Moirai: 다양한 예측을 위한 시계열 파운데이션 모델 (feat. Salesforce)
요약

Moirai는 범용 예측 기능을 제공하는 최첨단 시계열 기초 모델입니다. 여러 도메인, 주파수 및 변수에 걸쳐 다양한 예측 작업을 제로 샷 방식으로 처리할 수 있는 다목적 시계열 예측 모델이라는 점이 특징입니다. 이를 위해 Moirai(모이라이)는 (i) 9개 영역에 걸쳐 270억 개의 관측치로 구성된 대규모의 다양한 시계열 데이터 세트인 LOTSA 구축, (ii) 단일 모델이 다양한 주파수에 걸쳐 시간적 패턴을 포착할 수 있는 다중 패치 크기 투영 레이어 개발, (iii) 단일 모델이 모든 변수에 대한 예측을 처리할 수 있는 임의 변수 주의 메커니즘 구현, (iv) 유연한 예측 분포 모델을 위한 혼합 분포 통합의 네 가지 주요 과제를 해결하고 있습니다. 분포 내 및 분포 외 환경 모두에서 종합적인 평가를 통해 Moirai는 풀샷 모델에 비해 경쟁력이 있거나 우수한 성능을 일관되게 제공함으로써 제로샷 예측자로서의 역량을 입증했습니다.
소개

Moirai는 범용 시계열 예측 모델로, 다양한 도메인과 빈도의 데이터를 하나의 모델로 처리합니다. 기존의 시계열 모델은 특정 데이터셋에 맞춰 훈련되었지만, Moirai는 대규모 데이터셋 LOTSA를 활용하여 다양한 패턴을 학습합니다. 이를 통해 Moirai는 여러 분야의 시계열 데이터를 효과적으로 예측할 수 있는 능력을 갖추게 되었습니다.
기존의 시계열 모델은 주로 단일 도메인과 고정된 빈도로 훈련되었지만, Moirai는 다중 빈도, 다변량 데이터를 한꺼번에 처리할 수 있습니다. 이는 기존 모델 대비 훈련과 운영의 효율성을 크게 향상시킵니다.
주요 특징

-
다중 빈도 예측: 다양한 빈도의 데이터를 처리하기 위해 여러 크기의 패치 투영 레이어를 도입.
-
다변량 주의 메커니즘: Rotary Position Embeddings와 이진 주의 편향을 통해 다변량 데이터를 하나의 시퀀스로 처리.
-
혼합 분포 사용: 유연한 예측 분포를 위해 혼합 분포를 최적화, 다양한 데이터셋에 대응.
-
LOTSA 데이터셋: 27억 개의 관측값을 포함한 대규모 시계열 데이터셋을 사용하여 모델을 훈련.
성능 평가
Moirai의 성능은 다양한 시계열 예측 작업에서 평가되었습니다. 이를 위해 각기 다른 도메인과 주기를 포함한 대규모 데이터셋을 사용하였습니다. 주요 성능 지표는 평균 절대 백분율 오차(MAPE), 평균 제곱 오차(MSE), 평균 절대 오차(MAE) 등이 있습니다. 각각의 성능 지표에 대한 설명은 다음과 같습니다:
- MAPE (Mean Absolute Percentage Error): 예측값과 실제값 간의 평균 절대 백분율 차이
- MSE (Mean Squared Error): 예측값과 실제값 간의 제곱 평균 차이
- MAE (Mean Absolute Error): 예측값과 실제값 간의 절대 오차의 평균

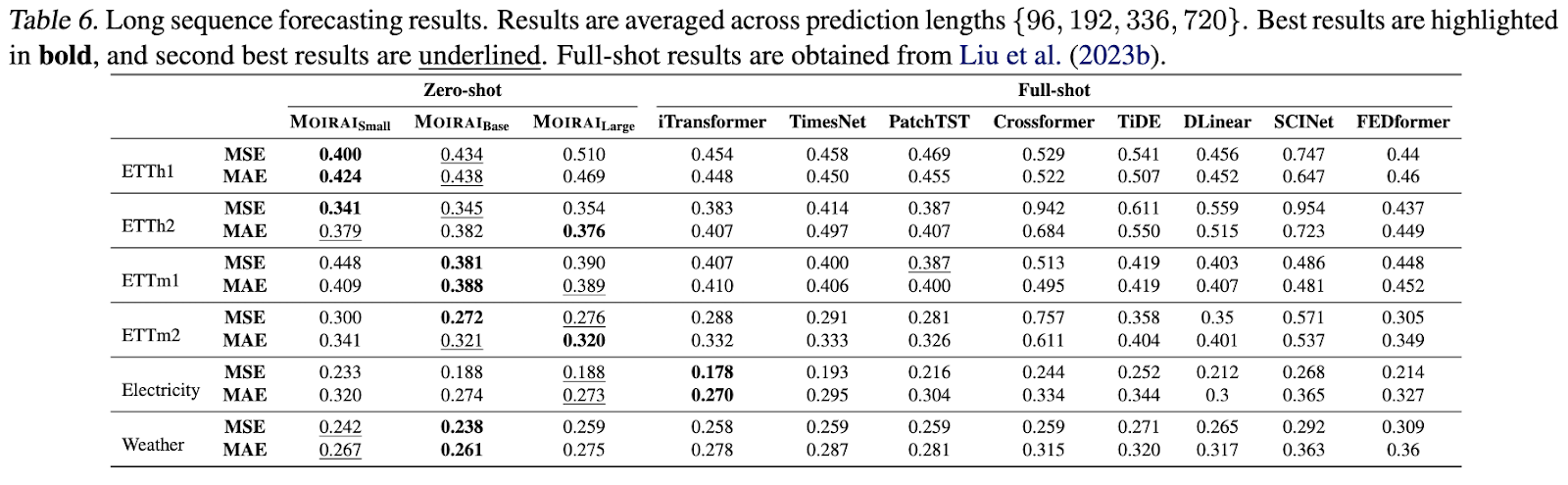
Moirai는 범용 시계열 예측 모델로서 다양한 도메인에서 뛰어난 성능을 입증하였습니다. 특히 제로샷 예측에서의 높은 정확도와 유연성은 Moirai의 큰 장점입니다. 다양한 크기의 모델을 제공하여 사용자의 필요에 맞게 선택할 수 있으며, 기존의 시계열 예측 모델들보다 더 나은 성능을 보입니다.
- Prophet vs Moirai: Moirai가 더 낮은 MAPE와 MAE를 기록
- ARIMA vs Moirai: Moirai가 더 낮은 MSE를 기록
- LSTM vs Moirai: Moirai가 더 높은 예측 정확도를 보임
사용 방법
Moirai는 Transformer 기반의 시계열 예측 모델로, 입력 데이터의 패치를 벡터로 투영하여 처리합니다. 각 패치는 예측 구간을 나타내며, 혼합 분포의 매개변수로 변환됩니다. 예측을 위해서는 다양한 도메인의 데이터를 통합하여 사용하며, 특히 IT 운영, 판매 예측, 에너지 예측 등에서 활용도가 높습니다.
Moirai는 작은(small), 기본(base), 큰(large) 세 가지 크기로 제공됩니다. 각 모델 크기별 성능은 다음과 같습니다:
-
작은 모델 (Moirai-Small): 빠른 연산 시간 / 적은 메모리 사용 / 비교적 낮은 예측 정확도
-
기본 모델 (Moirai-Base): 적절한 연산 시간과 메모리 사용 / 높은 예측 정확도
-
큰 모델 (Moirai-Large): 긴 연산 시간 / 많은 메모리 사용 / 최고의 예측 정확도
관련하여 Salesforce가 공개한 Uni2TS를 사용하여 사전 학습된 모델에서 제로샷 예측을 수행하는 간단한 예제입니다. 데이터는 pandas를 사용하여 넓은 DataFrame 형식으로 로드됩니다. Uni2TS는 GluonTS를 활용하여 데이터셋을 train/test로 분할하고 롤링 평가를 수행합니다.
import torch
import matplotlib.pyplot as plt
import pandas as pd
from gluonts.dataset.pandas import PandasDataset
from gluonts.dataset.split import split
from huggingface_hub import hf_hub_download
from uni2ts.eval_util.plot import plot_single
from uni2ts.model.moirai import MoiraiForecast
SIZE = "small"
PDT = 20
CTX = 200
PSZ = "auto"
BSZ = 32
TEST = 100
url = (
"https://gist.githubusercontent.com/rsnirwan/c8c8654a98350fadd229b00167174ec4"
"/raw/a42101c7786d4bc7695228a0f2c8cea41340e18f/ts_wide.csv"
)
df = pd.read_csv(url, index_col=0, parse_dates=True)
ds = PandasDataset(dict(df))
train, test_template = split(ds, offset=-TEST)
test_data = test_template.generate_instances(prediction_length=PDT, windows=TEST // PDT, distance=PDT)
model = MoiraiForecast.load_from_checkpoint(
checkpoint_path=hf_hub_download(
repo_id=f"Salesforce/moirai-1.0-R-{SIZE}", filename="model.ckpt"
),
prediction_length=PDT,
context_length=CTX,
patch_size=PSZ,
num_samples=100,
target_dim=1,
feat_dynamic_real_dim=ds.num_feat_dynamic_real,
past_feat_dynamic_real_dim=ds.num_past_feat_dynamic_real,
map_location="cuda:0" if torch.cuda.is_available() else "cpu",
)
predictor = model.create_predictor(batch_size=BSZ)
forecasts = predictor.predict(test_data.input)
input_it = iter(test_data.input)
label_it = iter(test_data.label)
forecast_it = iter(forecasts)
inp = next(input_it)
label = next(label_it)
forecast = next(forecast_it)
plot_single(inp, label, forecast, context_length=200, name="pred", show_label=True)
plt.show()
평가 및 파인튜닝을 위해서는 Uni2TS GitHub 저장소를 참고해주세요.
라이선스
이 프로젝트는 MIT License로 공개 및 배포되고 있습니다.
더 읽어보기
Moirai 소개 글
Moirai 논문: Unified Training of Universal Time Series Forecasting Transformers
Moirai 코드 저장소: Uni2TS
https://github.com/SalesforceAIResearch/uni2ts