MINT-1T 데이터셋 소개
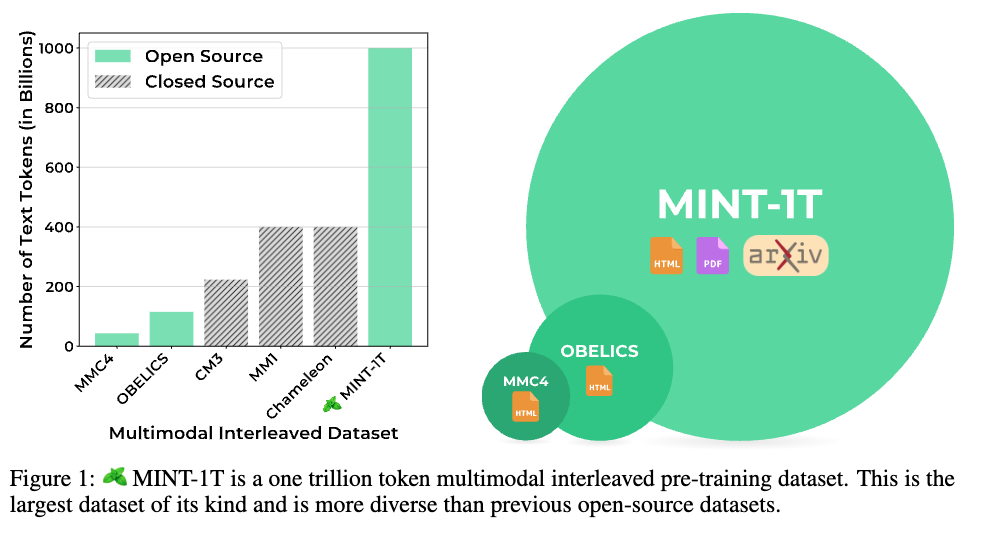
MINT-1T는 Multimodal INTerleaved 데이터셋으로, 1조(Trillion)개의 텍스트 토큰과 34억 개의 이미지를 포함하는 오픈소스 멀티모달 데이터셋입니다. 이는 기존 오픈소스 데이터셋 규모의 약 10배에 해당하며, PDF와 ArXiv 논문과 같은 이전에는 활용되지 않았던 소스도 포함하고 있습니다.
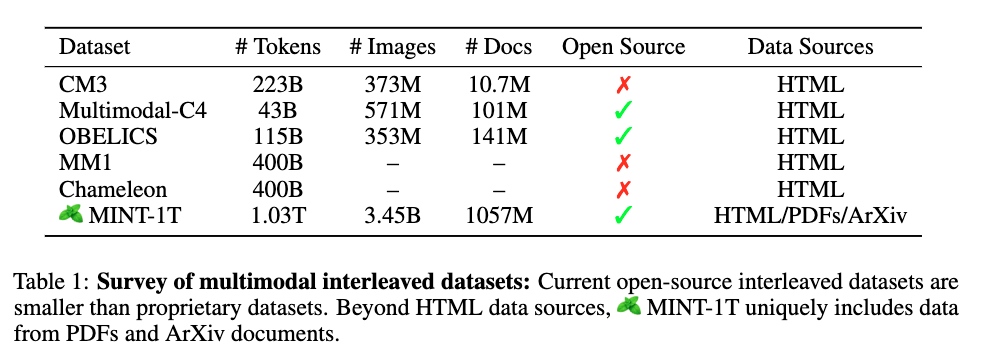
기존의 멀티모달 데이터셋과 비교했을 때, MINT-1T는 그 규모와 다양성에서 큰 차이를 보입니다. 예를 들어, CommonCrawl 데이터셋은 주로 웹 페이지에서 수집된 데이터를 포함하고 있지만, MINT-1T는 PDF와 ArXiv 논문 등 다양한 형식의 데이터를 포함하고 있습니다. 이는 더 다양한 연구와 실험에 활용될 수 있는 가능성을 열어줍니다.
MINT-1T 데이터셋의 주요 특징
-
대규모 데이터셋: 1조 개의 텍스트 토큰과 34억 개의 이미지
-
다양한 데이터 소스: HTML, PDF, ArXiv 데이터 포함
-
CommonCrawl PDF 샤드 제공: 여러 시점에서 수집된 PDF 데이터 제공
-
오픈소스: 누구나 접근 가능하고 활용할 수 있는 오픈소스 데이터셋
데이터셋 링크

HTML 데이터
PDF 데이터
- CommonCrawl 2024-18: 링크
- CommonCrawl 2024-10: 링크
- CommonCrawl 2023-50: 링크
- CommonCrawl 2023-40: 링크
- CommonCrawl 2023-23: 링크
- CommonCrawl 2023-14: 링크
- CommonCrawl 2023-06: 링크
arXiv 데이터
 MINT-1T 기술 문서
MINT-1T 기술 문서
 MINT-1T 데이터셋
MINT-1T 데이터셋
 MINT-1T 블로그 글
MINT-1T 블로그 글
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()