
Psyche 소개
Nous Research가 공개한 Psyche는 대규모 언어 모델(LLM) 훈련을 기존의 중앙 집중형 방식에서 벗어나 누구나 참여할 수 있는 분산형으로 전환할 수 있는 시스템입니다. Idle 상태인 전 세계의 GPU를 모아 LLM을 효율적으로 훈련시키기 위한 Psyche 프로젝트는 “AI 개발의 민주화”를 목표로 하고 있습니다.
기존의 LLM은 수천 개의 GPU가 한 곳에 모여 있는 데이터 센터에서 학습됩니다. 이 방식은 막대한 자본과 인프라를 요구해 대기업 중심의 개발 구조를 고착화시키는 결과를 낳았습니다. Psyche는 이 흐름을 거스르며 전 세계에 분산된 GPU 자원을 활용하여 모두가 AI 개발에 참여할 수 있는 구조를 제안합니다.
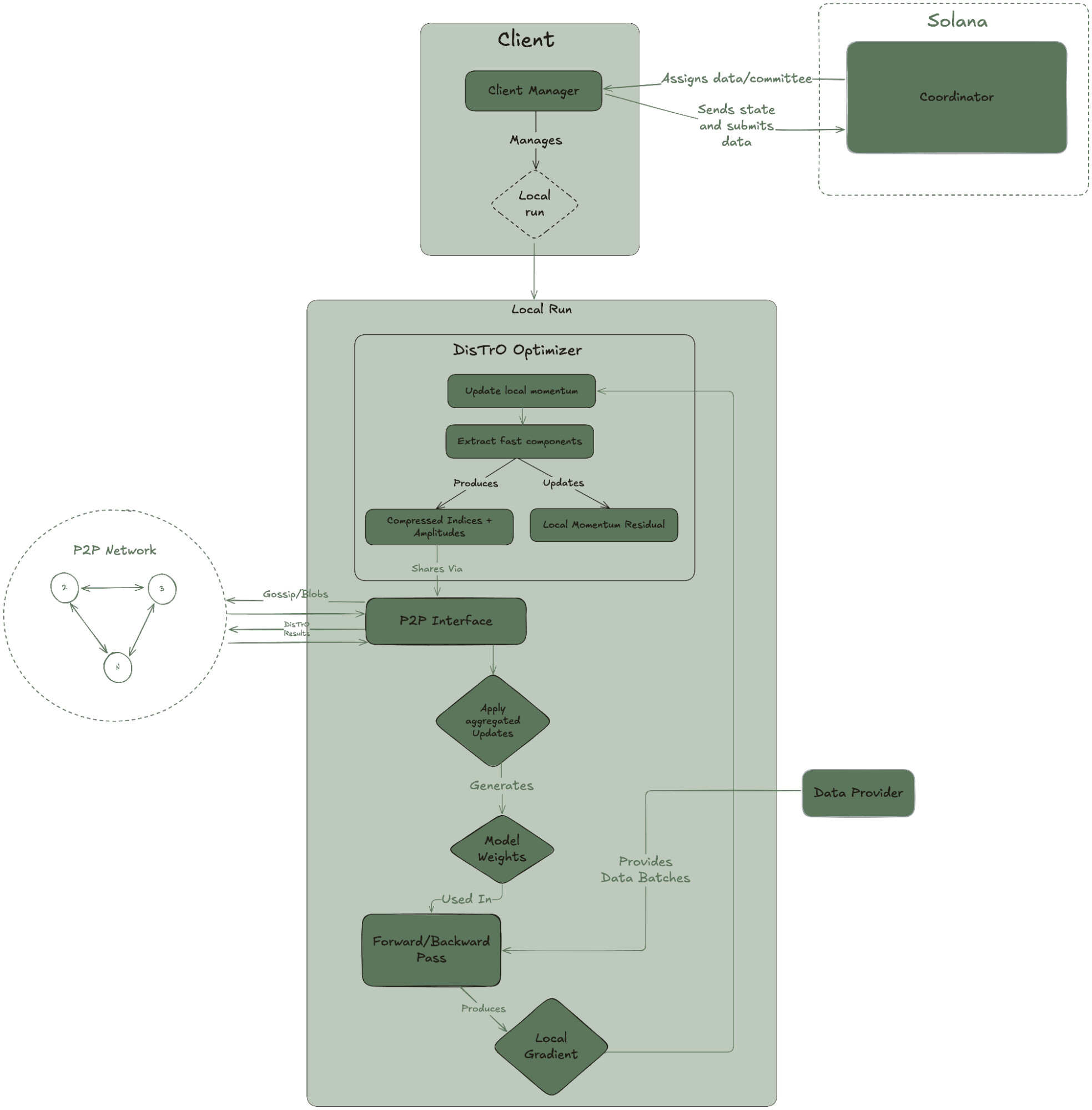
핵심은 훈련을 “네트워크로 나누는 방식”에 있습니다. 하나의 거대한 모델을 각 노드가 일부씩 훈련하며 서로의 업데이트를 공유하고 검증하는 구조입니다. 여기에는 DeMo(Decoupled Momentum Optimization)와 DisTrO(Distributed Training Optimization)라는 새로운 최적화 방법론이 적용됩니다. JPEG 압축처럼 필요한 정보만 뽑아 통신 비용을 줄이는 방식이 인상적입니다.
Psyche의 주요 특징
- DisTrO: 훈련 중 통신되는 정보를 DCT(이산 코사인 변환)로 압축, 필요한 정보만 전달
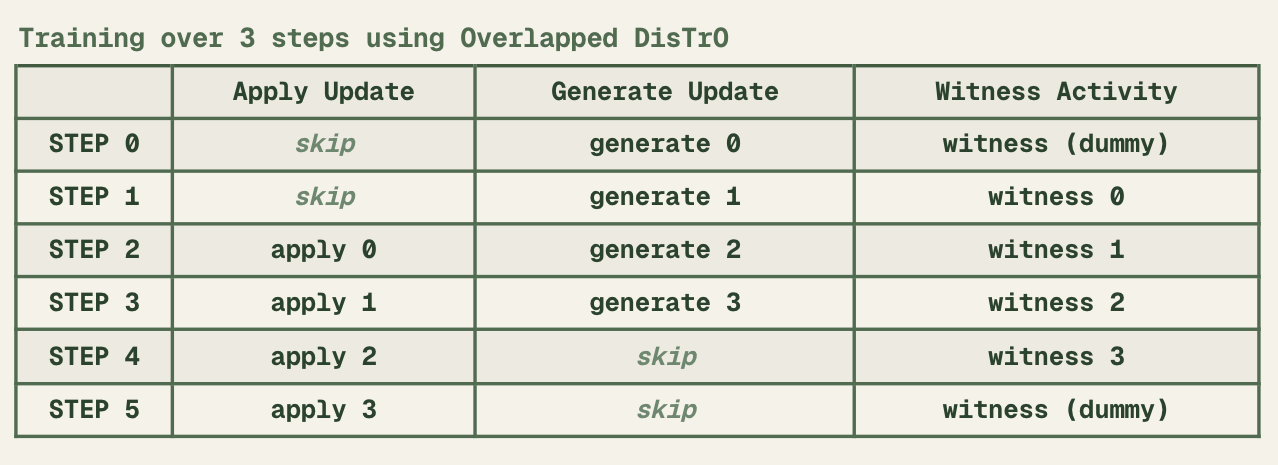
- Overlapped Training: 통신과 훈련을 동시에 진행하여 GPU 효율 극대화
- Quantized Communication: DCT의 부호만 전송하여 3배 이상 압축 효과
- P2P 인프라: Iroh와 UDP Hole-punching을 활용한 NAT 넘기 지원
- 훈련 검증: Witness 및 Bloom Filter를 통한 사기 방지 메커니즘 도입
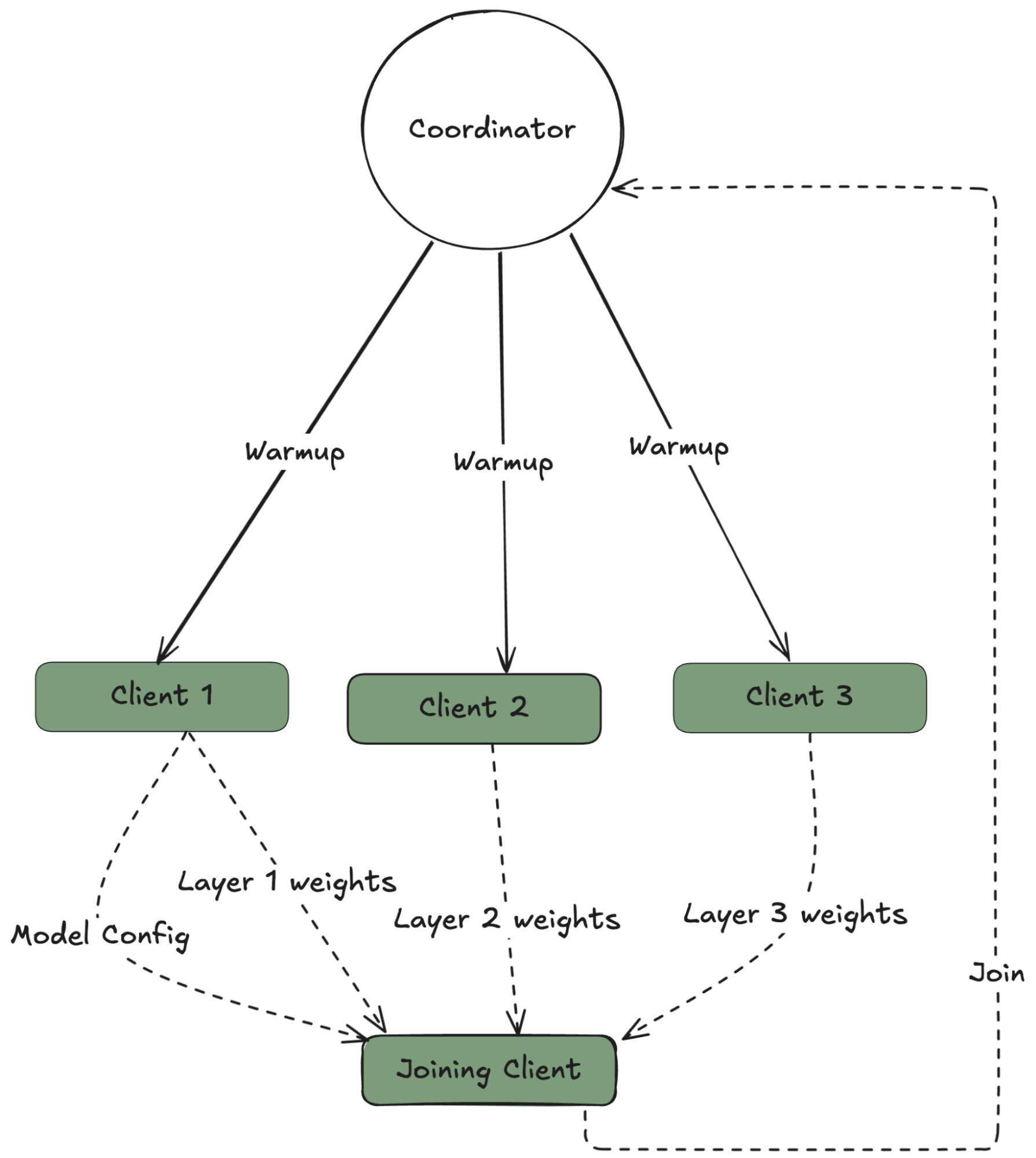
- Epoch 구조: 짧은 단위로 나누어 참여자의 유연한 입퇴장을 지원
Psyche의 동작 개요
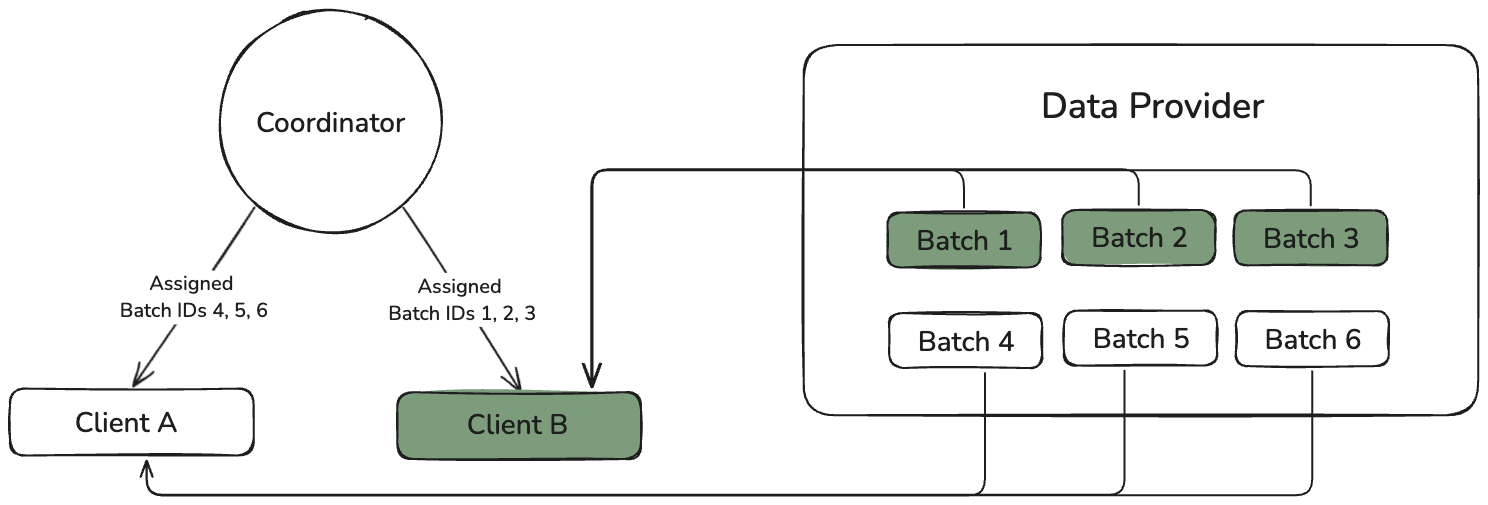
Psyche는 Rust 기반의 클라이언트와 스마트 컨트랙트 기반의 Coordinator, 데이터 제공자(Data Provider)로 구성됩니다:
훈련 흐름 요약
- 클라이언트들이 Coordinator에 연결
- 모델 체크포인트 다운로드 (HuggingFace or P2P)
- 훈련 시작 → 결과를 DisTrO 방식으로 공유
- Witness가 다른 클라이언트의 행동을 감시하고 보고
- 일정 Epoch마다 체크포인트를 저장 및 배포
네트워크는 NodeId 기반으로 구성되며, 모든 통신은 End-to-End 암호화됩니다.
첫 번째 실험: Psyche 40B (Consilience)
첫 번째 실험은 40B 파라미터를 가진 모델 ‘Consilience’의 사전 학습입니다. MLA(Multi-head Latent Attention) 구조를 기반으로 하며, Llama의 GQA보다 더 표현력이 뛰어나다고 알려진 구조입니다.
- 학습 데이터: FineWeb (14T), FineWeb-2 (4T), The Stack V2 (0.2T → 1T)
- 토큰 수: 총 20T 토큰
- 타깃 디바이스: H100/DGX 및 3090에서도 실행 가능
Consilience는 기본 모델(raw)과, 후에 제공될 annealed 모델로 나뉘어 배포됩니다.
 Psyche 학습 현황 확인: Consilence-40B
Psyche 학습 현황 확인: Consilence-40B
 Psyche 소개 블로그
Psyche 소개 블로그
 Psyche GitHub 저장소
Psyche GitHub 저장소
https://github.com/PsycheFoundation/psyche
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()