
PyTorch 2.10 소개
PyTorch Foundation에서는 최신 PyTorch 버전인 PyTorch 2.10을 공식 발표하였습니다. 이번 버전은 성능(Performance) 및 수치 디버깅(Numerical Debugging) 기능 강화에 중점을 두었으며, 특히 분산 강화 학습(Distributed Reinforcement Learning) 워크플로우와 같은 복잡한 환경에서의 모델 안정성을 높이는 데 주력했습니다. 또한, Python 3.14에 대한 지원을 포함하여 최신 개발 생태계와의 호환성을 확보했습니다.
이번 릴리스는 2.x 시리즈의 컴파일러 스택(TorchDynamo, TorchInductor)을 기반으로 성능을 더욱 최적화했습니다. torch.compile의 기능이 확장되었으며, 커널 실행 오버헤드를 줄이는 새로운 퓨전 기술들이 도입되었습니다. 이와 더불어 수치적 불일치(Numerical Divergence)를 추적할 수 있는 새로운 디버깅 모드가 추가되어, 대규모 모델 학습 시 발생할 수 있는 미세한 오류를 효율적으로 잡아낼 수 있게 되었습니다.
주요 변화로는 TorchScript의 공식적인 폐기(Deprecation) 및 torch.export 로의 전환 권장이 포함되어 있어, 기존 프로덕션 파이프라인을 운영 중인 엔지니어들의 주의가 필요합니다. 또한 2026년부터는 릴리스 주기가 기존 분기별에서 2개월(격월) 단위로 단축되어, 새로운 기능이 더 빠르게 배포될 예정입니다.
PyTorch 2.10의 주요 업데이트
성능 최적화 및 컴파일러 업데이트
PyTorch 2.10은 성능 향상을 위해 컴파일러와 연산 커널 레벨에서 다양한 최적화를 적용했습니다.
-
Python 3.14 지원:
torch.compile()이 Python 3.14를 완벽하게 지원하며, 실험적으로 Python 3.14t(free-threaded build) 빌드도 지원합니다. -
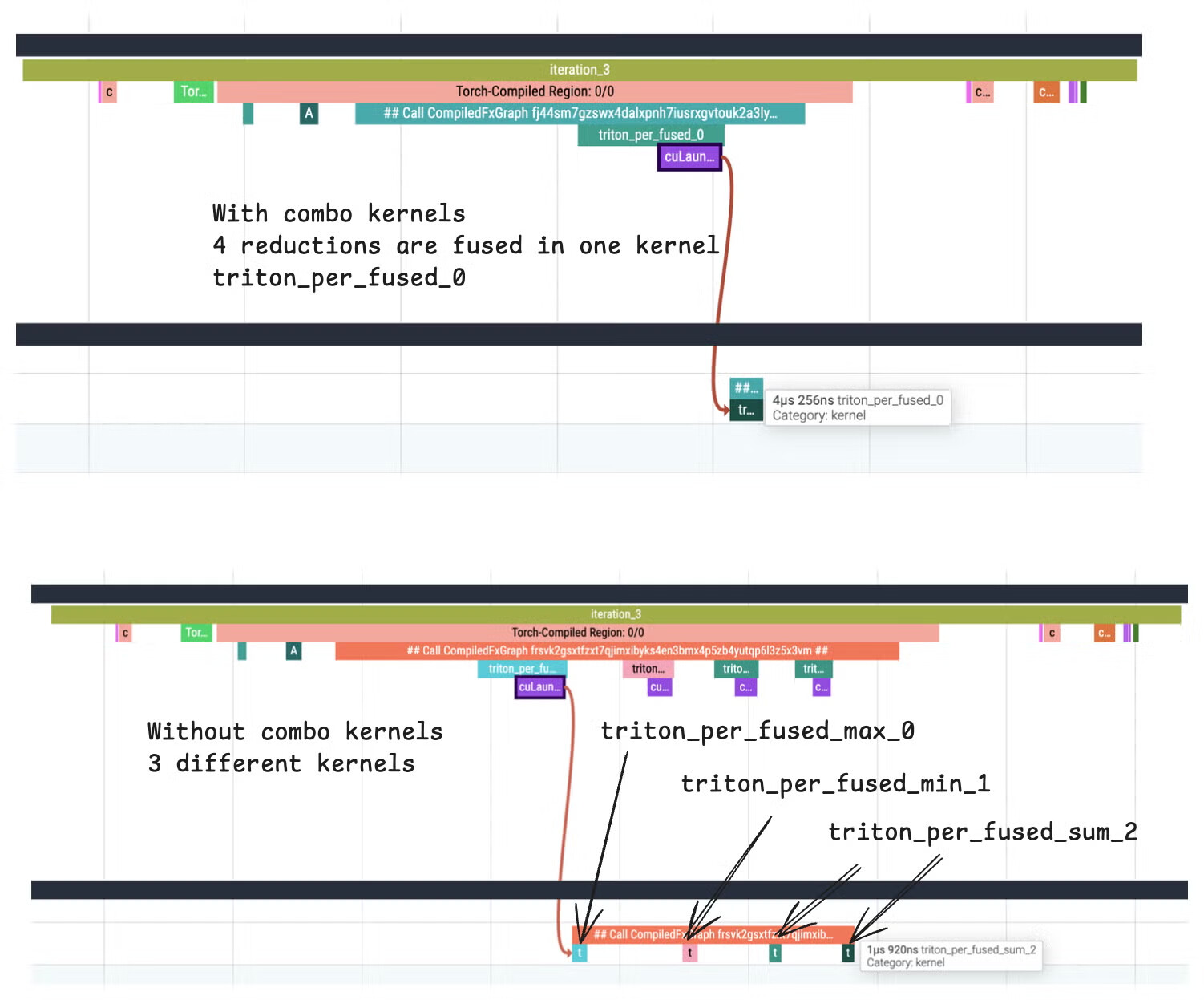
Combo-Kernels (Horizontal Fusion):
torchinductor에 데이터 의존성이 없는 여러 독립적인 연산을 하나의 통합된 GPU 커널로 합치는 수평 퓨전(Horizontal Fusion) 기술이 도입되었습니다. 이를 통해 커널 실행(Kernel Launch) 오버헤드를 크게 줄일 수 있습니다. RFC에서 예시를 확인해보세요.
-
결정론적 모드(Deterministic Mode) 지원 : 이제
torch.compile()이use_deterministic_mode설정을 준수합니다.torch.use_deterministic_algorithms(True)를 설정하면 컴파일된 그래프 실행에서도 동일한 연산 순서와 결과를 보장받을 수 있어 재현성 확보가 용이해졌습니다.
새로운 연산자(Operators) 및 API
최신 하드웨어 활용과 모델 아키텍처 지원을 위한 새로운 연산자들이 추가되었습니다.
-
varlen_attn()(가변 길이 어텐션): Ragged Sequence나 Packed Sequence 처리를 위한 새로운 어텐션 연산자입니다. 이는 순전파(Forward) 및 역전파(Backward)를 모두 지원하며torch.compile과 호환됩니다.
현재는 FlashAttention v2(FA2)를 통해 지원되며, 향후 cuDNN 및 FA4 지원이 계획되어 있으며, NVIDIA A100 이상의 GPU에서 BF16 및 FP16 데이터 타입을 사용할 수 있습니다.
varlen_attn()관련 API 문서 및 튜토리얼을 참고해주세요. -
효율적인 고유값 분해(DnXgeev): NVIDIA GPU의 cuSOLVER DnXgeev를 활용하여 일반적인 고유값 분해(Eigenvalue Decomposition) 연산의 효율성을 높였습니다.
디버깅 및 수치 안정성 (DebugMode)
대규모 분산 학습 시 발생하는 미세한 수치 오류를 잡기 위해 DebugMode 가 강화되었습니다. 이는 프로파일링 스타일의 런타임 덤프를 제공합니다.
-
텐서 해싱(Tensor Hashing): 입력 및 출력 텐서에 결정론적 해시(Hash)를 부여하여 기록합니다. 동일한 입력을 가진 두 모델 버전(예: Eager 모드 vs Compile 모드)을 실행했을 때, 해시 값이 달라지는 지점을 찾아냄으로써 어떤 연산에서 수치적 차이가 발생했는지 정확히 격리(Isolate)할 수 있습니다.
-
런타임 로깅(Runtime Logging): 디스패치된 연산(Dispatched Operations)과 TorchInductor가 컴파일한 Triton 커널을 기록합니다.
-
디스패치 훅(Dispatch Hooks): 커스텀 훅을 등록하여 호출을 주석 처리(Annotate)하거나 추적할 수 있습니다.
더 상세한 내용은 디버깅 모드 튜토리얼을 참고해주세요.
TorchScript 폐기 및 기타 변경 사항
-
TorchScript Deprecation : 이번 2.10 버전부터 TorchScript가 공식적으로 폐기(Deprecated) 됩니다. 이번 버전부터는 TorchScript 대신
torch.export를 사용하는 것을 강력히 권장합니다. 더 상세한 내용은 PyTorch Conference의 발표 영상을 참고해주세요. -
tlparse & TORCH_TRACE : 컴파일러 이슈 리포팅을 돕기 위해
tlparse로그 포맷이 개선되었습니다. 복잡한 문제를 재현하기 어려울 때, 로그 아티팩트를 공유하여 원인을 분석할 수 있습니다. 더 상세한 내용은 GitHub 및 이 튜토리얼을 참고해주세요. -
릴리스 주기 변경: 2026년부터 릴리스 주기가 기존 분기별(3개월)에서 2개월로 변경됩니다. 향후 릴리즈 주기는 이 스케쥴을 참고해주세요.
 PyTorch 2.10 출시 공지 블로그
PyTorch 2.10 출시 공지 블로그
 PyTorch 2.10 출시 노트 (Release Note)
PyTorch 2.10 출시 노트 (Release Note)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()