
오프라인 추론 (Offline Inference)
오프라인 환경에서의 처리량 테스트 결과입니다. MINISGL_DISABLE_OVERLAP_SCHEDULING=1 설정을 통해 Overlap Scheduling의 효과를 검증하는 ablation study도 수행할 수 있습니다.
- 하드웨어: 1x NVIDIA H200 GPU
- 모델: Qwen3-0.6B, Qwen3-14B
- 테스트 요청: 256개 시퀀스 (입력/출력 길이 각각 100~1024 토큰 무작위 샘플링)
- 상세 스크립트:
bench_nanovllm.py
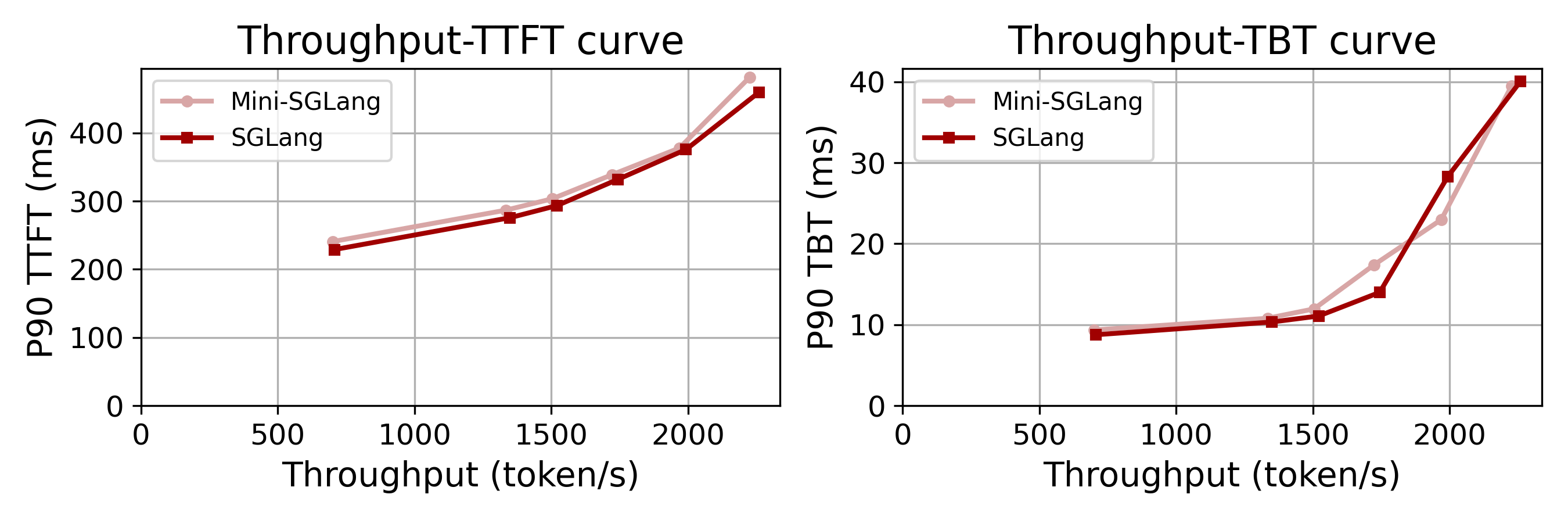
온라인 추론 (Online Inference)
실제 서비스 환경과 유사한 온라인 추론 성능 테스트입니다. Mini-SGLang은 SGLang과 비교했을 때 대등한 수준의 성능을 보여줍니다:
- 하드웨어: 4x NVIDIA H200 GPU (NVLink 연결)
- 모델: Qwen3-32B
- 데이터셋: Qwen trace (실제 트래픽 데이터, 처음 1000개 요청 재생)
- 상세 스크립트:
benchmark_qwen.py
실행 명령어 비교:
# Mini-SGLang 실행
python -m minisgl --model "Qwen/Qwen3-32B" --tp 4 --cache naive
# SGLang 실행 (비교군)
python3 -m sglang.launch_server --model "Qwen/Qwen3-32B" --tp 4 \
--disable-radix --port 1919 --decode-attention flashinfer
Mini-SGLang 설치 및 사용
Mini-SGLang은 Python 패키지 관리자인 uv를 사용하여 설치하는 것을 권장합니다:
# 가상 환경 생성 및 활성화
uv venv --python=3.12
source .venv/bin/activate
# 소스 코드 클론 및 설치
git clone https://github.com/sgl-project/mini-sglang.git
cd mini-sglang
uv pip install -e .
![]() 주의
주의![]() : NVIDIA CUDA Toolkit이 설치되어 있어야 하며, 드라이버 버전과 일치해야 합니다.
: NVIDIA CUDA Toolkit이 설치되어 있어야 하며, 드라이버 버전과 일치해야 합니다.
설치 후에는 OpenAI 호환(OpenAI Compatiable) API 서버를 명령어 한 줄로 실행(Online Serving)할 수 있습니다:
# 단일 GPU에 Qwen/Qwen3-0.6B-Instruct 모델 배포
python -m minisgl --model "Qwen/Qwen3-0.6B-Instruct"
# 4개의 GPU에 Llama-3.1-70B 모델 배포 (Tensor Parallelism 적용)
python -m minisgl --model "meta-llama/Llama-3.1-70B-Instruct" --tp 4 --port 30000
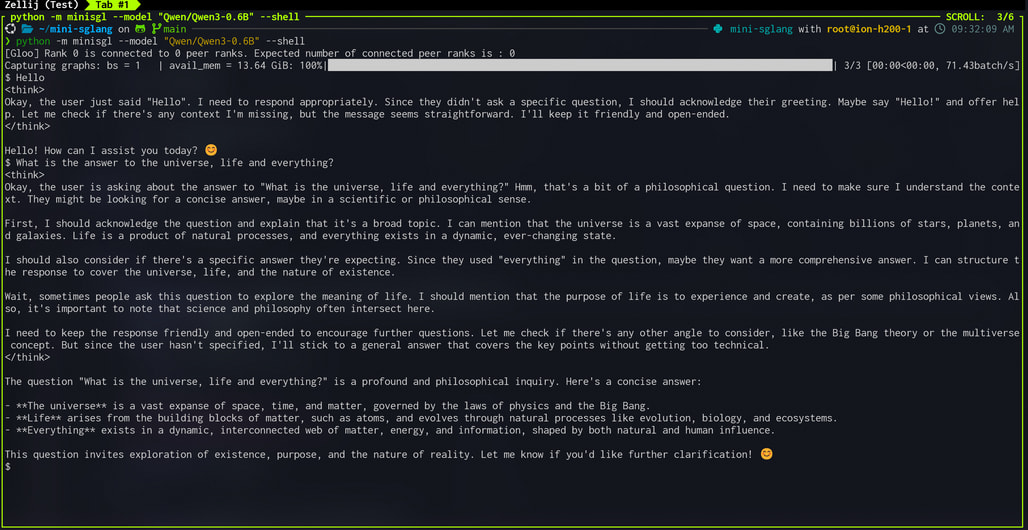
또는, 필요하다면 --shell 옵션을 추가하여 OpenAI 호환 서버를 띄우지 않고 터미널에서 바로 모델에 질의하는 대화형 셸(Interactive Shell) 로도 실행할 수 있습니다:
python -m minisgl --model "Qwen/Qwen3-0.6B" --shell
실행 후에는 다음과 같이 터미널에서 바로 모델에 질의할 수 있습니다. 사용 중 /reset 명령을 통해 세션을 초기화할 수 있습니다.
Mini-SGLang의 아키텍처 및 코드 구조
Mini-SGLang은 LLM 추론을 효율적으로 처리하기 위해 분산 시스템으로 설계되었으며, 독립적으로 실행되는 여러 프로세스로 구성됩니다.
시스템 컴포넌트 (System Components)
- API Server: 사용자의 요청을 받는 진입점(Entrypoint)입니다. OpenAI 호환 API(예:
/v1/chat/completions)를 제공하여 프롬프트를 수신하고 생성된 텍스트를 반환합니다. - Tokenizer Worker: 입력 텍스트를 모델이 이해할 수 있는 숫자(토큰)로 변환합니다.
- Detokenizer Worker: 모델이 생성한 숫자(토큰)를 다시 사람이 읽을 수 있는 텍스트로 변환합니다.
- Scheduler Worker: 추론의 핵심을 담당합니다. 멀티 GPU 환경에서는 각 GPU마다 하나의 Scheduler Worker가 할당되어(TP Rank), 해당 GPU의 연산과 자원을 관리합니다.
데이터 흐름 (Data Flow)
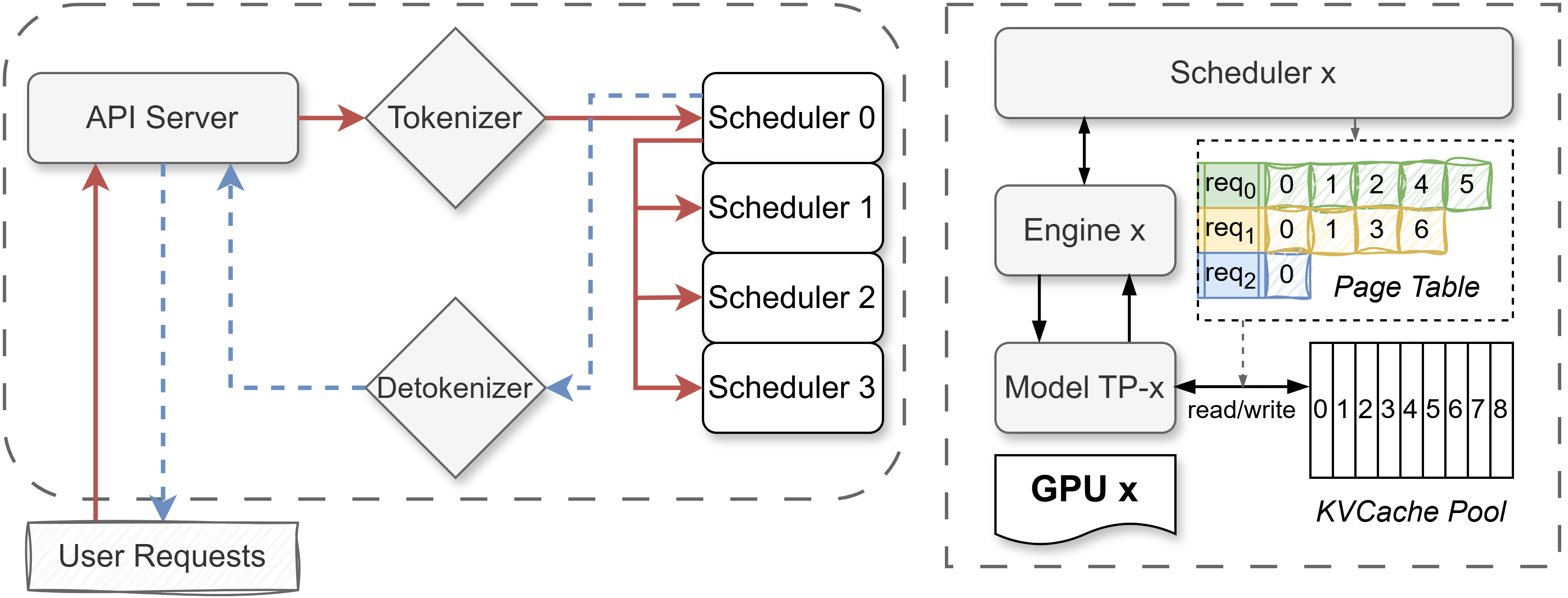
각 컴포넌트는 ZeroMQ (ZMQ) 를 통해 제어 메시지를 주고받으며, GPU 간의 대용량 텐서 데이터 교환은 NCCL (via torch.distributed)을 사용합니다. 요청의 처리 과정은 다음과 같습니다:
- User -> API Server: 사용자가 요청을 보냅니다.
- API Server -> Tokenizer: 텍스트를 토큰으로 변환 요청합니다.
- Tokenizer -> Scheduler (Rank 0): 변환된 토큰을 메인 스케줄러에게 전달합니다.
- Broadcast: Scheduler (Rank 0)는 요청을 다른 모든 Scheduler(다른 GPU)에게 전파합니다.
- Execution: 모든 Scheduler가 요청을 스케줄링하고, 로컬 Engine을 트리거하여 다음 토큰을 계산합니다.
- Scheduler (Rank 0) -> Detokenizer: 생성된 출력 토큰을 수집하여 Detokenizer에게 보냅니다.
- Detokenizer -> API Server: 토큰을 텍스트로 변환하여 API 서버로 전달합니다.
- API Server -> User: 결과를 사용자에게 스트리밍합니다.
코드 구성 (Code Organization)
소스 코드는 python/minisgl 패키지 내에 모듈별로 깔끔하게 정리되어 있습니다.
| 모듈 (Module) | 설명 (Description) |
|---|---|
minisgl.core |
요청(Req) 및 배치(Batch) 상태 관리, 전역 컨텍스트(Context), 샘플링 파라미터 정의 |
minisgl.distributed |
텐서 병렬 처리를 위한 All-Reduce, All-Gather 인터페이스 및 TP 정보 관리 |
minisgl.layers |
LLM 구성을 위한 기본 레이어(Linear, LayerNorm, Embedding, RoPE 등) 구현 |
minisgl.models |
Llama, Qwen3 등 실제 LLM 모델 구현 및 가중치 로딩 유틸리티 |
minisgl.attention |
FlashAttention, FlashInfer 등 어텐션 백엔드 인터페이스 및 구현 |
minisgl.kvcache |
KV 캐시 풀 및 매니저 (RadixCacheManager, NaiveCacheManager 등) 구현 |
minisgl.engine |
단일 프로세스 내의 TP 워커로, 모델/컨텍스트/KV 캐시/CUDA 그래프를 관리하는 Engine 클래스 구현 |
minisgl.scheduler |
각 TP 워커 프로세스에서 실행되며 해당 Engine을 관리하는 Scheduler 클래스 구현 |
minisgl.server |
시스템의 모든 서브프로세스를 시작하는 launch_server 및 FastAPI 기반 프론트엔드 구현 |
 SGLang 공식 홈페이지
SGLang 공식 홈페이지
 Mini-SGLang 프로젝트 GitHub 저장소
Mini-SGLang 프로젝트 GitHub 저장소
https://github.com/sgl-project/mini-sglang
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()