MMLU-Pro, LLM 성능 평가를 위한 벤치마크인 MMLU의 개선된 버전
소개
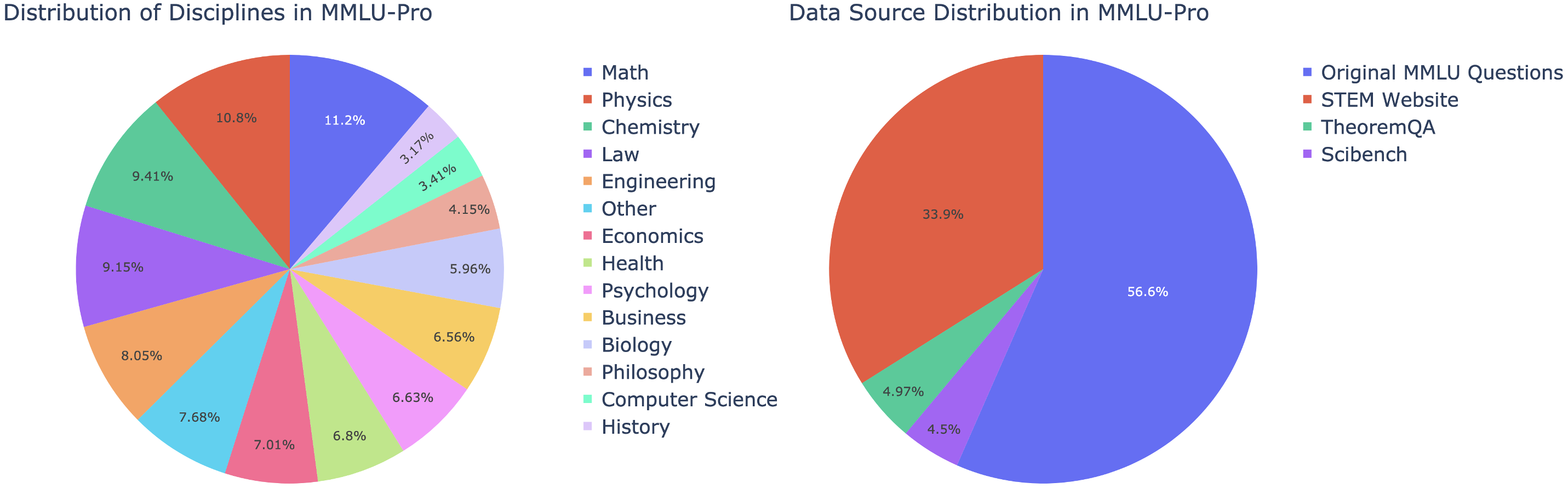
MMLU-Pro 데이터셋은 기존의 MMLU 데이터셋을 개선한 버전으로, 총 12,000개의 복잡한 질문들로 구성되어 있습니다. 이 데이터셋은 대형 언어 모델의 성능을 더욱 엄격하게 평가하기 위해 설계되었습니다. 기존 MMLU 데이터셋이 주로 지식 기반의 질문들로 구성되어 있었던 반면, MMLU-Pro는 문제 난이도를 높이고 추론 중심의 질문들을 추가하여 모델이 더 깊은 이해와 분석을 필요로 하게 합니다. 또한, 질문의 선택지도 4개에서 10개로 늘려 무작위 추측의 가능성을 줄였습니다.
MMLU와 MMLU-Pro 비교
기존 MMLU와 MMLU-Pro의 주요한 차이점은 다음과 같습니다:
- 선택지 증가: MMLU는 4개의 선택지를 제공했지만, MMLU-Pro는 10개의 선택지를 제공합니다. 이는 평가의 현실성을 높이고 난이도를 증가시킵니다.
- 질문 난이도: MMLU는 주로 지식 기반의 질문들로 구성되어 있었으나, MMLU-Pro는 더 많은 추론을 필요로 하는 문제들로 구성되어 있어, 체인 오브 생각(Chain of Thought, CoT) 방식의 결과가 더 높게 나옵니다.
- 성능 안정성: MMLU-Pro는 다양한 프롬프트에서도 성능 변동이 적어 모델의 성능이 더 안정적입니다.
각 분야별 데이터 수의 변화는 다음 표와 같습니다:
| Discipline | Number of Questions | From Original MMLU | Newly Added |
|---|---|---|---|
| Math | 1351 | 846 | 505 |
| Physics | 1299 | 411 | 888 |
| Chemistry | 1132 | 178 | 954 |
| Law | 1101 | 1101 | 0 |
| Engineering | 969 | 67 | 902 |
| Other | 924 | 924 | 0 |
| Economics | 844 | 444 | 400 |
| Health | 818 | 818 | 0 |
| Psychology | 798 | 493 | 305 |
| Business | 789 | 155 | 634 |
| Biology | 717 | 219 | 498 |
| Philosophy | 499 | 499 | 0 |
| Computer Science | 410 | 274 | 136 |
| History | 381 | 381 | 0 |
| Total | 12032 | 6810 | 5222 |
다음은 MMLU와 MMLU-Pro의 벤치마크 점수 차이입니다:
| 모델 | 기존 MMLU 점수 | MMLU Pro 점수 | 감소 |
|---|---|---|---|
| GPT-4 | 0.887 | 0.7255 | 0.1615 |
| Claude-3-Opus | 0.868 | 0.6845 | 0.1835 |
| Claude-3-Sonnet | 0.815 | 0.5511 | 0.2639 |
| Gemini 1.5 Flash | 0.789 | 0.5912 | 0.1978 |
| Llama-3-70B-Instruct | 0.820 | 0.562 | 0.258 |
일부 모델은 GPT-4처럼 16% 감소에 그치지만, Mixtral-8x7B와 같은 모델은 30% 이상 감소하는 것을 보실 수 있습니다.
주요 특징
-
질문과 선택지: 각 질문은 일반적으로 10개의 선택지를 가지고 있으며, 이는 문제의 복잡성과 모델의 분석 능력을 강화합니다.
-
출처: 원본 MMLU 질문 외에도 STEM 웹사이트, TheoremQA, SciBench 등 다양한 출처에서 질문을 선별하여 통합했습니다.
-
학문 분야: 수학, 물리학, 화학, 법학, 공학, 경제학, 심리학, 생물학 등 다양한 학문 분야의 질문들로 구성되어 있습니다.
또한, 기존 MMLU는 PPL 평가를 선호하지만, MMLU-Pro는 CoT(Chain-of-Thoughts) 추론이 더 나은 결과를 얻기 위해 필요합니다. 다음은 CoT를 활용했을 때와 활용하지 않았을 때의 결과를 비교한 표입니다:
| Models | Prompting | Overall | Biology | Business | Chemistry | ComputerScience | Economics | Engineering | Health | History | Law | Math | Philosophy | Physics | Psychology | Other |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | CoT | 0.7255 | 0.8675 | 0.7858 | 0.7393 | 0.7829 | 0.808 | 0.55 | 0.7212 | 0.7007 | 0.5104 | 0.7609 | 0.7014 | 0.7467 | 0.7919 | 0.7748 |
| GPT-4o | Direct | 0.5346 | 0.8102 | 0.392 | 0.3447 | 0.5813 | 0.6899 | 0.3981 | 0.6933 | 0.6949 | 0.542 | 0.3427 | 0.6614 | 0.3971 | 0.7628 | 0.6391 |
보시다시피, 연쇄 추론을 사용하지 않은 경우 성능이 19%까지 떨어졌으며, 이는 데이터 집합의 까다로운 특성을 반영합니다.
라이선스
이 프로젝트는 MIT License로 공개 및 배포되고 있습니다.
더 읽어보기
MMLU-Pro 데이터셋 다운로드 및 설명( Hugging Face)
Hugging Face)
MMLU-Pro GitHub 저장소
https://github.com/TIGER-AI-Lab/MMLU-Pro
MMLU-Pro를 사용한 리더보드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()