MobileLLM 연구 소개
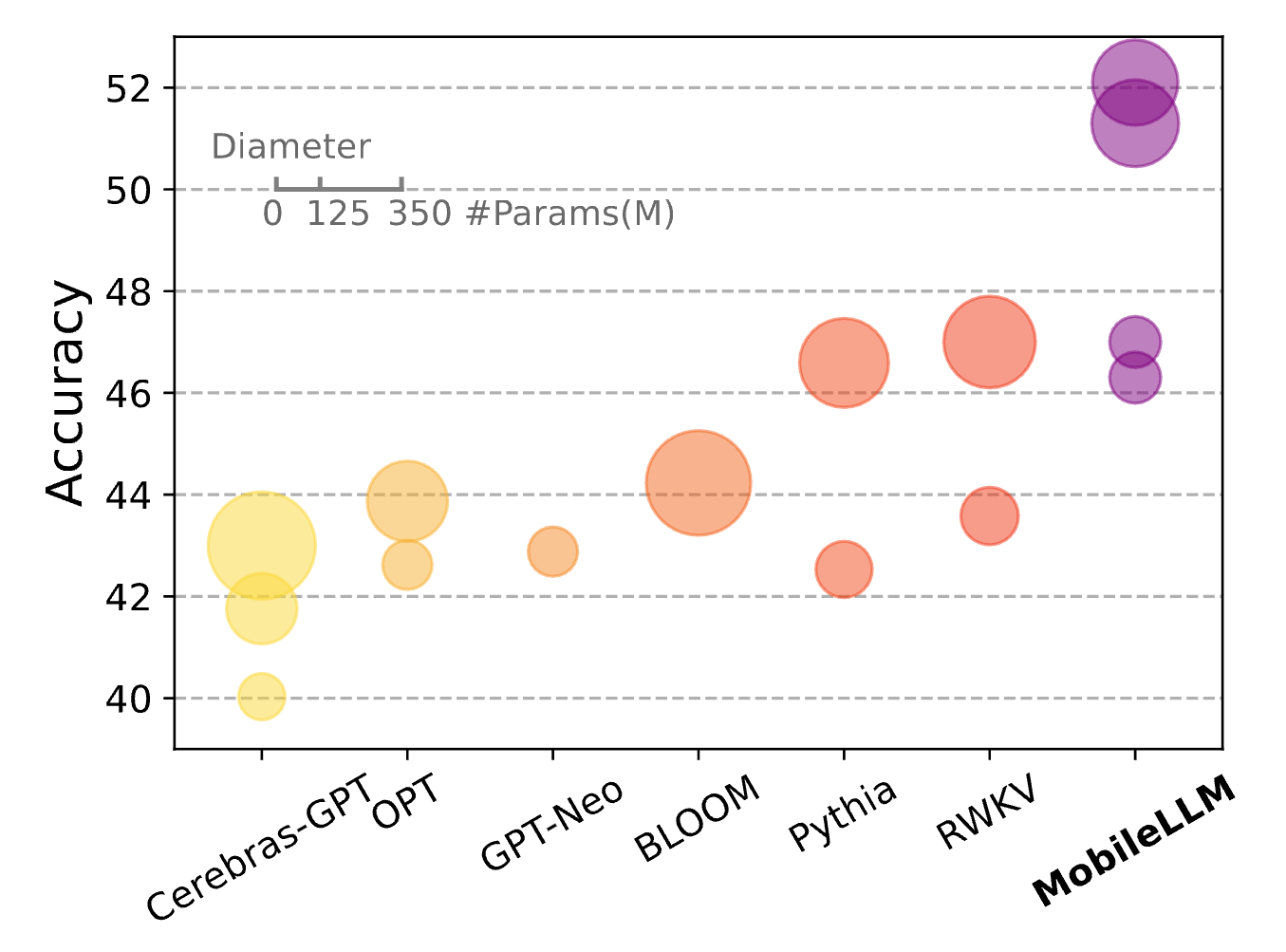
MobileLLM은 사용자 장치 등에서 바로 사용할 수 있도록 최적화하여 1B 미만 규모(sub-billion scale)의 언어 모델(LM, Language Model)로 최적화하는 연구입니다. Meta에서 진행한 연구로, 이러한 방식을 통해 제한적인 하드웨어에서 실질적으로 사용 가능한 모델을 최적화 및 배포할 수 있는 것을 목표로 합니다.
MobileLLM은 레이어 공유 등의 방법을 사용하여 모델 크기를 증가시키지 않고도 정확도를 향상시키는 접근 방식을 취합니다. 이 접근 방식은 모델 크기가 주요 제약인 On-Device 시나리오에서 유용합니다. 실험 결과에 따르면 트랜스포머 블록을 단순히 복제하는 것만으로도 성능 향상이 가능했습니다. 또한, 세 가지 다른 가중치 공유 전략을 검토한 결과, 블록 단위 즉시 공유(Immediate Block-wise Sharing) 전략이 가장 효과적임을 확인했습니다.
기존의 모델 경량화 방법들
-
모델 프루닝(Pruning): 모델에서 덜 중요한 뉴런이나 파라미터를 제거하여 모델 크기를 줄이고 효율성을 높이는 기술입니다. 하지만 프루닝은 모델 성능 손실을 초래할 수 있습니다.
-
양자화(Quantization): 모델의 파라미터를 부동 소수점에서 8비트 정수와 같은 낮은 정밀도로 변환하여 모델 크기와 컴퓨팅 요구 사항을 줄이는 방법입니다. 양자화는 효과적이지만 모델 정확도가 저하될 수 있습니다.
-
지식 증류(Distillation): 더 큰 "교사(Teacher)" 모델에서 더 작은 "학생(Student)" 모델로 지식을 전달합니다. 이 방법은 작은 크기에도 성능을 유지하는 데 도움이 되지만, 추가 학습 복잡성과 시간이 필요합니다.
그 외에도 소규모 모델 설계에서는 TinyLLaMA와 같은 연구들이 있지만, 여전히 1B 이상의 크기가 필요로 합니다. 신경망 아키텍처 검색에서는 NAS(Neural Architecture Search) 알고리즘이 주로 사용되며, 레이어 공유에서는 트랜스포머의 중간 레이어를 공유하는 방법이 주로 연구되고 있습니다. 자세한 내용은 MobileLLM 논문의 4. Related Work 섹션(8~9page)을 참고해주세요.
더 작은 모델을 만들기 위한 기준(Baseline) 모델 구성
피드-포워드 네트워크(FFN, Feed-Forward Network) 선택
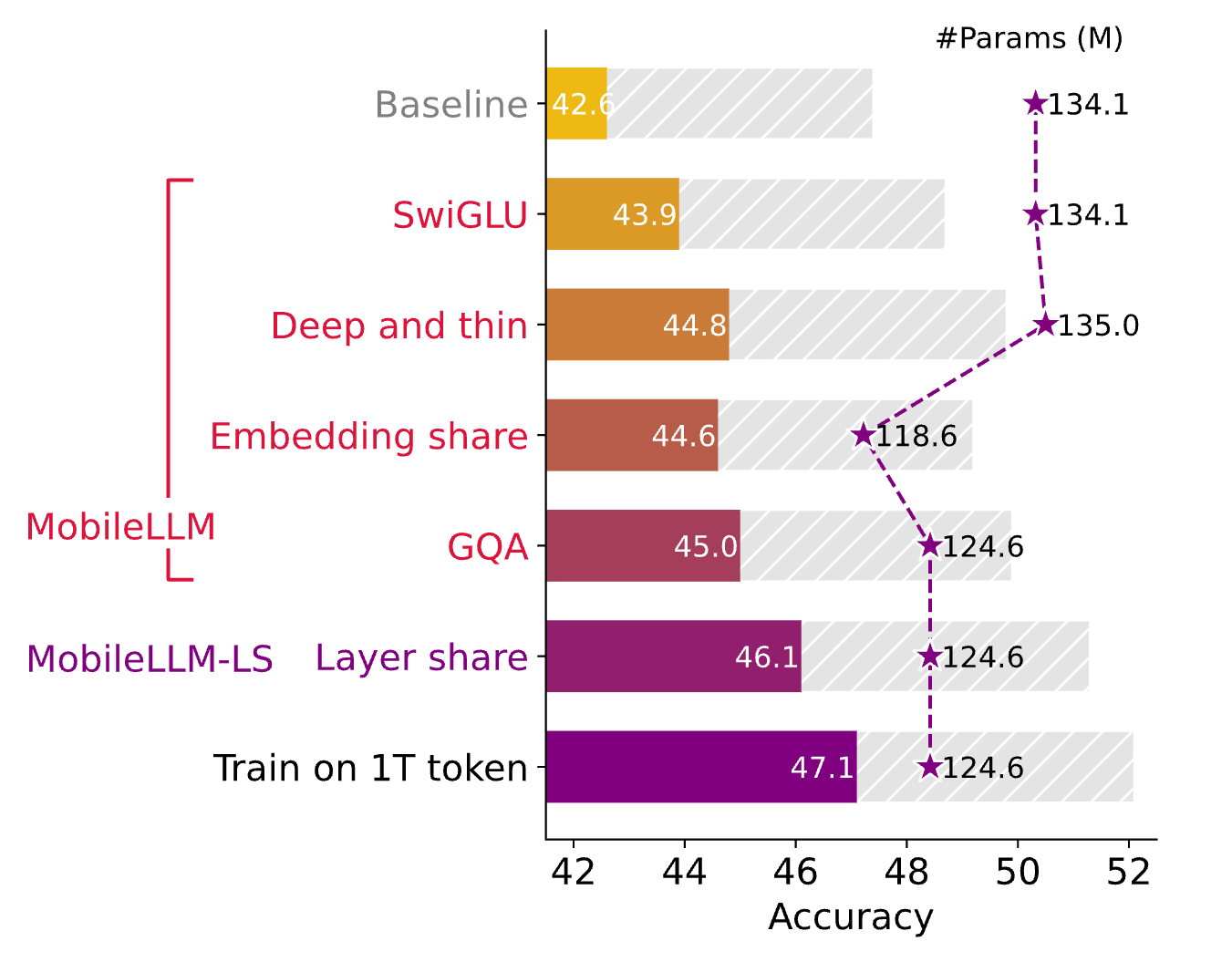
먼저 피드-포워드 네트워크(FFN, Feed-Forward Network)에서 일반적으로 사용되는 활성화 함수들을 조사하였으며, 최첨단 SwiGLU가 소규모 모델에서도 유익함을 발견했습니다. 기본 FFN(FC → ReLU → FC)을 SwiGLU로 변경함으로써, 125M 모델의 제로샷 추론 작업에서 평균 성능이 42.6에서 43.9로 향상되었습니다. 따라서 이후 실험에서는 FFN에서 SwiGLU를 사용하기로 했습니다.
SwiGLU는 두 개의 게이트를 사용하여 활성화 함수를 적용하는 방법으로, 더 복잡한 비선형성을 도입하여 모델의 학습 능력을 향상시킵니다. 이는 특히 소규모 모델에서 중요한데, 모델의 파라미터 수를 크게 늘리지 않고도 성능을 향상시킬 수 있기 때문입니다. 실험 결과는 이러한 접근 방식이 작은 모델에서 특히 효과적임을 보여주었습니다.
MobileLLM에서는 이 활성화 함수를 사용하여 모델 성능을 추가로 향상시켰습니다. 실험 결과, 125M 및 350M 모델 모두에서 약 1.3%의 성능 향상을 달성했습니다. 이는 모델의 비선형성을 증가시켜 더 복잡한 패턴을 학습할 수 있게 합니다.
깊이 vs. 넓이 (Depth vs. Width)
Scaling Law에 따르면, 일반적으로 트랜스포머 모델의 성능은 주로 매개변수의 수, 학습 데이터셋의 크기, 학습의 반복 회수에 의해 결정된다고 합니다. 즉, 모델의 아키텍처 설계가 트랜스포머 모델의 성능에 미치는 영향은 미미하다고 가정하고 있습니다. 하지만 연구 결과에 따르면 소규모 모델에서는 이러한 Scaling Law가 맞지 않을 수 있음을 보입니다.
하드웨어의 제약으로 모델의 깊이와 넓이를 모두 증가시킬 수는 없기 때문에, 논문에서는 깊고 얇은 모델(Deeper & Thinner)과 얕고 넓은 모델(Shallower & Wider)의 성능을 비교하는 접근 방식을 취했습니다.
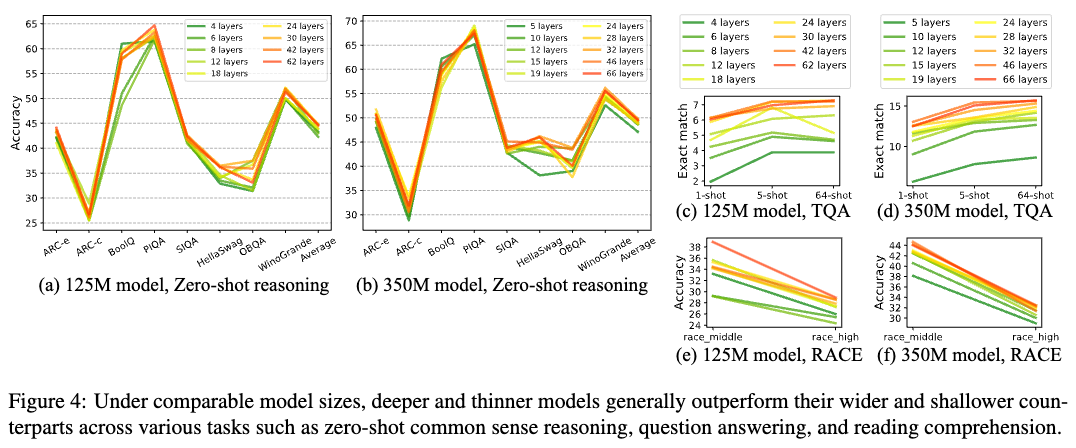
그 결과, 소규모 모델에서는 깊이가 너비보다 성능 향상에 더 중요한 요소임을 확인했습니다. 125M 파라미터 모델 9개와 350M 파라미터 모델 10개를 포함한 19개의 모델을 대상으로 한 광범위한 연구 결과, 깊고 얇은 모델이 얕고 넓은 모델보다 성능이 뛰어남을 보여주었습니다. 제로샷 상식 추론 작업 및 질문 응답, 독해 벤치마크에서 깊은 네트워크가 더 나은 성능을 보였으며, 이는 특히 TQA와 RACE 데이터셋에서 더욱 두드러졌습니다.
이 연구는 모델 크기가 약 125M인 트랜스포머 모델에서 30개 또는 42개의 레이어를 갖는 모델이 12개의 레이어를 갖는 모델보다 성능이 훨씬 뛰어남을 시사합니다. 이는 이전의 125M 모델들이 대부분 12개의 레이어로 제한되었던 것과 대조적입니다.
임베딩 공유(Embedding Sharing)
1B 미만 규모의 언어 모델(Sub-billion Scale Language Model)에서는 임베딩 레이어가 파라미터 수의 상당 부분을 차지합니다. 예를 들어, 임베딩 차원이 512이고 어휘 크기가 32k인 경우, 입력 및 출력 임베딩 레이어는 각각 1600만 개의 파라미터를 포함합니다. 이는 125M 파라미터 모델의 총 파라미터 중 20% 이상을 차지합니다. 반면, 더 큰 언어 모델에서는 이 비율이 훨씬 낮습니다.

MobileLLM에서는 입력과 출력 임베딩을 공유하여 모델의 파라미터 수를 줄이고 효율성을 높였습니다. 실험 결과, 30개의 레이어로 구성된 125M 모델에서 입력과 출력 임베딩을 공유하면 약 16M(135M - 119M)개의 파라미터가 줄어들고 평균 정확도는 0.2 포인트만 감소(44.8 -> 44.6)했습니다. 이렇게 절감된 파라미터를 사용하여 레이어 수를 늘리면 성능 저하를 쉽게 복구할 수 있습니다.
위 실험 결과에서 볼 수 있듯이 레이어를 30개에서 32개로 증가시키면, 기본 모델보다 10M(135M - 125M)개의 파라매터가 줄어들지만 평균 성능은 오히려 0.2 포인트 향상(44.8 -> 45.0)됩니다.
최적의 헤드(Head) 및 키-값 헤드(KV-Head) 수
논문에서는 또한 트랜스포머 모델 기반의 작은 모델에 대한 최적의 헤드 크기를 조사했습니다. 헤드 크기를 선택할 때 중요한 고려 사항은 1) 헤드 차원당 더 많은 의미론적 정보를 얻는 것과 2) 여러 헤드의 비선형 조합입니다. 대부분의 이전 연구에서는 쿼리 헤드(Query-Heads)와 키-값 헤드(KV-Heads)의 수를 동일하게 사용했지만, 논문에서는 그룹 쿼리 어텐션(Group Query Attention)이 작은 LLM에서 키-값 헤드의 중복을 효과적으로 줄일 수 있음을 발견했습니다.
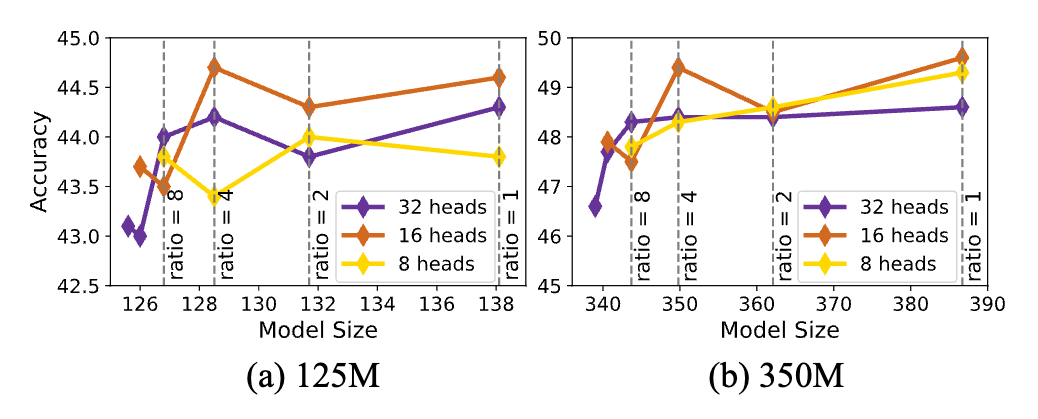
125M 및 350M 모델에서 최적의 헤드 크기를 결정하기 위한 실험을 수행한 결과, 16개의 쿼리 헤드를 사용했을 때 가장 좋은 결과를 얻을 수 있었습니다. 또한, 키-값 헤드의 수를 16개에서 4개로 줄여도 125M 모델에서는 유사한 정확도를, 350M 모델에서는 정확도가 0.2 포인트만 감소하면서 모델 크기는 거의 10% 줄었습니다. 이를 통해 그룹 쿼리 어텐션(GQA, Group Query Attention)을 도입하고 임베딩 차원을 늘려 모델 크기를 유지함으로써 125M 모델의 정확도를 추가로 0.4 포인트 향상시킬 수 있었습니다.
결론 - 기본 모델 구성
앞에서 살펴본 내용들을 종합적으로 구성하여 기본 모델(Baseline Model)을 구성하였습니다. 즉, SwiGLU를 사용한 FFN, 깊고 얇은 아키텍처, 임베딩 공유, 그룹 쿼리 어텐션을 포함한 모델 구조를 통해 MobileLLM이라는 sLM(Small Language Model)을 구축하였습니다. 또한, 여기에 레이어 공유(Layer Sharing) 기법을 추가하여 소규모 모델의 성능을 최적화할 수 있었습니다.
레이어 공유(Layer Sharing)
MobileLLM은 레이어 공유(Layer Sharing)를 통해 기존의 소규모 언어 모델(sLM; Small Language Model)보다 더 많은 숨겨진 레이어를 추가하여 모델 성능을 향상시키는 것을 목표로 합니다. 실험 결과에 따르면, 트랜스포머 블록을 단순히 복제하는 것만으로도 성능 향상이 가능했습니다.
레이어 공유(Layer Sharing)는 신경망의 여러 레이어에서 동일한 가중치를 재사용하는 방법입니다. 이 기술은 고유한 파라미터 수를 줄이면서도 모델의 깊이를 효과적으로 증가시켜, 온-디바이스(on-device) 응용 프로그램에 더 효율적으로 만들 수 있습니다.
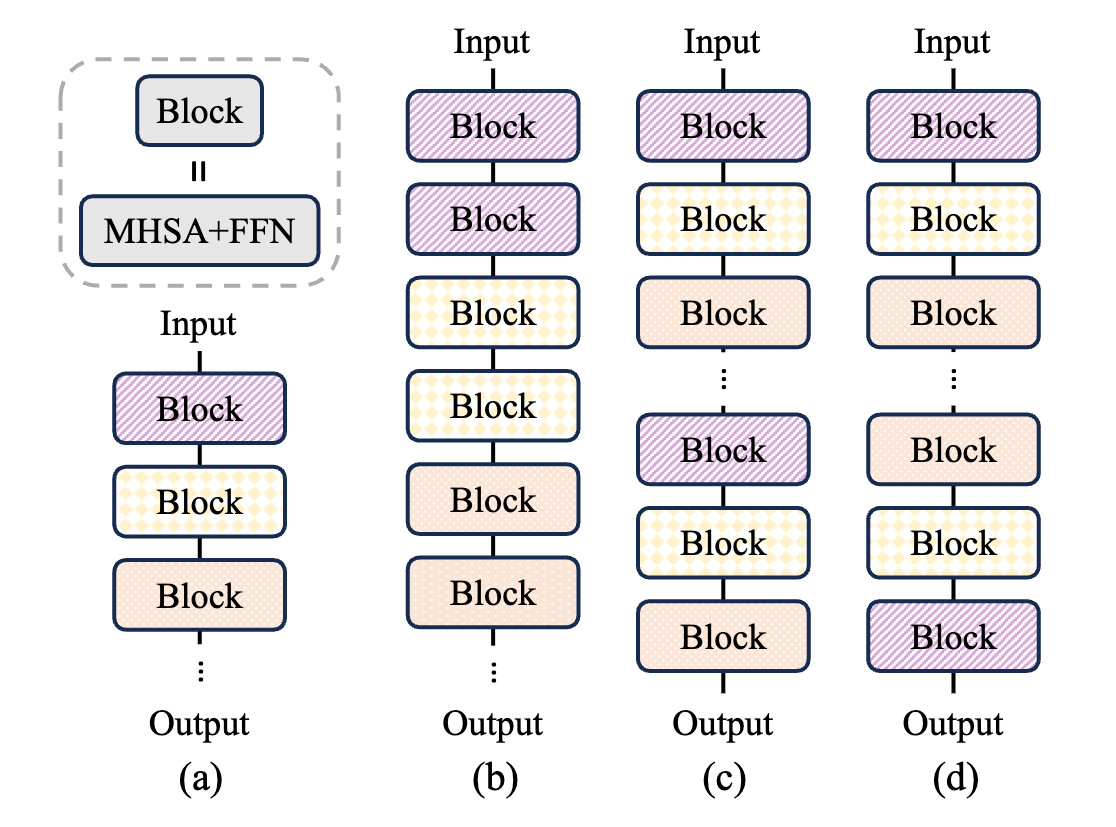
위 그림은 논문에 소개된 레이어 공유(Layer Sharing)에 대한 그림(Fig.6)입니다. 좌측부터 (a)는 레이어 공유가 없는 기본 모델, (b)는 즉각적인 블록 단위(Imeediate Block-wise) 공유, (c)는 전체 반복(Repeat-All-Over) 공유, (d)는 역방향(Reverse) 공유를 도식화한 것입니다.
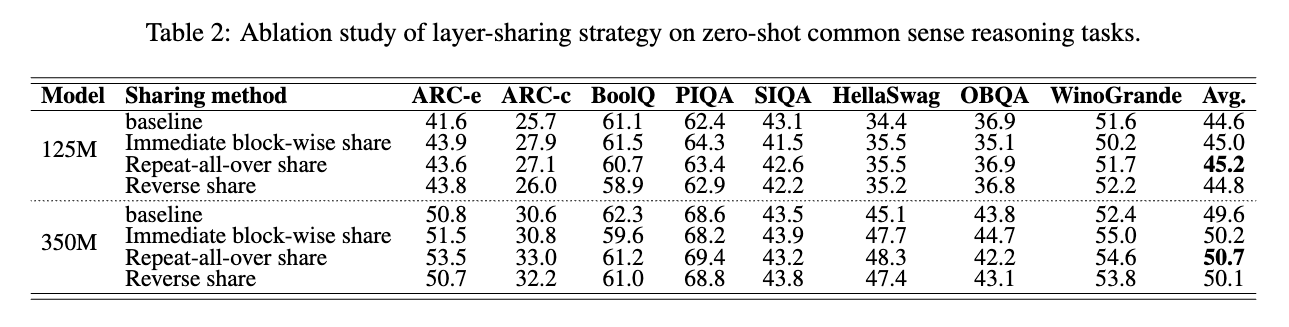
논문에서는 위 3가지(b, c, d)의 세 가지 가중치 공유 전략을 비교하였습니다. 그 결과, (b)의 블록 단위 즉시 공유 전략이 가장 높은 성능을 보였습니다. 이는 즉각적인 블록별(Imeediate Block-wise) 공유가 동일한 가중치(= 공유 가중치)의 블록을 바로 두번씩 연산을 하기 때문에, 가장 캐시를 잘 활용할 수 있어 전체적인 실행 속도 개선에 도움이 되었기 때문으로 보입니다. 즉, 하드웨어 메모리 계층을 활용하여 SRAM과 DRAM 간의 가중치 전송을 최소화할 수 있습니다.
이러한 레이어 공유 방법은 전체 모델을 양자화(Quantization) 후에도 유효하며, 최소한의 성능 손실로 정확도를 유지할 수 있습니다.
결과
지금까지 살펴본 방법들을 통해 모델의 크기를 줄이면서 성능을 향상시킬 수 있는 소규모 모델을 설계할 수 있었습니다.
또한, 1B 미만 크기의 다른 언어 모델들과 비교해봤을 때, MobileLLM 및 MobileLLM-LS(Layer Sharing) 모델들이 규모 대비 성능이 우수함을 확인할 수 있었습니다. 아래는 제로샷 상식(Common Sense) 분야에서의 추론, 질문 응답, 독해 작업에서 우수한 성능을 보여줍니다. 레이어 공유(Layer Sharing) 기술은 최소한의 컴퓨팅 오버헤드로 정확도를 더욱 향상시킴을 확인할 수 있습니다.

iPhone 13에서 MobileLLM-125M 및 MobileLLM-LS-125M 모델의 지연 시간을 측정한 결과, 레이어 공유를 통해 모델 크기를 두 배로 늘린 경우에도 로딩 및 초기화 시간은 2.2%만 증가하였고, 실행 시간도 2.6%만 증가했습니다. 이는 가중치 공유를 통해 데이터 국소성을 유지하면서 효율적으로 처리할 수 있었기 때문입니다. 반면, 가중치를 공유하지 않고 레이어 수를 두 배로 늘린 모델은 로딩 및 초기화 시간이 143% 증가하였고, 실행 시간도 86% 증가했습니다.
또한, MobileLLM 모델은 채팅 및 API 호출과 같은 실제 작업에서도 성능 향상을 보였으며, 더 큰 파라미터 크기의 모델과 비교해도 비슷하거나 더 나은 성능을 보입니다. 마지막으로 더 넓은 범위의 메모리 제약 조건에서 설계 원칙을 더욱 검증하기 위해 MobileLLM-600M, 1B 및 1.5B 구성을 포함하도록 모델을 확장했습니다. 이에 대한 전체적인 성능 비교 결과는 아래와 같습니다:
MobileLLM-125M 모델의 성능 비교
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| OPT-125M | 41.3 | 25.2 | 57.5 | 62.0 | 41.9 | 31.1 | 31.2 | 50.8 | 42.6 |
| GPT-neo-125M | 40.7 | 24.8 | 61.3 | 62.5 | 41.9 | 29.7 | 31.6 | 50.7 | 42.9 |
| Pythia-160M | 40.0 | 25.3 | 59.5 | 62.0 | 41.5 | 29.9 | 31.2 | 50.9 | 42.5 |
| MobileLLM-125M | 43.9 | 27.1 | 60.2 | 65.3 | 42.4 | 38.9 | 39.5 | 53.1 | 46.3 |
| MobileLLM-LS-125M | 45.8 | 28.7 | 60.4 | 65.7 | 42.9 | 39.5 | 41.1 | 52.1 | 47.0 |
MobileLLM-350M 모델의 성능 비교
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| OPT-350M | 41.9 | 25.7 | 54.0 | 64.8 | 42.6 | 36.2 | 33.3 | 52.4 | 43.9 |
| Pythia-410M | 47.1 | 30.3 | 55.3 | 67.2 | 43.1 | 40.1 | 36.2 | 53.4 | 46.6 |
| MobileLLM-350M | 53.8 | 33.5 | 62.4 | 68.6 | 44.7 | 49.6 | 40.0 | 57.6 | 51.3 |
| MobileLLM-LS-350M | 54.4 | 32.5 | 62.8 | 69.8 | 44.1 | 50.6 | 45.8 | 57.2 | 52.1 |
MobileLLM-600M 모델의 성능 비교
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| Qwen1.5-500M | 54.7 | 32.1 | 46.9 | 68.9 | 46.0 | 48.8 | 37.7 | 55.0 | 48.8 |
| BLOOM-560M | 43.7 | 27.5 | 53.7 | 65.1 | 42.5 | 36.5 | 32.6 | 52.2 | 44.2 |
| MobiLlama-800M | 52.0 | 31.7 | 54.6 | 73.0 | 43.3 | 52.3 | 42.5 | 56.3 | 50.7 |
| MobileLLM-600M | 58.1 | 35.8 | 61.0 | 72.3 | 44.9 | 55.9 | 47.9 | 58.6 | 54.3 |
MobileLLM-1B 모델의 성능 비교
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| Pythia-1B | 49.9 | 30.4 | 58.7 | 69.2 | 43.3 | 47.4 | 38.6 | 52.2 | 48.7 |
| MobiLlama-1B | 59.7 | 38.4 | 59.2 | 74.5 | 44.9 | 62.0 | 43.7 | 59.0 | 55.2 |
| Falcon-1B | 59.5 | 38.4 | 63.9 | 74.6 | 44.6 | 62.9 | 45.6 | 60.9 | 56.3 |
| BLOOM-1.1B | 47.6 | 27.3 | 58.6 | 67.0 | 42.4 | 42.2 | 36.6 | 53.8 | 46.9 |
| TinyLlama-1.1B | 59.2 | 37.1 | 58.1 | 72.9 | 43.9 | 59.1 | 44.7 | 58.8 | 54.2 |
| MobileLLM-1B | 63.0 | 39.0 | 66.7 | 74.4 | 45.0 | 61.4 | 46.8 | 62.3 | 57.3 |
MobileLLM-1.5B 모델의 성능 비교
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| GPT-neo-1.3B | 51.3 | 33.0 | 61.8 | 70.9 | 43.7 | 48.6 | 41.2 | 54.5 | 50.6 |
| OPT-1.3B | 54.4 | 31.7 | 58.4 | 71.5 | 44.7 | 53.7 | 44.6 | 59.1 | 52.3 |
| BLOOM-1.7B | 50.9 | 31.2 | 61.7 | 70.0 | 43.2 | 47.2 | 36.2 | 56.1 | 49.6 |
| Qwen1.5-1.8B | 61.1 | 36.5 | 68.3 | 74.1 | 47.2 | 60.4 | 42.9 | 61.2 | 56.5 |
| GPT-neo-2.7B | 55.8 | 34.3 | 62.4 | 72.9 | 43.6 | 55.6 | 40.0 | 57.9 | 52.8 |
| OPT-2.7B | 56.6 | 34.6 | 61.8 | 74.5 | 45.6 | 60.2 | 48.2 | 59.6 | 55.1 |
| Pythia-2.8B | 59.4 | 38.9 | 66.1 | 73.8 | 44.5 | 59.6 | 45.0 | 59.4 | 55.8 |
| BLOOM-3B | 55.1 | 33.6 | 62.1 | 70.5 | 43.2 | 53.9 | 41.6 | 58.2 | 52.3 |
| MobileLLM-1.5B | 67.5 | 40.9 | 65.7 | 74.8 | 46.4 | 64.5 | 50.5 | 64.7 | 59.4 |
 MobileLLM 논문
MobileLLM 논문
 MobileLLM GitHub 저장소
MobileLLM GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()