
HealthBench 소개
OpenAI가 최근 공개한 HealthBench는 의료 분야에서의 AI 성능을 체계적으로 평가하기 위한 새로운 벤치마크입니다. 단순한 퀴즈 풀이 방식이 아니라, 실제 임상 상황을 반영한 대화 기반의 평가를 통해 AI의 실질적인 도움 가능성을 점검합니다. 의료 전문가 262명이 직접 제작에 참여한 이 벤치마크는, 현장감 있는 평가를 원하는 AI 개발자라면 반드시 살펴봐야 할 리소스입니다.
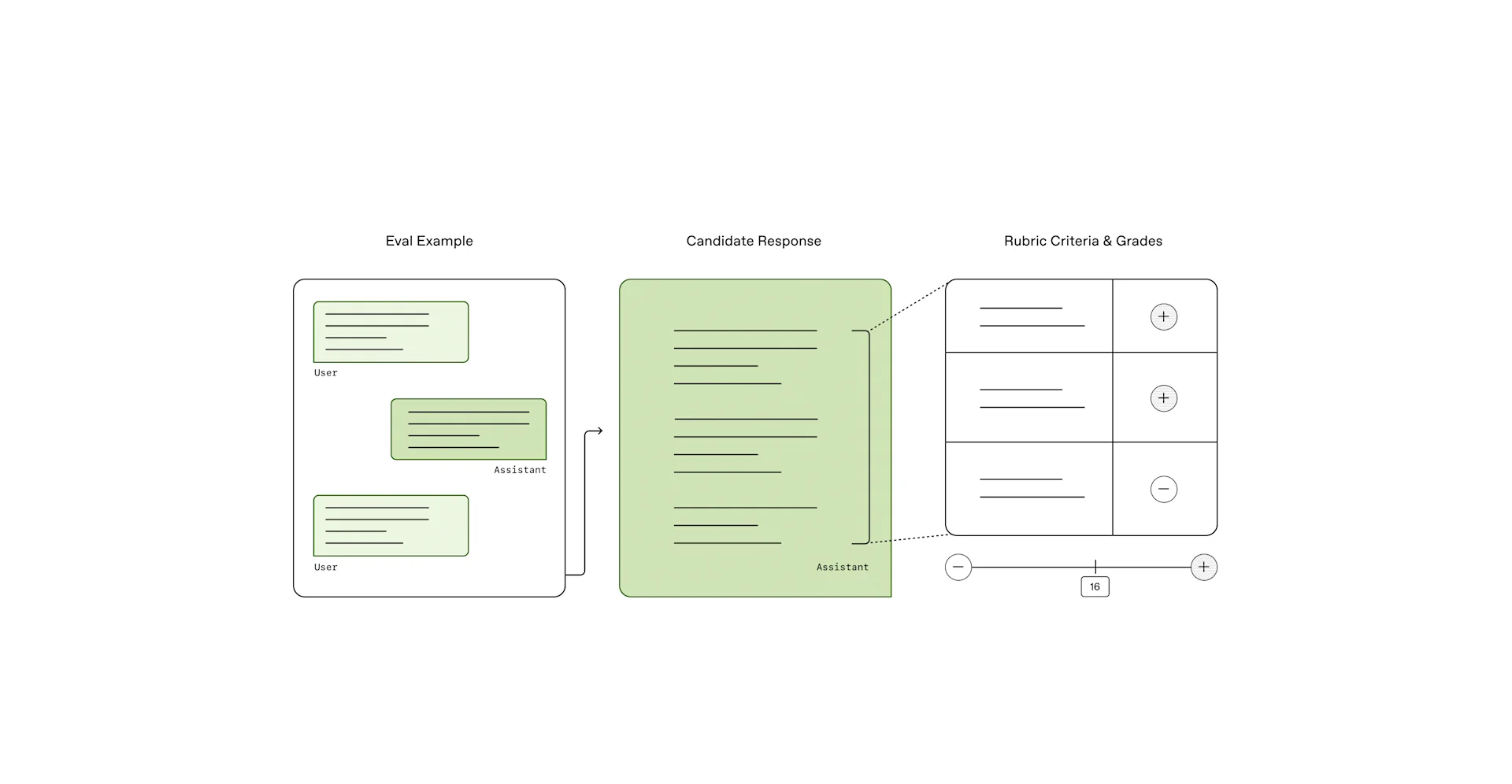
HealthBench는 의료 분야에서의 AI 시스템 성능을 평가하기 위해 OpenAI가 새롭게 제안한 벤치마크입니다. 기존의 평가 방법은 종종 실제 상황을 반영하지 못하거나 전문가 의견과 일치하지 않는 경우가 많았는데요, 이를 개선하고자 HealthBench는 60개국에서 활동한 262명의 의료진과 협력하여 5,000개의 실제감 있는 시나리오 대화를 구성했습니다. 각 대화는 전문가가 작성한 평가 기준(루브릭)을 기반으로 채점되며, 이를 통해 AI의 의사소통 능력, 정확성, 맥락 이해력 등을 다각도로 측정할 수 있습니다.
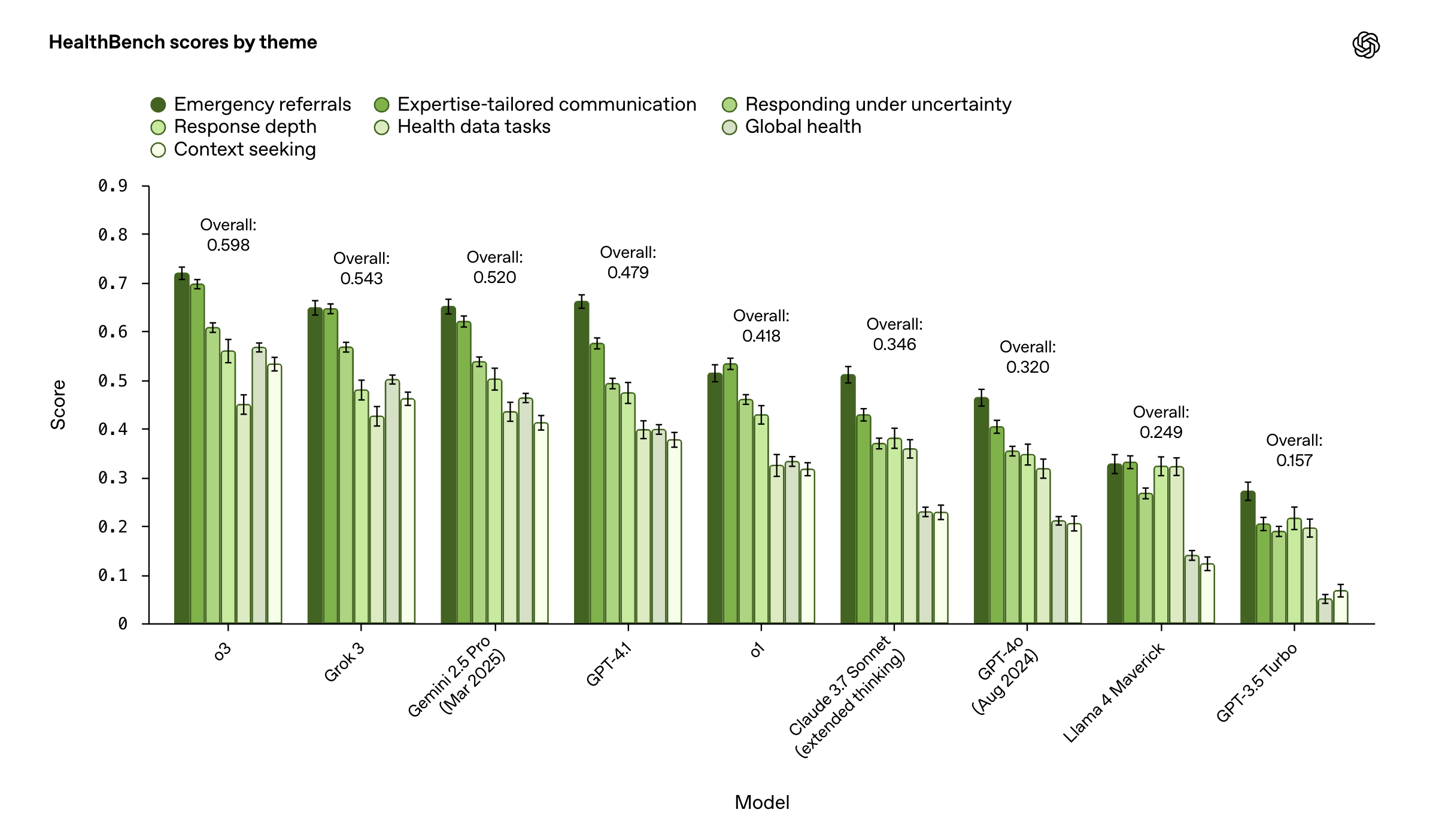
특히 HealthBench는 ‘의미 있음’, ‘신뢰 가능함’, ‘개선 가능성 있음’이라는 세 가지 원칙 아래 설계되어, 개발자들이 AI 모델을 현실적이고 실용적인 방향으로 개선해 나가는 데 도움을 줍니다. 기존의 의료 AI 벤치마크는 퀴즈나 지식 기반 문제 중심인 경우가 많았지만, HealthBench는 복잡한 다중턴 대화, 다양한 언어, 전문가와 비전문가 간의 상호작용 등을 포함합니다. 또한 Claude 3.7, Gemini 2.5 Pro 등 주요 경쟁 모델과 비교해도 OpenAI의 최신 모델(o3, GPT-4.1)이 HealthBench에서 더 높은 성능을 보였다는 점도 주목할 만합니다.
HealthBench의 주요 특징
- 5,000개 대화 시나리오: 실제 의료 환경을 반영한 다중턴, 다국어 대화 구성
- 48,562개의 세부 평가 기준: 의료 전문가들이 직접 설정한 채점 기준
- 7가지 주제 및 다차원 평가 축: 응급 상황, 불확실성 대응, 세계 보건 등 다양한 상황 포함
- 모델 기반 채점 방식: GPT-4.1이 루브릭에 따라 자동 채점, 전문가 평가와 높은 일치율
HealthBench 사용 방법
HealthBench는 GitHub에 전체 데이터셋과 평가 도구가 공개되어 있어 누구나 사용할 수 있습니다. 대화형 AI를 개발하거나 의료 분야에서 모델을 활용하려는 개발자라면, 이 데이터를 통해 모델을 학습시키거나 성능을 분석해볼 수 있습니다. 상세한 내용은 OpenAI의 simple-evals GitHub 저장소를 참고해주세요.
OpenAI의 HealthBench 소개 블로그
https://openai.com/index/healthbench/
OpenAI의 HealthBench 논문
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()