
OAT 소개
OAT(Online Alignment for LLMs) 프레임워크는 대규모 언어모델(LLM, Large Language Model)의 온라인 정렬(Online Alignment) 과정을 실험하고 연구하기 위한 프레임워크로, 가볍고(lightweight) 확장 가능한 것이 특징입니다. 이 프로젝트는 싱가포르 국립대학 AI 연구 그룹(SAIL-SG) 이 주도한 연구의 결과물로, “Sample-Efficient Alignment for LLMs” (arXiv:2411.01493)에서 제안된 아이디어를 실용적인 코드베이스로 구현하였습니다.
기존의 RLHF(Reinforcement Learning from Human Feedback)나 DPO(Direct Preference Optimization)와 같은 LLM 정렬 방식은 주로 정적인 데이터셋(offline dataset) 에 기반했습니다. 즉, 사전에 수집된 인간 피드백(Human Feedback) 데이터를 이용해 모델을 한 번 학습하고 종료하는 구조로, 이러한 고정 데이터셋을 사용하여 학습하는 방법은 몇 가지 단점을 갖고 있었습니다. 예를 들어, 새로운 피드백이나 상호작용을 즉시 반영하지 못하거나, 학습 효율이 낮고 실험 재현성이 낮은 등, 모델이 얼마나 효율적으로 피드백을 활용하는지를 평가하기 어려웠습니다.
이에 반해, OAT는 LLM 정렬을 CDB(Contextual Dueling Bandits) 문제로 보고 접근하는 방식을 취했습니다. 즉, LLM이 생성한 여러가지 응답 중, 어떠한 응답이 더 인간의 선호에 가까운지를 비교(Pairwise Preference) 형태로 학습합니다. 이러한 과정을 통해 OAT는 실험 중 모델이 생성하는 응답을 실시간으로 평가하고, 그 결과(보상·선호)를 즉시 학습에 반영하는 “온라인 정렬” 방식을 지원합니다. 이로써, 모델은 고정된 데이터셋에 의존하지 않고 스스로 탐색하며 지속적으로 개선되는 “자기 학습형(Active Learning)” 정렬 구조를 형성할 수 있습니다.
LLM Alignment 개념 및 연구 동향
LLM Alignment(대규모 언어 모델 정렬) 이란, 언어 모델이 인간의 의도와 가치, 논리적 일관성에 맞게 행동하도록 학습시키는 과정을 의미합니다.
LLM은 대량의 텍스트 데이터를 통해 확률적으로 다음 단어를 예측하는 방식으로 훈련되지만, 이러한 방식만으로는 ‘인간이 기대하는 방식’의 응답을 보장하지 못합니다. 예를 들어, 모델이 유해하거나 편향된 답변을 생성하거나, 논리적으로 타당하지 않은 결론을 내릴 수 있습니다. 이를 해결하기 위해 RLHF(Reinforcement Learning from Human Feedback), DPO(Direct Preference Optimization), RLAIF(Reinforcement Learning from AI Feedback) 등의 정렬 기법이 등장했습니다. 이러한 접근법들은 인간(또는 AI)의 피드백을 보상 신호로 활용해 모델이 바람직한 응답을 선택하도록 훈련합니다.
최근 연구 경향은 오프라인 정렬(offline alignment) 에서 **온라인 정렬(online alignment)**로 진화하고 있습니다. 기존에는 고정된 데이터셋을 바탕으로 모델을 일괄 학습했지만, 최신 연구들은 모델이 학습 중 실시간 피드백을 받고 이를 즉시 반영하는 실시간 피드백 루프(online feedback loop) 에 집중하고 있습니다. 또한, LLM-as-a-Judge(모델이 스스로 보상 평가자 역할을 하는 구조), 자기강화(Self-play), 능동적 탐색(Active Exploration), 검증 가능한 보상(Verifiable Reward) 등의 방향으로 발전하며, 인간 의존도를 줄이고 효율적인 정렬 프로세스를 구축하려는 시도가 활발히 진행되고 있습니다.
OAT의 설계 철학 및 목표
OAT의 기반이 되는 'Sample-Efficient Alignment for LLMs' 논문에서는 다음 3가지 아이디어를 제안하였습니다:
-
능동적 탐색(Active Exploration): 단순히 무작위 샘플링하는 것이 아니라,모델이 “불확실성이 높은 영역(uncertain region)”에서 더 많은 샘플을 요청하여 학습 효율을 높이는 방식입니다. 이는 OAT에서는 Active Alignment 모듈로 구현되어 있으며, 학습 중 불확실성이 높은 데이터에 더 높은 쿼리 확률을 부여합니다.
-
혼합 선호 학습(Mixed Preference Learning): SEA는 모델의 현재 정책(policy)와 과거의 피드백을 함께 사용하여, 보상 예측기의 불확실성을 줄입니다. 이는 OAT에서는 Learner가 Oracle의 피드백 로그를 지속적으로 누적하며 '즉시 학습 + 장기 평균 보상'을 함께 최적화하는 방식으로 구현되었습니다.
-
샘플 효율성(Sample Efficiency): 목표는 가능한 적은 피드백(예: 1,000회 이하의 평가)으로 최대의 정렬 효과를 내는 것입니다. OAT의 분산 학습 엔진은 비동기 데이터 파이프라인으로 구성되어 동일한 피드백 데이터를 여러 정책 업데이트에 재활용할 수 있도록 구현되었습니다.
이를 기반으로 구현한 OAT는 다음과 같은 설계 철학을 갖습니다:
-
Simple but Scalable (단순하지만 확장 가능한 구조) LLM 정렬 실험의 파이프라인을 단순화하여, 연구자가 빠르게 실험을 설계하고 확장할 수 있도록 지원합니다.
-
Online by Design (본질적으로 온라인 중심) 정렬 알고리즘이 실시간 피드백 루프를 자연스럽게 수행하도록 설계되었습니다.즉, 모델의 출력과 보상 신호가 끊임없이 순환하며 학습됩니다.
-
Research-Friendly (연구 친화성 극대화) 알고리즘, 보상 모델, 탐색 전략 등을 모듈 단위로 교체·확장할 수 있습니다. 즉, PPO, DPO, GRPO 등 최신 정렬 기법을 직접 실험하거나 변형해 볼 수 있습니다.
고효율 분산 Actor–Learner–Oracle 구조
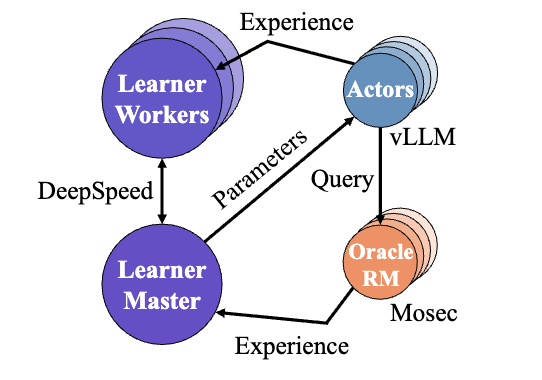
OAT 는 강화학습(RL) 기반 시스템에서 자주 사용되는 Actor–Learner–Oracle 구조를 기반으로 합니다. 이 구조는 LLM 정렬의 각 단계를 독립된 모듈로 분리함으로써 병렬화와 분산 실행이 가능하도록 설계되었습니다. 각각은 다음과 같습니다:
-
Actor: Actor는 모델의 응답을 생성하고, 실험 데이터를 수집하는 역할을 수행합니다. vLLM을 기반으로 고속 샘플링 및 배칭을 지원하며, 다중 GPU(Multi-GPU) 환경에서 수천 개의 문장을 실시간으로 생성할 수 있습니다. 이러한 과정을 거쳐 생성된 응답은 Learner와 Oracle로 전달되어 보상 평가 및 학습에 활용됩니다.
-
Learner: Learner는 Actor가 생성한 데이터를 바탕으로 모델 파라미터를 업데이트합니다. DeepSpeed의 ZeRO 전략을 통해 GPU 메모리 사용을 최적화하며, 실시간 학습이 가능하도록 비동기 학습(Asynchronous Training) 구조를 채택했습니다. Learner는 PPO, DPO, SimPO, IPO, GRPO 등의 다양한 온라인 정렬 알고리즘을 지원합니다.
-
Oracle: Oracle은 모델의 응답을 평가하고 보상 신호를 반환하는 컴포넌트입니다. Mosec을 원격 서비스로 활용하며, 동적 배칭 및 병렬 평가를 지원합니다. Oracle은 LLM을 평가자로 사용하는 LLM-as-a-Judge 형태로, OpenAI API나 자체 모델을 연결하여 사용할 수 있습니다. 또한, 규칙 기반(rule-based) 또는 경량화된 로컬 보상 모델을 사용할 수도 있습니다.
이러한 Actor-Learner-Oracle의 구조는 모델의 학습, 평가, 보상 계산이 독립적으로 이루어지므로, 서버 자원이 분산되어 있거나 다양한 연구 환경에서 쉽게 확장할 수 있습니다.
기존 정렬 프레임워크와의 비교
OAT는 Hugging Face의 TRL(Transformers Reinforcement Learning) , OpenRLHF , DeepSpeed-Chat 등 기존 RLHF 구현과 다음과 같은 점에서 차별화됩니다:
| 구분 | 기존 RLHF/DPO | OAT |
|---|---|---|
| 학습 방식 | 오프라인 (정적 데이터셋 기반) | 온라인 (실시간 피드백 기반) |
| 보상 모델 | 고정된 reward model | 동적 reward/oracle 구조 |
| 아키텍처 | 단일 프로세스 중심 | 분산 Actor–Learner–Oracle |
| 실험 편의성 | 수동 평가 및 checkpoint 관리 필요 | 실시간 wandb 시각화 및 자동 평가 |
| 확장성 | 제한적 | 모듈형 구조로 실험 자유도 높음 |
| 연산 효율성 | 표준 HuggingFace 트레이너 | TRL 대비 최대 2.5배 효율적 (논문 기준) |
즉, OAT는 단순히 빠른 RLHF 구현 도구가 아니라, LLM의 정렬 알고리즘 자체를 탐구하기 위한 실험 플랫폼(Research Framework) 으로 설계되었습니다.
LLM 정렬 실험 예제
Oat는 다양한 LLM 정렬 시나리오를 바로 실행할 수 있는 예제를 제공합니다:
-
수학적 추론 강화를 위한 Dr.GRPO (R1-Zero 스타일)
- 코드: oat/experiment/run_math_rl.py
- 실행 스크립트: examples/math_rl.sh
-
다중 턴 SFT(Multi-turn Supervised Fine-Tuning)
-
온라인 선호 학습(Active Preference Learning)
- 설명 문서: docs/alignment_as_cdb.md
이외에도 저장소의 examples/ 디렉토리에는 다양한 실험 시나리오가 포함되어 있으며, 이러한 예제들을 참고하여 각 알고리즘을 확장하거나 커스터마이징할 수 있습니다.
OAT의 실제 활용 사례
OAT는 다음과 같은 여러 연구 프로젝트의 기반 프레임워크로 활용되고 있습니다:
-
Understanding R1-Zero-Like Training: GRPO의 최적화 편향 문제를 분석
-
VeriFree: Verifier 없이 강화 학습을 수행하는 보상 모델링 연구
-
SPIRAL: 다중 에이전트 자기경쟁(Self-play) 강화학습
-
GEM: LLM 기반 에이전트 시뮬레이션을 위한 환경
라이선스
OAT 프로젝트는 Apache 2.0 라이선스 하에 공개되어 있습니다. 상업적 이용, 수정 및 재배포가 가능하지만, 저작권 표시와 라이선스 고지를 유지해야 합니다.
 OAT 관련 논문: Sample-Efficient Alignment for LLMs
OAT 관련 논문: Sample-Efficient Alignment for LLMs
 OAT 프로젝트 GitHub 저장소
OAT 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()