pdfplumber 소개
PDF는 많은 양의 데이터가 담긴 파일 형식입니다. 하지만 이 데이터를 효과적으로 추출하는 것은 쉽지 않습니다. pdfplumber는 이러한 문제를 해결하기 위한 강력한 도구로, PDF에서 텍스트, 테이블, 이미지 등 다양한 정보를 쉽게 추출할 수 있습니다.
pdfplumber는 PDF 파일의 각 텍스트 문자, 사각형, 선 등에 대한 자세한 정보를 추출할 수 있는 Python 라이브러리입니다. 또한 테이블 추출 및 시각적 디버깅 기능도 제공합니다. pdfplumber는 pdfminer.six를 기반으로 구축되었으며, 주로 머신 생성 PDF에 최적화되어 있습니다.
pdfplumber는 PDF 파일을 분석하여 각 객체의 위치, 크기, 색상 등의 세부 정보를 제공하며, 이를 통해 텍스트 추출, 테이블 추출, 폼 데이터 추출 등의 다양한 작업을 수행할 수 있습니다. 또한, 시각적 디버깅 도구를 통해 추출한 데이터를 시각적으로 확인할 수 있습니다.
주요 기능
- 텍스트 추출: 페이지 내의 텍스트를 문자열로 추출할 수 있습니다. 레이아웃을 유지하면서 텍스트를 추출하는 기능도 제공합니다.
- 테이블 추출: 페이지 내의 테이블을 감지하고, 각 셀의 텍스트를 추출할 수 있습니다. 다양한 설정을 통해 테이블 감지 방식을 커스터마이즈할 수 있습니다.
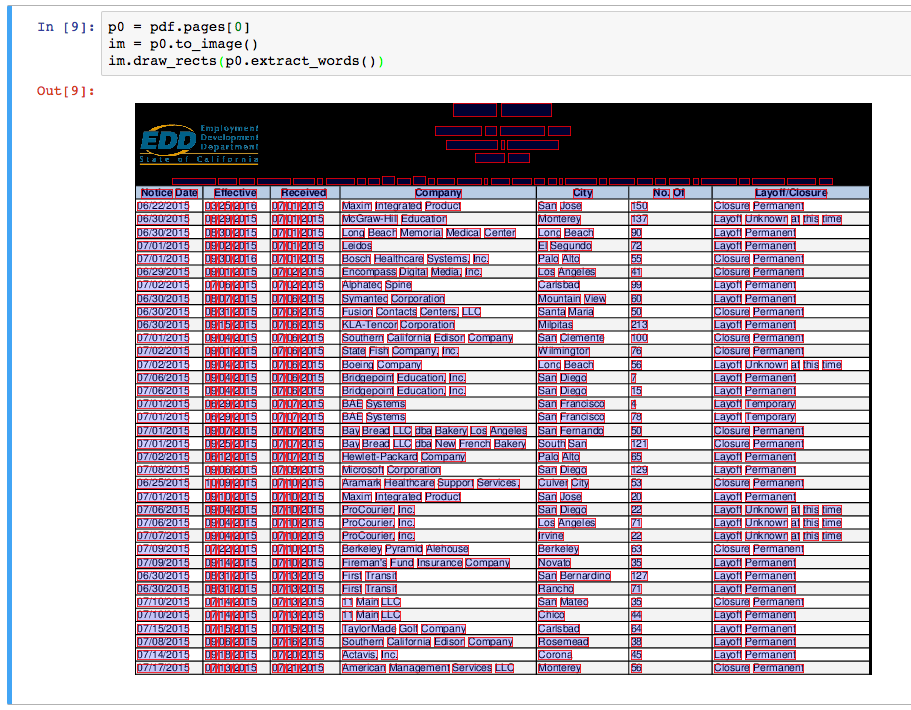
- 시각적 디버깅: 추출한 데이터를 시각적으로 확인할 수 있는 기능을 제공합니다. 예를 들어, 페이지 내의 각 객체를 시각적으로 표시하고, 이를 통해 데이터의 위치와 크기를 확인할 수 있습니다.
- 폼 데이터 추출: PDF 파일 내의 폼 필드와 해당 값을 추출할 수 있습니다.
데모
라이선스
pdfplumber는 MIT License 하에 공개 및 배포되고 있습니다.
 pdfplumber GitHub 저장소
pdfplumber GitHub 저장소
pdfminer.six GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()