
NextFlow 연구 배경: 통합 모델의 딜레마와 NextFlow의 등장
인공지능 연구의 궁극적인 지향점 중 하나는 텍스트, 이미지, 비디오 등 다양한 모달리티를 사람처럼 자유자재로 이해하고 생성할 수 있는 통합 시스템, 즉 인공 일반 지능(AGI)을 구축하는 것입니다. 현재 우리는 텍스트 추론 영역에서는 거대 언어 모델(LLM)이, 시각적 생성 영역에서는 디퓨전(Diffusion) 모델이 각자의 영역에서 최고 수준의 성능을 보여주는 시대를 살고 있습니다. 하지만 이 두 가지 강력한 패러다임은 근본적으로 서로 다른 구조와 표현 방식을 가지고 있어, 이를 하나의 시스템으로 통합하는 데에는 큰 '마찰(Friction)'이 존재해 왔습니다. 예를 들어, Transfusion이나 Bagel과 같은 하이브리드 모델들이 등장하여 가능성을 보여주었지만, 서로 다른 인코딩 방식을 사용함으로써 발생하는 간극과 재인코딩(Re-encoding) 오버헤드는 여전히 해결해야 할 과제로 남아 있었습니다.
순수하게 텍스트와 이미지를 하나의 시퀀스로 처리하려는 자기회귀(Autoregressive, AR) 방식의 시도들, 예컨대 Chameleon이나 EMU3 같은 모델들도 등장했습니다. 하지만 이들 역시 실용적인 배포를 어렵게 만드는 치명적인 병목 현상에 직면했습니다. 가장 큰 문제는 바로 '추론 속도'였습니다. 이미지를 텍스트처럼 왼쪽 상단에서 오른쪽 하단으로 픽셀 단위로 예측해 나가는 래스터 스캔(Raster-scan) 방식은 해상도가 높아질수록 처리해야 할 시퀀스 길이가 기하급수적으로 늘어납니다. 실제로 1024 \times 1024 해상도의 고화질 이미지를 생성하기 위해 기존 AR 모델들은 10분 이상의 시간이 소요되기도 하여, 실시간 상호작용이 필요한 서비스에 적용하기에는 무리가 있었습니다. 또한, 픽셀 복원력에만 집중한 기존의 VQ-VAE 토크나이저는 생성된 토큰이 언어 모델이 이해할 수 있는 고차원적인 의미(Semantic)를 충분히 담지 못해, 복잡한 추론이나 멀티모달 이해 능력에서 한계를 드러냈습니다.


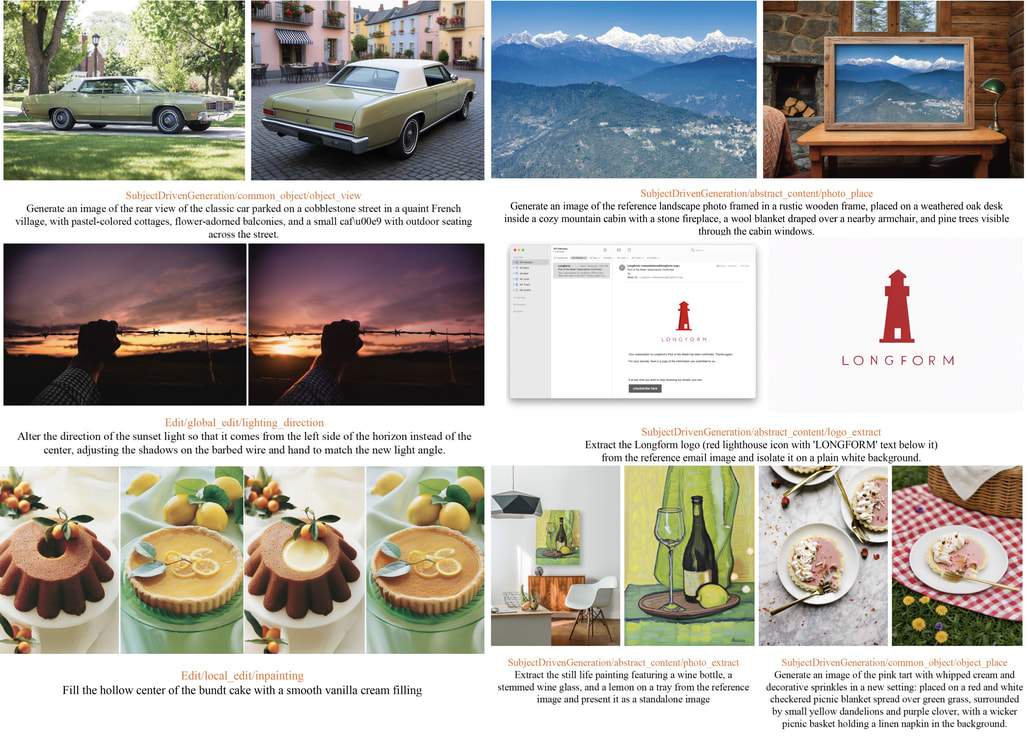


이러한 배경에서 등장한 NextFlow는 기존의 패러다임을 근본적으로 재설계하여 이러한 문제들을 정면으로 돌파합니다. NextFlow는 6조(6T) 개에 달하는 방대한 텍스트-이미지 토큰으로 학습된 단일 디코더 전용(Decoder-only) 트랜스포머 모델입니다. 이 모델의 가장 핵심적인 혁신은 이미지를 생성할 때 픽셀의 위치 순서가 아닌, 정보의 스케일(Scale) 순서로 예측한다는 점입니다. 이는 이미지의 거친 전체 구조(Coarse structure)를 먼저 잡아내고, 점차 세밀한 디테일(Fine-grained details)을 채워 나가는 계층적 접근 방식입니다. 이 방식을 통해 NextFlow는 1024 \times 1024 해상도의 이미지를 단 5초 만에 생성해 낼 수 있게 되었습니다. 이는 기존 래스터 스캔 방식 대비 수십 배, 동급의 디퓨전 모델 대비 6배 이상 빠른 놀라운 속도입니다. 또한, 의미론적 정보와 픽셀 수준의 정보를 정교하게 분리하면서도 통합하는 이중 코드북 토크나이저를 도입하여, 모델이 텍스트와 이미지 사이의 '의미적 간극'을 좁히고 진정한 의미의 멀티모달 이해와 생성을 가능하게 했습니다.
NextFlow 아키텍처: 효율성과 통합을 위한 정교한 설계
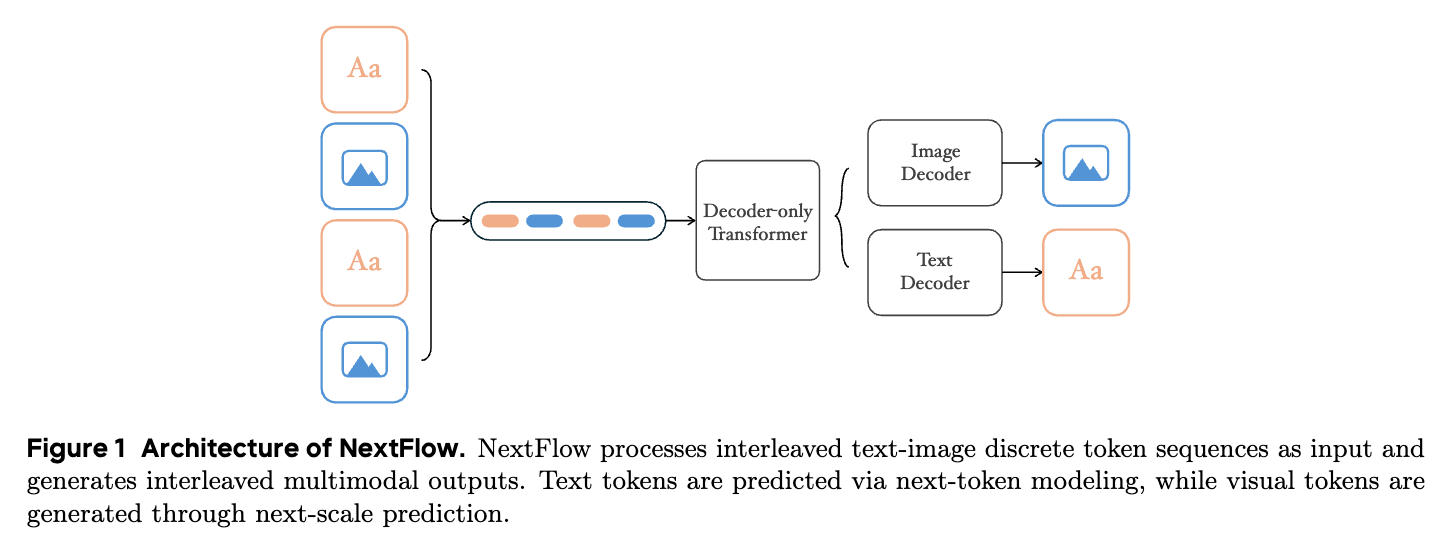
NextFlow의 아키텍처는 단순히 여러 모듈을 결합한 것이 아니라, 효율적인 통합을 위해 바닥부터 정교하게 설계되었습니다. 복잡성을 최소화하면서도 성능을 극대화하기 위해 토크나이저부터 예측 메커니즘까지 모든 구성 요소가 유기적으로 연결되어 있습니다.
이중 코드북 토크나이저 (Dual-Codebook Tokenizer)
일반적인 VQ-VAE나 VQGAN은 이미지를 압축하고 다시 복원하는 과정에서 픽셀 수준의 정확도, 즉 재구성 충실도(Reconstruction Fidelity)에 집중합니다. 하지만 이렇게 만들어진 이산화된(Discrete) 토큰들은 언어 모델이 처리하기에 적합한 고차원적인 의미 정보를 충분히 담지 못하는 경우가 많습니다. NextFlow는 이 문제를 해결하기 위해 TokenFlow 연구에서 제안된 이중 코드북(Dual-Codebook) 구조를 채택하고 발전시켰습니다. 이 구조는 크게 '의미(Semantic) 인코더'와 '픽셀(Pixel) 인코더'라는 두 개의 경로로 나뉩니다.
의미 인코더 (Semantic Encoder) 는 SigLIP2-SO400M-NaFlex를 사용하여 이미지의 고차원적인 의미를 추출합니다. 이 모델은 다양한 해상도와 종횡비를 처리하는 데 특화되어 있어, 이미지를 찌그러뜨리지 않고 있는 그대로 이해합니다. 픽셀 인코더 (Pixel Encoder) 는 CNN 기반으로 이미지의 시각적 디테일과 텍스처 정보를 처리합니다. 즉, 의미 인코더는 이미지의 내용을 개념적으로 이해하고, 픽셀 인코더는 시각적인 세부 사항을 처리합니다.
이렇게 추출한 두 정보는 따로 활용하지 않고, 공유된 매핑 메커니즘을 통해 하나의 토큰으로 정렬 및 통합됩니다. 따라서 토큰화 과정에서 단순히 그림을 똑같이 그리는 것뿐만 아니라, 그 그림이 무엇을 의미하는지까지 고려하여 코드북에서 가장 적절한 벡터를 찾도록 학습됩니다. 즉, 토큰화 과정에서 단순히 픽셀값만 맞추는 게 아니라, "이것은 강아지다"라는 의미적 정보까지 고려하여 코드북에서 벡터를 찾도록 학습됩니다. 또한, **완전 동적 공간 처리(Fully Dynamic Spatial Processing)**를 구현하여, 입력 이미지를 고정된 크기로 자르지 않고 원본 비율 그대로 처리할 수 있게 했습니다.
특히, 이번 연구에서는 다양한 해상도와 종횡비(Aspect Ratio)를 유연하게 처리하기 위해 의미론적 인코더의 초기화 모델을 기존의 SigLIP-SO400M에서 SigLIP2-SO400M-NaFlex로 업그레이드했습니다. 이 모델은 가변적인 입력 크기를 처리하는 데 특화되어 있어, 이미지를 강제로 정사각형으로 자르거나 찌그러뜨리지 않고 원본 비율 그대로 처리할 수 있게 해줍니다.
연구진들은 여기에 CNN 기반의 픽셀 브랜치를 결합하여 완전 동적 공간 처리(Fully Dynamic Spatial Processing) 기법을 구현했습니다. 이는 모델이 학습 단계에서부터 다양한 크기의 이미지를 있는 그대로 받아들일 수 있게 하여, 실제 사용 환경에서의 유연성을 크게 높여줍니다. 또한, 양자화 품질을 높이기 위해 다중 스케일 VQ(Multi-scale VQ) 기법을 사용하여, 아주 작은 디테일부터 전체적인 색감까지 놓치지 않도록 설계되었습니다.
디코더 전용 트랜스포머와 Next-Scale 예측 패러다임
NextFlow의 두뇌에 해당하는 메인 모델은 Qwen2.5-VL-7B를 기반으로 초기화된 디코더 전용 트랜스포머입니다. 이 모델은 텍스트와 이미지를 처리하는 방식에서 흥미로운 차별점을 둡니다. 텍스트 데이터에 대해서는 우리가 잘 아는 '다음 토큰(Next-token)' 예측 방식을 그대로 사용합니다. 하지만 이미지 데이터에 대해서는 픽셀 순서가 아닌 다음 스케일(Next-scale) 을 예측하는 방식을 적용합니다.
이러한 방식은 VAR(Visual Auto-Regressive Modeling) 연구에서 영감을 받은 것으로, 이미지를 1 \times 1 의 아주 작은 스케일에서 시작하여 2 \times 2, 4 \times 4 등으로 점진적으로 해상도를 높여가며 토큰 맵을 예측하는 방식입니다. 마치 화가가 그림을 그릴 때 전체적인 구도를 먼저 잡고 나서 세부 묘사를 하는 것과 유사합니다.
연구진은 또한 모델 구조를 단순화하기 위해 텍스트와 이미지를 위한 출력 헤드(Output Head)를 통합할지 분리할지를 두고 깊이 고민했습니다. 실험 결과, 단일 헤드를 사용하여 두 모달리티를 모두 예측하는 것이 구조적으로 훨씬 간단하면서도 성능 저하가 없다는 것을 확인했습니다. 이에 따라 NextFlow는 통합된 단일 출력 헤드를 채택하였으며, 모델은 교차 엔트로피(Cross-entropy) 손실 함수를 통해 텍스트와 이미지 코드북의 인덱스를 동시에 예측하도록 학습됩니다. 시각적 코드북의 임베딩은 앞서 설명한 토크나이저의 코드북 임베딩으로 초기화되어, 학습 초기부터 안정적인 성능을 낼 수 있도록 돕습니다.
위치 인코딩과 스케일 재조정 (3D RoPE & Scale Reweight)
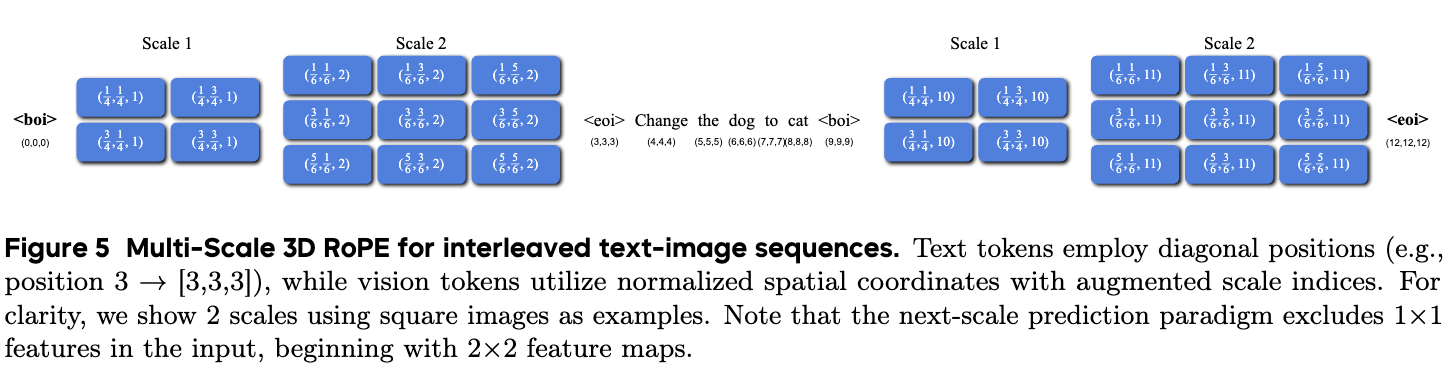
텍스트와 다중 스케일의 이미지 토큰이 뒤섞여 입력되는 상황에서, 모델이 각 토큰의 위치와 역할을 정확히 인지하는 것은 매우 중요합니다. 이를 위해 NextFlow는 Multiscale 3D RoPE (Rotary Positional Embedding) 라는 새로운 위치 인코딩 방식을 도입했습니다.
텍스트 토큰의 경우 기존처럼 (t, t, t) 와 같이 모든 차원에 동일한 시퀀스 위치 정보를 복제하여 사용합니다. 반면, 이미지 토큰은 (x, y, scale) 형태의 3차원 좌표계를 가집니다. 여기서 x 와 y 는 공간적 위치를, scale 은 해당 토큰이 어느 해상도 단계에 속하는지를 나타냅니다. 특히 공간 좌표는 [0, C] 범위로 정규화된 값을 사용하여, 16 \times 16 그리드든 32 \times 32 그리드든 동일한 상대적 위치라면 같은 좌표 공간을 공유하게 설계했습니다. 이러한 방식은 추후 더 높은 해상도로 파인튜닝할 때 모델이 보지 못한 위치 값으로 인해 겪을 수 있는 외삽(Extrapolation) 문제를 원천적으로 방지하기 위한 장치입니다.
그 외에도 '다음 스케일 예측' 방식의 특성상 발생할 수 있는 학습 불균형 문제를 해결하기 위해 스케일 재가중치(Scale-Aware Loss Reweighting) 전략을 도입했습니다. 저해상도 단계(Coarse scale)는 토큰 수가 매우 적지만 이미지의 전체적인 구조를 결정하는 결정적인 역할을 합니다. 반면 고해상도 단계(Fine scale)는 토큰 수가 압도적으로 많습니다. 만약, 모든 토큰에 동일한 가중치를 부여하면, 모델은 수가 많은 고해상도 토큰을 맞추는 데에만 집중하게 되어 정작 중요한 전체 구도를 엉망으로 만들 수 있습니다.
연구진은 이러한 문제를 방지하기 위해 각 스케일의 손실 값에 해상도 면적에 반비례하는 가중치(k_s = 1/(h_s \times w_s)^\alpha)를 부여했습니다. 실험을 통해 \alpha=0.9 라는 최적의 값을 찾아내었으며, 이 간단한 수식 하나가 학습의 안정성과 생성된 이미지의 구조적 완성도를 크게 높여주었습니다.
고해상도 디테일을 위한 선택적 디퓨전 디코더
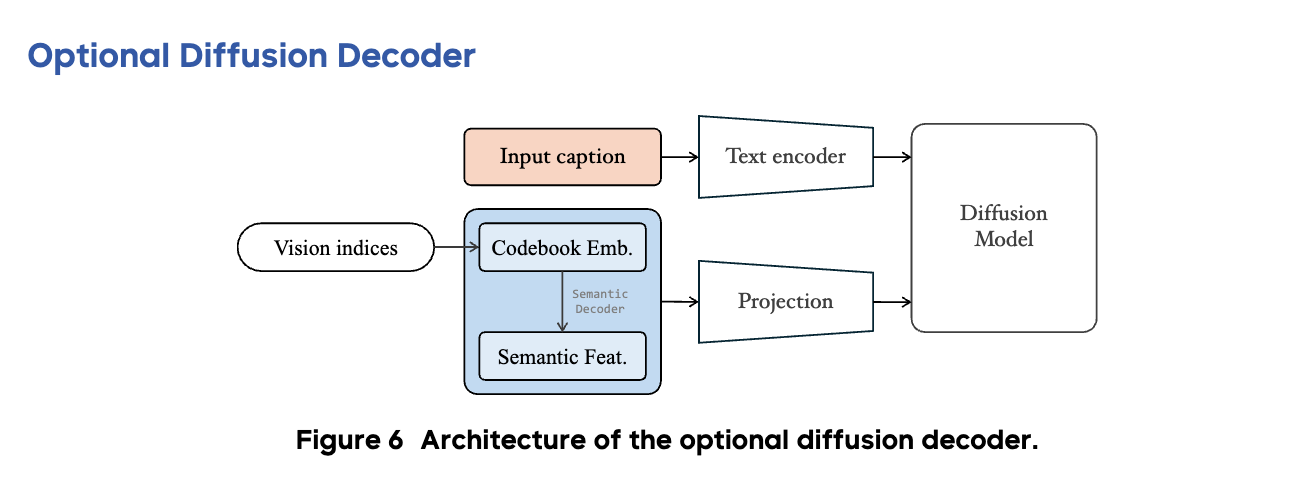
NextFlow는 순수 자기회귀 모델만으로도 뛰어난 품질의 이미지를 생성하지만, 이산화된 토큰(Discrete Token)을 사용하는 방식의 물리적 한계로 인해 아주 미세한 고주파(High-frequency) 정보가 손실될 수 있습니다. 예를 들어, 군중 속의 아주 작은 얼굴이나 깨알 같은 텍스트의 선명도가 다소 떨어질 수 있습니다. 이를 보완하기 위해 NextFlow는 선택적 디퓨전 디코더(Optional Diffusion Decoder) 를 추가적인 모듈로 제공합니다. 이는 필수적인 생성 단계라기보다는, AR 모델이 생성한 결과를 더욱 완벽하게 다듬어주는 정제(Refinement) 도구에 가깝습니다.
이러한 디퓨전 디코더는 AR 모델이 예측한 시각적 인덱스로부터 의미적 임베딩, 픽셀 임베딩, 그리고 디코딩된 의미적 특징(Semantic feature)을 추출하고, 이를 조건(Condition)으로 받아 이미지를 생성합니다. 즉, AR 모델이 "여기에 강아지가 있고 저기에 나무가 있다"는 구조와 내용을 확실하게 잡아주면, 디퓨전 모델이 그 위에 사실적인 털의 질감이나 잎사귀의 디테일을 덧입히는 방식입니다. 연구진은 1B, 12B, 18B 등 다양한 크기의 디퓨전 모델을 실험했으며, 텍스트 캡션 정보도 함께 입력받도록 하여 텍스트가 묘사하는 세부 사항을 놓치지 않도록 했습니다.
다만, 디퓨전 과정의 확률적 특성으로 인해 원본의 구조가 미세하게 변형될 수 있는 트레이드-오프(trade-offs)가 존재하므로, 논문의 주된 실험 결과들은 대부분 이 디퓨전 디코더를 사용하지 않은 순수 AR 모델의 성능임을 강조하고 있습니다.
NextFlow 학습 오디세이: 6조 토큰 학습의 난관과 엔지니어링 해결책
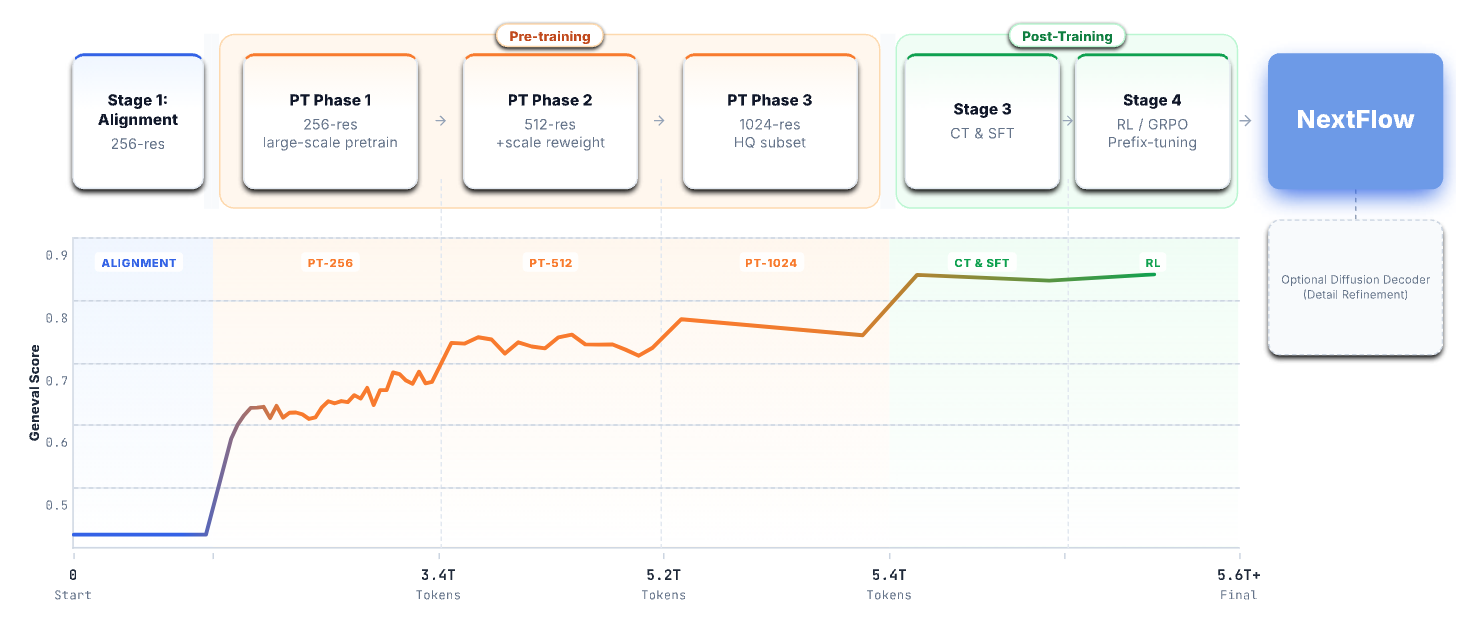
NextFlow 연구진들은 "실험의 진행은 결코 선형적이지 않다"라고 솔직하게 고백하며, 6조 토큰이라는 거대한 데이터를 학습시키는 과정에서 겪은 수많은 난관과 그 해결책을 학습 오디세이(Training Odyssey) 라는 챕터를 통해 상세히 공유합니다. 이 섹션에는 대규모 모델을 다루는 엔지니어들에게 실질적인 도움이 될 수 있는 여러가지 노하우들로 가득 차 있습니다.
토크나이저 학습의 3단계 전략과 정렬(Alignment)
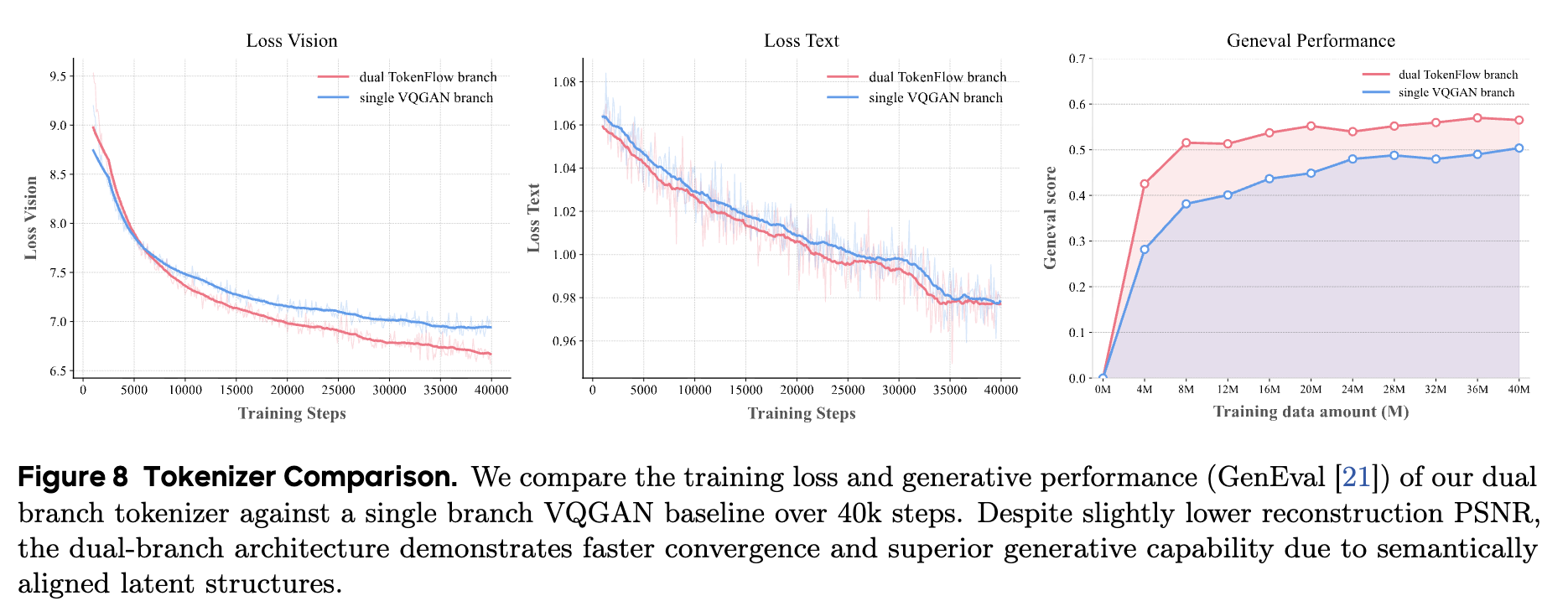
초기 실험에서 연구진은 토크나이저를 학습시킬 때, 의미 인코더는 이미 학습된 모델을 고정해서 사용하고 픽셀 인코더만 처음부터 학습(Scratch)시키는 방식을 시도했습니다. 하지만 이 경우 학습 초기에 강력한 의미적 특징(Semantic feature)이 최적화 과정을 지배해 버려서, 정작 시각적 재구성(Reconstruction) 능력이 충분히 학습되지 않는 문제가 발생했습니다. 이를 해결하기 위해 연구진은 3단계 학습 전략을 수립했습니다:
첫째, 픽셀 브랜치만 독립적으로 학습시켜 기본적인 이미지 복원 능력을 먼저 확보합니다.
둘째, 의미 인코더와 픽셀 인코더 등 모든 구성 요소를 결합하여 공동 학습(Joint Training)을 수행함으로써 두 정보 간의 균형을 맞춥니다.
셋째, 픽셀 디코더의 용량을 두 배로 늘리고 이를 별도로 파인튜닝하여, 작은 얼굴이나 텍스트 같은 미세한 디테일의 복원력을 극한으로 끌어올립니다.
또한, 학습 중 무작위로 VAR 스케일의 50%를 드롭(Drop)하는 기법을 사용하여, 코드북의 수치적 분포를 견고하게 만들고 재구성 품질을 향상했습니다.
고해상도 학습의 불안정성 해결: 스케일 재가중치(Scale Reweight)
NextFlow는 256 \rightarrow 512 \rightarrow 1024 해상도로 점진적으로 해상도를 높여가는 커리큘럼 학습을 진행했습니다. 그런데 256 해상도에서 512 해상도로 넘어가는 순간, 이미지의 품질이 오히려 떨어지고 기하학적인 아티팩트가 발생하는 심각한 문제가 생겼습니다. 원인을 분석해 보니, 해상도가 높아지면서 추가되는 토큰의 개수가 약 3,000개에 달할 정도로 급증했고, 모델이 이 많은 수의 고해상도 토큰을 맞추는 데에만 과도하게 집중한 나머지, 정작 이미지의 뼈대를 형성하는 저해상도 토큰에 대한 학습을 소홀히 하게 된 것이었습니다.
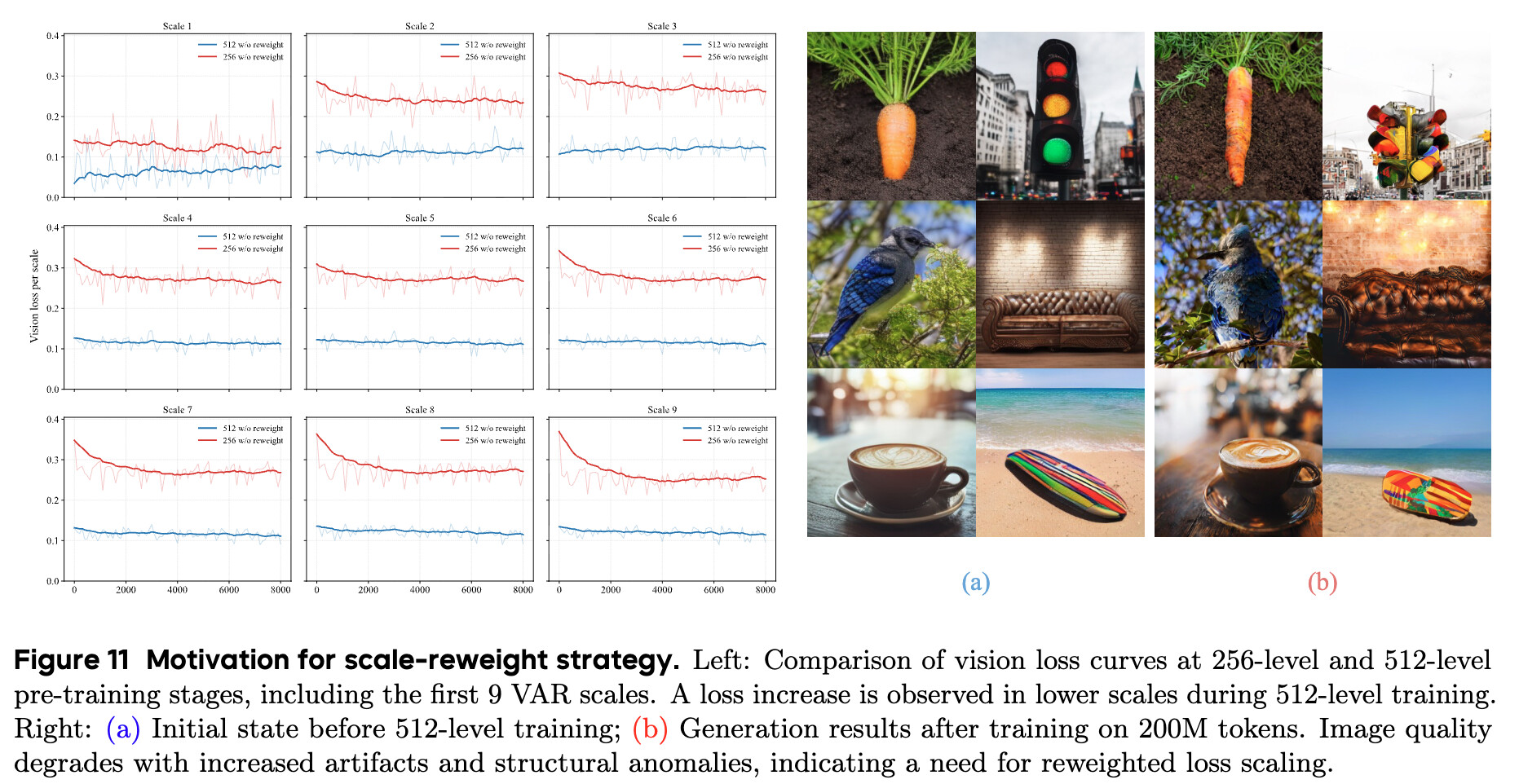
이 문제를 해결하기 위해 NextFlow 연구진들은 앞서 언급한 스케일 재가중치(Scale-Aware Loss Reweighting) 전략을 도입했습니다. 각 스케일의 손실 함수에 해상도에 반비례하는 가중치를 적용함으로써, 토큰 수가 적은 초기 스케일의 중요도를 강제로 높여주었습니다. 이 조치 덕분에 모델은 고해상도 학습 단계에서도 전체적인 구조를 잃지 않고 안정적으로 학습을 이어나갈 수 있게 되었습니다.
자기회귀 모델의 한계 극복: 자가 수정(Self-Correction)과 잔차 특징
자기회귀 모델은 학습할 때는 정답(Ground-truth) 토큰을 보며 다음 토큰을 예측하지만, 실제 추론(Inference) 시에는 자신이 예측한 토큰을 기반으로 다음을 예측해야 합니다. 이를 노출 편향(Exposure Bias) 문제라고 하며, 초반의 작은 실수가 뒤로 갈수록 눈덩이처럼 불어나 이미지가 망가지는 원인이 됩니다.
이러한 노출 편향 문제를 막기 위해 NextFlow는 학습 중에 자가 수정(Self-Correction) 메커니즘을 도입했습니다. 즉, 인코딩 시 항상 가장 가까운 토큰(Top-1)만을 선택하는 대신, 일정 확률로 Top-k 토큰 중에서 무작위로 샘플링하여 일부러 약간의 노이즈를 섞어주고, 모델이 이 차선의 선택을 스스로 바로잡아 정답을 예측하도록 훈련시킨 것입니다.
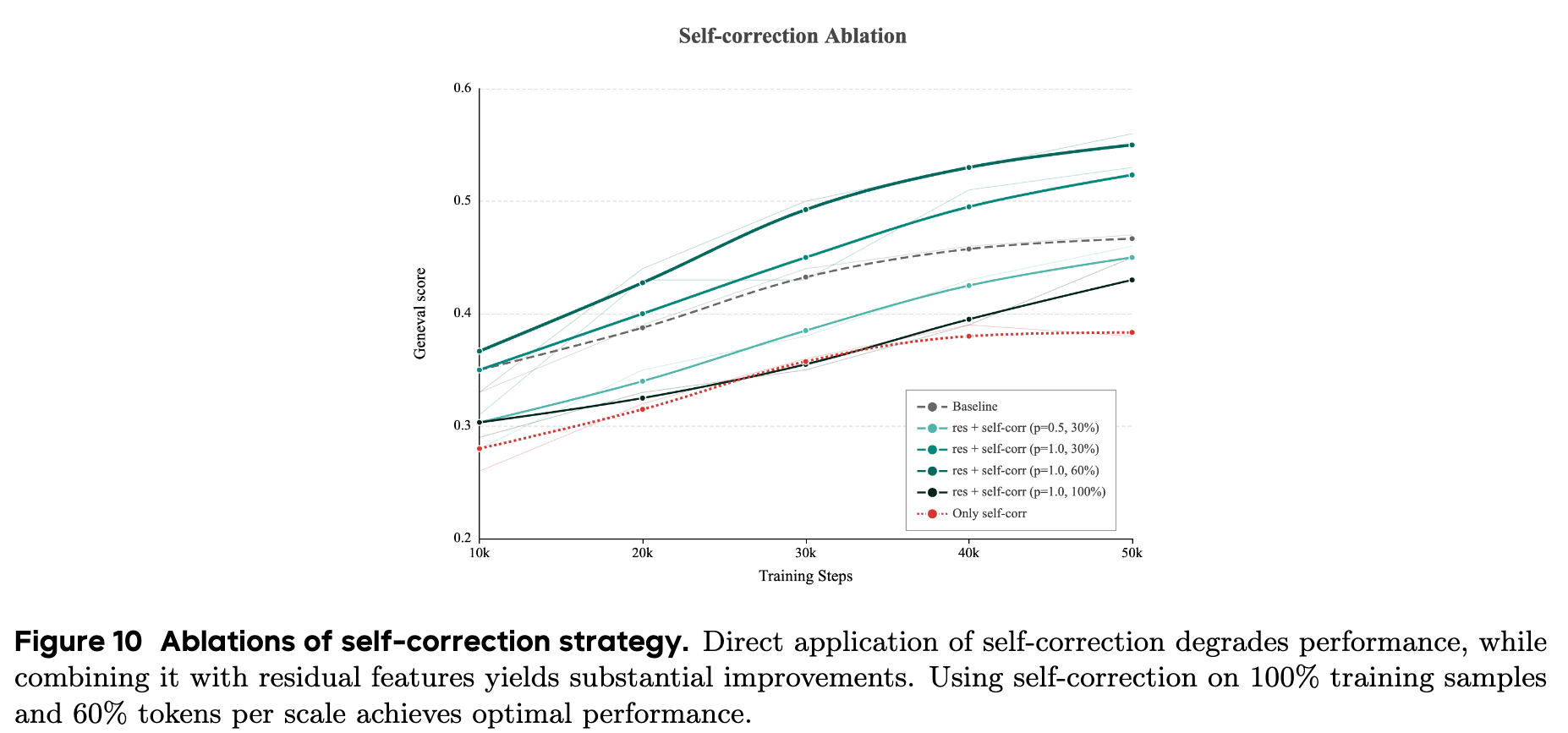
여기서 흥미로운 발견은, 이전 스케일의 특징들을 누적(Accumulate)해서 사용하는 기존 방식 대신, 각 스케일의 특징을 독립적으로 사용하는 잔차(Residual) 특징 방식이 훨씬 효과적이었다는 점입니다. 위 그래프에서 단순히 자가 수정을 적용하면 성능이 저하되지만(붉은 점선, Only self-corr), 잔차 특징(Residual features)과 결합(res + self-corr)하면 성능이 크게 향상됩니다. 실험 결과, 가장 좋은 성능은 100% 학습 샘플에 대해 스케일당 60%의 토큰에 자가 수정을 적용했을 때(검은 실선, res + self-corr (p=1.0, 100%)) 달성되었습니다.
이러한 자가 수정 및 잔차 특징을 활용한 방식은 시각적 입력 공간의 복잡도를 낮추어 텍스트 토큰과의 정합성을 높이는 데 크게 기여했습니다.
강화 학습의 혁신: 프리픽스 튜닝(Prefix-tuning) GRPO
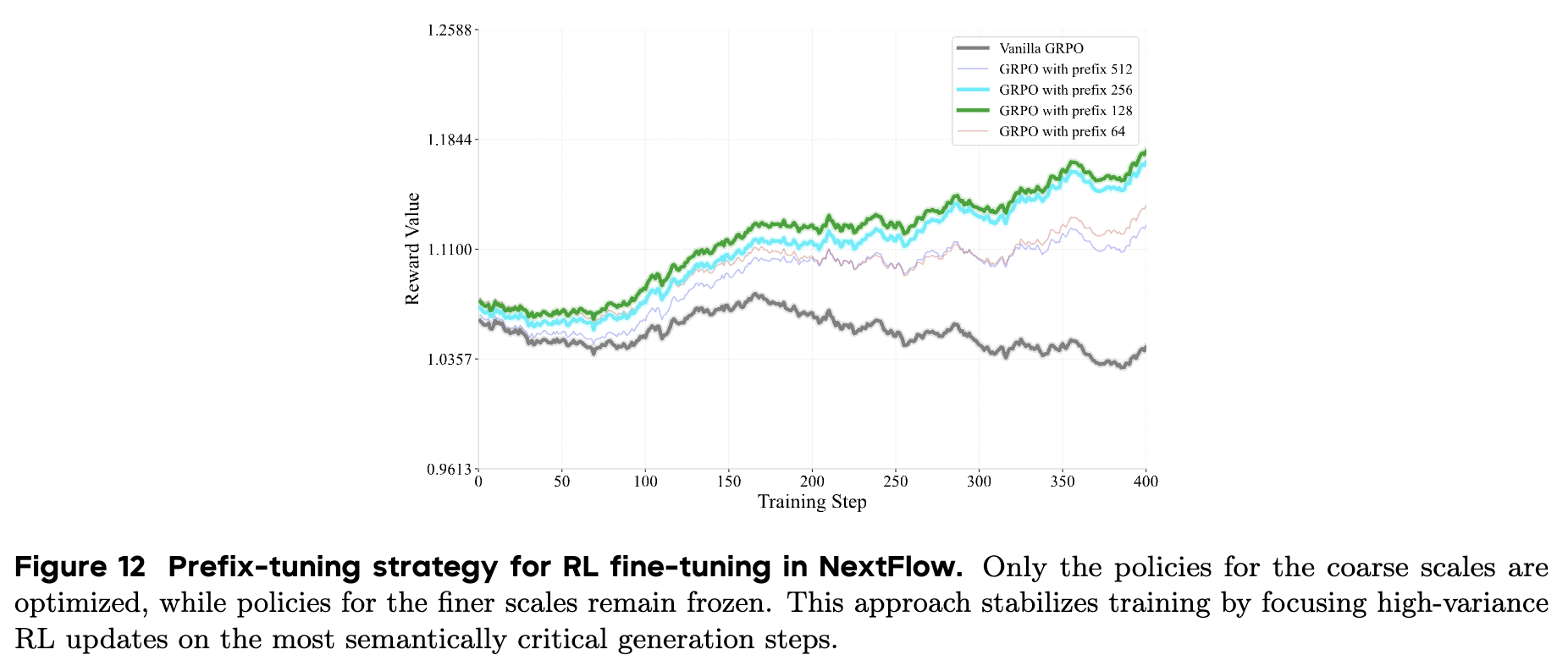
NextFlow는 순수 AR 모델이기 때문에 LLM에서 널리 쓰이는 강화 학습(RL) 기법을 적용할 수 있다는 장점이 있습니다. 연구진은 GRPO (Group Reward Policy Optimization) 알고리즘을 채택했습니다. 하지만 이미지 생성은 다단계(Multi-step) 프로세스이기 때문에 일반적인 RL을 그대로 적용하기 까다로웠습니다. 특히 후반부의 미세 조정 단계에서 발생하는 높은 분산(Variance)이 학습 전체를 불안정하게 만들었습니다.
이 난관을 타개하기 위해 NextFlow 연구진은 프리픽스 튜닝(Prefix-tuning) 이라는 새로운 전략을 제안했습니다. 이미지의 전체적인 구조와 의미는 생성 초반부의 저해상도 스케일(Coarse scales)에서 대부분 결정됩니다. 따라서 RL 업데이트를 전체 스케일에 적용하는 대신, 초반 m 개의 스케일(Prefix)에만 집중하고 나머지 후반부 스케일은 고정(Freeze)하는 방식을 택했습니다.
이는 마치 사람이 그림을 배울 때, 세밀한 붓 터치보다는 전체적인 구도를 잡는 법에 집중적으로 피드백을 주는 것과 같습니다. 이러한 프리픽스 튜닝 GRPO 전략은 학습의 불필요한 노이즈를 줄이고 수렴 속도를 높였으며, 결과적으로 모델이 사용자의 프롬프트 의도(Prompt alignment)를 더 잘 따르면서도 기존의 생성 품질을 해치지 않도록 만들었습니다.
NextFlow의 데이터 및 인프라: 효율적인 학습을 위한 최적화
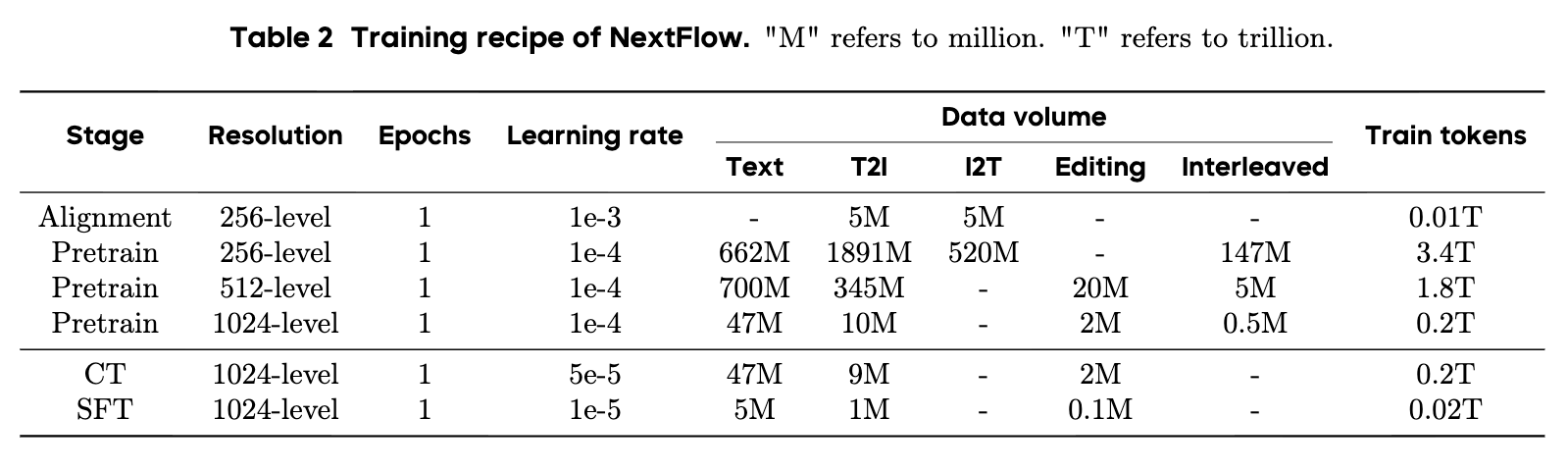
NextFlow의 압도적인 성능 뒤에는 정교하게 설계된 데이터 파이프라인과 이를 뒷받침하는 효율적인 인프라가 존재합니다. 6조 토큰이라는 방대한 데이터를 처리하기 위해 연구진은 다양한 최적화 기법을 동원했습니다.
멀티모달 데이터 파이프라인과 비디오 데이터 활용
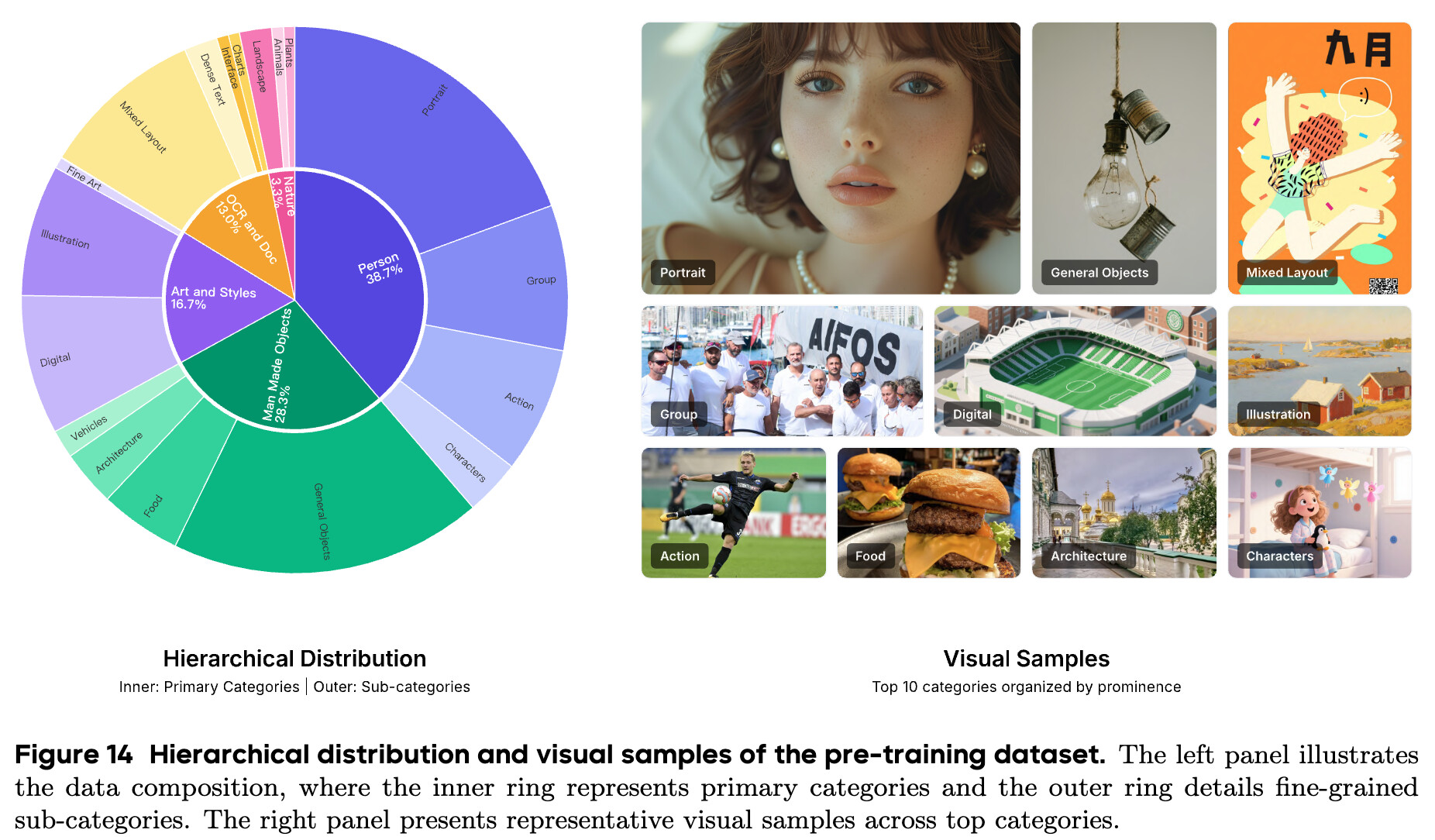
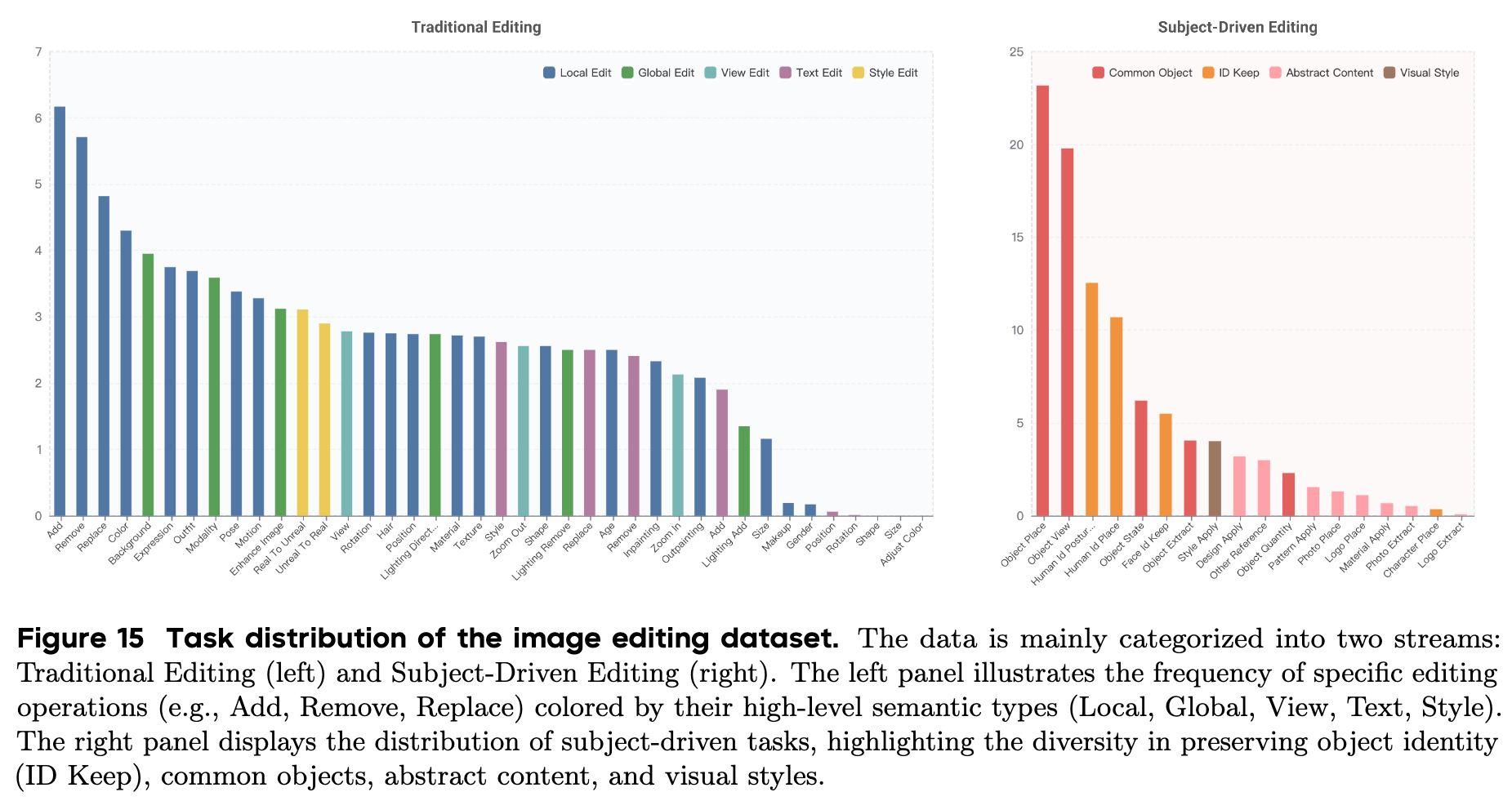
학습 데이터는 텍스트, 이미지-텍스트 쌍, 인터리브(Interleaved) 데이터 등 총 6조(6T) 토큰에 달합니다. 단순히 양만 늘린 것이 아니라 질적인 다양성도 확보했습니다. 시각적 이해(Understanding) 능력을 키우기 위해 문서 이미지, 차트, 표 등이 포함된 텍스트가 풍부한 이미지를 추가하여 OCR 능력을 배양했고, 이미지 생성(Generation)을 위해서는 10억 장 규모의 고품질 이미지 데이터셋을 구축했습니다. 특히 모델의 편집(Editing) 능력을 향상하기 위해, 인터넷상에 존재하는 유사한 이미지 쌍들을 VLM으로 분석하여 자동으로 구축한 주체 중심(Subject-driven) 생성 데이터를 대거 투입했습니다.
또한, 이미지와 텍스트가 번갈아 나오는 인터리브 생성 능력을 위해, 비디오 데이터를 활용했습니다. 비디오 클립에서 프레임을 추출하고, VLM을 이용해 그 사이를 이어주는 연결 텍스트(Transition text)를 생성함으로써, 비디오를 마치 긴 호흡의 그림 동화책처럼 변환하여 학습에 활용했습니다. 이는 모델이 이미지 간의 맥락과 서사를 이해하는 데 결정적인 역할을 했습니다.
인프라 최적화: 고정 계산 예산 패킹과 커널 융합

서로 다른 모달리티와 해상도의 데이터를 섞어서 학습하다 보면 GPU 간의 워크로드 불균형이 심각하게 발생합니다. 텍스트 데이터만 있는 배치는 순식간에 처리가 끝나지만, 고해상도 이미지가 포함된 배치는 연산 시간이 오래 걸리기 때문에, 전체 학습 속도가 가장 느린 GPU에 맞춰지는 비효율이 발생합니다.
NextFlow 팀은 고정 계산 예산 패킹(Fixed Computation Budget Packing) 전략을 사용하여 이 문제를 해결했습니다. 단순히 시퀀스 길이(Length)를 맞추는 것이 아니라, 각 샘플의 실제 연산량(TFLOPS)을 미리 계산하여 모든 GPU가 동일한 양의 연산을 수행하도록 데이터를 배분한 것입니다.
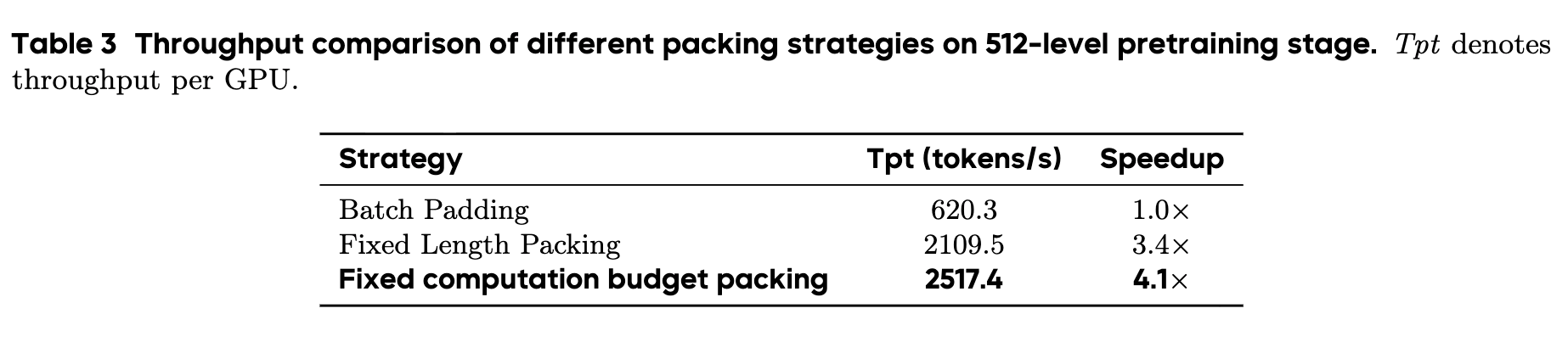
이를 통해 기존 방식 대비 학습 처리량(Throughput)을 4.1배나 향상하는 성과를 거두었습니다. 또한, 대규모 코드북으로 인한 메모리 병목을 해결하기 위해 FusedLinear Cross Entropy 커널을 적용하고, 학습 중 반복되는 이미지 인코딩 부하를 없애기 위해 모든 학습 이미지의 인덱스를 사전에 추출(Pre-extract)하여 저장해 두는 등 극한의 엔지니어링 최적화를 수행했습니다.
NextFlow 성능 평가 및 분석: SOTA를 향한 검증
그렇다면 이렇게 공들여 만든 NextFlow의 실제 성능은 어떨까요? 정량적, 정성적 평가 결과는 NextFlow가 단순한 연구용 모델을 넘어 실제 상용화 가능한 수준임을 보여줍니다.
이미지 생성 품질과 압도적인 추론 효율성
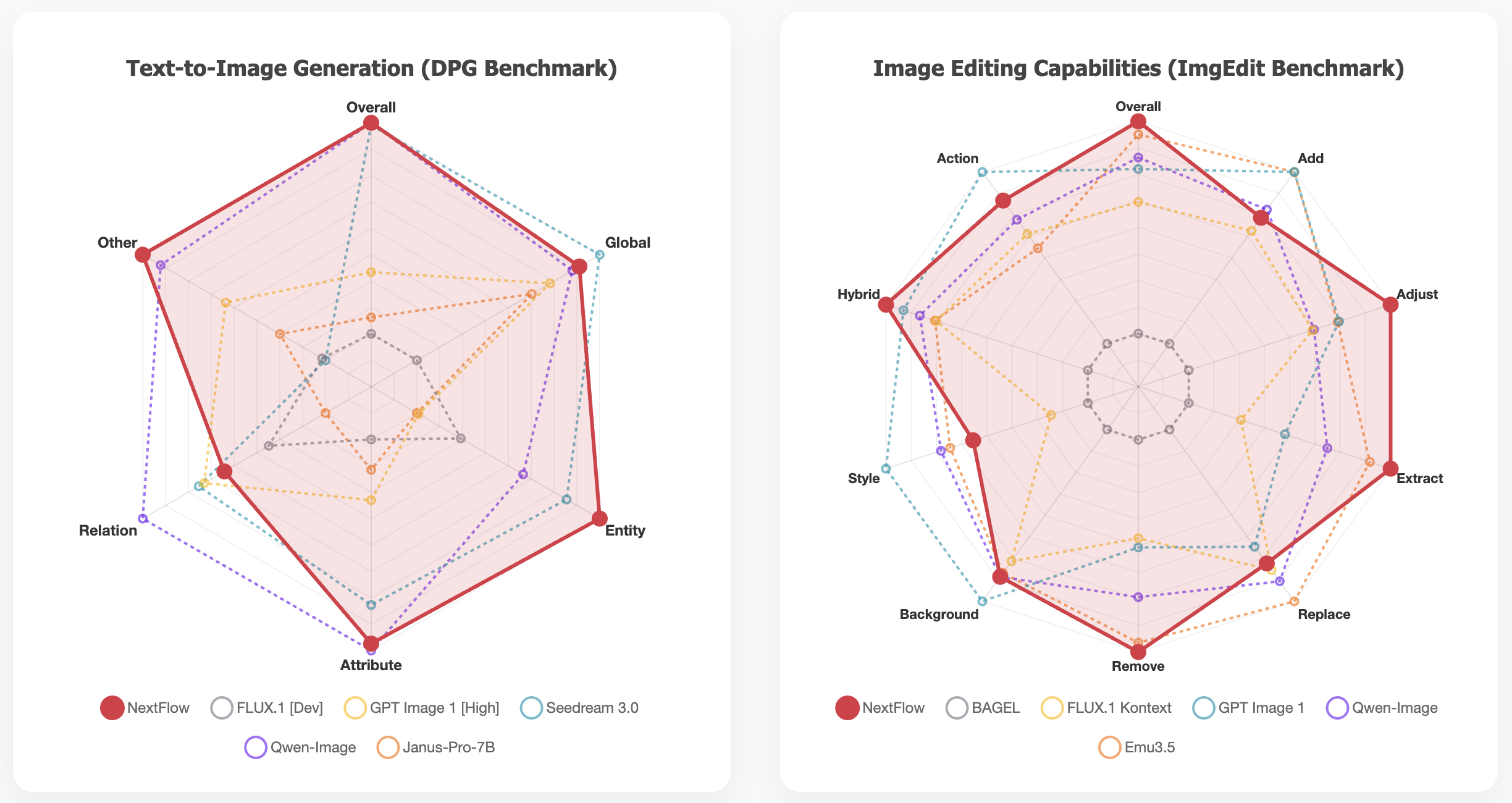
NextFlow는 텍스트-이미지 생성 벤치마크인 GenEval에서 0.84점, DPG에서 88.32점을 기록하며, FLUX.1-dev나 SD3-Medium 같은 최신 디퓨전 모델들을 능가하거나 대등한 성능을 보여주었습니다. 특히 강화 학습(RL) 튜닝을 거친 모델(NextFlow-RL)은 사용자의 지시를 따르는 프롬프트 준수(Prompt Following) 능력에서 탁월한 성과를 보였습니다.
무엇보다 놀라운 것은 효율성입니다. MMDiT(Multi-Modal Diffusion Transformer) 기반의 모델들과 비교했을 때, NextFlow는 동일한 해상도의 이미지를 생성하는 데 **약 6배 적은 FLOPs(부동소수점 연산)**만을 사용합니다. 이는 Next-scale 예측 방식 덕분에, 토큰 수가 적은 초반 스케일에서 적은 연산량으로 이미지의 뼈대를 빠르게 완성할 수 있기 때문입니다. 실제로 1024 \times 1024 해상도의 고화질 이미지를 생성하는 데 단 5초밖에 걸리지 않습니다. 기존의 래스터 스캔 방식 AR 모델들이 분 단위의 시간이 걸리던 것과 비교하면, 이는 실시간 서비스가 가능한 수준으로의 혁신적인 도약입니다.
새로운 벤치마크 EditCanvas와 편집 성능
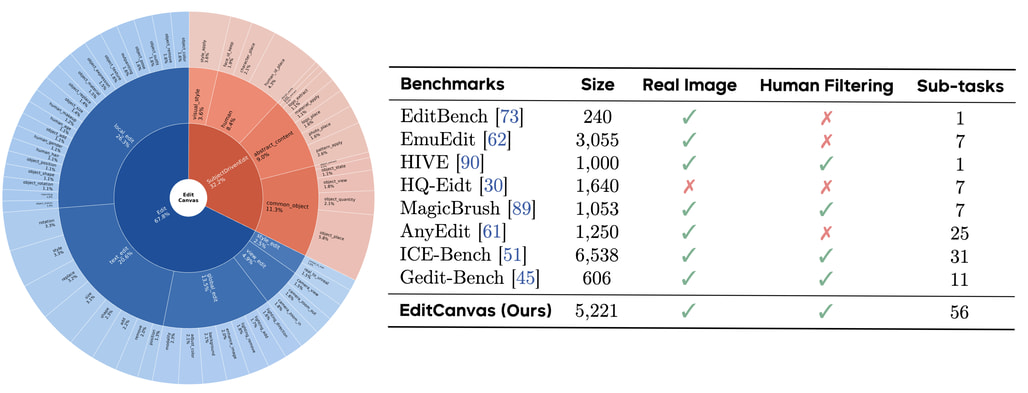
기존의 이미지 편집 벤치마크들은 대부분 단순한 작업에 치중되어 있거나, 데이터의 품질이 낮아 최신 모델들의 성능을 제대로 평가하기 어려웠습니다. 이에 연구진은 EditCanvas라는 새로운 벤치마크를 직접 구축하여 공개했습니다.
EditCanvas는 전통적인 편집 작업뿐만 아니라 주체 중심(Subject-driven) 생성까지 포괄하는 56개의 세부 태스크로 구성되어 있으며, 5,000개 이상의 고품질 샘플을 포함합니다. 이 엄격한 벤치마크에서 NextFlow는 객체 추가/제거, 배경 변경, 스타일 변환 등 다양한 작업에서 기존 모델들을 압도하는 성능을 보여주었습니다.
특히 텍스트와 이미지가 번갈아 나오는 인터리브 생성에서도 문맥을 유지하며 일관성 있는 이미지를 만들어내는 능력을 입증했습니다. 이는 NextFlow가 단순한 생성 모델을 넘어, 복합적인 멀티모달 작업을 수행할 수 있는 강력한 도구임을 시사합니다.
결론 및 향후 전망
NextFlow는 단일 디코더 트랜스포머가 인식(Perceive), 추론(Reason), 창조(Create)를 모두 수행할 수 있다는 강력한 가능성(Proof of Concept)을 제시했습니다. 래스터 스캔 방식의 한계에서 벗어나 Next-Scale Prediction이라는 새로운 패러다임을 도입함으로써, AR 모델도 디퓨전 모델만큼 빠르고 고품질의 이미지를 생성할 수 있음을 증명했습니다. 또한, 이중 코드북 토크나이저와 스케일 재가중치, 프리픽스 튜닝 RL과 같은 정교한 학습 레시피를 통해 멀티모달 통합 모델이 나아가야 할 기술적 방향성을 명확히 보여주었습니다.
물론 한계도 존재합니다. 이산적인 토큰화 과정에서 필연적으로 발생하는 정보 손실로 인해 극도로 사실적인 미세 디테일 표현에는 여전히 디퓨전 기반의 리파인먼트가 도움이 될 때가 있습니다. 또한, 텍스트 생성과 시각적 생성을 하나의 파라미터 공간에서 최적화하는 것은 여전히 까다로운 과제입니다. 연구진은 앞으로 더 고밀도의 추론 데이터를 확보하고, MoE(Mixture-of-Experts) 구조를 통한 모델 확장, 그리고 가변율(Variable-rate) 양자화 같은 차세대 토큰화 기술을 통해 이러한 한계를 극복해 나갈 계획이라고 밝혔습니다.
NextFlow는 단순한 모델 하나를 넘어, 우리가 꿈꾸는 진정한 의미의 옴니 모델(Omni-model)로 가는 중요한 이정표가 될 것입니다.
 NextFlow 논문: NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
NextFlow 논문: NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
 NextFlow 프로젝트 GitHub 저장소
NextFlow 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()