Ollama의 Llama 3.2 Vision 모델 추가 소개
Local LLM 도구인 Ollama에 Llama 3.2 Vision 모델이 추가되었습니다. 11B와 90B 모델 모두 추가되었으며, Meta에서 공개한 것과 동일하게 영어와 독일어, 프랑스어, 이탈리아어, 포르투칼어, 힌디어, 스페인어, 타이(Thai)어의 8개 언어를 지원합니다.
Llama 3.2 Vision 11B 모델 사용을 위해서는 최소 8GB의 VRAM이, 90B 모델 사용을 위해서는 최소 64GB의 VRAM이 필요합니다.
https://github.com/user-attachments/assets/82e25d0d-921c-4900-b78f-589c1bb86968
Ollama에서 Llama 3.2 Vision 모델을 사용하기 위해서는 다음과 같은 명령어를 실행하시면 됩니다(Ollama가 설치되어 있어야 합니다.):
# Llama 3.2 Vision 11B 모델 실행 시
ollama run llama3.2-vision
# Llama 3.2 Vision 90B 모델 실행 시
ollama run llama3.2-vision:90b
프롬프트에 이미지를 추가하기 위해서는 이미지를 터미널에 Drag&Drop을 하거나, (Linux에서) 이미지의 경로를 추가하면 됩니다.
사용 예시
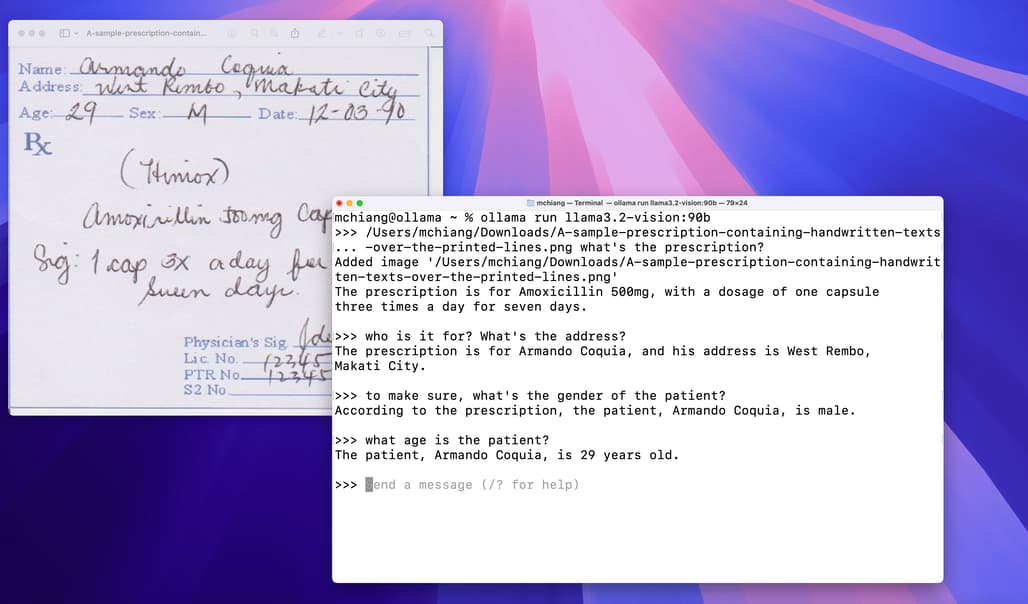
손글씨 인식 / Handwriting
광학 글자 인식 (OCR, Optical Character Recognition)
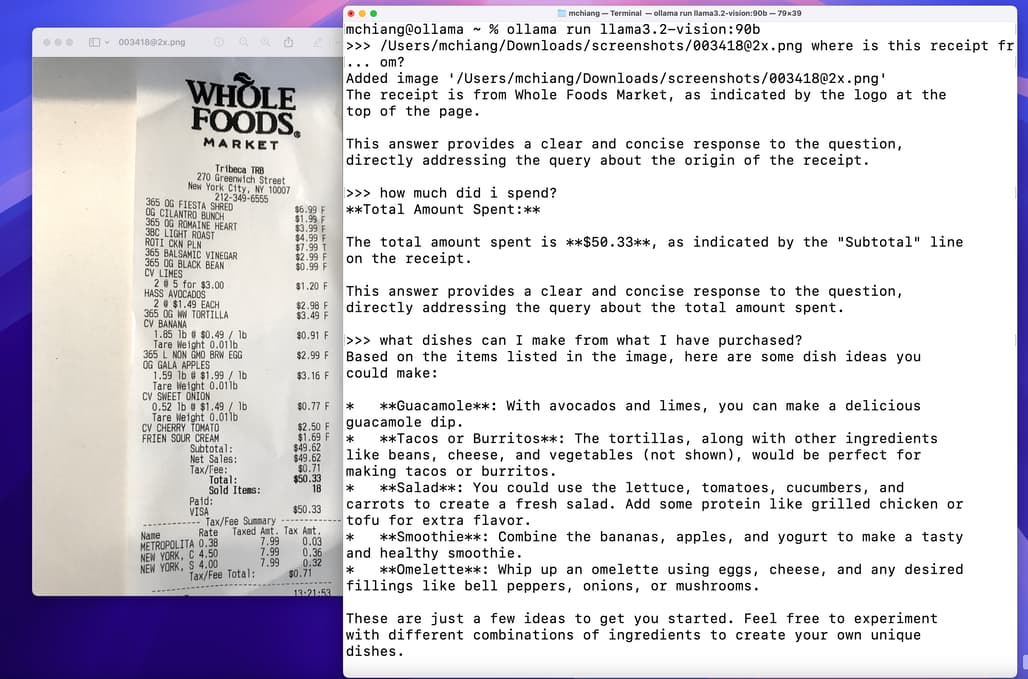
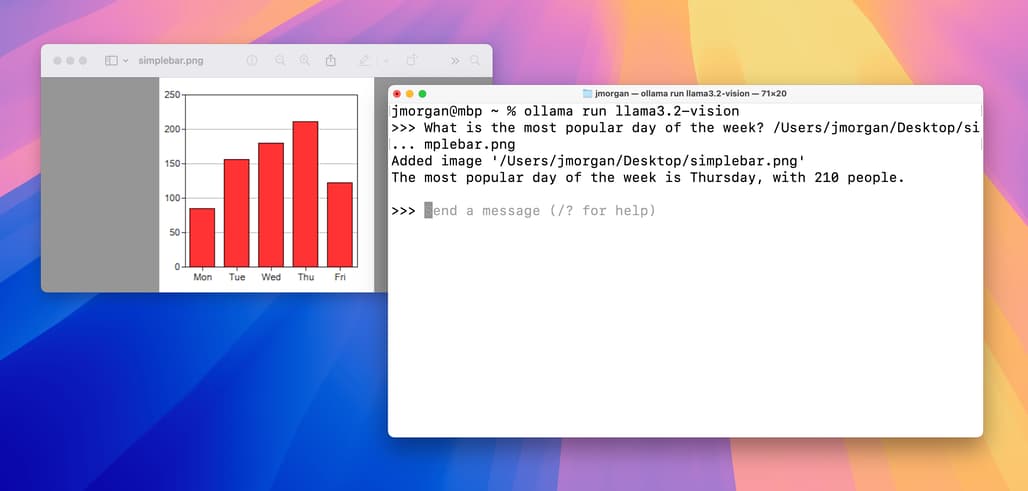
차트 및 표 / Charts & tables
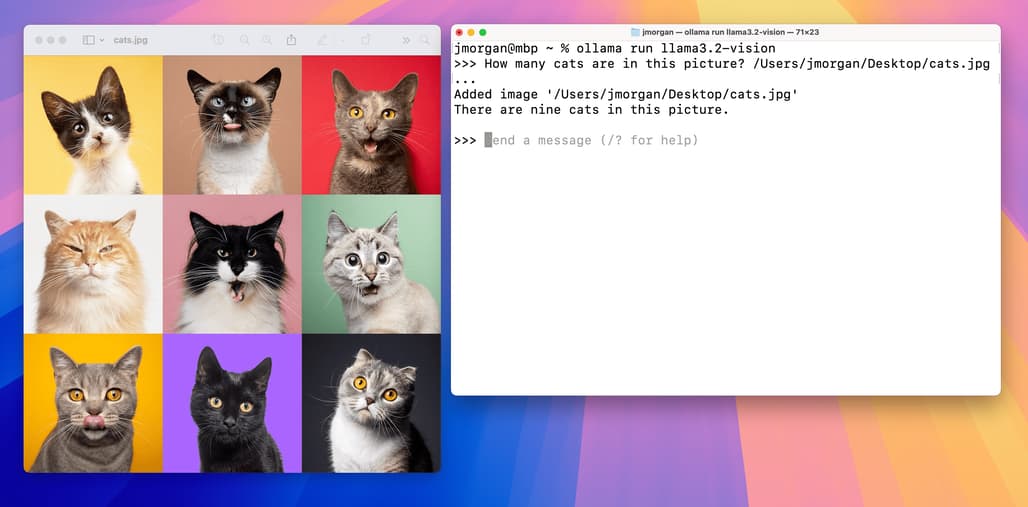
이미지 기반 질문&답변 / Image Q&A
Python / Javascript Library 사용 방법
Python Library
Ollama Python library를 사용하는 방법은 다음과 같습니다:
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'What is in this image?',
'images': ['image.jpg']
}]
)
print(response)
JavaScript Library
Ollama JavaScript library를 사용하는 방법은 다음과 같습니다:
import ollama from 'ollama'
const response = await ollama.chat({
model: 'llama3.2-vision',
messages: [{
role: 'user',
content: 'What is in this image?',
images: ['image.jpg']
}]
})
console.log(response)
cURL로 ollama API 호출하기
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2-vision",
"messages": [
{
"role": "user",
"content": "what is in this image?",
"images": ["<base64-encoded image data>"]
}
]
}'
 ollama의 공지 블로그
ollama의 공지 블로그
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()