Open Knowledge Format(OKF) 소개
파운데이션 모델(Foundation Model)의 성능이 빠르게 좋아지고 있지만, 정작 현장에서 모델을 가로막는 것은 모델 자체의 한계가 아니라 관련 맥락(context)의 부재인 경우가 많습니다. 모델은 코드를 작성하고 문서를 요약하고 데이터셋을 분석할 수 있지만, 정확하고 실행 가능한 결과를 내려면 결국 "올바른 정보"가 필요합니다. 특히 여러 도구와 데이터 소스를 넘나드는 에이전트(Agent) 시스템을 만들 때 이 문제는 더 두드러집니다. 테이블의 스키마, 우리 회사가 정의한 지표의 의미, 장애 대응 런북, 두 시스템 사이의 조인 경로 같은 지식은 대부분 조직 내부에 흩어져 있고, 어느 것도 다른 시스템으로 쉽게 옮겨지지 않습니다.
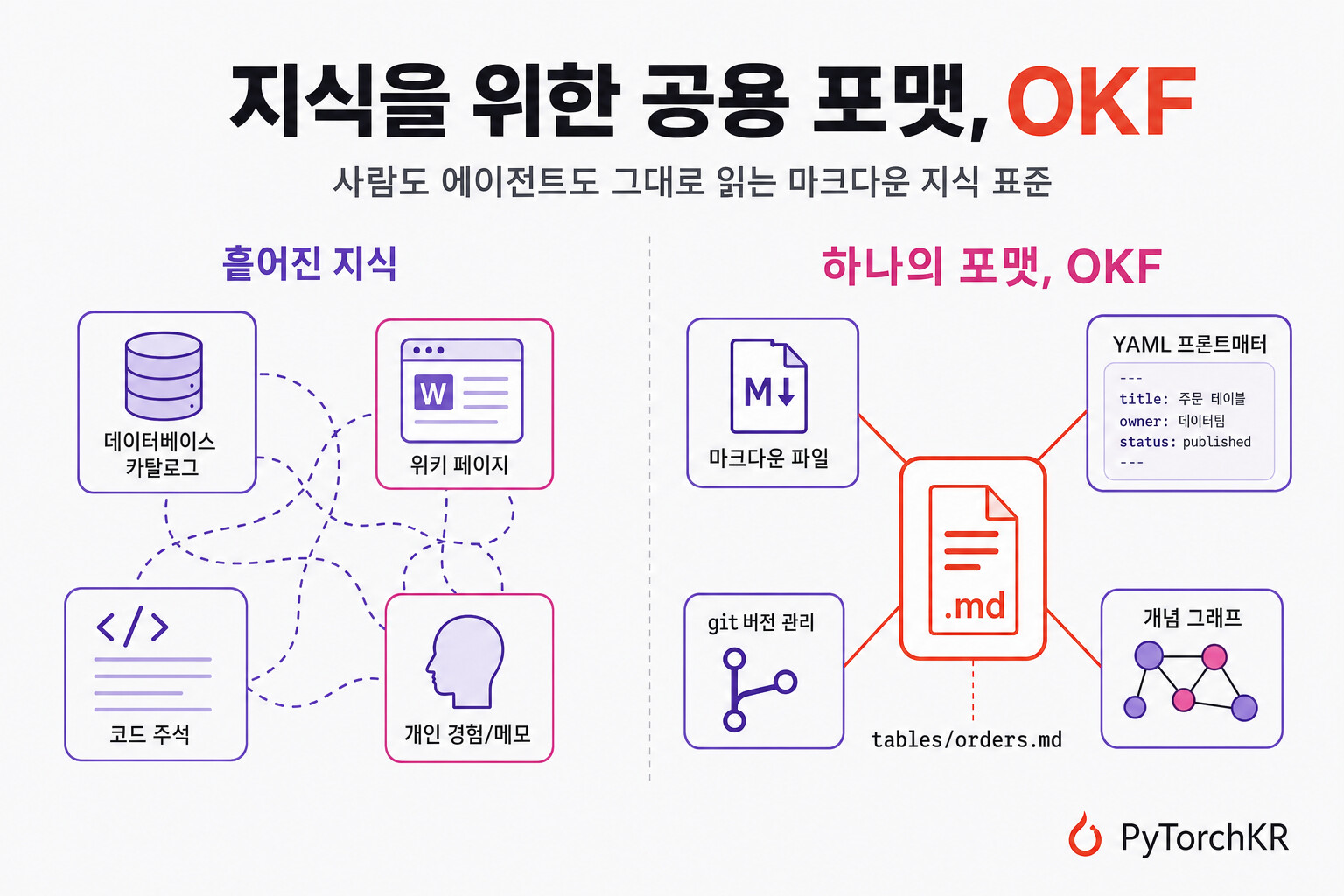
Google Cloud 데이터 클라우드 팀이 공개한 Open Knowledge Format(OKF) 은 바로 이 지점을 겨냥한 개방형 명세(open specification)입니다. OKF는 지난 1년 사이 여러 이름으로 반복해서 등장한 LLM 위키(LLM Wiki) 패턴을, 누구나 생산하고 누구나 소비할 수 있는 이식 가능하고 상호운용 가능한(interoperable) 포맷으로 형식화합니다. 특정 벤더에 묶이지 않고, 사람과 에이전트가 모두 읽을 수 있는 방식으로 현대 AI 시스템이 필요로 하는 메타데이터, 맥락, 큐레이션된 지식을 표현하는 것이 목표입니다.
핵심은 의외로 단순합니다. 현재 공개된 OKF v0.1 은 지식을 "YAML 프론트매터(frontmatter)가 붙은 마크다운 파일들의 디렉토리" 로 표현하고, 서로 다른 생산자가 작성한 위키를 서로 다른 에이전트가 번역 없이 소비할 수 있도록 하는 소수의 합의된 관례(convention)만을 정의합니다. 복잡한 압축 스킴도, 새로운 런타임도, 필수 SDK도 없습니다. OKF 문서 묶음은 그저 다음과 같습니다.
- 그냥 마크다운(Just markdown): 어떤 에디터에서도 읽히고, GitHub에서 그대로 렌더링되며, 어떤 검색 도구로도 색인할 수 있습니다.
- 그냥 파일(Just files): tarball로 배포하거나, 아무 git 저장소에 호스팅하거나, 어떤 파일시스템에든 마운트할 수 있습니다.
- 그냥 YAML 프론트매터(Just YAML frontmatter): 쿼리 가능해야 하는 소수의 구조화된 필드(type, title, description, resource, tags, timestamp)만을 위한 것입니다.
Obsidian, Notion, Hugo 같은 도구나 지난 1년간 쏟아진 LLM 위키 패턴을 써본 적이 있다면 OKF의 형태가 익숙하게 느껴질 것입니다. OKF는 이런 패턴들을 상호운용 가능하게 만드는 데 필요한 최소한의 관례만을 형식화한 것입니다.
흩어진 지식의 문제: 파편화된 컨텍스트 풍경
대부분의 조직에서 파운데이션 모델이 사용하는 정보는 압도적으로 내부 지식입니다. 테이블의 스키마, 비즈니스가 정의한 지표의 의미, 장애 발생 시의 런북(runbook), 두 시스템 사이의 조인 경로, 오래된 API의 폐기(deprecation) 공지 같은 것들이죠. 그런데 오늘날 이 "지식의 원자(atoms of knowledge)" 들은 서로 호환되지 않는 매우 파편화된 시스템에 나뉘어 살고 있습니다.
- 각자의 API를 가진 메타데이터 카탈로그
- 위키, 서드파티 시스템, 공유 드라이브
- 코드 주석, 독스트링(docstring), 노트북 셀
- 그리고 몇몇 시니어 엔지니어의 머릿속
AI 에이전트가 "우리 이벤트 스트림에서 주간 활성 사용자(WAU)를 어떻게 계산하지?" 라는 질문에 답하려면, 이렇게 흩어지고 상호 호환되지 않는 표면들로부터 답을 조립해야 합니다. 모든 벤더가 자기만의 카탈로그, 자기만의 SDK, 자기만의 지식 그래프(Knowledge Graph) 스키마를 제공하고, 그 어떤 지식도 제품이나 조직을 넘어 손쉽게 이식되지 않습니다.
그 결과는 명백한 낭비입니다. 모든 에이전트 개발자가 똑같은 "맥락 조립(context-assembly)" 문제를 처음부터 다시 풀고 있고, 모든 카탈로그 벤더가 똑같은 데이터 모델을 재발명하고 있으며, 지식 자체는 그것을 만들어낸 표면 뒤에 갇혀 있습니다.
살아있는 위키로서의 지식, 그리고 Karpathy의 LLM Wiki
개발 팀들이 AI 에이전트를 만드는 방식이 바뀌고 있습니다. 모델이 똑같은 문서에서 똑같은 사실을 반복해서 검색하게 하는 대신, 시간이 갈수록 더 유용해지는 공유 마크다운 라이브러리를 에이전트에게 쥐여 주는 방향입니다. 이렇게 하면 에이전트가 자기 파일을 읽고 갱신하는 잡일(drudgery)을 떠맡고, 팀은 콘텐츠를 코드처럼 큐레이션하고 관리하게 됩니다.
이 아이디어를 가장 선명하게 표현한 사람이 저명한 AI 연구자이자 교육자인 Andrej Karpathy입니다. 그는 자신의 LLM Wiki gist에서 이렇게 적었습니다.
"LLM은 지루해하지 않고, 상호 참조(cross-reference)를 갱신하는 것을 잊지 않으며, 한 번에 15개 파일을 건드릴 수 있다."
"LLMs don't get bored, don't forget to update a cross-reference, and can touch 15 files in one pass."
사람이 개인 위키를 끝내 포기하게 만드는 그 귀찮은 장부 정리(bookkeeping)야말로, LLM이 가장 잘하는 일이라는 통찰입니다. 실제로 이 "위키로서의 지식(knowledge-as-Wiki)" 패턴은 서로 다른 이름으로 계속 다시 등장하고 있습니다. 코딩 에이전트에 연결된 Obsidian 볼트(vault), 프로젝트마다 놓이는 AGENTS.md / CLAUDE.md 류의 관례 파일, 에이전트가 실제 작업 전에 참조하는 index.md 와 log.md 아티팩트로 가득한 저장소, 데이터 팀 내부의 "코드로서의 메타데이터(metadata as code)" 저장소 등이 그것입니다.
이 패턴은 매력적이고 강력하지만, 문제는 모든 사례가 제각각 따로(bespoke) 라는 점입니다. Karpathy의 위키와 우리 팀의 위키, 그리고 벤더의 카탈로그 내보내기 결과물은 모두 비슷해 보이지만(마크다운, 프론트매터, 상호 링크), 그 어느 것도 의도적으로 서로 협력하도록 설계되지 않았습니다. 모든 문서가 어떤 필드를 담아야 하는지, 어떤 파일명이 무엇을 뜻하는지에 대한 합의된 답이 없습니다. 그래서 위키에 담긴 지식은 원래의 팀 안에 갇혀 있고, 새로운 에이전트를 만들 때마다 똑같은 노력이 중복됩니다.
또 하나의 서비스가 아니라, 포맷이 필요하다
이 문제의 해답은 또 하나의 지식 서비스가 아닙니다. 필요한 것은 포맷(format), 즉 지식을 표현하는 방식 그 자체입니다. OKF가 지향하는 포맷의 조건은 다음과 같습니다.
- 누구나 SDK 없이 생산할 수 있어야 한다
- 누구나 통합 작업 없이 소비할 수 있어야 한다
- 시스템, 조직, 도구 사이를 옮겨 다녀도 살아남아야 한다
- 그것이 설명하는 코드 옆에서 버전 관리 안에 함께 살아야 한다
- 사람이 읽을 수 있고 에이전트가 파싱할 수 있어야 한다(같은 파일, 번역 계층 없음)
설계상 OKF가 바로 그 포맷입니다. 명세 문서 자체가 "cat 으로 파일을 읽을 수 있으면 OKF를 읽을 수 있고, git clone 으로 저장소를 받을 수 있으면 OKF를 배포할 수 있다" 고 선언할 만큼, 진입 장벽을 의도적으로 0에 가깝게 낮췄습니다.
OKF의 작동 방식: 한 화면에 담기는 설계
OKF의 전체 v0.1 명세는 적합성 기준, 상호 링크 규칙, 소수의 예약 파일명까지 포함해 한 페이지에 들어갑니다. 핵심 구조를 차례로 살펴보겠습니다.
번들(Bundle)과 개념(Concept)
OKF 번들(bundle) 은 마크다운 파일들의 디렉토리이며, 배포의 단위입니다. 각 파일은 하나의 개념(concept) 을 나타냅니다. 개념은 테이블, 데이터셋, 지표, 플레이북, 런북, API처럼 포착하고 싶은 그 무엇이든 될 수 있습니다. 유형(tangible asset)이 있는 자산일 수도 있고, 지표나 비즈니스 프로세스 같은 추상적 아이디어일 수도 있습니다.
여기서 가장 중요한 규칙은 파일 경로가 곧 개념의 정체성(identity) 이라는 점입니다. 개념 ID는 번들 안에서 그 파일의 경로에서 .md 확장자를 뗀 것입니다. 예를 들어 tables/users.md 의 개념 ID는 tables/users 가 됩니다.
번들의 디렉토리 구조는 도메인과 독립적입니다. 생산자는 포착하려는 지식에 맞게 자유롭게 개념을 조직하면 됩니다.
path/to/bundle/
├── index.md # Optional. Directory listing for progressive disclosure.
├── log.md # Optional. Chronological history of updates.
├── <concept>.md # A concept at the bundle root.
└── <subdir>/ # Subdirectories organize concepts into groups.
├── index.md
├── <concept>.md
└── <subsubdir>/
└── …
번들은 git 저장소(이력, 기여자 정보, diff를 제공하므로 권장), 디렉토리를 압축한 tarball/zip, 또는 더 큰 저장소 안의 하위 디렉토리 형태로 배포될 수 있습니다.
개념 문서: 프론트매터와 본문
모든 개념은 UTF-8 마크다운 파일이며, 두 부분으로 구성됩니다. 하나는 파일 맨 위에 --- 로 구분되는 YAML 프론트매터 블록, 다른 하나는 그 뒤에 오는 자유 형식의 마크다운 본문(body) 입니다.
프론트매터에서 유일하게 필수인 필드는 type 하나입니다. 나머지는 모두 권장 사항(recommended)이며 우선순위 순으로 title, description, resource, tags, timestamp 가 있습니다.
---
type: BigQuery Table # REQUIRED
title: Customer Orders # Recommended: human-readable display name
description: One row per completed customer order across all channels.
resource: https://console.cloud.google.com/bigquery?p=acme&d=sales&t=orders
tags: [sales, orders, revenue] # Optional
timestamp: 2026-05-28T14:30:00Z # Optional, last-modified time (ISO 8601)
# … other producer-defined key/value pairs
---
각 필드의 의미는 다음과 같습니다. type 은 개념의 종류를 식별하는 짧은 문자열로, 소비자가 라우팅, 필터링, 표현에 사용합니다. BigQuery Table, API Endpoint, Metric, Playbook, Reference 같은 값을 쓸 수 있는데, 중요한 것은 타입 값이 중앙에 등록되지 않는다 는 점입니다. 생산자는 설명적이고 자기 설명적인 값을 고르면 되고, 소비자는 모르는 타입을 만나도 우아하게(일반 개념으로 취급) 처리해야 합니다.
resource 는 개념이 설명하는 실제 자산을 고유하게 식별하는 URI입니다. 추상적 아이디어를 설명하는 개념에는 없을 수 있습니다. 생산자는 그 외 어떤 키든 추가할 수 있으며(extensions), 소비자는 모르는 키를 만나도 문서를 거부해서는 안 되고 라운드트립(round-trip) 시 보존해야 합니다.
본문은 표준 마크다운입니다. 생산자는 자유로운 산문보다 헤딩, 리스트, 표, 코드 블록 같은 구조적 마크다운을 선호해야 합니다. 구조가 사람의 읽기와 에이전트의 검색(retrieval) 모두를 돕기 때문입니다. 필수 본문 섹션은 없지만, 다음 세 헤딩은 관례적(conventional) 의미를 가지며 해당하는 경우 사용하도록 권장됩니다.
| 헤딩 | 용도 |
|---|---|
# Schema |
자산의 컬럼/필드에 대한 구조적 설명 |
# Examples |
구체적 사용 예시, 주로 코드 블록 |
# Citations |
본문의 주장을 뒷받침하는 외부 출처 |
다음은 자원에 묶인(bound to a resource) 개념의 완전한 예시입니다.
---
type: BigQuery Table
title: Customer Orders
description: One row per completed customer order across all channels.
resource: https://console.cloud.google.com/bigquery?p=acme&d=sales&t=orders
tags: [sales, orders, revenue]
timestamp: 2026-05-28T14:30:00Z
---
# Schema
| Column | Type | Description |
|---------------|-----------|------------------------------------------|
| `order_id` | STRING | Globally unique order identifier. |
| `customer_id` | STRING | Foreign key into [customers](/tables/customers.md). |
| `total_usd` | NUMERIC | Order total in US dollars. |
| `placed_at` | TIMESTAMP | When the customer submitted the order. |
# Joins
Joined with [customers](/tables/customers.md) on `customer_id`.
# Citations
[1] [BigQuery table schema](https://console.cloud.google.com/bigquery?p=acme&d=sales&t=orders)
개념들을 잇는 상호 링크(Cross-linking)
개념은 일반적인 마크다운 링크로 다른 개념을 가리킬 수 있습니다. 이렇게 하면 디렉토리는 파일 시스템이 암시하는 부모/자식 링크보다 훨씬 풍부한 관계의 그래프(graph) 가 됩니다. 링크 형태는 두 가지입니다.
절대(번들 기준) 링크는 / 로 시작하며 번들 루트를 기준으로 해석됩니다. 문서가 하위 디렉토리 안에서 이동해도 안정적이기 때문에 권장되는 형태입니다.
See the [customers table](/tables/customers.md) for the join key.
상대 링크는 표준 마크다운 상대 경로를 사용합니다.
See the [neighboring concept](./other.md).
링크의 의미론에서 흥미로운 설계 결정은, 개념 A에서 B로의 링크가 관계(relationship) 를 주장할 뿐, 그 관계의 구체적 종류(부모/자식, 참조, 조인, 의존 등)는 링크 자체가 아니라 주변 산문이 전달한다 는 점입니다. 그래프 뷰를 만드는 소비자는 보통 모든 링크를 타입 없는(untyped) 관계의 방향성 간선으로 취급합니다. 또한 소비자는 깨진 링크를 관용해야 합니다. 번들 안에 대상이 존재하지 않는 링크는 잘못된 것이 아니라, 아직 작성되지 않은 지식을 나타낼 수도 있기 때문입니다.
인덱스 파일과 로그 파일
index.md 파일은 번들 루트를 포함해 어느 디렉토리에든 놓일 수 있습니다. 디렉토리의 내용물을 열거하여 점진적 공개(progressive disclosure) 를 지원합니다. 즉, 사람이나 에이전트가 개별 문서를 열기 전에 무엇이 있는지 먼저 파악하게 해줍니다. 인덱스 파일에는 프론트매터가 없으며, 각 섹션이 헤딩 아래 개념들을 묶는 형태입니다.
# Section / Group Heading
* [Title 1](relative-url-1) - short description of item 1
* [Title 2](relative-url-2) - short description of item 2
# Another Section
* [Subdirectory](subdir/) - short description of the subdirectory
log.md 파일은 계층의 어느 수준에든 놓여 해당 범위의 변경 이력을 기록할 수 있습니다. 최신 항목이 위로 오는 날짜별 평탄 목록 형태이며, 날짜 헤딩은 반드시 ISO 8601 YYYY-MM-DD 형식을 써야 합니다.
# Directory Update Log
## 2026-05-22
* **Update**: Added new BigQuery table reference for [Customer Metrics](/tables/customer-metrics.md).
* **Creation**: Established the [Dataplex Playbook](/playbooks/dataplex.md).
## 2026-05-15
* **Initialization**: Created foundational directory structure.
여기서 index.md 와 log.md 는 개념 문서로 사용할 수 없는 예약 파일명(reserved filenames) 입니다. 그 외 모든 .md 파일은 개념 문서로 취급됩니다.
출처를 밝히는 인용(Citations)
개념 본문이 외부 자료에서 가져온 주장을 담을 때, 그 출처는 문서 하단의 # Citations 헤딩 아래에 번호를 붙여 나열하도록 권장됩니다. 인용 링크는 절대 URL이거나, 번들 기준 경로이거나, 외부 자료를 일급 OKF 개념으로 미러링한 references/ 하위 디렉토리로의 경로일 수 있습니다.
# Citations
[1] [BigQuery public dataset announcement](https://cloud.google.com/blog/products/data-analytics/...)
[2] [Internal data quality runbook](https://wiki.acme.internal/data/quality)
설계를 떠받치는 세 가지 원칙
OKF의 명세를 읽다 보면, 이 포맷이 의도적으로 "적게 정의하기"를 택했다는 점이 분명해집니다. 그 철학은 세 가지 원칙으로 요약됩니다.
최소한의 주관 (Minimally opinionated): OKF가 모든 개념에 요구하는 것은 정확히 한 가지, type 필드뿐입니다. 어떤 타입이 존재하는지, 어떤 필드를 더 넣을지, 본문에 어떤 섹션을 둘지는 전부 생산자에게 맡깁니다. 명세는 콘텐츠 모델이 아니라 상호운용의 표면(interoperability surface) 만을 정의합니다.
생산자/소비자 독립성 (Producer/consumer independence): OKF는 지식을 쓰는 쪽과 읽는 쪽을 깔끔하게 분리합니다. 사람이 손으로 쓴 번들을 AI 에이전트가 소비할 수 있고, 메타데이터 내보내기 파이프라인이 생성한 번들을 시각화 도구로 둘러볼 수 있으며, 한 LLM이 합성한 번들을 다른 LLM이 쿼리할 수 있습니다. 포맷이 곧 계약(contract)이고, 양 끝의 도구는 독립적으로 교체 가능합니다.
플랫폼이 아니라 포맷 (Format, not platform): OKF는 특정 클라우드, 데이터베이스, 모델 제공자, 에이전트 프레임워크에 묶이지 않습니다. 읽고 쓰고 서빙하기 위해 독점 계정이나 SDK를 요구하지 않습니다. 지식 포맷의 가치는 누가 소유하느냐가 아니라 얼마나 많은 당사자가 그 언어를 말하느냐에서 나오기 때문에, 처음부터 개방형 표준으로 공개되었습니다.
이 세 원칙은 명세의 적합성(Conformance) 규칙에서도 그대로 드러납니다. 번들이 OKF v0.1에 적합하려면 (1) 모든 비예약 .md 파일이 파싱 가능한 YAML 프론트매터 블록을 담고, (2) 모든 프론트매터가 비어 있지 않은 type 필드를 가지며, (3) 예약 파일명이 있을 경우 정해진 구조를 따르면 됩니다. 그 외 모든 제약은 소비자가 느슨한 가이드로 취급해야 합니다. 특히 소비자는 선택적 필드 누락, 모르는 type 값, 모르는 추가 키, 깨진 링크, index.md 부재를 이유로 번들을 거부해서는 안 됩니다. 이 관대한 소비 모델은 의도적입니다. 번들이 성장하고 리팩토링되고 부분적으로 에이전트에 의해 생성되는 동안에도 OKF가 계속 쓸모 있게 남도록 하기 위함입니다.
명세와 함께 공개된 레퍼런스 구현
Google은 포맷을 구체적으로 만들기 위해 생산자 측과 소비자 측 양쪽에 레퍼런스 구현(reference implementation) 을 함께 공개했습니다. 이들은 모두 개념 증명(proof of concept) 으로, 포맷이 특정 도구를 요구하지 않는다는 것을 보여주기 위한 사례입니다.
- 인리치먼트 에이전트(enrichment agent): BigQuery 데이터셋을 순회하며 모든 테이블과 뷰에 대해 OKF 개념 문서 초안을 작성하고, 두 번째 LLM 패스로 권위 있는 문서를 크롤링해 각 개념을 인용, 스키마, 조인 경로로 보강합니다.
- 정적 HTML 시각화 도구(static HTML visualizer): 어떤 OKF 번들이든 단 하나의 자기완결적(self-contained) 파일 안에서 인터랙티브한 그래프 뷰로 바꿔 줍니다. 백엔드도, 보는 쪽의 설치도 없고, 데이터가 페이지 밖으로 나가지 않습니다.
- 바로 둘러볼 수 있는 샘플 번들 3종: 레퍼런스 에이전트가 생성해 저장소에 커밋한 살아있는 예시로, GA4 이커머스 데이터셋, Stack Overflow 공개 데이터셋, Bitcoin 공개 데이터셋을 포함합니다.
여기서 강조할 점은 이 도구들이 의도적으로 개념 증명에 머문다는 것입니다. 에이전트는 OKF를 생산하는 하나의 방법을 보여줄 뿐, 포맷 자체는 특정 에이전트 프레임워크나 LLM을 요구하지 않습니다. 시각화 도구는 OKF를 소비하는 하나의 방법을 보여줄 뿐, 포맷 자체는 HTML이나 그래프 뷰를 요구하지 않습니다. Google은 생산자와 소비자 생태계가 자신들이 공개한 것을 훨씬 넘어서 자라기를 기대하고 또 원한다고 밝혔습니다. 실제로 Google Cloud의 Knowledge Catalog 역시 Open Knowledge Format을 수집(ingest)해 자사 에이전트에게 서빙할 수 있도록 업데이트되었습니다.
OKF 더 알아보기
Open Knowledge Format 발표 블로그 - "How the Open Knowledge Format can improve data sharing"
OKF v0.1 명세 (SPEC.md)
knowledge-catalog GitHub 저장소 (명세, 샘플 번들, 레퍼런스 구현)
Andrej Karpathy의 LLM Wiki gist
다른 포맷과의 관계: 무엇이 다른가
OKF는 일부러 여러 기존 패턴과 가깝게 설계되었습니다. 마크다운과 프론트매터를 에이전트가 읽을 수 있는 지식 베이스로 쓰는 LLM 위키 저장소, 계층적 마크다운과 상호 링크를 쓰는 Obsidian이나 Notion 같은 개인 지식 관리 도구, 카탈로그 메타데이터를 별도 레지스트리가 아니라 소스 코드 옆에 저장하는 "코드로서의 메타데이터" 접근이 그것입니다.
| 구분 | LLM 위키 / Obsidian / Notion | 벤더 메타데이터 카탈로그 | Open Knowledge Format |
|---|---|---|---|
| 형태 | 마크다운 + 프론트매터 | 독점 DB + API | 마크다운 + YAML 프론트매터 |
| 상호운용성 | 도구마다 제각각 | 벤더 종속 | 명세로 표준화 |
| 필수 SDK | 없음(도구 종속) | 있음 | 없음 |
| 버전 관리 | 가능 | 보통 불가 | git 친화적(diff 가능) |
| 표준화 여부 | 비공식 관례 | 비공개 스키마 | 공개 명세(v0.1) |
OKF가 이들과 다른 핵심은 "명세되어 있다(specified)" 는 점입니다. 도구를 강제하지 않으면서, 상호운용에 필요한 최소한의 규칙만을 못 박았습니다. OKF는 Avro, Protobuf, OpenAPI 같은 도메인 특화 스키마를 대체하려는 것이 아니라 참조(reference) 합니다. 즉 OKF는 이런 스키마를 포섭하지 않고, 자신의 개념 문서에서 그것들을 가리킬 뿐입니다.
흥미롭게도 OKF는 에이전트에게 컨텍스트를 공급하는 더 넓은 흐름의 일부로 읽을 수 있습니다. 도구 호출과 컨텍스트 연결을 표준화하려는 Model Context Protocol(MCP)이 "에이전트가 어떻게 외부 시스템과 대화하는가" 를 다룬다면, OKF는 "그 컨텍스트가 되는 지식을 어떤 포맷으로 표현하고 교환하는가" 를 다룹니다. 두 접근은 경쟁하기보다 보완적입니다.
버전 관리와 향후 전망
OKF v0.1은 완성된 표준이 아니라 출발점입니다. 더 많은 생산자와 소비자가 등장하고, 에이전트가 실무에서 실제로 어떤 지식 표현을 필요로 하는지 함께 배워 나가면서 포맷이 진화할 것입니다. 향후 개정은 <major>.<minor> 형식으로 버전이 매겨지며, 마이너 버전 올림은 하위 호환되는 추가(새 선택 필드, 새 관례적 섹션 헤딩)를 도입하고, 메이저 버전 올림은 호환성을 깨는 변경(필수 필드 이름 변경, 예약 파일명 변경 등)을 할 수 있습니다. 번들은 루트 index.md 의 프론트매터에 okf_version: "0.1" 을 넣어 자신이 목표하는 OKF 버전을 선언할 수 있습니다.
Google은 OKF를 시작하기 위한 구체적인 행동을 다음과 같이 제안합니다.
- 명세를 읽어 보세요 (짧습니다)
- 여러분의 소스 시스템, 데이터베이스, 문서 사이트를 위한 생산자(producer)를 작성해 보세요
- 뷰어, 검색 색인, 번들 위에서 추론하는 에이전트 같은 소비자(consumer)를 작성해 보세요
- 자신의 데이터에 레퍼런스 구현을 시험해 보세요
- 명세는 버전 관리되고 하위 호환 성장을 명시적으로 설계했으므로, 이슈를 열거나 PR을 보내거나 확장을 제안해 보세요
결국 OKF가 던지는 메시지는 분명합니다. 기여물은 도구가 아니라 포맷 그 자체이며, 함께 공개된 도구들은 그 포맷을 현실로 만들고 시도 비용을 낮추기 위해 존재한다는 것입니다. 오늘 여러분의 지식이 어떤 형태를 띠고 있든, OKF는 내일 그것을 교환할 수 있는 공용어(lingua franca) 가 되는 것을 목표로 합니다.
 How the Open Knowledge Format can improve data sharing 소개 블로그
How the Open Knowledge Format can improve data sharing 소개 블로그
 knowledge-catalog GitHub 저장소
knowledge-catalog GitHub 저장소
더 읽어보기
-
Google, Context Engineering을 위한 세션(Session)과 메모리(Memory)의 개념 및 구현 전략에 대한 기술 백서 공개 [영문/PDF/72p]
-
[Deep Research] Model Context Protocol(MCP) 개념 및 이해를 위한 학습 자료
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()