
OmniGen 연구 개요
대규모 언어 모델(LLM, Large Language Model)은 다양한 자연어 처리(NLP, Natural Language Processing) 작업을 하나의 통합 모델로 수행하며 인공지능과의 상호작용을 혁신하였습니다. 하지만, 이미지 생성 분야는 여전히 개별 작업에 초점을 맞춘 모델들이 주를 이루며, 다양한 작업을 하나의 모델로 수행할 수 있는 통합 이미지 생성 모델은 부족한 상황입니다.
OmniGen의 연구 동기는 이러한 문제를 해결하고자 하는 것입니다. 좀 더 세부적으로는 텍스트-이미지 생성(Text-to-Image)뿐 아니라 이미지 편집(Image Editing), 주제 기반 생성(Subject-Driven Generation), 시각적 조건 기반 생성(Visual-Conditional Generation)과 같은 다양한 이미지 생성 작업(X2I, Anything-to-Image)을 하나의 프레임워크에서 처리할 수 있도록 하는 것을 목표로 합니다.
OmniGen의 주요 특징은 크게 3가지로, 각각은 통합성(Unification), 간결성(Simplicity), 지식 전이(Knowledge Transfer)입니다:
-
통합성(Unification): OmniGen은 텍스트-이미지 생성 외에도 다중 작업을 수행할 수 있는 통합 모델입니다. 추가적인 모듈 없이 텍스트와 이미지 입력을 활용하여 여러 작업을 지원합니다.
-
간결성(Simplicity): 구조가 간단하여 기존의 텍스트 인코더 없이 설계되었으며, 사용자가 명령어만으로 복잡한 작업을 수행할 수 있어 사용이 간편합니다.
-
지식 전이(Knowledge Transfer): OmniGen은 다양한 작업 간 지식을 전이하여 새로운 작업이나 도메인에서도 활용할 수 있는 가능성을 제시합니다.
OmniGen 모델 소개
OmniGen은 통합성과 간결성을 염두에 두고 설계되었습니다. 기존 확산 모델(Diffusion Model)들은 텍스트-이미지 생성(Text-to-Image)과 같은 특정 작업에 특화되어 있으며, 다양한 작업을 지원하려면 추가 모듈이나 네트워크를 필요로 합니다. OmniGen은 이러한 구조적 복잡성을 피하고, 텍스트 및 이미지 입력을 다양하게 받아들이며 복잡한 네트워크 구성을 피하는 방향으로 설계되었습니다.
OmniGen 모델 구조
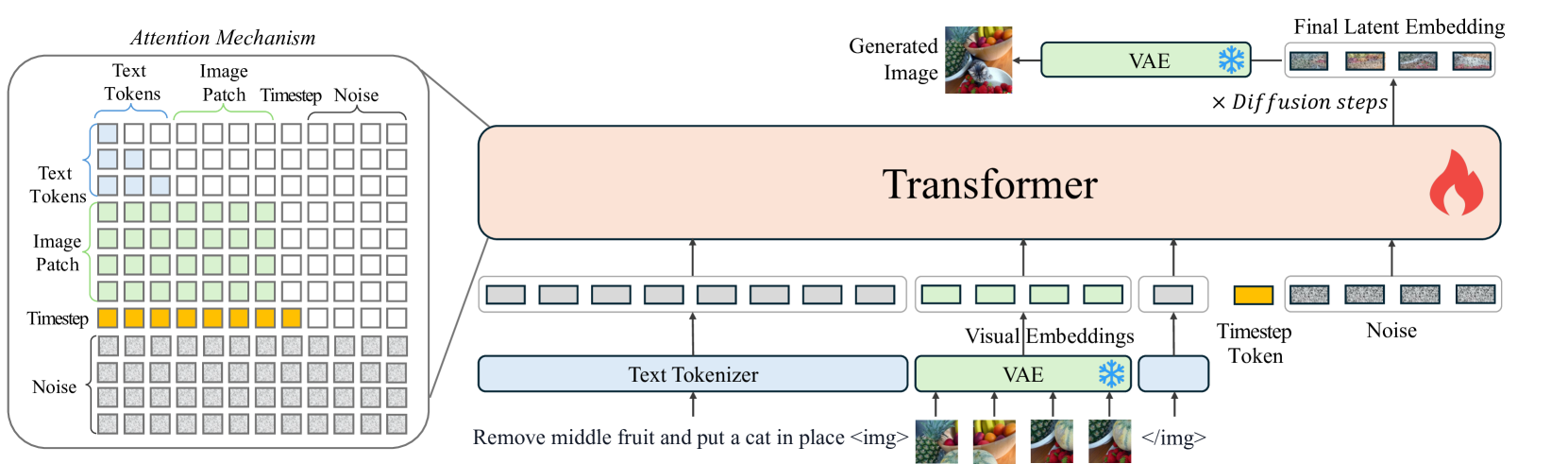
OmniGen의 모델 구조는 주로 VAE(Variational Autoencoder와 Transformer 모델로 구성되어 있습니다. VAE는 이미지에서 연속적인 시각적 특징을 추출하여 시각적 임베딩(Visual Embedding)을 출력으로 내놓고, Transformer 모델은 이미지와 텍스트 입력 조건을 기반으로 이미지를 생성합니다. 여기에서는 SDXL의 VAE를 사용하였으며, 학습 중에 고정된(freeze) 상태로 사용합니다. 또한, 트랜스포머 모델은 Phi-3를 사용하여 초기화하여 텍스트 처리 성능을 활용하였습니다.
이러한 모델 구조를 기반으로, 별도의 추가 인코더가 필요한 최신의 디퓨전 모델(State-of-the-Art Diffusion Model)들과 달리 OmniGen은 기본적으로 이미지 생성에 필요한 조건 정보(Conditional Information)을 직접 처리하여 전체 파이프라인을 크게 간소화하였습니다. 또한, 텍스트와 이미지 입력을 별도의 인코더를 통해 처리하여 모달리티별 조건(Modality Condition)들 간의 상호작용이 부족한 기존의 연구들과 달리, OmniGen은 이미지와 텍스트를 하나의 모델에서 자체적으로 인코딩합니다.
OmniGen의 입력은 텍스트와 이미지가 자유롭게 결합된 형태이며, 각각의 토크나이저를 통해 처리합니다:
먼저, 이미지 입력은 먼저 간단한 선형층(Linear Layer)을 갖는 VAE를 사용하여 잠재 표현(Latent Representation)을 추출합니다. 그런 다음, 패치(Patch)를 선형적으로 임베딩하여 일련의 시각적 토큰(Sequance of Visual Tokens)으로 평탄화(flatten)합니다. 그런 다음, Stable Diffusion 모델에서와 같이 시각적 토큰(Visual Token)에 일반적인 주파수 기반의 위치 임베딩(Standard Frequency-Based Positional Embeddings)을 적용하고, SD3와 같은 기법을 사용하여 이미지의 다양한 종횡비(ASpect Ratio)를 갖는 이미지를 처리합니다. 언급한 각 연구에 대한 자세한 내용은 아래 링크한 각 연구들을 참고해주세요:
- Stable Diffusion: [2212.09748] Scalable Diffusion Models with Transformers
- SD3: [2403.03206] Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
텍스트 입력은 Text Tokenizer를 거쳐 텍스트 토큰(Text Token)으로 변환합니다. 이 과정에서 텍스트 입력에 포함된 <img> 및 </img> 부분에 이미지 입력들을 각각 앞에서 설명한 방식으로 생성된 시각적 임베딩(Visual Embeddings)으로 캡슐화(Encapsulate)하여 삽입합니다. 또한, 마지막으로 입력 시퀀스의 끝에 타임스텝 임베딩(Timestep Embeddings)을 추가합니다.
OmniGen의 연구자들은 개별 토큰(Discrete Tokens)으로 쉽게 분해할 수 있는 텍스트 입력과 달리, 이미지 입력의 경우에는 전체적으로 모델링해야 한다고 주장하고 있습니다. 이러한 주장에 따라 OmniGen 모델에서는 위 그림의 좌측에서와 같이 어텐션 메커니즘을 구현하였습니다. LLM의 일반적인 인과적 어텐션(Causal Attention) 메커니즘을 변경하여 각 이미지 시퀀스에는 양방향 어텐션(Bidirectional Attention)을 적용합니다. 이를 통해 각 패치는 동일한 이미지 내의 다른 패치에 주의를 기울이면서, 각 이미지가 이전에 등장한 다른 이미지나 텍스트 시퀀스에만 집중할 수 있도록 보장합니다.
추론 과정에서 무작위로 가우시안 노이즈(Gaussian noise)를 샘플링하여 Flow Matching 기법에 적용하는 단계를 반복하며 최종 잠재 표현(Final Latent Representation)을 얻습니다. 이 최종 잠재 표현을 VAE에 통과시켜 이미지로 디코딩방식으로 이미지를 생성합니다. 기본적으로 추론 단계는 50으로 설정되어 있으며, 어텐션 메커니즘 덕분에 KV-Cache를 사용하여 (LLM처럼) 추론 속도를 높일 수 있습니다.
X2I 데이터셋 (X2I Dataset)
OmniGen은 여러 이미지 생성 작업을 학습하기 위해 X2I라는 이름의 데이터셋을 구축하였습니다. Anything-to-Image를 뜻하는 X2I 데이터셋에는 다음과 같이 Text-to-Image 외에도 여러 모달리티에 걸친 프롬프트(Mixed-modal Prompts)나 주제별 이미지 생성, 컴퓨터 비전 작업 등의 다양한 작업별 데이터를 대략 1억건(Approx. 0.1B) 가량 모았습니다. X2I 데이터셋의 예시는 다음과 같습니다:


(데이터셋의 작업별 구성 내용은 논문 3.1 ~ 3.3을 참고해주세요.)
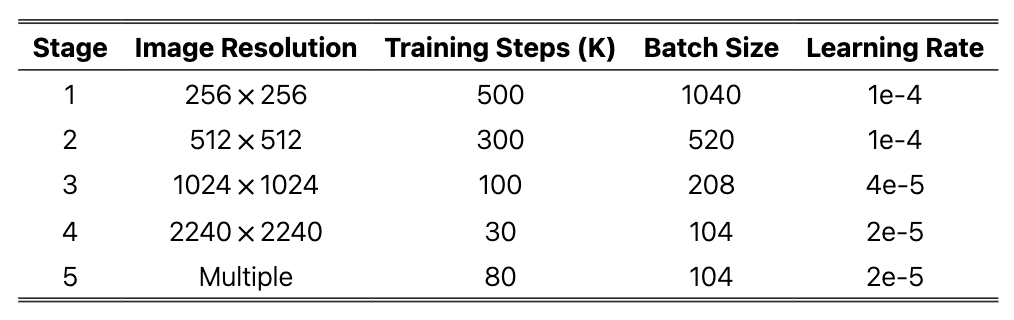
OmniGen은 이렇게 구성한 X2I 데이터셋을 사용하여 다중 작업을 학습합니다. 학습 시 목표는 평균 제곱 오차 손실을 최소화하는 것입니다. 이미지 편집 작업에서는 변화가 발생하는 영역에 높은 가중치를 부여해 모델이 수정 영역에 집중할 수 있도록 유도했습니다. 상세한 학습 단계별 정보는 다음 표를 참고해주세요:
실험 결과
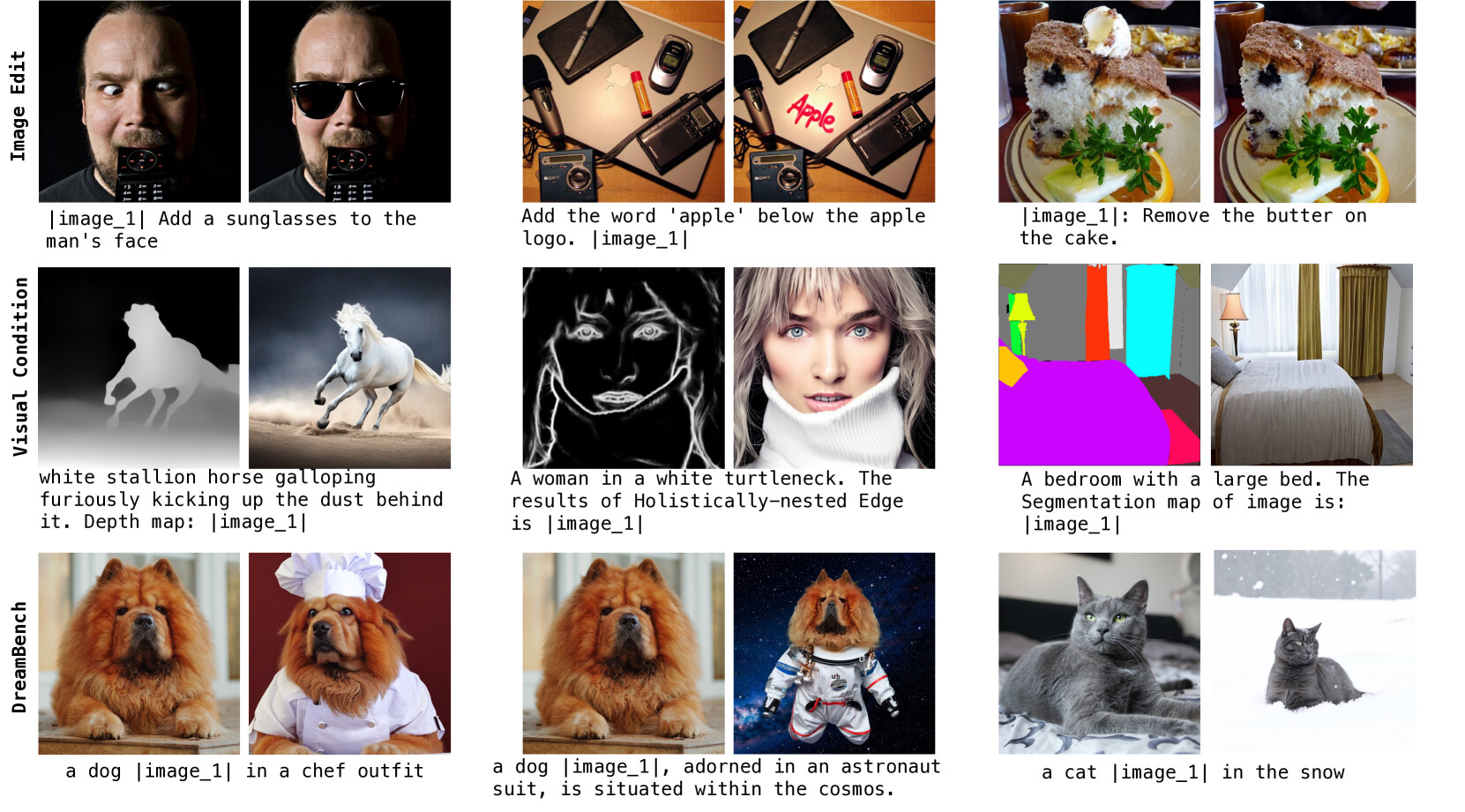
OmniGen은 텍스트 기반 이미지 생성, 이미지 편집, 주제 기반 생성 등 다양한 작업에서 기존 모델들과 비슷하거나 더 나은 성능을 보였습니다. 특히 텍스트-이미지 생성에서는 비교적 적은 파라미터와 데이터로도 우수한 성능을 발휘합니다. 생성한 이미지 예시는 다음과 같습니다:
텍스트 기반 이미지 생성(Text-to-Image) 결과 예시

주제 기반 이미지 생성(Subject-Driven Generation) 결과 예시

여러가지 이미지 생성 작업의 결과 예시
전통적인 다양한 비전 작업에서의 결과 예시
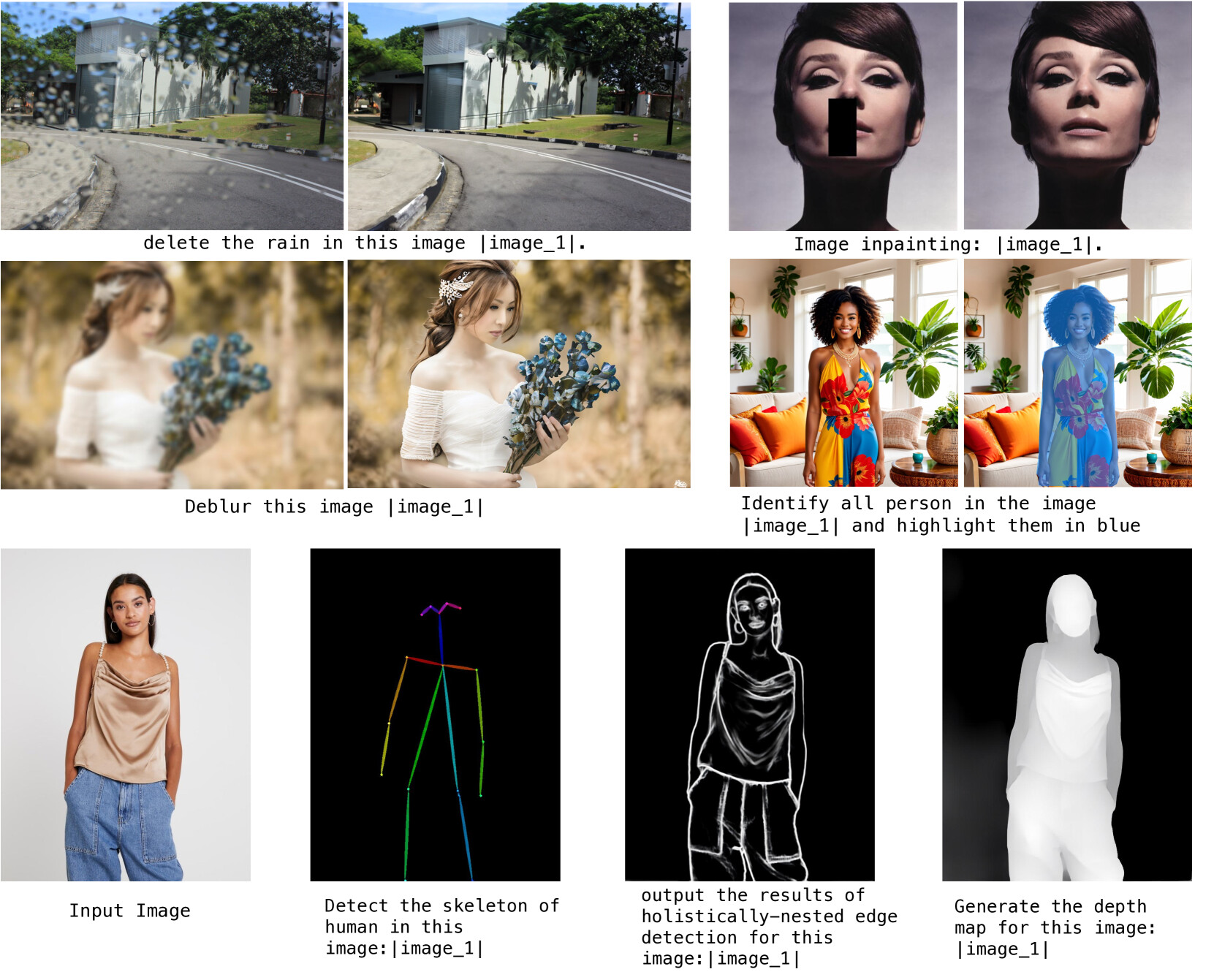
위 결과에서 볼 수 있듯, OmniGen은 기본적인 이미지 생성 외에도 이미지 복원, 인간 포즈 인식, 깊이 추정 등 고전적인 비전 작업도 잘 수행합니다. 추가 처리 과정 없이도 하나의 모델로 다양한 작업을 지원할 수 있어 워크플로우 간소화에 기여할 수 있습니다.
 OmniGen Demo
OmniGen Demo 
 OmniGen 논문 (OmniGen: Unified Image Generation)
OmniGen 논문 (OmniGen: Unified Image Generation)
 OmniGen GitHub 저장소
OmniGen GitHub 저장소
OmniGen 모델 파인튜닝 코드 및 가이드를 함께 제공합니다
OmniGen 모델
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()