
대규모 언어 모델(LLM)의 크기와 복잡성이 증가함에 따라 신속하고 비용 효율적으로 제공하기 위한 성능 요구사항도 증가하고 있습니다. LLM 추론 성능을 높이려면 효율적인 병렬 컴퓨팅 아키텍처와 유연하고 고도로 최적화된 소프트웨어 스택이 필요합니다. 최근 NVIDIA Hopper GPU가 NVIDIA TensorRT-LLM 추론 소프트웨어를 실행하여 업계 표준인 MLPerf Inference v4.0 벤치마크에서 새로운 성능 기록을 세웠습니다.
혼합 전문가(MoE, Mixture-of-Experts) 아키텍처를 기반으로 하는 LLM이 등장하여 모델 용량, 교육 비용 및 초기 토큰 제공 지연 시간 측면에서 잠재적인 이점을 제공합니다. Mistral AI가 개발한 Mixtral 8x7B 모델은 이러한 MoE 아키텍처를 사용하여 인상적인 성능을 보여주었습니다. 이 글에서는 NVIDIA H100 Tensor Core GPU와 TensorRT-LLM 소프트웨어가 Mixtral 8x7B에서 뛰어난 성능을 발휘하는 방법을 보여줍니다.
Mixtral 8x7B 성능: NVIDIA H100 및 TensorRT-LLM
대규모 언어 모델(LLM) 배포 시, 클라우드 서비스는 쿼리 응답 시간 목표를 설정하고, 이러한 제약 내에서 가능한 많은 사용자 쿼리를 병렬로 처리하도록 최적화합니다. TensorRT-LLM은 LLM 제공 중에 완료된 요청을 새로운 요청으로 대체하는 "실시간 배칭"을 지원하여 성능을 향상시킵니다.
H100 처리량 대 응답 지연 시간
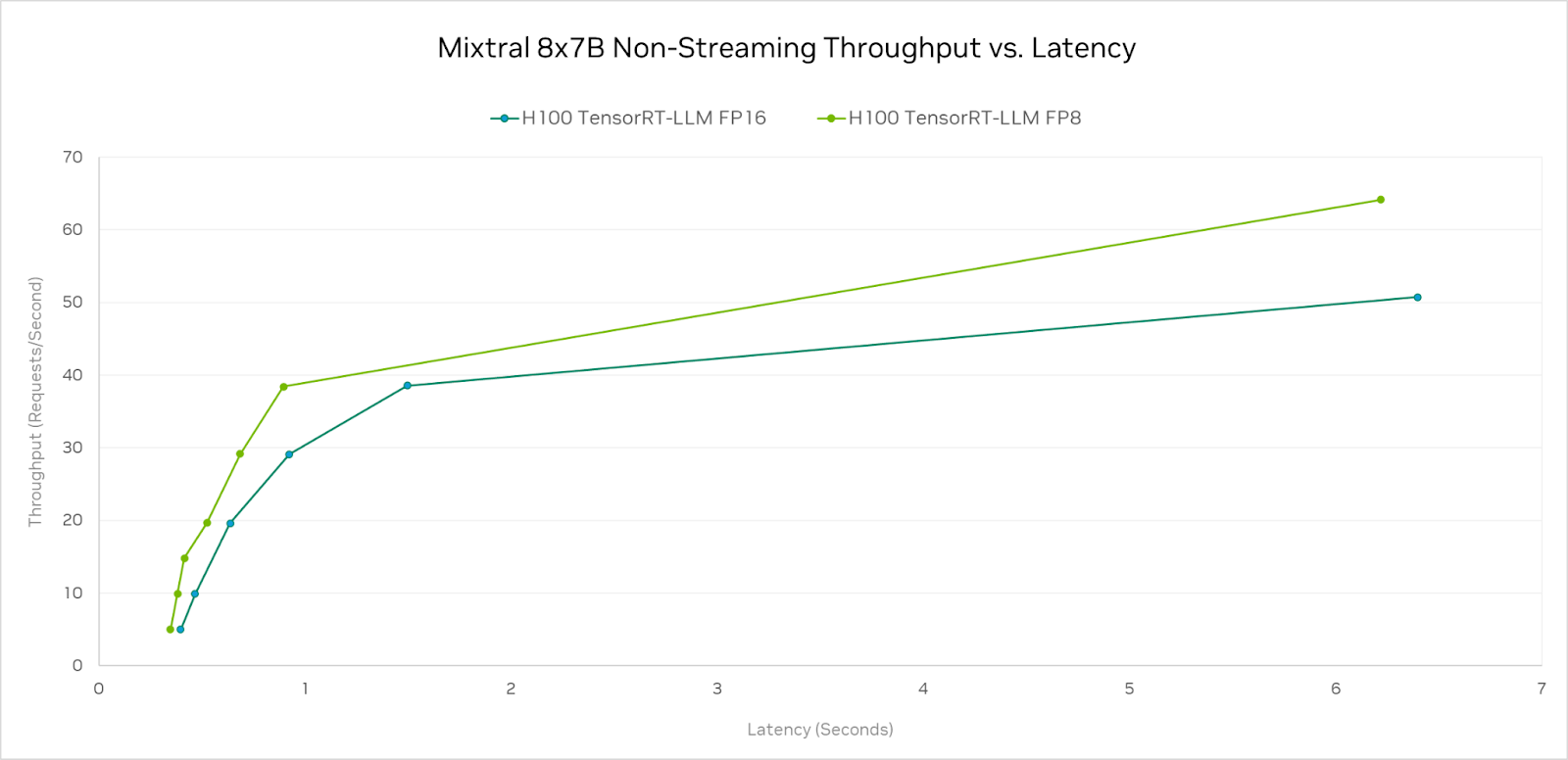
H100 SXM GPU 두 대를 사용하여 FP16 및 FP8 정밀도로 TensorRT-LLM 소프트웨어를 실행할 때의 처리량과 각 요청에 대한 응답 시간을 도식화한 차트를 아래에서 볼 수 있습니다.
NVIDIA Hopper 아키텍처는 FP8 데이터 유형을 지원하며, 이는 FP16 또는 BF16과 비교하여 두 배의 연산 성능을 제공합니다. FP8 정밀도를 사용하면 H100 GPU는 0.5초 응답 시간 제한 내에서 거의 50% 더 많은 처리량을 제공합니다.
H100 처리량 대 출력 토큰당 평균 시간
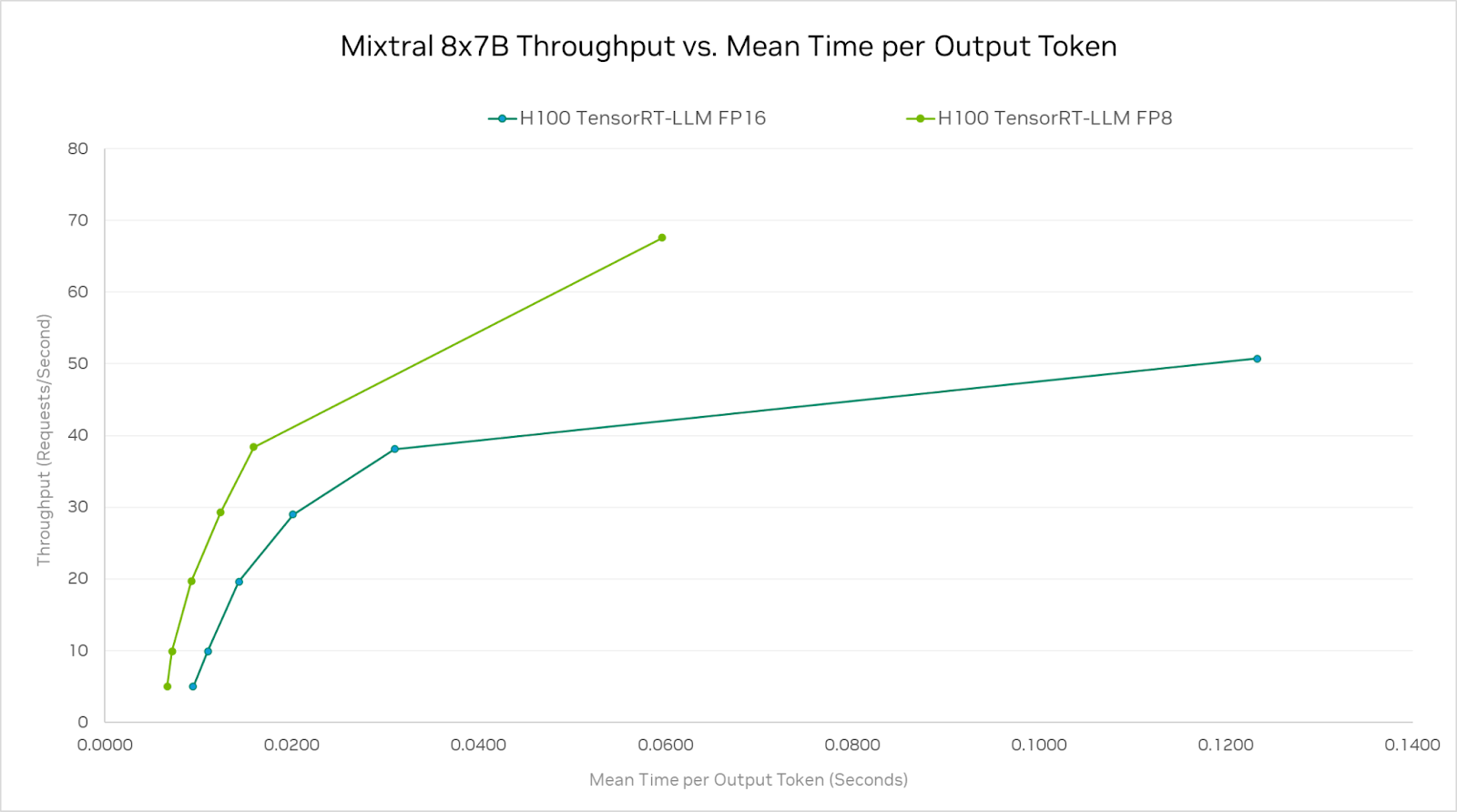
H100 GPU와 TensorRT-LLM 소프트웨어는 스트리밍 모드에서도 뛰어난 성능을 제공합니다. 스트리밍 모드에서는 전체 추론 요청이 처리된 후 총 지연 시간을 보고하는 대신 출력 토큰이 생성될 때마다 결과를 보고합니다.
FP8 정밀도를 사용하면, 각 사용자에게 초당 60개 이상의 토큰을 제공하면서 높은 처리량을 달성할 수 있습니다. 이는 응답성을 높이고 비용을 절감하는 데 도움이 됩니다.
지연 시간 제약이 없는 경우의 H100 처리량
지연 시간 제약이 없는 시나리오에서 H100의 성능을 측정한 표는 다음과 같습니다.
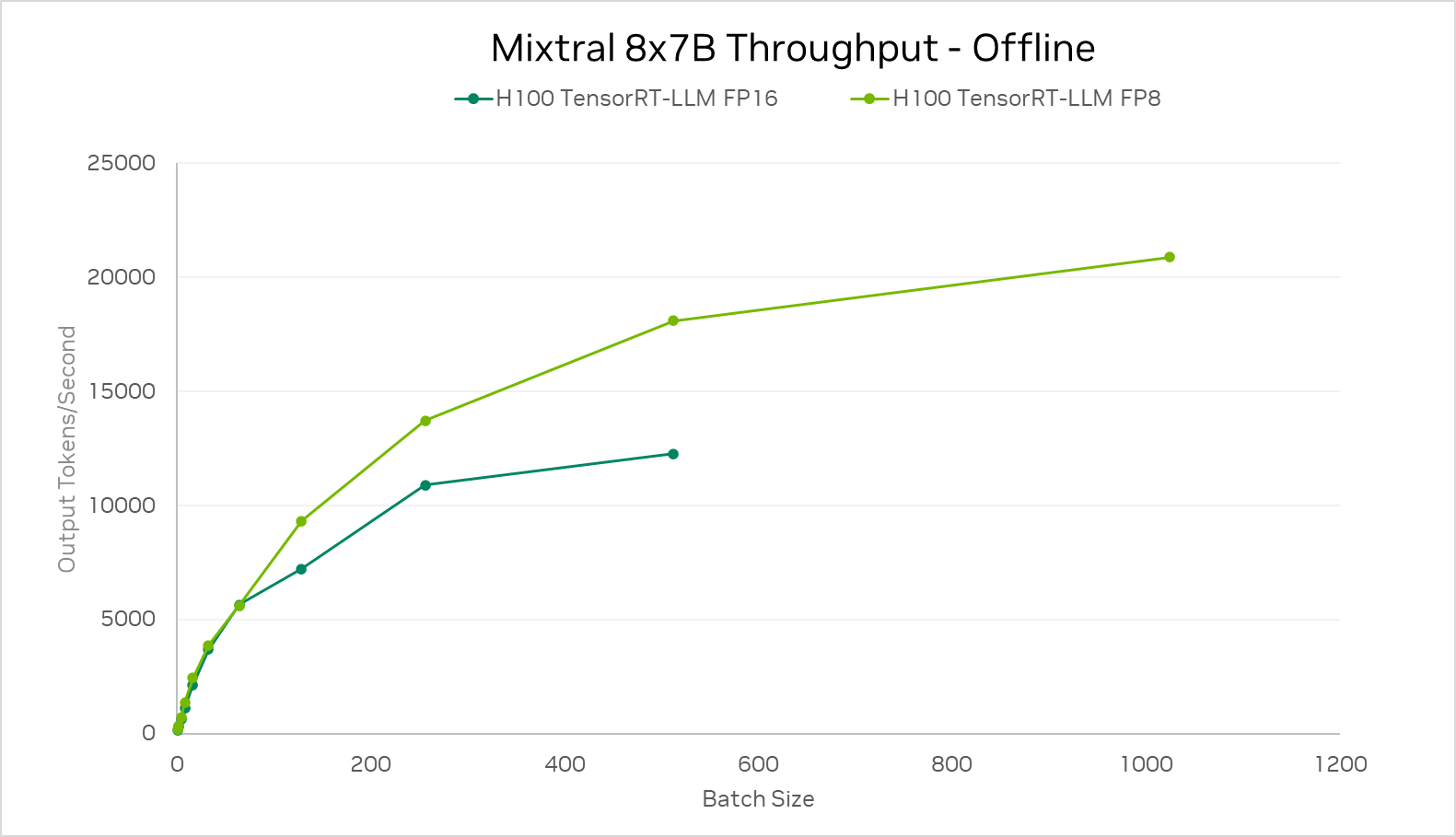
배치 크기가 증가함에 따라 작업이 점점 더 계산 집약적으로 변하고, FP8 처리량의 이점이 극대화됩니다.
NVIDIA TensorRT-LLM 및 Mixtral 8x7B
TensorRT-LLM은 Mixtral과 같은 LLM의 추론을 최적화하기 위한 오픈 소스 라이브러리입니다. 이 라이브러리는 최적화된 어텐션 커널, KV 캐싱 기술, FP8 또는 INT4 AWQ 양자화 등 다양한 최적화 기능을 제공합니다. Mixtral을 TensorRT-LLM으로 배포하면 전문가 병렬 처리와 최적화된 전문가 커널과 같은 맞춤형 기술을 사용할 수 있습니다.
MoE는 여러 전문가의 출력을 결합하여 정확도와 일반화를 향상시킵니다. 각 전문가는 특정 데이터셋과 기술에 대해 훈련되며, 이를 통해 도메인별 정확도를 높일 수 있습니다. 전문가의 조합은 정확도를 높이고, 가중 평균화된 전문가들의 출력은 일반화를 향상시킵니다.
NVIDIA Hopper GPU와 TensorRT-LLM은 최신 LLM, 특히 MoE 모델인 Mixtral 8x7B에서 뛰어난 추론 성능을 제공합니다. NVIDIA는 또한 최신 모델에 대한 빠른 지원과 지속적인 성능 향상을 제공하여 총 소유 비용을 최소화하고 투자 수익을 증가시킵니다.
NVIDIA의 원본 글
 TensorRT-LLM GitHub 저장소
TensorRT-LLM GitHub 저장소
https://github.com/NVIDIA/TensorRT-LLM
TensorRT-LLM에서의 Mixtral 8x7B 모델 활용 예시
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()