
NeurIPS 2024에 공개한 Apple의 주요 연구 소개
지난 12월 중순에 진행된 NeurIPS(Neural Information Processing Systems) 2024는 AI와 머신러닝(Machine Learning, ML) 분야에서 가장 중요한 연례 학회 중 하나로, 캐나다 밴쿠버에서 개최됩니다. 이번 NeurIPS 2024에서 Apple은 ML과 AI의 발전을 목표로 한 연구를 통해 프라이버시 보호 기술, 멀티모달 모델 향상, LLM 성능 개선 등 다양한 주제를 발표하였습니다. 각 연구들에 대해서 간략히 살펴보시죠.
프라이버시 보호 머신러닝: Advancing Privacy-Preserving ML
Apple은 개인정보 보호가 인간의 기본적 권리라고 믿으며, 개인정보 보호 ML 기술을 발전시키는 것을 지속적인 연구 주제로 삼고 있습니다. NeurIPS 2024에서 Apple 연구원들은 연합 학습(FL, Federated Learning)과 관련된 두 편의 논문을 발표하였습니다.
FL(Federated Learning)을 연구하는 연구원들은 새로운 아이디어를 빠르게 반복하기 위해 시뮬레이션을 통한 실험을 자주 수행합니다. Apple 연구원들은 pfl-research: 개인 연합 학습의 연구 가속화를 위한 시뮬레이션 프레임워크는 연구 커뮤니티가 이 주제에 대해 더 많은 진전을 이룰 수 있도록 지원하는 빠르고 모듈식이며 사용하기 쉬운 FL 시뮬레이션용 Python 프레임워크입니다.
Apple 연구원들은 또한 개인 연합 학습을 사용하여 개인화된 빈도 히스토그램을 비공개로 계산하는 새로운 접근 방식을 설명하는 연합 설정에서의 비공개 및 개인화된 빈도 추정을 발표하였습니다. 개인화된 단어(또는 토큰)의 빈도는 사용자 디바이스에서 키보드 입력을 위한 다음 단어 예측에 유용합니다. 대부분의 사용자는 사용 데이터가 거의 없고 사용자의 다양한 어휘, 주제, 스타일로 인해 데이터 분포가 다양하기 때문에 이 작업은 어렵습니다. 이 논문에서는 유사한 사용자 하위 집단을 발견하고 활용하는 새로운 기법을 제시하며, 이 접근 방식은 기존의 클러스터링 기반 알고리즘보다 성능이 뛰어난 것으로 나타났습니다.
멀티모달 모델의 성능 향상: Making Multimodal Models More Capable
멀티모달 및 멀티태스크 모델은 점점 더 강력해지고 있지만, 학습 데이터의 한계로 인해 그 효율성이 저해될 수 있습니다. NeurIPS에서 Apple ML 연구원들은 이러한 한계를 극복하고 이러한 모델의 성능을 향상시킬 수 있는 새로운 방법을 제시합니다.
CLIP과 같이 사전 학습된 대규모 시각 언어 모델은 잘 일반화되는 것으로 나타났지만, 사전 학습 데이터에서 시각적 개념이 제대로 표현되지 않은 세분화된 분류(예: 자동차 모델 식별)와 같은 작업에서는 여전히 어려움을 겪을 수 있습니다. NeurIPS에서 Apple ML 연구원들은 제한된 주석 데이터를 사용할 수 있을 때 CLIP을 미세 조정하기 위한 새로운 학습 프롬프트 방법을 보여주는 CLIP의 다운스트림 일반화를 위한 집계 및 적응 자연어 프롬프트를 발표할 예정입니다. 집계 및 적응형 프롬프트 임베딩(AAPE)을 사용하면 자연어 프롬프트(사람 또는 LLM에 의해 생성)에서 텍스트 지식을 추출하여 모델의 학습 데이터에서 잘 표현되지 않은 개념을 보강할 수 있습니다. 이 접근 방식은 CLIP의 다운스트림 일반화를 개선하여 이미지-텍스트 검색, 소수 샷 분류, 이미지 캡션 및 VQA를 비롯한 다양한 시각 언어 작업에서 강력한 성능을 달성합니다.

4M-21은 특화된 단일/소수의 작업 모델에 비해 성능 저하 없이 수십 개의 매우 다양한 양식에 대해 단일 모델을 훈련하는 것을 보여줍니다. 양식은 양식별 토큰화 도구를 사용하여 개별 토큰에 매핑됩니다. 이 모델은 양식의 하위 집합에서 모든 양식을 생성할 수 있습니다.
4M과 같은 멀티모달 및 멀티태스크 기반 모델은 유망한 결과를 보여주지만, 다양한 입력을 받아들이고 다양한 작업을 수행하는 능력은 훈련된 양식과 작업에 따라 제한됩니다. NeurIPS에서 Apple ML 연구원과 EPFL의 협력자들은 4M-21: 수십 가지 작업과 모달리티를 위한 애니투애니 비전 모델을 발표할 예정이며, 이 발표에서는 수십 가지의 매우 다양한 모달리티를 학습하고 대규모 멀티 모달 데이터 세트와 텍스트 말뭉치에 대한 공동 학습을 수행함으로써 4M의 기능을 크게 확장하는 방법을 보여줄 예정입니다. 결과 모델은 최대 30억 개의 파라미터로 확장되며 강력한 즉시 사용 가능한 비전 성능, 조건부 및 조정 가능한 생성, 교차 모달 검색, 다중 감각 융합 기능을 제공합니다.
대규모 언어 모델(LLM) 사전 학습 개선: Improving LLM Pretraining
LLM은 일부 Apple 서비스를 비롯한 다양한 프로덕션 애플리케이션에서 사용되며, 이러한 모델을 근본적으로 개선하면 업계 전반의 개발자와 사용자에게 상당한 영향을 미칠 수 있습니다. NeurIPS에서 Apple ML 연구원들이 발표할 연구에는 보다 효율적인 LLM 사전 학습을 위한 새로운 기술이 포함됩니다.
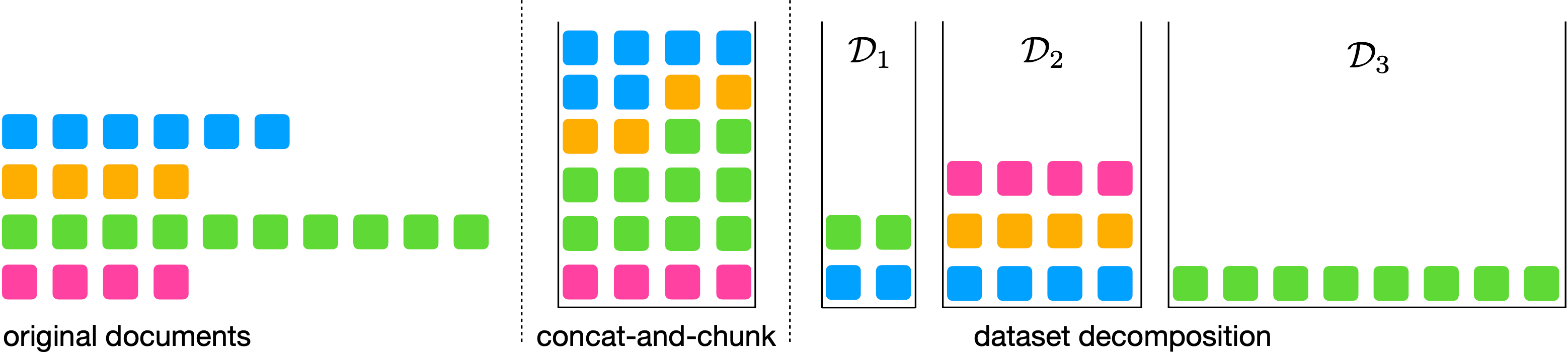
그림의 각 셀은 토큰을 나타냅니다. 왼쪽: 다양한 길이의 원본 문서. 가운데: 고정된 목표 길이를 가진 시퀀스를 형성하기 위한 연결 및 청크 기준선(여기서는 = 4). 오른쪽: D1, D2, D3 버킷을 사용한 데이터 세트 분해 방법.
LLM은 일반적으로 고정 길이의 토큰 시퀀스 데이터 세트로 훈련하는데, 이는 훈련 인프라가 제한된 시퀀스 길이만 지원하는 경우가 많기 때문입니다. 이를 생성하기 위해 다양한 길이의 문서를 결합한 다음 지정된 길이의 청크로 분할합니다. 이 접근 방식에서는 문서가 무작위로 결합되기 때문에 모델은 관련 문서의 컨텍스트를 사용하는 대신 관련 없는 문서의 컨텍스트를 사용하여 다음 토큰을 예측할 수 있습니다. 이는 학습 신호가 좋지 않을 뿐만 아니라 불필요한 계산을 소모합니다. Apple 연구원들은 다양한 길이의 문서를 포함하는 데이터 세트를 동일한 길이의 시퀀스를 가진 '버킷' 또는 하위 집합의 조합으로 분해한 다음, 훈련 시점에 모든 버킷에서 동시에 샘플링된 가변 시퀀스 길이와 배치 크기를 사용하는 새로운 방법으로 이 문제를 해결하는 데이터 세트 분해: 가변 시퀀스 길이를 가진 LLM 사전 학습에 대한 연구를 발표합니다. 이를 통해 긴 시퀀스, 스케일에 대한 효율적인 사전 학습이 가능합니다.
LLM의 추론 능력 탐구: Exploring LLMs’ Ability to Reason
LLM은 여러 작업에서 그 능력이 입증되었지만, 오늘날의 모델이 어느 정도까지 추론할 수 있는지는 여전히 중요한 미해결 연구 과제로 남아 있습니다. 이러한 모델의 현재 기능과 한계를 이해하면 연구 커뮤니티가 지속적으로 개선할 수 있을 뿐만 아니라 개발자가 프로덕션 애플리케이션에서 LLM을 보다 지능적으로 활용할 수 있습니다.
NeurIPS에서 Apple 연구원들은 "How Far Can Transformers Reason? The Globality Barrier and Inductive Scratchpad"라는 논문에서 트랜스포머 기반 모델이 학습된 개념과 추론을 결합해야 하는 '글로벌 추론'이 필요한 작업에서 어려움을 겪는 이유를 조사합니다. 이 논문은 이러한 모델이 높은 전역성을 가진 분포를 효율적으로 학습할 수 없기 때문에 긴 연쇄(예: a⇒b 및 b⇒c에서 a⇒c를 추론)를 구성할 수 없다는 것을 보여주며, 트랜스포머가 이러한 한계를 극복할 수 있는 “귀납적 스크래치패드(Inductive Scratchpad)”라는 아이디어를 소개합니다.
자가 지도 학습(SSL) 이해: Understanding Self-Supervised Learning (SSL)
효과적이고 효율적으로 표현을 학습하는 것은 딥러닝의 기본 목표이며, 이러한 표현은 많은 다운스트림 작업에 사용될 수 있기 때문입니다. 다양한 접근 방식이 표현을 학습하는 방식에 대한 분야의 이해를 발전시킴으로써 이 분야의 연구는 궁극적으로 이러한 다운스트림 작업 전반의 성능 향상으로 이어질 수 있습니다.
NeurIPS에서 Apple 연구원들은 [JEPA가 노이즈가 많은 기능을 피하는 방법]을 발표할 예정입니다: 심층 선형 자가 증류 네트워크의 암묵적 편향](How JEPA Avoids Noisy Features: The Implicit Bias of Deep Linear Self Distillation Networks - Apple Machine Learning Research)을 발표하여 두 가지 주요 SSL 패러다임으로 표현을 학습하는 방법의 차이점을 살펴볼 예정입니다: 마스크드 자동 인코더(MAE)와 공동 임베딩 예측 아키텍처(JEPA)입니다. 이 연구는 두 접근 방식이 유사한 표현을 학습하는 단순화된 선형 환경에서 JEPA가 '영향력이 큰' 특징(즉, 회귀 계수가 높은 특징)을 학습하도록 편향되어 있다는 것을 보여주며, 현장에서 경험적으로 관찰되는 현상에 대한 공식적인 설명을 통해 JEPA가 세밀한 픽셀 정보보다 추상적인 특징을 우선시하는 것으로 보인다는 사실을 보여줍니다.
MLX 및 MobileCLIP 데모
그 외, Apple은 NeurIPS 2024 전시장에서 MLX 프레임워크 및 MobileCLIP 데모를 진행하였습니다:
MLX 프레임워크는 Apple 실리콘에서 대규모 모델 학습 및 추론을 지원하는 오픈소스 프레임워크로, iPhone, iPad, Mac에서 대규모 LLM과 이미지 생성 모델의 성능을 시연하였습니다.
https://github.com/ml-explore/mlx
MobileCLIP은 CNN과 Transformer의 하이브리드 구조를 사용한 모바일 친화적 이미지-텍스트 모델로, iPhone에서 실시간 장면 분류를 시연하였습니다.
 NeurIPS 2024에 Apple이 공개한 연구 소개 블로그
NeurIPS 2024에 Apple이 공개한 연구 소개 블로그
더 읽어보기
- Apple Intelligence: Apple의 On-Device 및 Private Cloud에서의 Foundation Model 소개
- CatLIP: CLIP의 대조 학습(CL) 대비 2.7배 빠른 범주 학습(Categorical Learning) 기법에 대한 연구 (feat. Apple)
- Talaria: Apple의 Apple Intelligence를 위한 On-Device 모델 성능 모니터링 및 최적화 도구
- Apple, 스마트폰에서 동작하는 270M ~ 3B 규모의 작은 언어모델 OpenELM 패밀리 공개
- Apple, 멀티모달 LLM 'MM1'에 대한 연구 결과 발표 (모델 공개X)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()