
OpenViking 소개
OpenViking은 ByteDance의 VolcEngine Viking 팀이 개발하여 공개한 AI 에이전트(AI Agent) 전용 오픈소스 맥락 데이터베이스(Context Database) 입니다. OpenViking은 기존의 AI 에이전트 개발 과정에서 발생하는 가장 큰 어려움 중 하나인 맥락(Context) 관리의 파편화 문제를 해결하기 위해 등장했습니다. 기존에는 에이전트의 기억, 외부 리소스, 기술(Skill)들이 벡터 데이터베이스나 코드 등 여러 곳에 흩어져 있어 통합 관리가 어려웠습니다.
OpenViking은 이러한 복잡한 데이터를 파일 시스템 패러다임(File System Paradigm) 으로 통합하여 관리합니다. 마치 우리가 컴퓨터에서 파일과 폴더를 다루듯이, 에이전트가 필요한 모든 정보를 viking://이라는 프로토콜 하에 계층적인 디렉터리 구조로 저장하고 탐색할 수 있게 해줍니다. 이를 통해 개발자는 직관적인 ls, cat, find와 같은 명령어로 에이전트의 기억과 지식을 체계적으로 관리하고 디버깅할 수 있습니다.
특히 OpenViking 프로젝트는 단순한 저장소를 넘어, 에이전트의 토큰 사용량을 절감하기 위한 계층적 로딩(Tiered Context Loading) 시스템과, 사용자와의 상호작용을 통해 스스로 기억을 발전시키는 자가 반복(Self-Iteration) 메커니즘을 내장하고 있습니다. 2026년 1월에 오픈소스로 공개되었으며, AI 에이전트 생태계의 핵심 인프라가 되는 것을 목표로 하고 있습니다.
OpenViking vs. 기존 RAG 방식 비교
기존의 검색 증강 생성(RAG) 방식과 OpenViking이 맥락 데이터를 다루는 방식에는 근본적인 차이가 있습니다. 먼저, 저장 및 조직화 방식 관점에서 살펴보면, 기존 RAG 방식은 텍스트를 단순히 청크(Chunk)로 잘라 평면적인 벡터 저장소(Flat Vector Storage) 에 보관합니다. 이렇게 저장된 정보들 간의 구조적 관계를 파악하기 어렵고 관리가 파편화됩니다. 이에 비해, OpenViking은 모든 맥락(기억, 리소스, 스킬)을 파일 시스템(viking://) 형태로 구조화합니다. 데이터 간의 위계와 포함 관계가 명확해지며, 특정 주제나 프로젝트별로 데이터를 디렉터리에 담아 관리할 수 있습니다.
다음으로 검색(Retrieval) 메커니즘 측면에서도 차이점이 있습니다. 기존 RAG 방식은 단순한 의미론적 유사도(Semantic Similarity)에 의존하여 검색합니다. 문맥의 전체적인 흐름보다는 단편적인 문장 일치에 집중하는 경향이 있습니다. 하지만 OpenViking은 디렉터리 재귀 검색(Directory Recursive Retrieval) 방식을 사용합니다. 에이전트가 의도(Intent)에 따라 특정 디렉터리로 이동한 뒤, 그 안에서 정밀 검색을 수행합니다. 이는 파일 탐색기의 폴더 진입 방식과 유사하여 더 정확한 맥락 파악이 가능합니다.
마지막으로 관측 가능성(Observability) 관점에서 살펴보면, 기존 RAG 방식은 검색 과정이 블랙박스(Black Box)에 가까워, 왜 특정 정보가 검색되었는지 디버깅하기 어렵습니다. 이에 비해 OpenViking은 파일 경로를 기반으로 탐색 경로가 남기 때문에 **검색 궤적(Retrieval Trajectory)**을 시각적으로 추적할 수 있습니다. 에이전트가 어떤 경로(path)를 통해 정보에 접근했는지 명확히 알 수 있어 디버깅이 용이합니다.
OpenViking 주요 기능 및 아키텍처
OpenViking은 에이전트의 '뇌'를 파일 시스템처럼 관리할 수 있도록 다음과 같은 핵심 기술을 제공합니다.
Viking URI 및 파일 시스템 패러다임
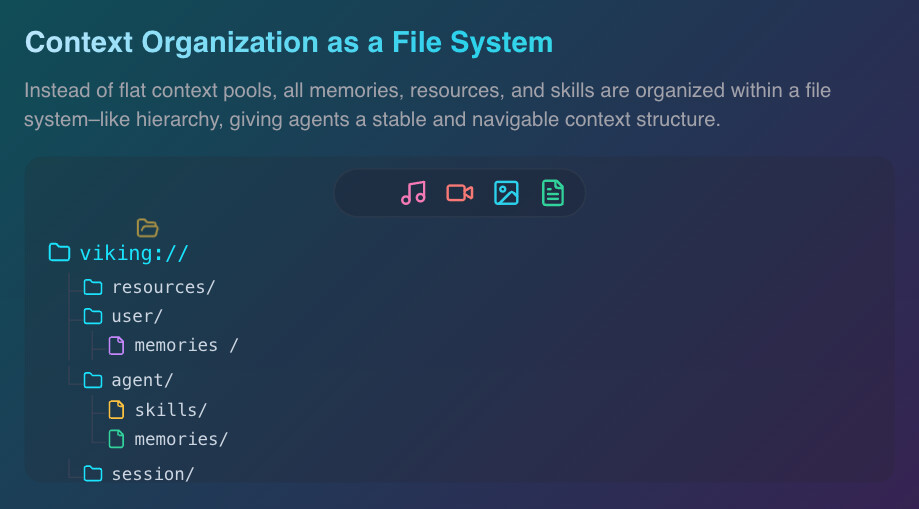
모든 데이터는 viking:// 프로토콜을 사용하는 가상 파일 시스템에 매핑됩니다. 크게 세 가지 주요 디렉터리로 구분됩니다.
viking://resources/: 프로젝트 문서, 웹 페이지, 리포지토리 등 외부 지식 저장소.viking://user/: 사용자의 선호도, 습관, 장기 기억 등을 저장.viking://agent/: 에이전트가 보유한 기술(Skills), 작업 지침(Instructions), 작업 기억 등.
계층적 컨텍스트 로딩 (Tiered Context Loading)
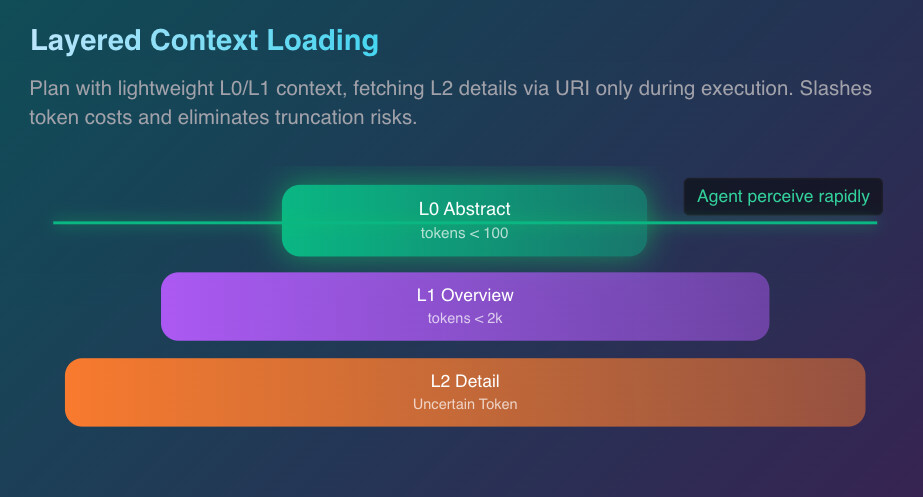
대량의 정보를 한 번에 모델에 주입할 때 발생하는 토큰 비용과 "Lost in the Middle" 문제를 해결하기 위해, 데이터를 3단계(L0, L1, L2)로 나누어 처리합니다.
- L0 (Abstract): 100 토큰 미만의 초요약본. 에이전트가 빠르게 훑어보고 계획을 세울 때 사용합니다.
- L1 (Overview): 2,000 토큰 미만의 개요. 대략적인 내용을 파악하는 데 사용됩니다.
- L2 (Detail): 전체 상세 내용. 실제로 해당 정보가 필요하다고 판단될 때만 로딩합니다.
재귀적 맥락 검색 (Recursive Context Retrieval)
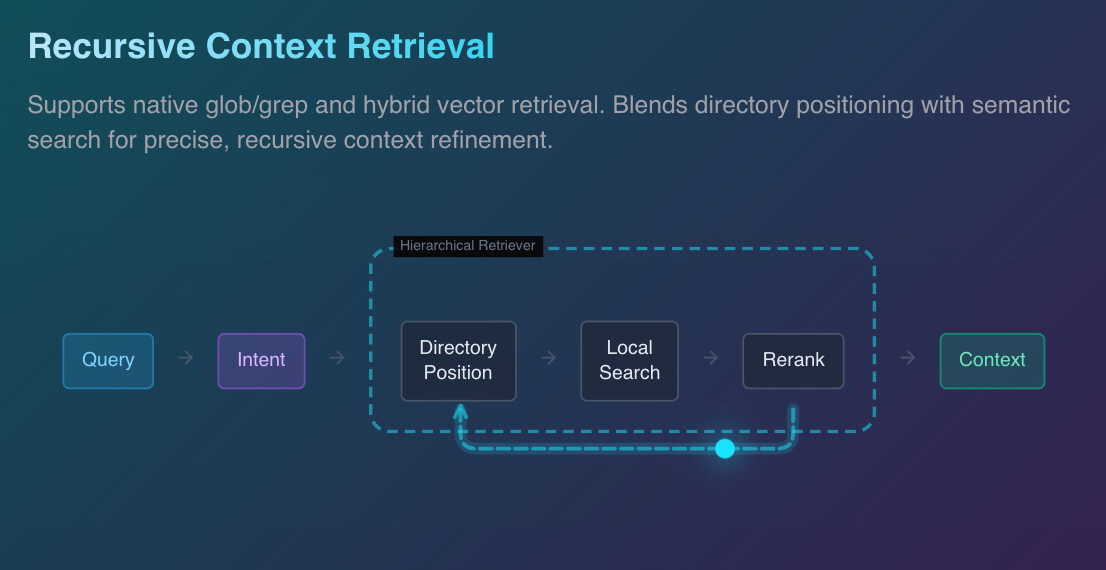
단순 키워드 매칭이 아닌, 에이전트가 능동적으로 탐색 경로를 결정하는 고급 검색 방식입니다.
- Index-Based Routing: 각 디렉터리는 자신이 포함한 하위 파일들의 내용을 요약한 인덱스(Index)를 가지고 있습니다.
- 탐색 과정: 에이전트는 현재 위치의 인덱스를 읽고, 사용자의 질문(Query)을 해결하기 위해 어떤 하위 디렉터리로 이동할지 판단합니다.
- 정밀도 향상: 관련 없는 폴더는 아예 진입하지 않으므로, 기존 RAG에서 발생하는 '유사하지만 엉뚱한 정보(Distractor)'에 의한 검색 품질 저하를 근본적으로 차단합니다.
관측 가능성 및 자가 진화 (Observable & Self-Evolving Context)

OpenViking은 에이전트의 행동을 투명하게 만들고, 지속적으로 똑똑해지는 메커니즘을 내장하고 있습니다.
- 관측 가능한 궤적 (Observable Trajectory): 검색 결과뿐만 아니라, 에이전트가 어떤 경로(
path)를 거쳐 그 정보에 도달했는지 **추적(Trace)**할 수 있습니다. 개발자는viking://resources/docs/api/v1과 같은 경로를 확인하여, 에이전트가 올바른 논리 흐름으로 정보를 찾았는지 디버깅할 수 있습니다. - 자가 진화 (Self-Evolving): 세션이 종료되면, 백그라운드 프로세스가 대화 내용을 분석합니다. 여기서 사용자의 새로운 선호도나 작업 수행 노하우를 추출하여
viking://user나viking://agent디렉터리에 자동으로 업데이트합니다.- Insight Extraction: 대화 중 발견된 사용자의 새로운 선호도나, 특정 작업의 성공/실패 원인을 추출합니다.
- Memory Update: 추출된 정보를
viking://user/preferences.md나viking://agent/lessons_learned.md와 같은 파일에 자동으로 **기록(Write-back)**합니다. 다음 세션에서 에이전트는 이 업데이트된 파일을 참조하여 더 나은 답변을 제공합니다.
OpenViking 설치 및 사용 방법
OpenViking은 Python 3.9 이상 환경에서 pip를 통해 쉽게 설치할 수 있습니다.
pip install openviking
설치를 완료한 후, 임베딩(Embedding) 및 VLM(Vision Language Model) 사용을 위한 설정 파일(ov.conf)을 작성해야 합니다. OpenAI 또는 VolcEngine(Doubao 모델) 등을 백엔드로 지원합니다.
다음은 설정 파일 예시(ov.conf)입니다:
{
"embedding": {
"dense": {
"api_base": "https://api.openai.com/v1",
"api_key": "your-openai-api-key",
"backend": "openai",
"model": "text-embedding-3-large",
"dimension": 3072
}
},
"vlm": {
"api_base": "https://api.openai.com/v1",
"api_key": "your-openai-api-key",
"backend": "openai",
"model": "gpt-4-vision-preview"
}
}
OpenViking 사용 예시
OpenViking 클라이언트를 초기화하고 리소스를 추가한 뒤, 파일 시스템처럼 탐색하고 의미 기반 검색을 수행하는 과정입니다.
import openviking as ov
# 1. 클라이언트 초기화 (데이터 저장 경로 지정)
client = ov.SyncOpenViking(path="./data")
client.initialize()
# 2. 리소스 추가 (웹 URL, 파일, 디렉터리 등 지원)
# 자동으로 L0, L1, L2 계층으로 처리되어 저장됩니다.
add_result = client.add_resource(
path="https://raw.githubusercontent.com/volcengine/OpenViking/main/README.md"
)
root_uri = add_result['root_uri']
# 3. 파일 시스템 탐색 (ls 명령어로 구조 확인)
print(client.ls(root_uri))
# 4. 파일 읽기 및 요약 확인
# glob 패턴으로 Markdown 파일 찾기
glob_result = client.glob(pattern="**/*.md", uri=root_uri)
if glob_result['matches']:
target_file = glob_result['matches'][0]
# 전체 내용 읽기
content = client.read(target_file)
# 요약본(Abstract) 확인
abstract = client.abstract(target_file)
# 5. 의미 기반 검색 (Semantic Search)
# 특정 URI 하위에서 "OpenViking이 무엇인가?" 검색
results = client.find("what is openviking", target_uri=root_uri)
for r in results.resources:
print(f"Found: {r.uri} (Score: {r.score})")
client.close()
라이선스
이 프로젝트는 Apache-2.0 License 로 공개 및 배포되고 있습니다.
 OpenViking 공식 홈페이지
OpenViking 공식 홈페이지
 OpenViking 프로젝트 GitHub 저장소
OpenViking 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()