
MiniMind 소개
대규모 언어 모델(LLM)의 작동 원리를 진정으로 이해하려면 단순히 API를 호출하거나 미리 학습된 모델을 파인튜닝하는 것만으로는 부족합니다. 토크나이저를 구성하고, 사전 학습(pretraining)부터 지도 파인튜닝(SFT), 강화학습(RLHF)까지 전 과정을 직접 구현해보는 경험이 모델의 내부 메커니즘을 진정으로 이해하는 가장 확실한 방법입니다. MiniMind는 바로 이러한 목적으로 설계된 오픈소스 초경량 언어 모델 프로젝트입니다. GPT-3의 약 1/2700 크기인 64M 파라미터 모델을 단일 NVIDIA 3090 GPU로 약 2시간, 비용으로는 약 3달러 안에 처음부터 학습시킬 수 있습니다.
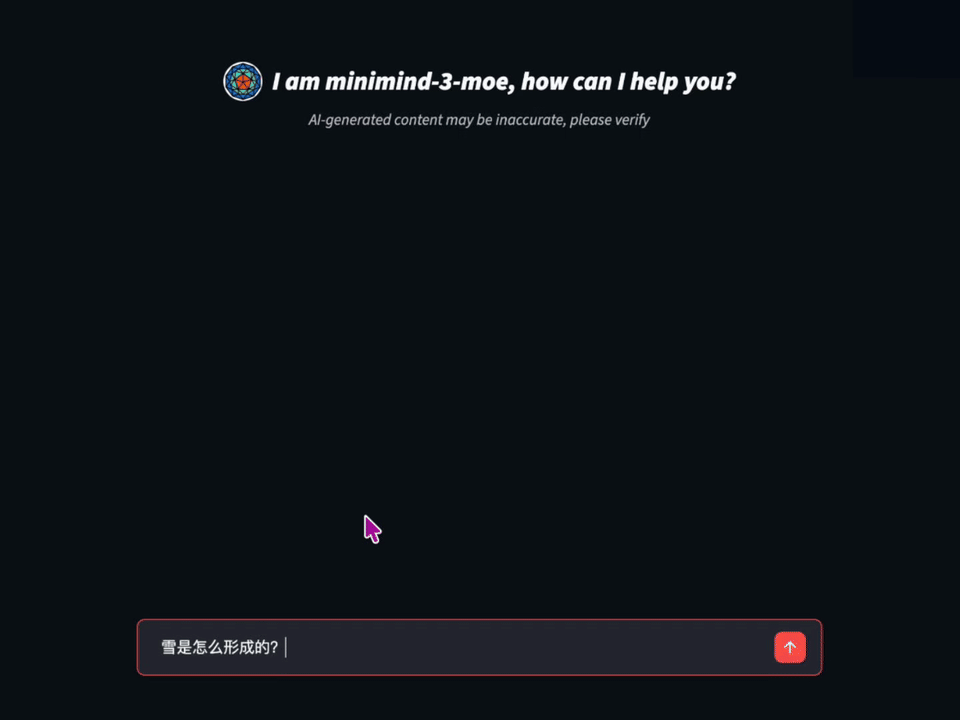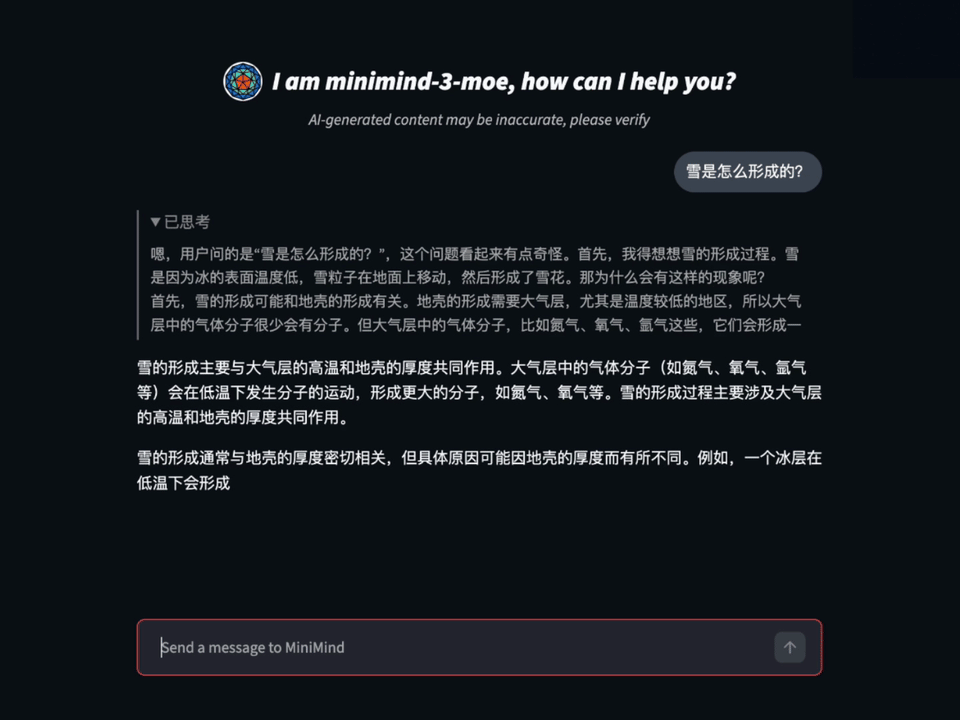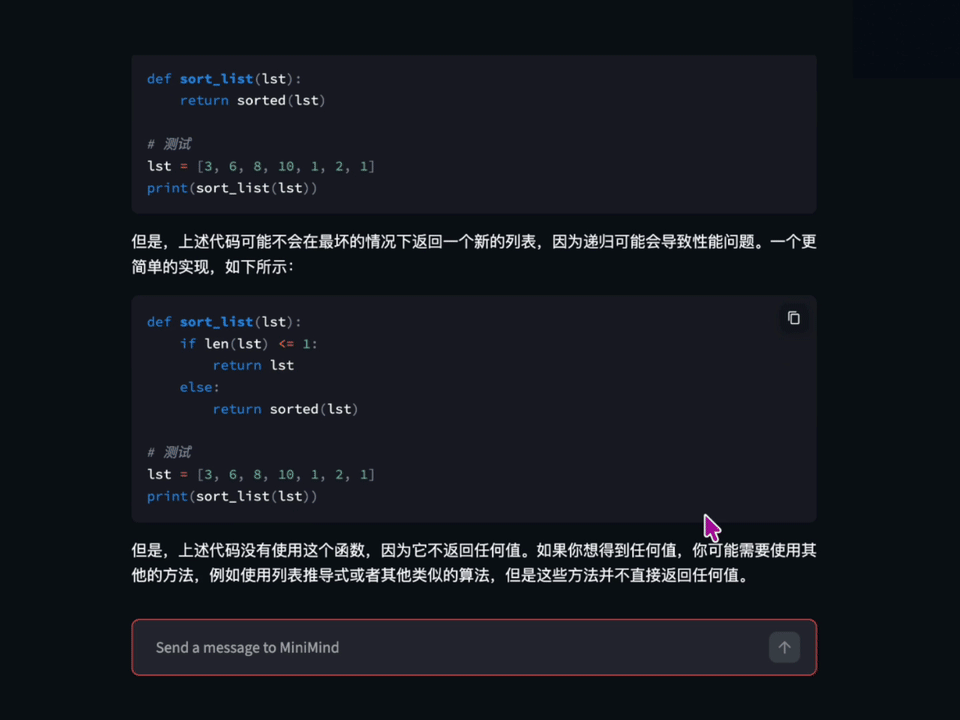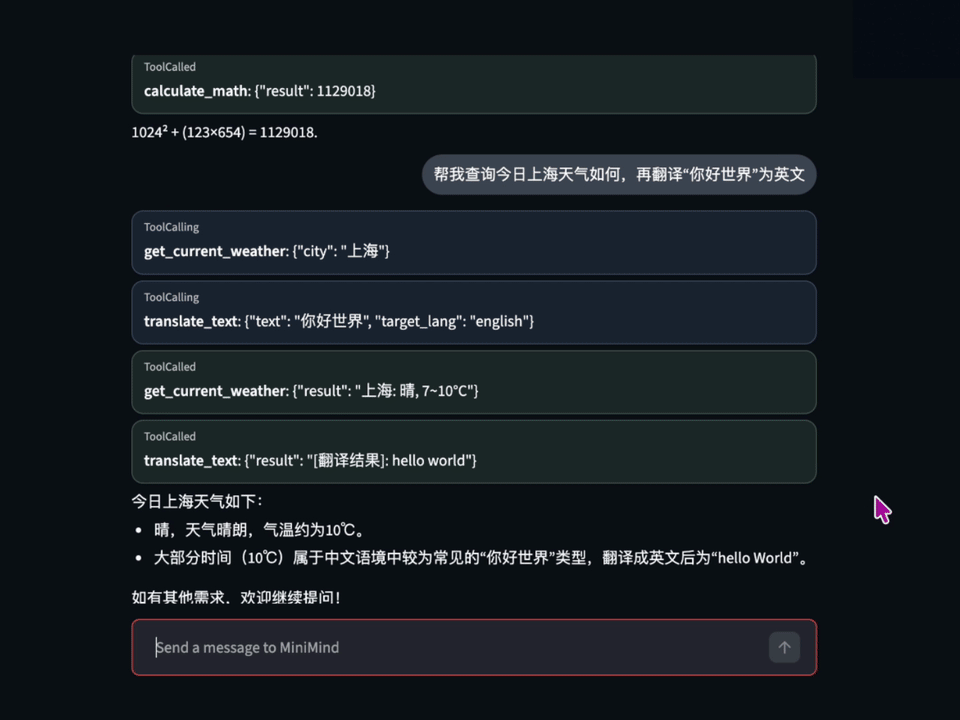
GitHub에서 44,500개 이상의 스타를 받은 이 프로젝트는 LLM을 처음 공부하는 학생부터 연구자까지 폭넓게 활용되고 있습니다. 2026년 4월에는 새로운 버전인 minimind-3(64M)와 minimind-3-moe(198M/A64M)가 출시될 예정으로, 지속적으로 발전하고 있습니다. 프로젝트 개발자는 "처음부터 작은 언어 모델을 구축하는 것이 단순히 추론만 하는 것보다 훨씬 더 많은 것을 배울 수 있다"는 철학을 강조합니다.
MiniMind의 학습 파이프라인 및 구조
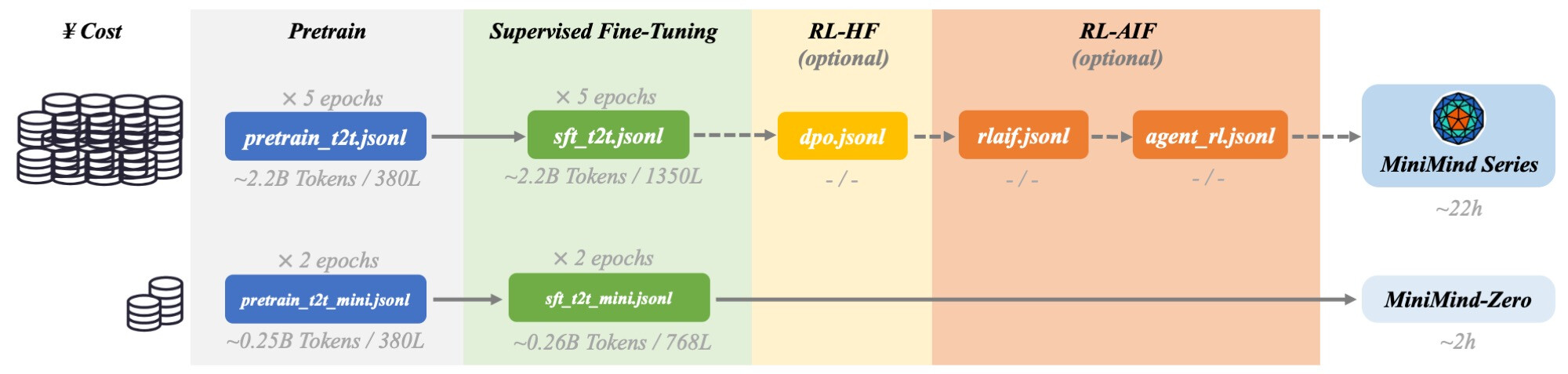
MiniMind는 실제 LLM 학습의 전체 파이프라인을 구현하고 있어, 각 단계가 어떻게 작동하는지 직접 실험하고 확인할 수 있습니다. 파이프라인은 사전 학습(Pretrain)에서 시작하여 지도 파인튜닝(SFT), LoRA 파인튜닝, 선호도 학습(DPO), 그리고 AI 피드백 강화학습(RLAIF)까지 이어집니다. RLAIF 단계에서는 PPO, GRPO, CISPO 등 다양한 강화학습 알고리즘을 실험할 수 있습니다.
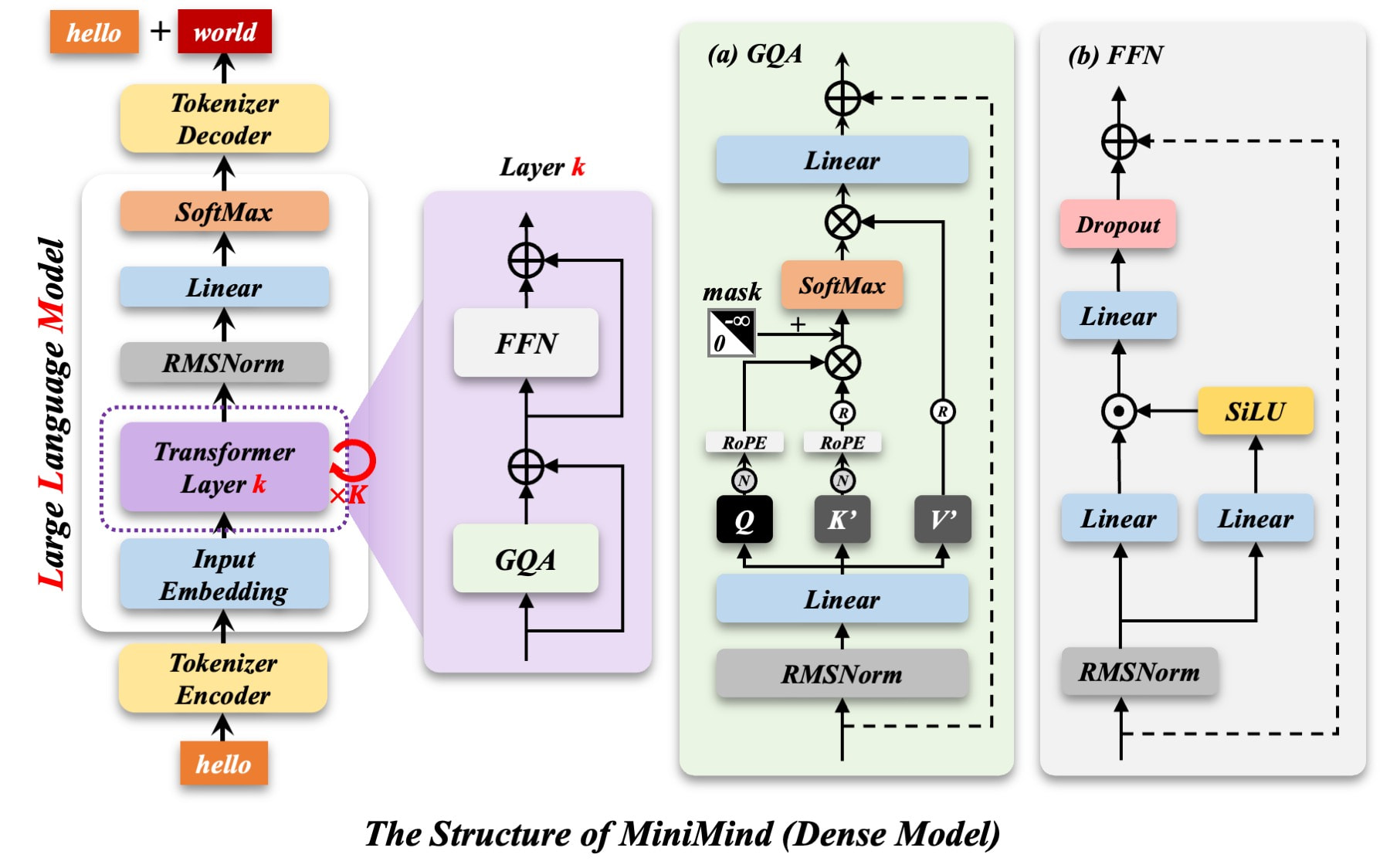
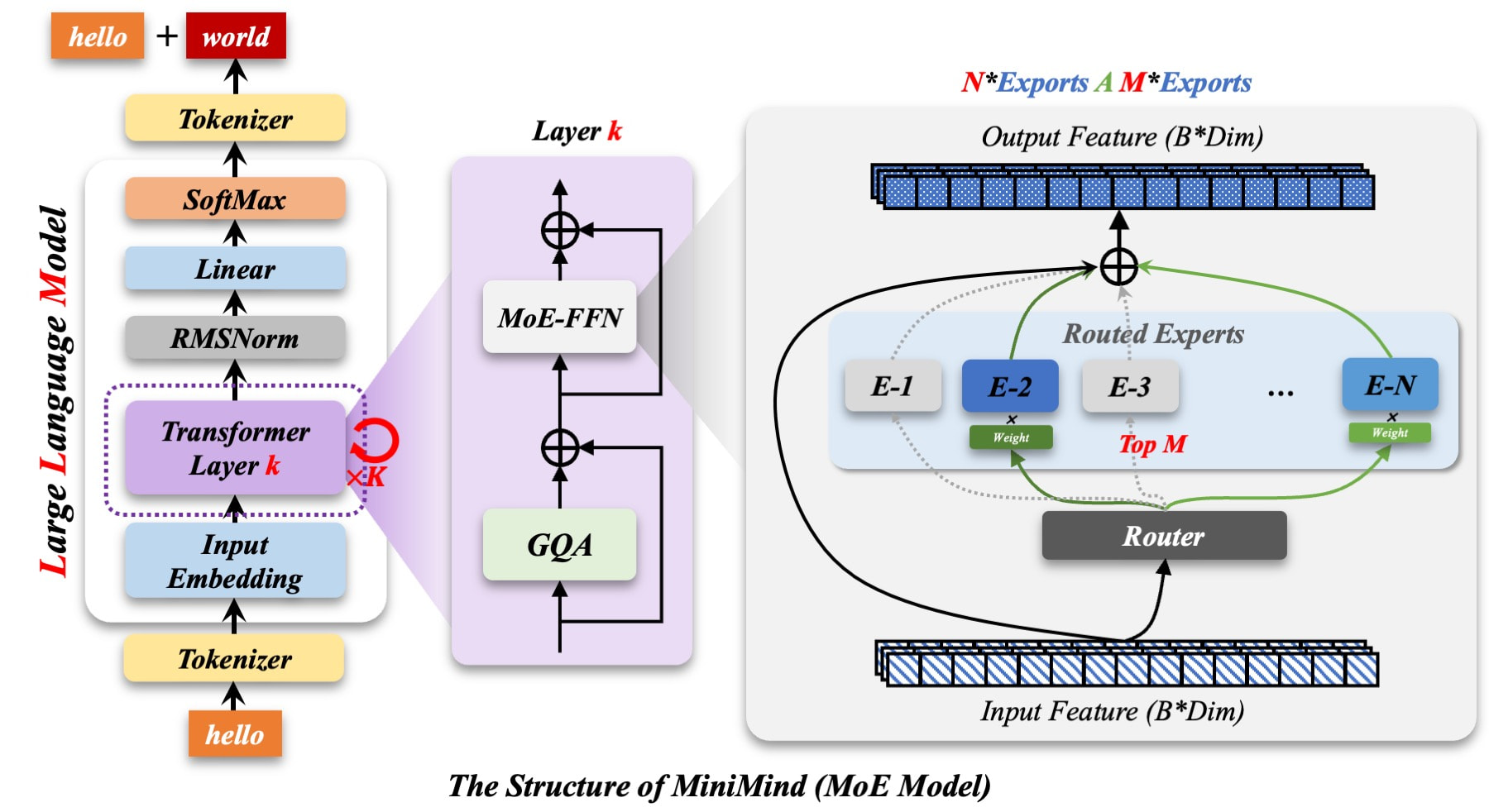
모델 아키텍처는 트랜스포머(Transformer) 기반의 Dense 모델과 전문가 혼합(Mixture-of-Experts, MoE) 변형을 모두 지원합니다. 또한 적응형 사고(Adaptive Thinking) 메커니즘과 모델 증류(Model Distillation), YaRN 기반의 RoPE 길이 외삽(length extrapolation)을 구현하고 있습니다. 커스텀 토크나이저는 도구 호출(tool-calling)과 추론 태그를 지원하도록 설계되었습니다.
현재까지 공개한 MiniMind 모델의 주요 파라매터들은 다음과 같습니다:
| Model Name | params | len_vocab | max_pos | rope_theta | n_layers | d_model | kv_heads | q_heads | note |
|---|---|---|---|---|---|---|---|---|---|
| minimind-3 | 64M | 6400 | 32768 | 1e6 | 8 | 768 | 4 | 8 | Dense |
| minimind-3-moe | 198M / A64M | 6400 | 32768 | 1e6 | 8 | 768 | 4 | 8 | 4 experts / top-1 |
| minimind2-small | 26M | 6400 | 32768 | 1e6 | 8 | 512 | 2 | 8 | Historical version |
| minimind2-moe | 145M | 6400 | 32768 | 1e6 | 8 | 640 | 2 | 8 | Historical version |
| minimind2 | 104M | 6400 | 32768 | 1e6 | 16 | 768 | 2 | 8 | Historical version |
MiniMind 설치 및 사용법
MiniMind 프로젝트는 PyTorch 네이티브 구현을 기반으로 하며, 제3자 프레임워크에 대한 의존을 최소화하여 코드를 직접 읽고 이해하기 쉽게 설계되었습니다.
git clone --depth 1 https://github.com/jingyaogong/minimind
cd minimind
pip install -r requirements.txt
사전 학습된 모델로 추론을 실행하는 방법입니다.
python eval_llm.py --load_from ./minimind-3
웹 인터페이스로 대화형 테스트도 가능합니다.
cd scripts && streamlit run web_demo.py
학습을 처음부터 시작하려면 먼저 데이터셋을 다운로드(HuggingFace 또는 ModelScope에서 제공)한 뒤 순서대로 실행합니다.
cd trainer
python train_pretrain.py # 1단계: 사전 학습
python train_full_sft.py # 2단계: 지도 파인튜닝
멀티 GPU 학습은 torchrun으로 지원합니다.
torchrun --nproc_per_node N trainer/train_pretrain.py
PyTorchKR
 커뮤니티에서 활용하기
커뮤니티에서 활용하기
MiniMind는 transformers, trl, peft 등 널리 사용되는 라이브러리와 호환되며, llama.cpp, vllm, ollama 등 다양한 추론 엔진에서도 실행할 수 있습니다. OpenAI API 호환 서버도 내장되어 있어 기존 프로젝트에 쉽게 통합할 수 있습니다.
특히 PyTorch를 공부하는 입장에서 MiniMind의 가장 큰 가치는 추상화 레이어 없이 트랜스포머 아키텍처, 어텐션 메커니즘, 위치 인코딩, KV 캐시, 그리고 각종 학습 알고리즘이 실제로 어떻게 구현되는지를 직접 볼 수 있다는 점입니다. LLM의 전체 학습 사이클을 처음부터 끝까지 경험하고 싶은 분들에게 가장 접근하기 쉬운 출발점 중 하나입니다.
라이선스
MiniMind 프로젝트는 Apache 2.0 라이선스로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용, 수정, 배포할 수 있습니다.
 MiniMind 프로젝트 GitHub 저장소
MiniMind 프로젝트 GitHub 저장소
 MiniMind 모델 컬렉션
MiniMind 모델 컬렉션
더 읽어보기
-
The Little Book of llm.c: Andrej Karphathy의 llm.c를 해설한 GPT-2 학습 도서 [영문/PDF&EPUB/255p]
-
MoD(Mixture-of-Depths): Transformer 기반 언어 모델 연산 최적화를 위한 접근법, 그리고 MoDE(MoD+MoE)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()