W&B의 ML Engineer인 Thomas Capelle가 Why You Should Upgrade Your Code to PyTorch 2.0 라는 제목으로 블로그 글을 올렸습니다 ㅎㅎ
원문 링크와 함께 DeepL의 도움을 받은 소개 부분을 공유드립니다. ![]()

Why You Should Upgrade Your Code to PyTorch 2.0
파이토치 2.0으로 코드를 업그레이드해야 하는 이유
Taking PyTorch 2.0 for a spin
PyTorch 2.0 사용해보기Introduction
소개
TLDR: This post is meant to inspire you to upgrade to PyTorch 2.0 today and enjoy this supercharged release!
요약: 이 포스팅은 파이토치 2.0으로 업그레이드하고 이 강력한 릴리스를 즐길 수 있도록 영감을 주기 위한 것입니다!This major release presents many tools that make your workflows more powerful. It has no API changes, and it's completely backward compatible with your existing PyTorch code. I am not going to go through everything that's new, for that I encourage you to read the blog post article about 2.0.
이번 주요 릴리스에는 워크플로우를 더욱 강력하게 만들어주는 많은 도구가 포함되어 있습니다. API가 변경되지 않았으며 기존 PyTorch 코드와 완벽하게 호환됩니다. PyTorch 2.0에 대한 블로그 게시글을 읽어보시길 권해드리며, 새로운 기능을 모두 소개하지는 않겠습니다.
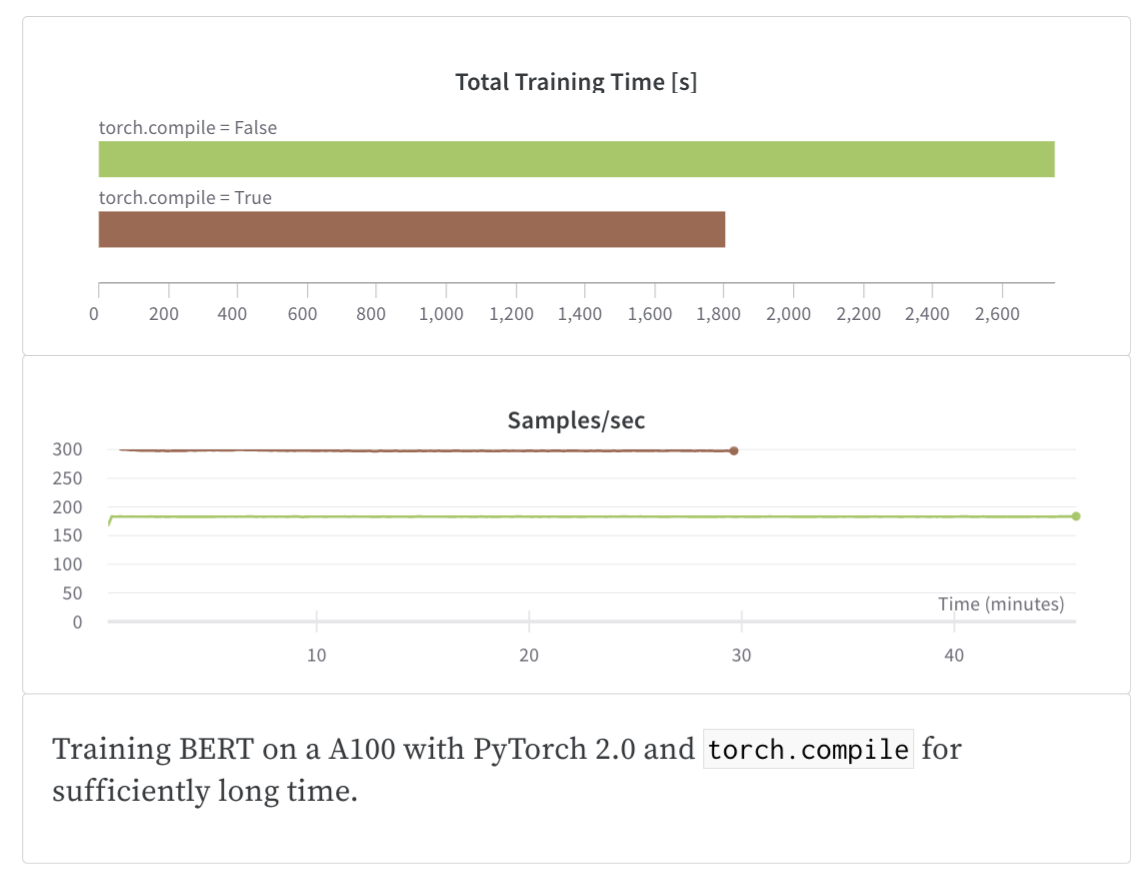
Training BERT on a A100 with PyTorch 2.0 and
torch.compilefor sufficiently long time.
PyTorch 2.0과 torch.compile을 사용하여 A100에서 충분히 오랜 시간 동안 BERT를 훈련합니다.
Two new features are very interesting for existing code bases:
두 가지 새로운 기능은 기존 코드베이스에 매우 흥미롭습니다:
torch.set_default_device: This enables to setup your device globally! no more.to("cuda")calls all over your code. Just set it up once and you're done. This new feature enables you to remove some boiler plate on your code––note that this is optional and you can keep your code as it is if you'd prefer.
torch.set_default_device: 이 기능을 사용하면 디바이스를 전역적으로 설정할 수 있습니다! 코드 전체에서 더 이상.to("cuda")호출을 하지 않아도 됩니다. 한 번만 설정하면 끝입니다And the
torch.compilefunction that promises extreme throughput on NVIDIA GPUs. Simply put, you wrap your model withcompile_model = torch.compile(model)and you are good to go! Normally, you get a nice performance boost from 10% to 100%, depending on the model!
그리고 NVIDIA GPU에서 뛰어난 처리량을 약속하는torch.compile함수도 있습니다. 간단히 말해서,compile_model = torch.compile(model)로 모델을 래핑하기만 하면 됩니다! 일반적으로 모델에 따라 10%에서 100%까지 성능이 향상됩니다!Ah, but not so fast: Is your DataLoader fast enough to handle the increased throughput?
아, 하지만 그렇게 빠르지는 않네요: DataLoader가 증가된 처리량을 처리할 수 있을 만큼 충분히 빠를까요?Let's run some benchmarks and see what happens
몇 가지 벤치마크를 실행하여 어떤 결과가 나오는지 확인해 봅시다.