현재 LSTM 디코더를 구현하고 있습니다.
targets 값을 정수 인덱스로 변화한 후, nn.embedding 값에 넣어 embed 값을 활용하고 있습니다.
그런데, nn.embedding 을 지난 후 targets 값이 변화합니다.
이러한 targets 값의 변화를 이해할 수 없습니다.
혹시 이런 경험을 해보신 분이 있나요?
아래는 코드입니다.
self.embedding = nn.Embedding(num_classes, hidden_state_dim, padding_idx = 0) # padding_idx = pad_id
embedded = self.embedding(targets)
if target_lengths is not None:
embedded = nn.utils.rnn.pack_padded_sequence(embedded.transpose(0, 1), target_lengths.cpu(), enforce_sorted=False)
outputs, hidden_states = self.rnn(embedded, hidden_states)
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)
outputs = self.out_proj(outputs.transpose(0, 1))
else:
outputs, hidden_states = self.rnn(embedded, hidden_states)
outputs = self.out_proj(outputs)
return outputs, hidden_states
targets값이 변화하는 것인데, target값이 왜 변화하는건지 모르겠네요ㅠㅠㅠㅠ
nn.embedding을 지나기 전에는

위의 사진 처럼 값이 제대로 있는데
nn.embedding만 지나면
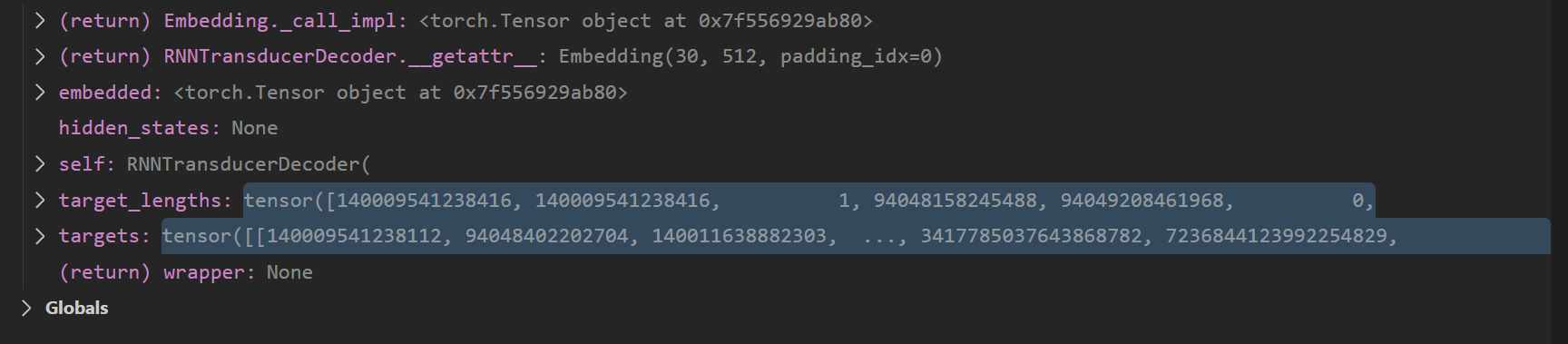
이이렇게 값이 크게 변화합니다.
봇들이 댓글을 달아주었는데, 저의 문제는 targets 값이 변화하는 것 입니다. 코드에 따르면 embedded = self.embedding(targets) 이후에 embedded 값은 당연히 임베딩 값으로 변화하겠지만, targets값에 다른 값이 지정되도록 설정해주진 않았습니다. 그런데 target 값이 변화하는 것 입니다...