MosaicML은 MPT-7B-8K를 발표하였습니다. 이는 8k 문맥 길이를 가진 7B 파라미터의 오픈 소스 LLM으로, MosaicML 플랫폼에서 훈련되었습니다. MPT-7B-8K는 문서 요약 및 질문 응답에 특화되어 있으며, MPT Foundation Series의 다른 모델들처럼, MPT-7B-8k는 더 빠른 훈련과 추론을 위해 최적화되어 있으며, MosaicML 플랫폼에서 도메인 특정 데이터에 대해 세부 조정할 수 있습니다.
요약
MPT-7B-8K는 MPT-7B 체크포인트에서 시작하여 시퀀스 길이를 8k로 업데이트하고 추가적인 500B 토큰에 대해 훈련하여 총 1.5T 토큰의 텍스트와 코드로 사전 훈련된 디코더 스타일의 트랜스포머입니다. 이 모델은 상업적 사용 가능성을 위해 라이선스가 부여되었으며, 대량의 데이터(1.5T 토큰)에 대해 훈련되었습니다. 이는 ALiBi 덕분에 긴 입력을 처리할 수 있으며, 이를 통해 모델은 8k 훈련 시퀀스 길이를 넘어서 최대 10k까지 외삽할 수 있습니다. 또한 수백만 토큰을 이용하여 더 멀리 외삽하기 위해 세부 조정할 수 있습니다.
오늘, 우리는 MosaicML 플랫폼으로 학습된 8k 컨텍스트 길이를 가진 7B 파라미터 오픈 소스 LLM인 MPT-7B-8K를 출시합니다. MPT-7B-8K는 MPT-7B 체크포인트에서 시작하여 256개의 NVIDIA H100에서 3일 동안 추가로 500B 토큰의 데이터로 사전 학습되었습니다.
MPT-7B-8k는 그 8k 컨텍스트 길이로 문서 요약과 질문 응답에 특화되어 있습니다. MPT Foundation Series의 다른 모든 모델들처럼, MPT-7B-8k는 더 빠른 학습과 추론을 위해 최적화되어 있으며, MosaicML 플랫폼에서 도메인 특정 데이터에 대해 미세 조정될 수 있습니다.
요약
오늘, 우리는 3가지 모델을 출시합니다:
MPT-7B-8k: MPT-7B에서 시작하여 시퀀스 길이를 8k로 업데이트하고 추가로 500B 토큰을 학습하여 총 1.5T 토큰의 텍스트와 코드를 결과로 내는 디코더 스타일의 트랜스포머입니다. 라이센스: CC-BY-SA-3.0
MPT-7B-8k-Instruct: 장문의 지시사항을 따르는 모델(특히 요약 및 질문 응답). MPT-7B-8k를 여러 개의 신중하게 선별된 데이터셋에서 미세 조정하여 구축하였습니다. 라이센스: CC-BY-SA-3.0
MPT-7B-8k-Chat: 대화 생성을 위한 챗봇 같은 모델. MPT-7B-8k를 대략 1.5B 토큰의 채팅 데이터에서 미세 조정하여 구축하였습니다. 라이센스: CC-By-NC-SA-4.0
복잡한 문서의 이해를 향상시키거나, 단순히 시간과 노력을 절약하려는 경우, MosaicML 플랫폼에서의 MPT-7B-8k는 언어 데이터에 추론 능력을 추가하려는 기업들에게 좋은 출발점이 될 것입니다.
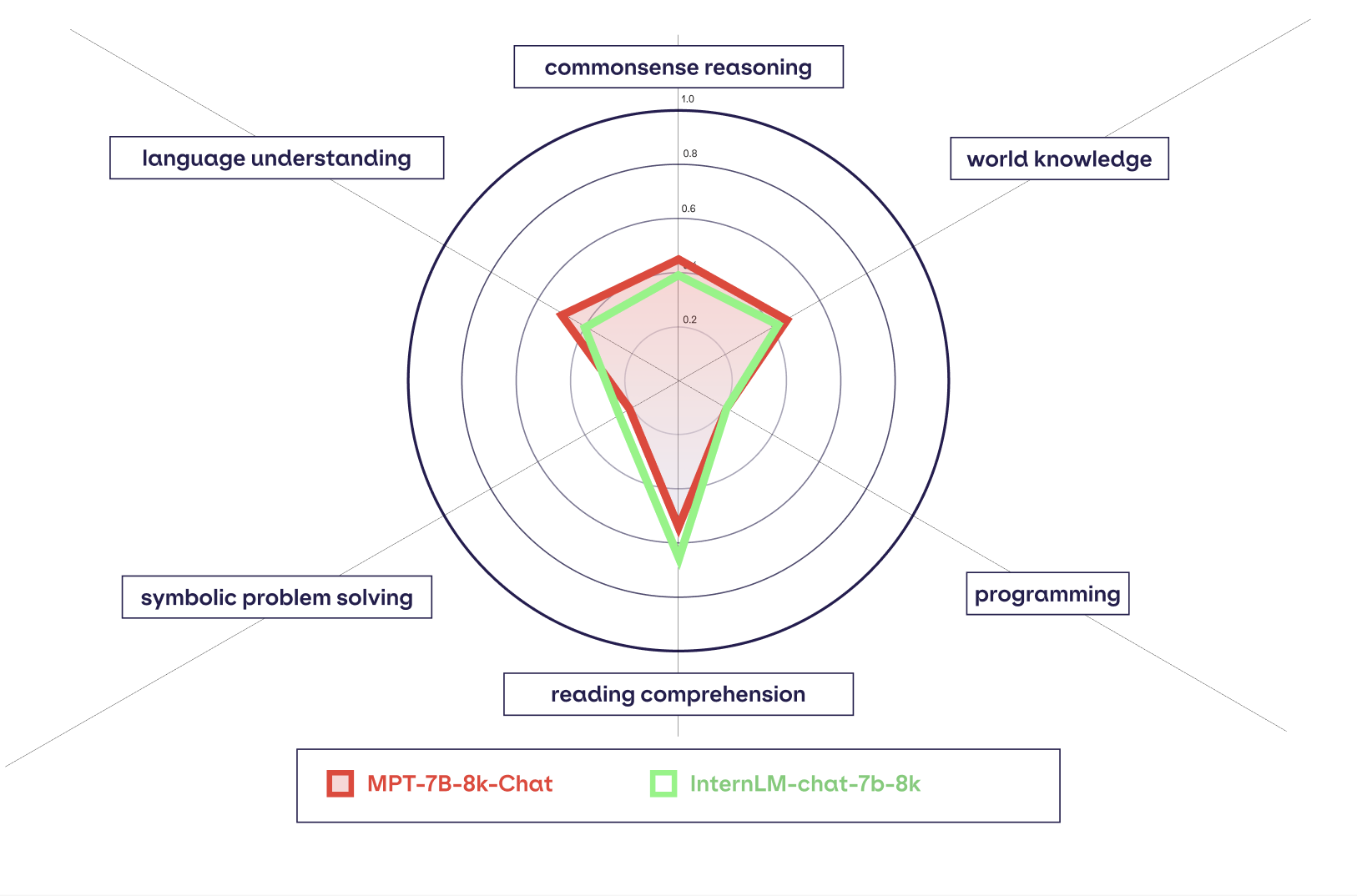
또한, MPT-7B-8k 모델들은 우리의 인-컨텍스트 학습 평가 하네스에서 다른 오픈 소스 8K 컨텍스트 길이 모델들과 비슷하게 또는 더 나은 성능을 보입니다. 우리의 인-컨텍스트 학습 평가 하네스에 대해 더 알아보고, 다른 오픈 소스 LLM들과의 비교 결과를 보려면, 우리의 새로운 LLM 평가 페이지를 확인해보세요. 질적인 결과를 선호한다면, 모델을 다운로드하여 우리의 Community Slack에서 결과를 공유하거나, 블로그 하단의 긴 컨텍스트 길이 읽기 이해 예제를 확인해보세요.