
NitroGen 프로젝트 소개
NitroGen은 NVIDIA와 Caltech, Stanford, UT Austin 등의 연구진이 개발한 게임 에이전트를 위한 프로젝트로, 멀티-게임 파운데이션 에이전트(Multi-Game Foundation Agent) 및 데이터셋, 시뮬레이터 등으로 구성되어 있습니다.
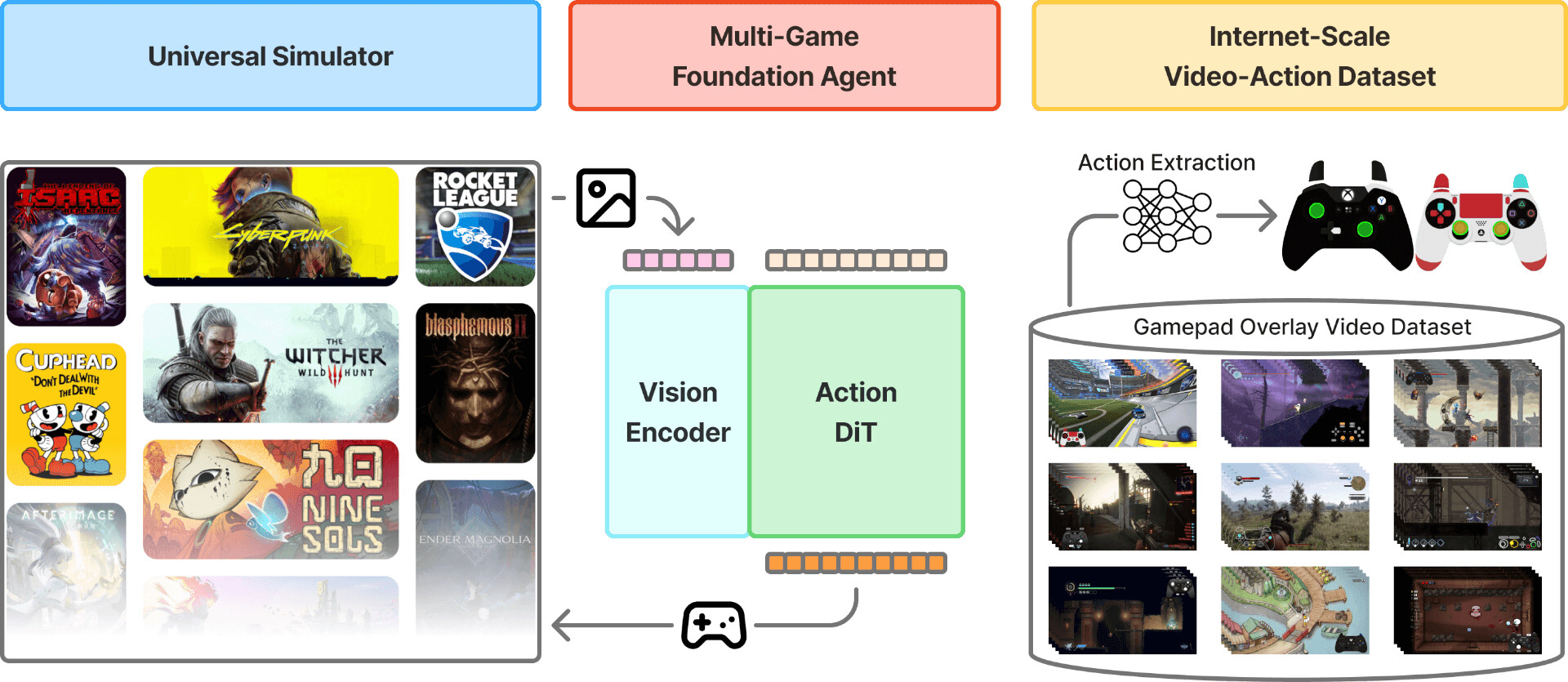
NitroGen 프로젝트의 핵심은 "인터넷 규모의 비디오 데이터로 일반적인 게임 에이전트를 학습시킬 수 있는가?" 라는 질문에 대한 답을 찾는 것입니다. 기존의 컴퓨터 비전(Computer Vision)이나 대규모 언어 모델(LLM) 분야는 인터넷상의 방대한 데이터로 비약적인 발전을 이루었지만, 로봇이나 게임 에이전트와 같은 Embodied AI(체화된 인공지능) 분야는 "행동(Action)" 레이블이 포함된 대규모 데이터를 구하기 어려워 발전이 더뎠습니다.
NitroGen은 이 문제를 기발한 방식으로 해결했습니다. 바로 유튜브 등 인터넷에 공개된 40,000시간 분량의 게임 플레이 영상에서 화면에 표시된 게임패드 오버레이(Gamepad Overlay) 를 인식하여 플레이어의 입력 신호를 역추적하는 방식입니다. 이를 통해 1,000개 이상의 게임을 아우르는 거대한 행동 데이터셋을 구축하고, 이를 학습한 Vision-Action 모델을 공개했습니다.
NitroGen은 3D 액션 게임의 전투, 2D 플랫포머의 정교한 점프, 절차적으로 생성되는 맵 탐험 등 다양한 게임 장르에서 준수한 수행 능력을 보여줍니다. 특히 처음 보는 게임(Unseen games)에 대해서도, 밑바닥부터 학습하는 것보다 NitroGen을 미세 조정(Fine-tuning)했을 때 성공률이 최대 52% 더 높게 나타나, 범용 게임 에이전트로서의 가능성을 입증했습니다.
프로젝트 배경: Embodied AI의 '데이터 장벽'을 넘어서
행동 데이터 부족 문제와 비디오 게임의 잠재력
인공지능 연구의 궁극적인 목표 중 하나는 낯선 환경에서도 유연하게 대처할 수 있는 범용 에이전트(Generalist Agent)를 만드는 것입니다. GPT-4나 Gemini 같은 언어 모델들은 인터넷상의 방대한 텍스트 데이터를 학습하여 일반화된 추론 능력을 얻었지만, 물리적 환경이나 가상 세계에서 상호작용해야 하는 Embodied AI는 이러한 '인터넷 규모(Internet-scale)'의 학습 혜택을 누리지 못했습니다. 로보틱스나 게임 에이전트를 학습시키기 위해서는 시각 정보와 그에 따른 행동이 쌍으로 묶인 데이터가 필수적인데, 기존의 강화학습(Reinforcement Learning) 방식은 시뮬레이터 안에서 수억 번의 시행착오를 거쳐야 하므로 계산 비용이 막대하고, 특정 환경에 과적합(Overfitting)되기 쉬웠습니다.
또한, 전문가의 시연(Demonstration)을 수집하는 방식은 사람의 노동력이 직접 투입되어야 하므로 확장성에 치명적인 한계가 있었습니다. 비디오 게임은 시각적으로 매우 복잡하고 다양한 물리 법칙과 목표를 가지고 있어 Embodied AI를 연구하기에 가장 이상적인 '테스트 베드'로 꼽히지만, 이러한 데이터 확보의 어려움 때문에 그동안은 소수의 특정 게임(스타크래프트, 마인크래프트 등)에 국한된 연구만 진행되어 왔습니다. NVIDIA 연구진은 이러한 문제를 해결하기 위해 특정 게임에 종속되지 않고, 인터넷상의 비디오만으로 범용적인 행동 양식을 학습할 수 있는 NitroGen 프로젝트를 시작하게 되었습니다.
NitroGen의 핵심 구성 요소 및 기여
NitroGen 프로젝트는 단순히 모델 하나를 발표한 것이 아니라, 게임 AI 연구를 위한 전체 생태계를 제안하고 있습니다. 이 연구의 핵심 기여는 크게 세 가지로 요약할 수 있습니다:
인터넷 규모의 게임 영상-행동 데이터셋(Internet-Scale Multi-Game Video-Action Dataset): 첫번째 기여는 인터넷상의 게임 플레이 영상에서 플레이어의 컨트롤러 입력값을 역추적하여 복원해 낸 세계 최대 규모의 비디오-행동 데이터셋(Video-Action Dataset)입니다. 연구진은 1,000개 이상의 다양한 게임 타이틀에서 약 40,000시간 분량의 고품질 행동 데이터를 확보하였고, 이를 Hugging Face에 공개하였습니다.
범용 시뮬레이터(Universal Simulator): 다음은 상용 게임들이 연구용 API를 제공하지 않는다는 문제를 해결하기 위해 개발한 유니버설 시뮬레이터(Universal Simulator)입니다. 이는 게임의 실행 속도를 제어하며 외부에서 입력을 주입할 수 있는 인터페이스로, 어떤 게임이든 표준화된 강화학습 환경(Gymnasium)처럼 다룰 수 있게 해줍니다.
멀티-게임 파운데이션 에이전트(Multi-Game Foundation Agent): 마지막은 이 방대한 데이터를 바탕으로 학습된 시각-행동 파운데이션 모델입니다. 이 모델은 본 적 없는 게임에서도 기본적인 조작이 가능할 뿐만 아니라, 소량의 데이터로 미세 조정(Fine-tuning)했을 때 바닥부터 학습하는 것보다 압도적으로 높은 성능을 보여주었습니다.
연구진은 이러한 모든 데이터셋, 시뮬레이터 코드, 사전 학습된 모델 가중치를 오픈 소스로 공개하여 커뮤니티의 발전을 가속화하고자 합니다.
NitroGen 데이터셋: 인터넷 비디오를 학습 데이터로 변환
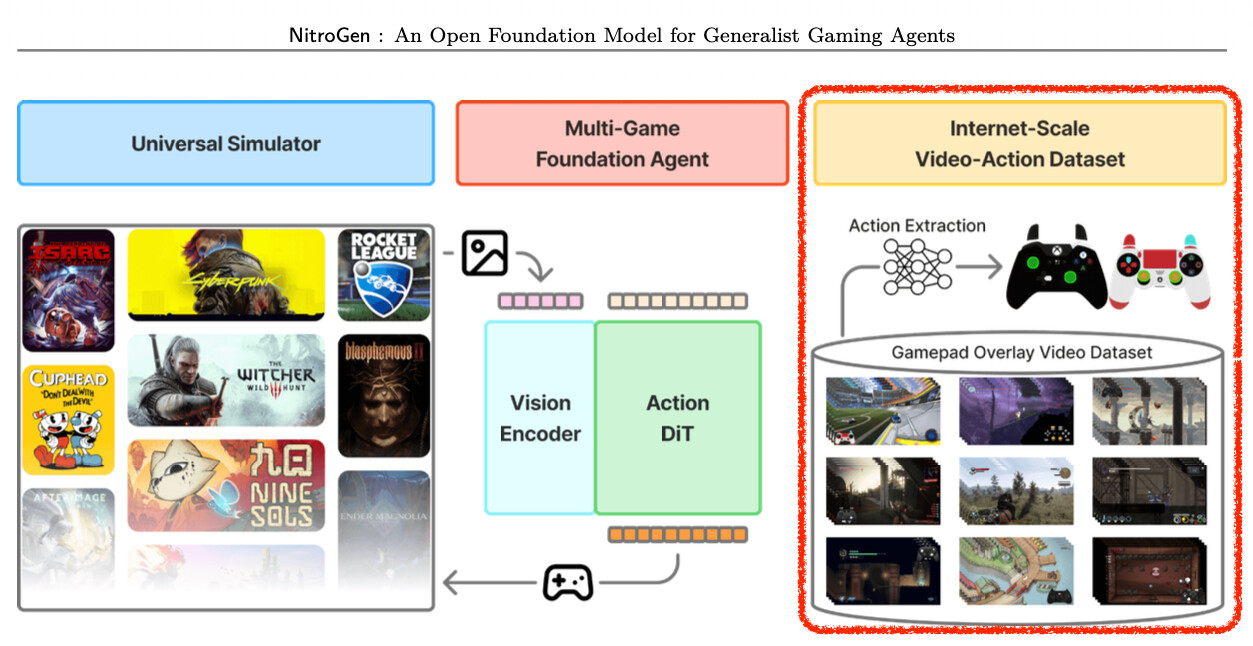
기발한 데이터 수집 전략: 게임패드 오버레이 활용
NitroGen 프로젝트에서 가장 기술적으로 흥미롭고 창의적인 부분은 데이터 수집 전략입니다. 유튜브나 트위치에는 수백만 시간의 게임 플레이 영상이 존재하지만, 정작 플레이어가 '언제 어떤 버튼을 눌렀는지'에 대한 정보는 영상 픽셀 어디에도 기록되어 있지 않습니다. 기존 연구들은 키보드 입력을 추론하려다 실패하거나 아주 제한적인 환경에서만 성공했습니다.

하지만 NitroGen 연구진은 게임 스트리밍 문화에 깊숙이 자리 잡은 입력 오버레이(Input Overlay) 소프트웨어에 주목했습니다. 스피드런(Speedrun) 플레이어나 공략 영상 제작자들은 시청자들에게 자신의 조작을 보여주기 위해 화면 한구석에 가상의 게임패드 이미지를 띄우고, 버튼을 누를 때마다 해당 버튼이 빛나게 설정해 둡니다. 연구진은 바로 이 시각적 신호를 역으로 해석하면 값비싼 하드웨어 장비나 해킹 없이도 완벽한 행동 라벨을 얻을 수 있다는 점에 착안했습니다.
연구진들은 이를 위해 'Gamepad Viewer'나 'Input Overlay' 같은 키워드를 사용하여 무려 71,000시간 분량의 원본 비디오를 수집했습니다. 특정 인기 게임에 데이터가 쏠리는 것을 방지하기 위해 장르별, 난이도별로 세심하게 큐레이션 하여 1,000개가 넘는 게임 타이틀을 확보했으며, 이는 캐주얼 게이머부터 프로 수준의 게이머까지 다양한 숙련도를 포괄하고 있습니다.
정교한 행동 추출 파이프라인 (Action Extraction Pipeline)
수집된 비디오는 단순히 영상일 뿐이므로, 여기서 기계가 이해할 수 있는 디지털 신호(0, 1)를 추출해 내는 과정이 필요합니다. 연구진은 이를 위해 3단계로 구성된 정교한 컴퓨터 비전 파이프라인을 구축했습니다.
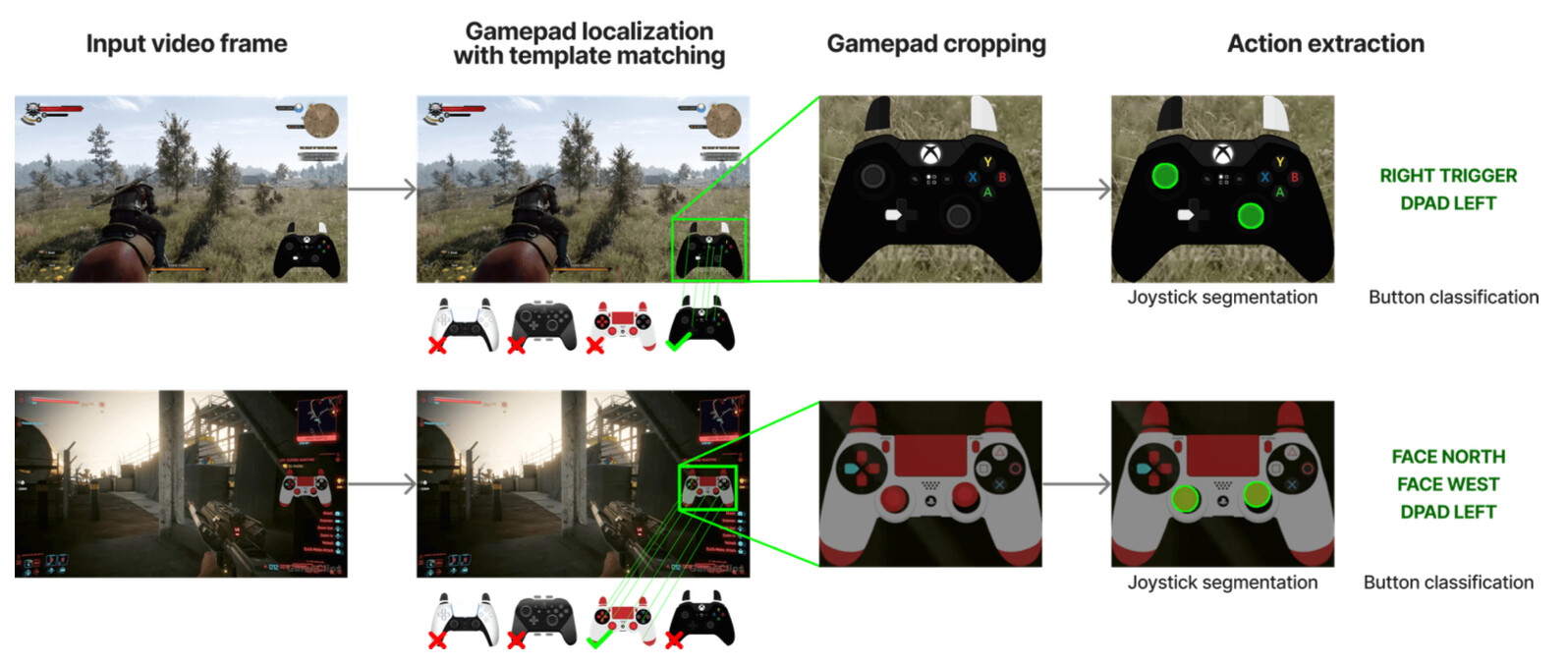
첫 번째 단계는 템플릿 매칭(Template Matching) 입니다. 연구진은 엑스박스(Xbox), 플레이스테이션(PlayStation) 등 널리 쓰이는 약 300종의 컨트롤러 스킨 이미지를 라이브러리로 구축했습니다. 그리고 비디오의 프레임에서 SIFT(Scale-Invariant Feature Transform)와 XFeat 같은 특징점 매칭 알고리즘을 수행하여 화면 내 어디에 컨트롤러가 위치해 있는지, 크기는 얼마인지, 회전되어 있지는 않은지를 찾아냅니다. 이 과정은 영상 전체가 아니라 샘플링된 프레임에 대해 수행되어 계산 효율을 높이면서도 정확하게 오버레이 영역을 잘라낼(Crop) 수 있게 해줍니다.
두 번째 단계는 게임패드 행동 파싱(Gamepad Action Parsing) 입니다. 잘라낸 컨트롤러 이미지에서 실제 버튼 눌림과 조이스틱의 기울기를 읽어내는 과정입니다. 여기서 연구진은 단순한 이미지 분류(Classification)가 아닌, 세그멘테이션(Segmentation) 모델인 SegFormer를 사용했습니다. 버튼의 경우 눌림/안 눌림을 이진 분류로 판단하지만, 조이스틱(아날로그 스틱)의 경우 그 위치를 정확히 파악하는 것이 매우 중요합니다. 연구진은 조이스틱의 좌표를 직접 회귀(Regression)로 예측하는 것보다, 조이스틱의 머리 부분을 세그멘테이션 마스크로 따낸 뒤 그 중심점(Centroid)을 계산하는 방식이 훨씬 오차가 적고 정밀하다는 것을 실험적으로 밝혀냈습니다. 모델은 연속된 두 프레임을 입력으로 받아 시간적인 변화까지 고려하여 현재의 입력 상태를 16개의 버튼과 2개의 아날로그 축으로 완벽하게 변환합니다.
마지막 단계는 품질 필터링(Quality Filtering) 입니다. 영상 중에는 로딩 화면이나 메뉴 화면처럼 플레이어가 아무런 조작을 하지 않는 구간이 많습니다. 이런 데이터가 많아지면 모델은 "아무것도 안 하는 것이 최선"이라고 잘못 학습할 수 있습니다. 이를 방지하기 위해 연구진은 전체 시간 중 50% 이상 입력이 존재하는 활성 구간만 남기고 나머지는 과감히 버렸습니다. 또한, 학습 시에는 모델이 화면 구석의 오버레이를 보고 정답을 '커닝'하는 것을 막기 위해 오버레이 영역을 마스킹(가림) 처리하는 꼼꼼함도 보였습니다.
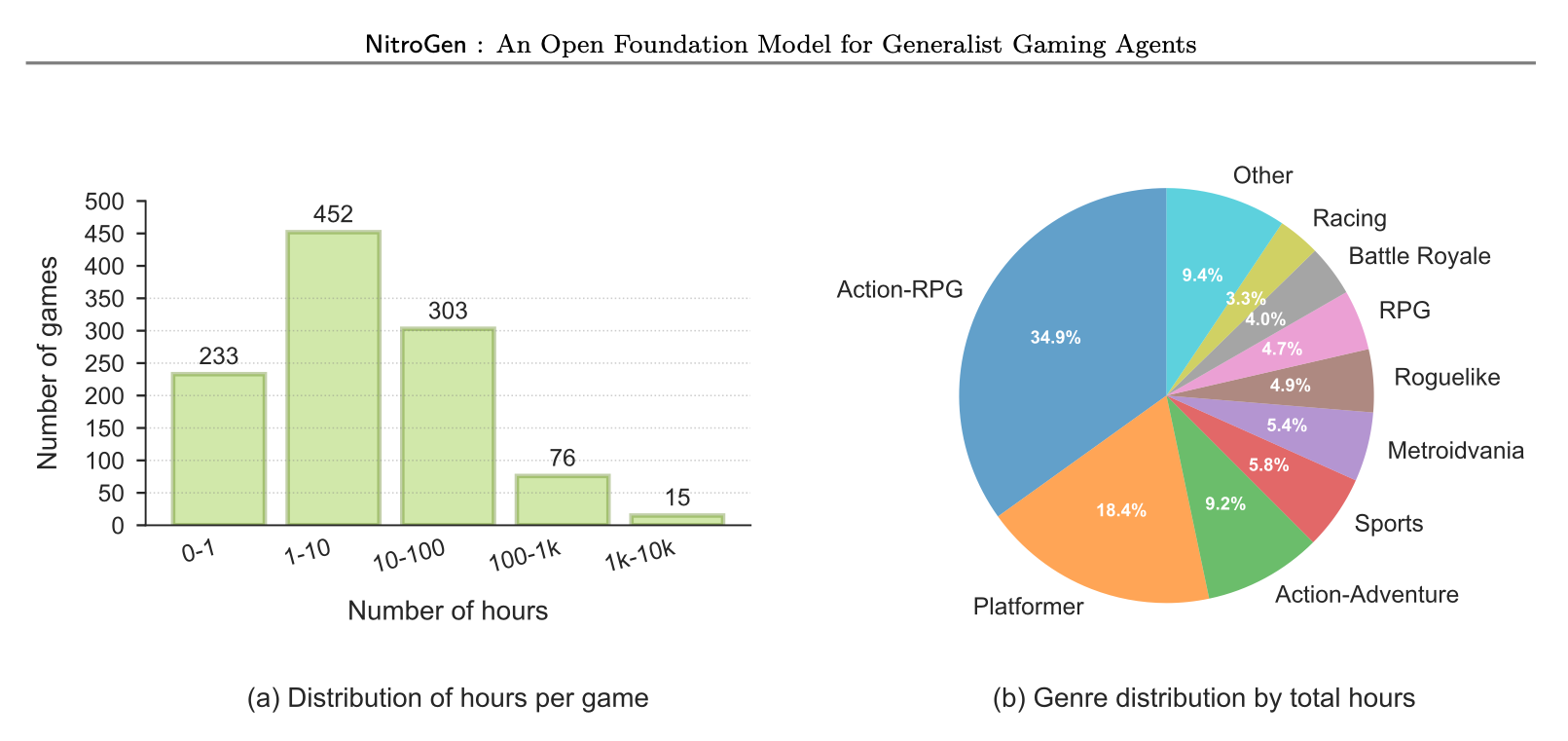
연구진들은 이러한 과정을 거쳐 최종적으로 노이즈가 최소화된 고순도 행동 데이터셋을 완성하였습니다. NitroGen 데이터셋은 1,000개 이상의 게임에 대한 40,000시간 분량의 게임 플레이 영상들로 구성되어 있으며, 이 중 846개 게임은 1시간 이상의 영상을, 91개 게임에 대해서는 100시간 이상, 15개 게임은 무려 1,000시간 이상의 영상을 포함하고 있습니다.
유니버설 시뮬레이터와 평가 벤치마크
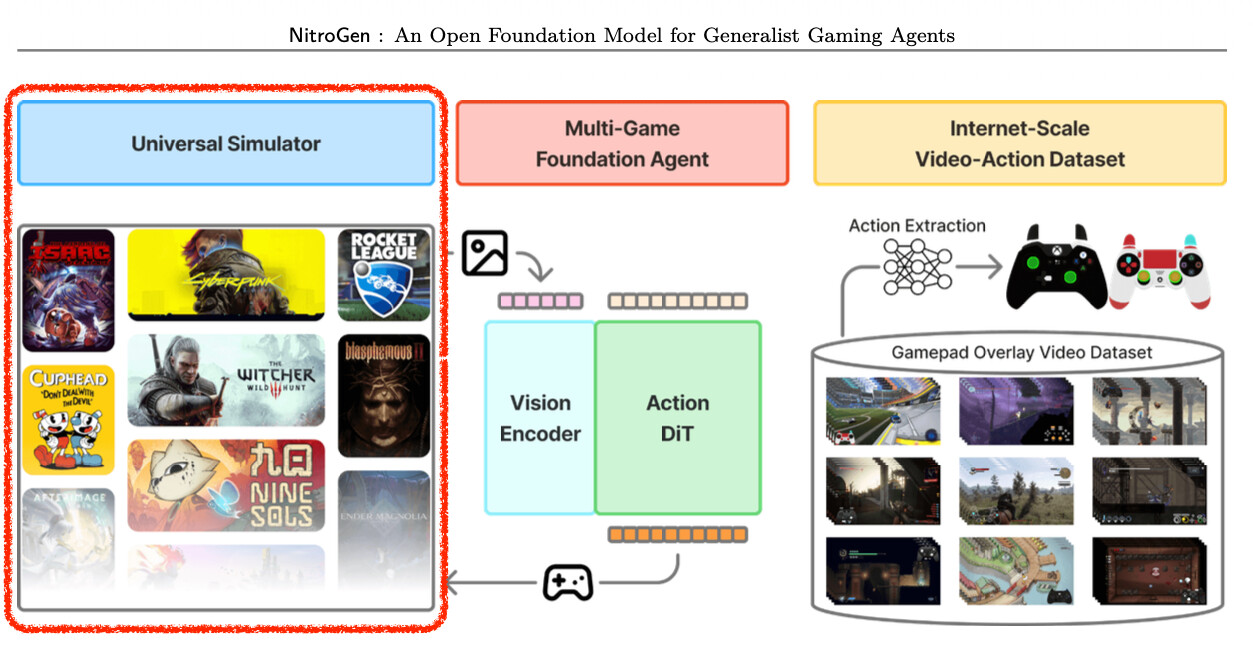
데이터셋이 준비되었다면, 다음으로 필요한 것은 에이전트가 실제로 게임을 플레이하며 성능을 검증받을 수 있는 환경입니다. 하지만 소스코드가 공개되지 않은 상용 게임(Commercial Games)들은 연구용 API를 제공하지 않기 때문에, 에이전트가 게임 상태를 관측하거나 명령을 내리는 것이 불가능에 가깝습니다. NitroGen 연구진은 이 난제를 해결하기 위해 유니버설 시뮬레이터(Universal Simulator) 를 개발하고, 이를 바탕으로 공정한 평가를 위한 멀티 게임 평가 스위트(Evaluation Suite) 를 구축했습니다.
상용 게임을 위한 Gym 인터페이스 구축
연구진이 개발한 유니버설 시뮬레이터의 핵심 기술은 운영체제 레벨에서 게임 엔진의 시스템 시계(System Clock)를 가로채는 것입니다. 대부분의 게임은 물리 엔진과 로직을 시스템 시간에 맞춰 연산하는데, 시뮬레이터가 이 시간의 흐름을 제어함으로써 게임의 속도를 마음대로 조절할 수 있게 됩니다. 즉, 이 시간을 멈추거나 아주 느리게 흐르게 조작함으로써 에이전트가 다음 행동을 계산할 시간을 벌어주는 것입니다.
이를 통해 실시간으로 흘러가는 게임을 마치 턴제 게임처럼 프레임 단위(Frame-by-frame)로 정밀하게 제어하면서 멈추고 진행할 수 있게 되었습니다. 덕분에 에이전트는 다음 행동을 계산할 충분한 시간을 확보할 수 있으며, 연구진은 널리 쓰이는 강화학습 인터페이스인 Gymnasium API 로 위쳐(The Witcher)나 로켓 리그(Rocket League) 같은 고사양 상용 게임들을 감싸(Wrapping) 표준화된 연구 환경으로 탈바꿈시켰습니다.
또한, 연구진은 게임을 빈번하게 멈췄다 실행해도 물리 엔진의 결정론적(Deterministic) 특성이 유지되는지 검증하기 위해, 동일한 입력을 리플레이했을 때 화면이 일치하는지를 확인하는 실험까지 거쳐 신뢰성을 확보했습니다.
다양성을 확보한 멀티 게임 평가 스위트
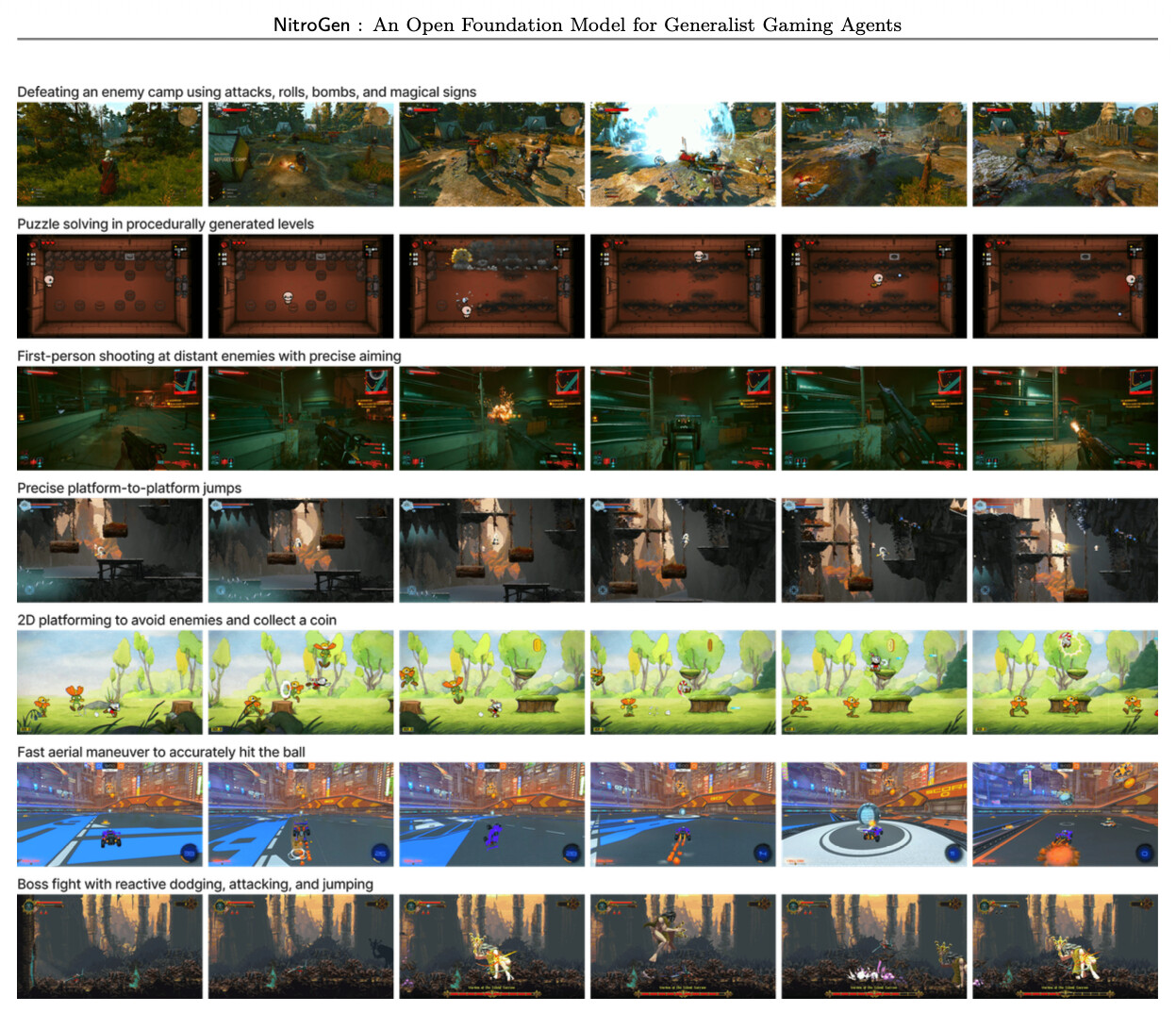
여러 게임을 하나의 모델로 학습시키기 위해서는 먼저 모델의 입력과 출력의 규격이 통일되어야 합니다. NitroGen은 모든 게임의 관측(Observation)을 256x256 해상도의 RGB 이미지 한 장으로 통일했습니다. 연구진들은 또한 통합 행동 공간(Unified Action Space) 설계에도 주의를 기울였습니다. 게임마다 제각각인 조작 체계를 따르는 대신, 최신 게임패드의 표준 입력을 기준으로 16차원의 이진 벡터(버튼) 및 4차원의 연속 벡터(조이스틱) 로 행동 공간을 표준화했습니다. 16개의 버튼(십자키, 페이스 버튼, 숄더/트리거, 기능 버튼)과 2개의 아날로그 스틱을 모사한 이 구조 덕분에, 에이전트는 특정 게임의 키 설정에 얽매이지 않고 마치 사람이 패드를 쥐고 게임을 하듯 다양한 게임 간에 정책(Policy)을 직접 전이(Transfer)할 수 있게 되었습니다.
이후, 연구진은 10개의 서로 다른 게임에서 총 30개의 과제(Task)를 선정하여 벤치마크를 구성했습니다. 이 벤치마크는 단순히 게임을 클리어하는 것을 넘어, 에이전트의 다양한 능력을 측정하도록 설계되었습니다. 예를 들어 '전투(Combat)' 카테고리에서는 3D 액션 RPG에서 적의 공격을 회피하고 반격하는 능력을, '내비게이션(Navigation)'에서는 복잡한 3D 맵에서 목적지까지 길을 찾아가는 능력을, '플랫폼(Platforming)'에서는 2D 횡스크롤 게임에서 낭떠러지로 떨어지지 않고 정밀하게 점프하는 능력을 평가합니다. 모든 게임은 16개의 버튼과 2개의 조이스틱으로 구성된 통합 행동 공간(Unified Action Space) 을 통해 제어됩니다. 이는 에이전트가 게임마다 다른 키 설정을 따로 배울 필요 없이, 마치 사람이 하나의 패드로 여러 게임을 하듯 보편적인 조작 감각을 익혔는지를 테스트하기 위함입니다. 연구진은 각 과제에 대해 인간 평가자가 성공 여부를 판단하도록 하여 신뢰성을 높였습니다.
NitroGen 모델 구조 및 학습
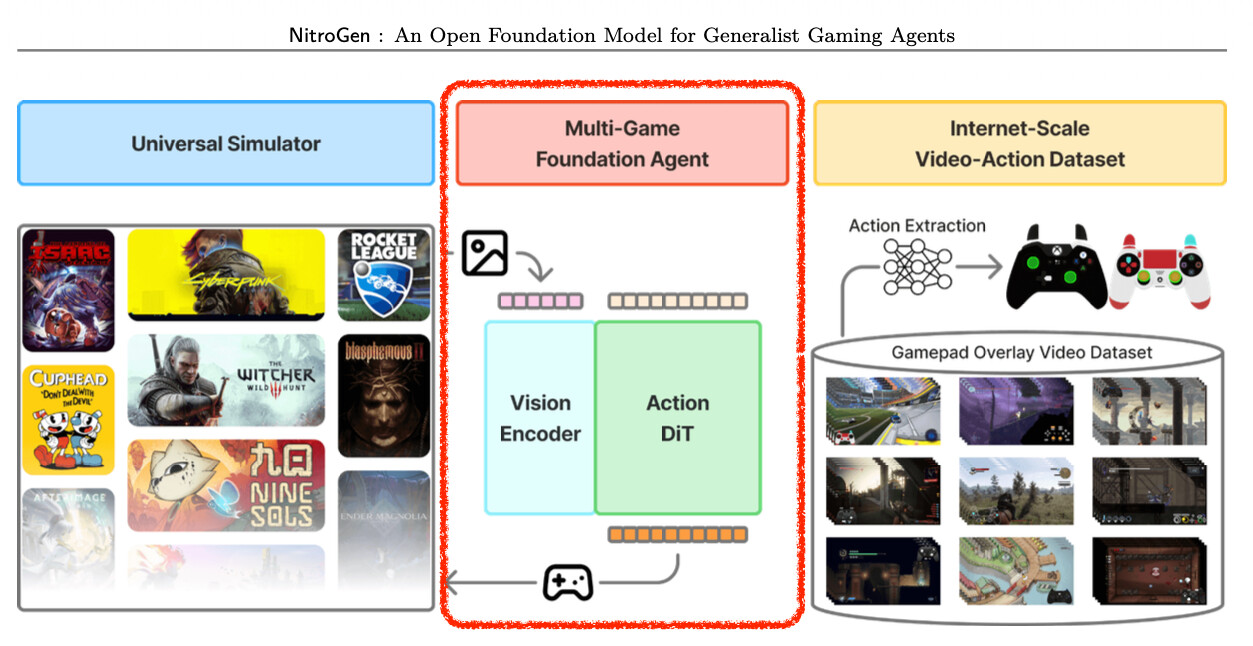
시각-행동 트랜스포머와 Flow Matching
NitroGen 모델은 최신 생성형 AI 기술을 적극적으로 도입했습니다. 기본적으로 언어적 입력 없이 오직 시각 정보만을 받아 행동을 출력하는 Vision-Action Transformer 형태를 띠고 있습니다. 시각 정보를 처리하는 인코더로는 구글의 최신 모델인 SigLIP ViT(Vision Transformer)를 사용하여 256x256 해상도의 게임 화면을 고차원의 특징 벡터로 변환합니다. 이렇게 추출된 시각 정보는 행동 생성 모듈로 전달되는데, 여기서 연구진은 단순한 예측 모델 대신 Flow Matching 기반의 DiT(Diffusion Transformer)를 채택했습니다. Flow Matching은 노이즈로부터 데이터를 생성하는 확산 모델(Diffusion Model)의 일종으로, 복잡하고 다봉(Multi-modal) 분포를 가진 행동 데이터를 모델링하는 데 탁월한 성능을 보입니다. 예를 들어, 적을 만났을 때 '왼쪽으로 피하기'와 '오른쪽으로 피하기'가 모두 정답일 수 있는데, 일반적인 회귀 모델은 이 둘의 평균인 '가만히 있기'를 선택하는 오류를 범하기 쉽지만, Flow Matching은 여러 가능성 중 하나를 명확하게 선택하여 생성할 수 있습니다.
또한, 모델은 한 번에 하나의 행동만을 예측하는 것이 아니라, 미래의 16 프레임 동안 취할 행동의 덩어리(Action Chunk)를 한 번에 생성합니다. 이는 로보틱스 분야의 ACT(Action Chunking Transformer)와 유사한 개념으로, 매 프레임마다 행동을 결정할 때 발생할 수 있는 '떨림 현상(Jittering)'을 줄이고 훨씬 부드럽고 일관성 있는 움직임을 만들어냅니다. 흥미로운 점은 과거의 여러 프레임을 입력으로 주는 것보다 현재의 단일 프레임만 주는 것이 성능이 더 좋았다는 연구진의 발견입니다. 이는 액션 게임의 특성상 현재 화면에 대부분의 정보(적의 위치, 나의 상태 등)가 담겨 있기 때문으로 분석됩니다.
대규모 행동 복제(Behavior Cloning) 학습
NitroGen은 수집된 40,000시간의 데이터를 지도 학습(Supervised Learning)의 일종인 행동 복제(Behavior Cloning) 방식으로 학습했습니다. 인터넷 데이터는 전문가의 플레이만 있는 것이 아니라 초보자의 실수나 엉뚱한 행동도 포함되어 있어 노이즈가 매우 심합니다. 또한 화면에는 스트리머의 채팅창, 후원 알림, 캠 화면 등 게임과 무관한 시각적 정보도 가득합니다. 하지만 연구진은 데이터의 규모가 이러한 노이즈를 압도할 수 있다는 'Scaling Law'를 믿고 학습을 진행했습니다. 학습 과정에서는 웜업(Warmup) 후에 학습률을 일정하게 유지하다가 마지막에 줄이는 WSD(Warmup-Stable-Decay) 스케줄러를 사용하고, 모델 가중치의 지수 이동 평균(EMA)을 적용하여 학습의 안정성을 극대화했습니다. 그 결과, 별도의 강화학습(RL) 과정 없이 오직 비디오를 보고 따라 하는 것만으로도 모델은 3D 공간을 이동하고, 적을 조준하고, 점프 타이밍을 맞추는 등의 기본적인 게임 플레이 능력을 획득할 수 있었습니다.
실험 결과 및 성능 분석
제로샷 및 파인튜닝 성능의 우수성
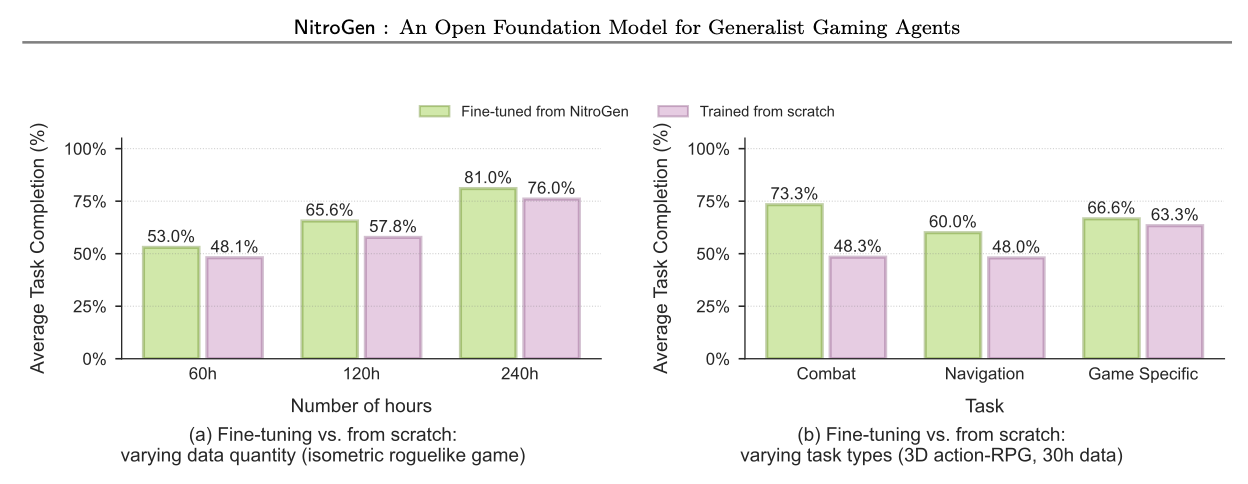
실험 결과는 NitroGen의 파운데이션 모델로서의 가치를 증명해 줍니다. 연구진은 NitroGen을 학습시킬 때 특정 게임 하나를 제외하고 학습시킨 뒤, 그 제외된 게임에 대해 모델을 평가하는 방식으로 성능을 검증했습니다. 놀랍게도 모델은 한 번도 본 적 없는 게임에서도 캐릭터를 움직이고 기본적인 상호작용을 수행하는 제로샷(Zero-shot) 능력을 보여주었습니다.
하지만 더 중요한 것은 미세 조정(Fine-tuning) 성능입니다. 제외된 게임의 데이터를 아주 조금(예: 30시간 분량)만 사용하여 NitroGen을 추가 학습시켰을 때, 바닥부터(From Scratch) 학습한 모델보다 월등히 높은 성공률을 기록했습니다.
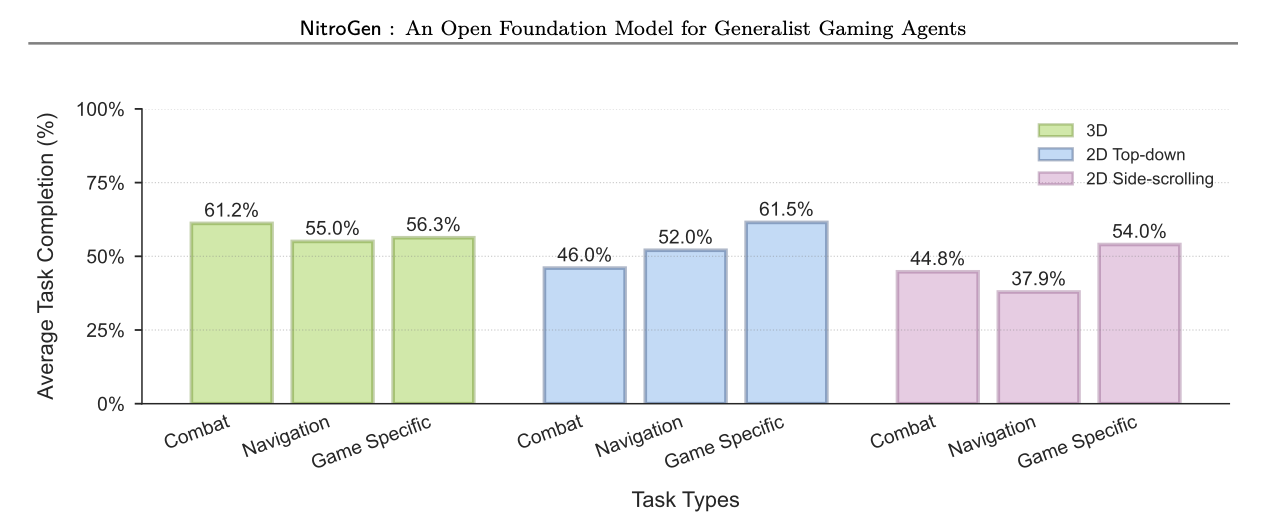
특히 데이터가 부족한 상황에서 성능 격차가 컸는데, 3D 액션 RPG 장르의 경우 바닥부터 학습한 모델 대비 상대적으로 최대 52%의 성능 향상을 보였습니다. 이는 NitroGen이 40,000시간의 학습을 통해 "3D 공간이란 무엇인가", "적을 만나면 어떻게 해야 하는가"와 같은 게임의 보편적인 문법을 이미 내재화하고 있으며, 이를 새로운 게임에 효과적으로 전이(Transfer)시킬 수 있음을 의미합니다.
데이터셋 품질 및 모델의 강건함 검증
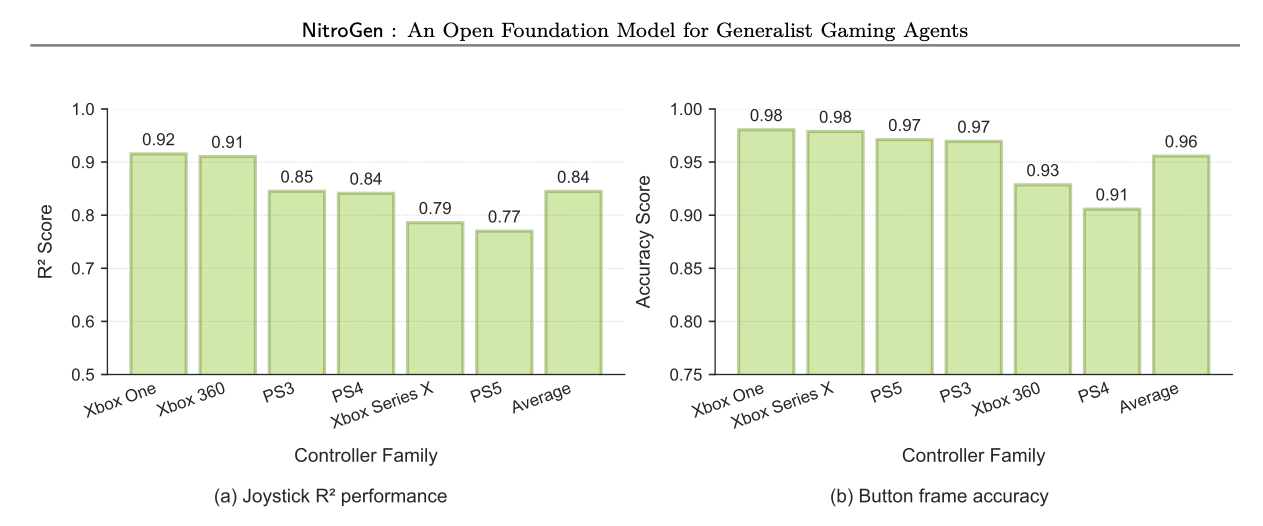
연구진은 또한 제작한 NitroGen 데이터셋의 신뢰성을 입증하기 위해 별도의 정량적 분석도 수행했습니다. 실제로 사람이 6개의 게임을 플레이하며 녹화한 '정답(Ground Truth)' 데이터와, 파이프라인이 영상만 보고 추출한 데이터를 비교한 것입니다. 그 결과 조이스틱의 위치 정확도를 나타내는 R-squared 점수는 평균 0.84, 버튼 입력 정확도는 96%에 달했습니다. 이는 영상 압축으로 인한 화질 저하, 다양한 컨트롤러 디자인, 화면을 가리는 자막 등의 악조건 속에서도 파이프라인이 매우 정확하게 행동을 복원해 냈음을 보여줍니다. 또한, 학습된 모델은 화면에 채팅창이나 웹캠 같은 시각적 방해 요소가 있어도 게임 플레이에 중요한 요소(캐릭터, 지형, 적)에 집중하여 안정적으로 작동하는 강건함(Robustness)을 보여주었습니다. 이는 인터넷 비디오를 활용한 대규모 학습이 Embodied AI에서도 충분히 효과적일 수 있다는 강력한 증거가 됩니다.
결론: 게임 AI 연구의 새로운 지평을 열다
연구의 의의와 한계점
NitroGen은 그동안 데이터 부족으로 정체되어 있던 게임 AI 및 Embodied AI 분야에 새로운 돌파구를 마련했습니다. "게임패드 오버레이"라는 놓치기 쉬운 정보를 대규모 데이터 마이닝의 원천으로 활용한 점은 데이터 중심(Data-centric) AI 연구의 훌륭한 모범 사례가 될 것입니다. 이 연구는 비디오 게임이 단순한 오락을 넘어 인공지능의 일반 지능(General Intelligence)을 테스트하고 훈련하는 훌륭한 환경임을 다시 한번 입증했습니다.
물론 한계점도 명확합니다. 현재의 NitroGen 모델은 눈앞의 상황에 즉각 반응하는 '반사적(System 1)' 능력에 집중되어 있습니다. 복잡한 퍼즐을 풀거나, 장기적인 계획을 세워 미션을 수행하는 '추론적(System 2)' 능력은 아직 부족합니다. 또한, 데이터셋이 컨트롤러를 사용하는 액션, RPG 장르에 편중되어 있어 마우스와 키보드를 사용하는 정밀한 전략 시뮬레이션(RTS)이나 MOBA 장르에는 적용하기 어렵다는 제약도 있습니다. 연구진은 향후 언어 모델(LLM)을 두뇌로 사용하여 장기적인 계획을 수립하고, NitroGen을 손과 발로 사용하는 계층적 구조를 통해 이러한 한계를 극복할 수 있을 것으로 내다보고 있습니다.
오픈 소스 생태계에 대한 기여
NVIDIA는 이 연구의 모든 산출물을 오픈 소스로 공개하는 대범한 결정을 내렸습니다. 누구나 HuggingFace에서 40,000시간의 데이터셋과 사전 학습된 모델을 다운로드할 수 있으며, GitHub를 통해 유니버설 시뮬레이터를 설치하여 자신의 게임 환경에 적용해 볼 수 있습니다. 이는 학계뿐만 아니라 인디 게임 개발자, AI 연구자들에게 엄청난 자산이 될 것입니다. 마치 이미지넷(ImageNet)이 컴퓨터 비전의 혁명을 이끌고, GPT가 자연어 처리의 혁명을 이끌었듯이, NitroGen이 공개한 리소스들이 게임 AI 에이전트 연구의 캄브리아기 대폭발을 일으키는 기폭제가 되기를 기대해 봅니다. 관심 있는 개발자분들은 아래 링크를 통해 직접 모델을 테스트해 보시길 권장해 드립니다.
NitroGen 프로젝트 홈페이지
NitroGen 논문: An Open Foundation Model for Generalist Gaming Agents
NitroGen 데이터셋: Internet-scale multi-game video-action dataset
NitroGen 모델: NitroGen Foundation Model
NitroGen GitHub 저장소
https://github.com/MineDojo/NitroGen
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()