
NeMo Curator 소개
NVIDIA가 공개한 NeMo Curator는 대규모 언어 모델(LLM)과 멀티모달 생성형 AI를 위한 데이터 전처리 및 큐레이션을 지원하는 Python 기반 라이브러리입니다. 대규모 모델 학습에서 가장 중요한 요소 중 하나는 ‘데이터의 품질’인데, 기존에는 방대한 텍스트·이미지 데이터를 수집한 뒤 이를 정제하는 과정에서 엄청난 시간이 소요되었습니다. NeMo Curator는 GPU 가속 기반의 **Dask**와 RAPIDS 라이브러리를 활용하여 이러한 데이터 처리 과정을 획기적으로 단축시키며, 확장성과 유연성을 동시에 제공합니다.
이 툴킷은 단순히 데이터를 정리하는 것에 그치지 않고, 합성 데이터(synthetic data) 생성 파이프라인까지 지원합니다. 예를 들어, Q&A 데이터셋 생성, 수학 문제, 코딩 과제, 창작형 글쓰기 프롬프트 등 다양한 유형의 데이터를 자동으로 만들어낼 수 있습니다. 이를 통해 모델 학습 시 더 다양하고 균형 잡힌 학습 데이터를 제공할 수 있으며, 특정 도메인 적응(DAPT), 지도학습(SFT), 매개변수 효율적 튜닝(PEFT) 등에 큰 도움을 줍니다.
또한 NeMo Curator는 텍스트뿐만 아니라 이미지 데이터셋 큐레이션까지 지원합니다. WebDataset 형식의 이미지-텍스트 데이터셋을 불러와 CLIP 임베딩 기반 분석, NSFW 필터링, 중복 제거 등을 거쳐 고품질 학습 데이터를 준비할 수 있습니다. 이러한 기능은 LLM뿐만 아니라 비전-언어 모델(VLM), 워크플로우 모델(WFM) 같은 다양한 생성형 AI 모델의 성능 향상에 직접적으로 기여합니다.
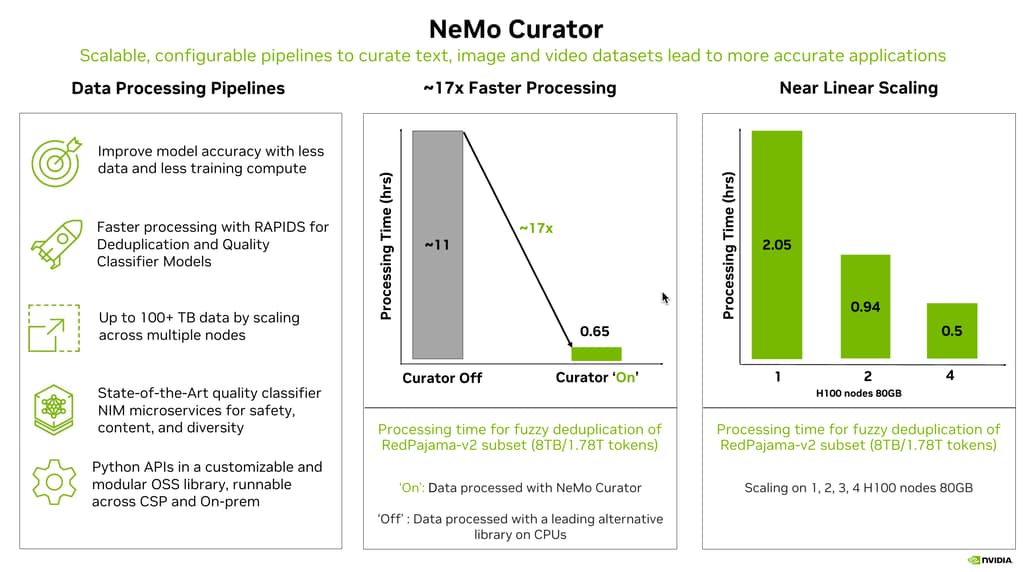
이러한 데이터 전처리와 큐레이션은 전통적으로 Hugging Face Datasets이나 OpenAI의 데이터 파이프라인 같은 오픈소스 생태계에서 많이 다루어졌습니다. 하지만 이러한 툴들은 보통 CPU 중심으로 작동하거나 특정 기능에 제한이 있어 대규모 데이터 처리에는 시간이 오래 걸리는 경우가 많습니다. 반면, NeMo Curator는 **GPU 다중 노드 환경에서 선형적 확장(near-linear scaling)**을 지원하여 수조 개 토큰 단위의 대규모 데이터셋도 짧은 시간 안에 처리할 수 있습니다. 실제로 RedPajama V2 데이터셋의 1.96조 토큰을 중복 제거하는데 32개의 H100 GPU로 단 0.5시간이 소요된 사례가 공개되었습니다.
즉, 기존 툴이 범용성과 접근성을 강조한다면, NeMo Curator는 대규모 기업·연구 환경에서 실질적으로 사용할 수 있는 고성능 엔터프라이즈급 솔루션이라는 점에서 차별화됩니다.
NeMo Curator의 주요 기능
텍스트 큐레이션
텍스트 데이터는 Load → Process → Generate의 세 단계 워크플로우를 따릅니다.
-
데이터 로드: Common Crawl, Wikipedia, ArXiv 등 주요 공개 소스에서 데이터를 다운로드하고 추출할 수 있습니다.
-
데이터 처리
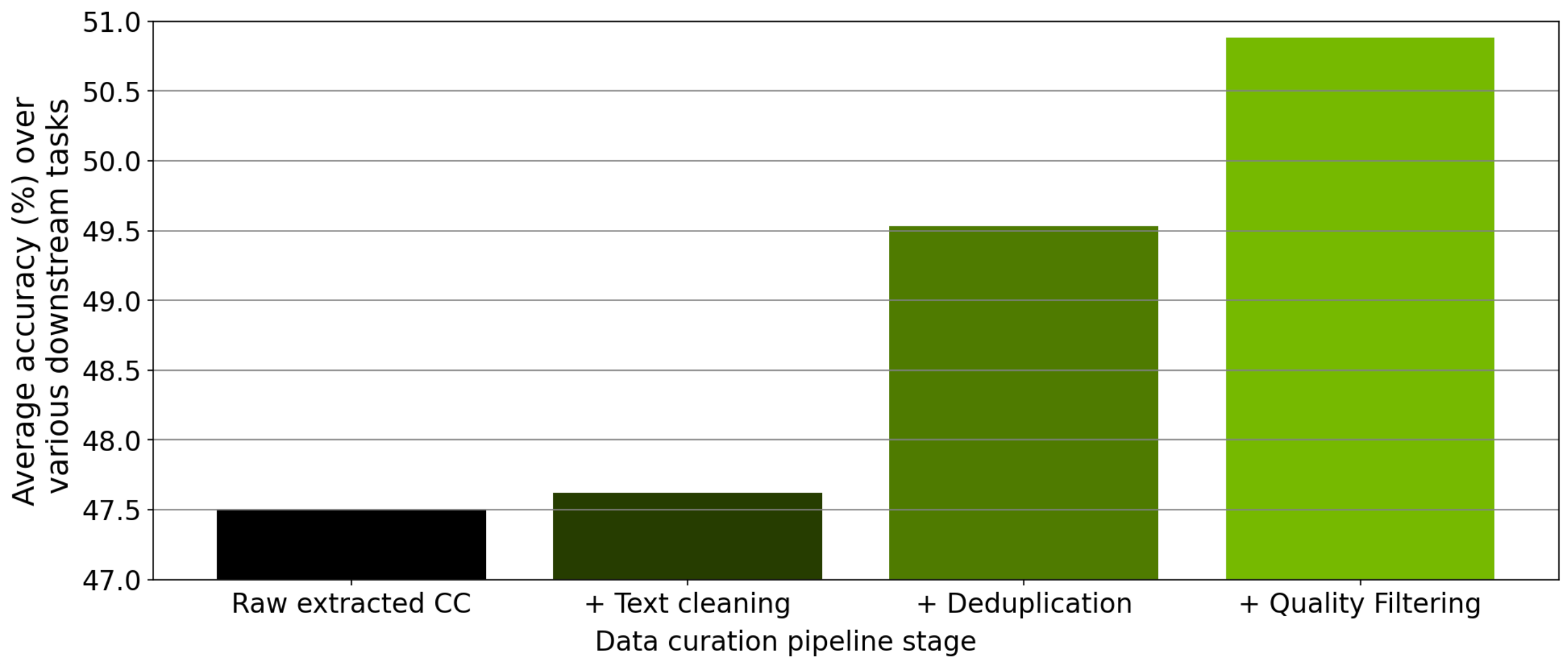
- 품질 평가 및 필터링: 30개 이상의 휴리스틱 필터, fastText 기반 언어/품질 분류기, GPU 가속 분류기를 활용해 도메인·안전성·교육용 여부 등을 판단합니다.
- 중복 제거: 정확 일치(Exact Match based Deduplication), 퍼지(fuzzy) 매칭, 의미론적(semantic) 중복 제거까지 GPU 기반으로 지원합니다.
- 콘텐츠 정제: 텍스트 클리닝, PII(개인정보) 제거, 언어 식별, 평가 데이터 오염 제거 등을 제공합니다.
- 데이터 생성: 합성 데이터 파이프라인을 통해 Q&A, 수학 문제, 코딩 과제, 창작 글쓰기, 대화형 데이터 등 다양한 학습 데이터를 생성할 수 있습니다.
이미지 큐레이션
이미지 데이터는 Load → Process 단계를 거칩니다.
-
데이터 로드: WebDataset 형식의 대규모 이미지-텍스트 데이터셋을 불러옵니다.
-
데이터 처리
- 임베딩 생성: CLIP 임베딩을 활용해 이미지 표현을 추출합니다.
- 품질 필터링: 심미적(Aesthetic) 분류, NSFW 필터링 기능 제공.
- 중복 제거: 의미론적 중복 제거로 시각적으로 유사한 이미지를 제거합니다.
성능 및 확장성
NeMo Curator는 NVIDIA RAPIDS 생태계(cuDF, cuML, cuGraph)와 Dask를 활용하여 멀티 GPU·멀티 노드 환경에서 거의 선형적으로 확장됩니다.
- 텍스트 처리 속도는 최대 16배 향상
- 대규모 데이터셋 중복 제거 시 H100 GPU 기반 초고속 처리 가능
이러한 성능은 LLM 및 생성형 AI 학습 파이프라인에서 모델 수렴 속도를 높이고, 학습 데이터 품질을 보장하는 데 큰 도움을 줍니다.
라이선스
NeMo Curator 프로젝트는 Apache License 2.0으로 공개 및 배포되고 있습니다. 상업적 사용에 제약이 없으며, 자유롭게 수정 및 재배포가 가능합니다.
 NeMo Curator GitHub 저장소
NeMo Curator GitHub 저장소
https://github.com/NVIDIA-NeMo/Curator
 NeMo Curator 빠른 시작을 위한 문서
NeMo Curator 빠른 시작을 위한 문서
-
상용 환경을 위한 확장(설정 및 배포): About Setup & Deployment - NeMo-Curator | NVIDIA
-
텍스트 데이터 큐레이션 빠른 시작: Get Started with Text Curation - NeMo-Curator | NVIDIA
-
이미지 데이터 큐레이션 빠른 시작: Get Started with Image Curation - NeMo-Curator | NVIDIA
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()