QMD 소개
최근 소프트웨어 엔지니어와 지식 노동자들 사이에서 개인적인 마크다운 노트, 기술 문서, 그리고 회의록 등을 효율적으로 관리하고 검색하는 방법에 대한 관심이 높아지고 있습니다. 우리가 일상적으로 사용하는 텍스트 기반 파일들은 그 양이 방대해짐에 따라 기존의 단순한 파일 탐색기나 기본 텍스트 검색 도구만으로는 원하는 정보를 적시에 찾아내기 어렵기 때문입니다.
특히, 보안과 프라이버시가 중요한 기업 업무 환경이나 개인적인 기록의 경우, 외부 클라우드 서버로 데이터를 전송하지 않고 기기 내부에서 안전하게 처리할 수 있는 진정한 로컬 검색 솔루션의 필요성이 크게 대두되었습니다. 기존의 클라우드 기반 AI 검색 도구들은 훌륭한 성능을 보여주지만 항상 데이터 유출에 대한 우려와 네트워크 종속성 문제를 동반합니다. 이러한 기술적 배경과 사용자들의 강력한 요구사항 속에서, Shopify의 창립자인 Tobi Lütke가 직접 개발하여 오픈소스로 공개한 qmd가 개발자 커뮤니티에서 큰 주목을 받고 있습니다.
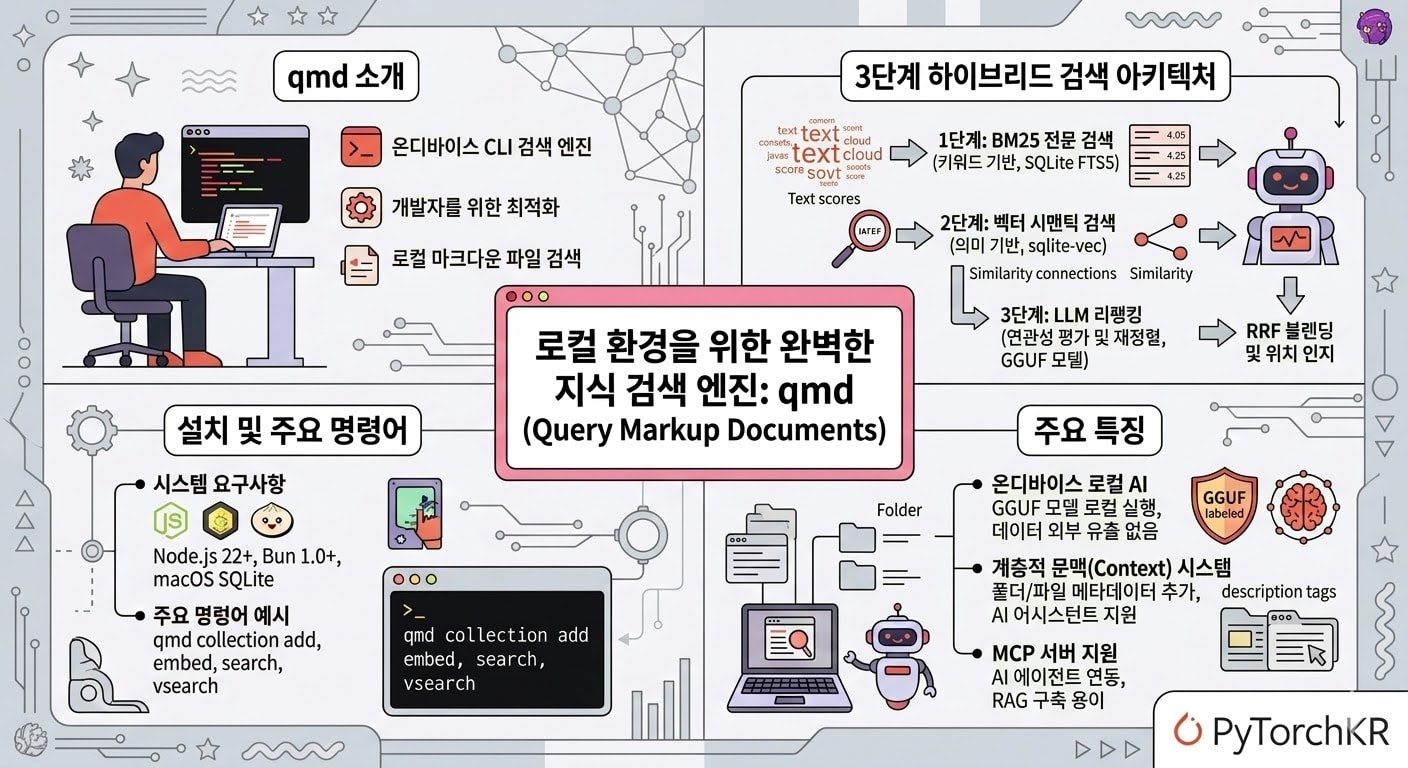
QMD는 'Query Markup Documents'의 약자로, 개발자의 기기 로컬 환경에서 완벽하게 독립적으로 동작하는 온디바이스(On-device) CLI 기반의 작고 가벼운 검색 엔진입니다. 이 도구는 사용자의 컴퓨터에 분산되어 저장된 마크다운 기반의 노트, 회의 텍스트, 코드 문서 및 다양한 지식 기반(Knowledge Base) 파일들을 색인화하여 자연어나 키워드로 빠르고 정확하게 검색할 수 있도록 돕습니다.
가장 큰 장점은 외부 인터넷 연결이나 클라우드 API 의존성 없이 로컬 LLM(대형 언어 모델) 생태계를 온전히 활용하기 때문에, 사용자의 민감한 개인 데이터나 기업 비밀이 외부망으로 유출될 우려가 전혀 없다는 점입니다.
더불어 AI 에이전트 시스템과의 매끄러운 연동을 위한 최신 개방형 표준인 MCP(Model Context Protocol)를 아키텍처 레벨에서 기본적으로 지원하고 있습니다. 따라서 단순히 텍스트를 찾아주는 독립적인 검색 도구를 넘어, 차세대 자율형 AI 어시스턴트 워크플로우의 확장된 로컬 기억 장치(Memory) 역할까지 훌륭하게 수행할 수 있는 강력하고 유연한 잠재력을 지니고 있습니다.
QMD vs. 기존 텍스트 검색 도구(grep 등)와의 비교
기존의 로컬 파일 텍스트 검색 작업에는 주로 터미널 기반의 grep이나 fzf와 같은 도구들이 널리 사용되어 왔습니다. 이러한 전통적인 도구들은 시스템 리소스를 적게 차지하고 매우 빠르지만, 사용자가 입력한 정확한 키워드나 정규 표현식 패턴에 극도로 의존하는 단순 문자열 매칭 방식을 사용하기 때문에 동의어나 문맥을 파악하는 데에는 근본적인 한계가 존재합니다. 예를 들어 "인증(Authentication)"이라는 키워드로 검색할 경우, 문서에 그 단어 없이 "로그인 플로우(Login flow)"나 "세션 관리"라는 단어만 있다면 해당 문서를 연관 지어 찾아내지 못합니다.
반면, QMD는 단순 키워드 매칭의 한계를 극복하기 위해 진보된 하이브리드 검색(Hybrid Search) 방식을 도입하여 이 문제를 기술적으로 해결합니다. 키워드의 고유성과 빈도수를 정밀하게 분석하는 BM25 방식과 텍스트의 의미를 수치화하여 문맥을 이해하는 벡터 시맨틱 검색(Vector Semantic Search)을 결합했습니다.
여기에 그치지 않고, 두 검색 결과를 바탕으로 로컬 LLM이 한 번 더 관련성을 평가하고 재정렬(Re-ranking)하는 파이프라인을 거칩니다. 이를 통해 키워드가 전혀 겹치지 않더라도 사용자의 검색 의도와 가장 부합하는 문서를 정확하게 찾아낼 수 있어, 기존 검색 도구와는 차원이 다른 압도적인 정확도와 검색 경험을 제공합니다.
QMD의 주요 특징
3단계 하이브리드 검색 및 RRF 블렌딩
QMD의 가장 핵심적인 기술적 특징은 단일 SQLite 데이터베이스 파일 내에서 세 가지 강력한 정보 검색 기법을 매끄럽게 엮어낸 하이브리드 검색 파이프라인에 있습니다:
첫번째 단계에서는 SQLite의 내장 FTS5(Full-Text Search 5) 확장을 적극 활용하여 문서 내 단어의 출현 빈도수와 고유성을 평가하는 BM25 기반 전문 검색을 수행합니다.
두번째 단계에서는 sqlite-vec 익스텐션을 통해 텍스트의 의미적 유사도를 측정하는 고차원 벡터 시맨틱 검색을 동시에 병렬로 진행합니다.
세번째 단계는 QMD만의 차별점인 LLM 리랭킹(Re-ranking) 과정입니다. 앞선 두 검색 결과를 통해 유력한 후보군 문서들이 추려지면, 로컬 크로스 인코더 모델이 상위 문서들의 텍스트를 직접 읽어보고 실제 사용자의 자연어 쿼리와의 연관성을 심층적으로 재평가합니다.
┌─────────────────────────────────────────────────────────────────────────────┐
│ QMD Hybrid Search Pipeline │
└─────────────────────────────────────────────────────────────────────────────┘
┌─────────────────┐
│ User Query │
└────────┬────────┘
│
┌──────────────┴──────────────┐
▼ ▼
┌────────────────┐ ┌────────────────┐
│ Query Expansion│ │ Original Query│
│ (fine-tuned) │ │ (×2 weight) │
└───────┬────────┘ └───────┬────────┘
│ │
│ 2 alternative queries │
└──────────────┬──────────────┘
│
┌───────────────────────┼───────────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Original Query │ │ Expanded Query 1│ │ Expanded Query 2│
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
┌───────┴───────┐ ┌───────┴───────┐ ┌───────┴───────┐
▼ ▼ ▼ ▼ ▼ ▼
┌───────┐ ┌───────┐ ┌───────┐ ┌───────┐ ┌───────┐ ┌───────┐
│ BM25 │ │Vector │ │ BM25 │ │Vector │ │ BM25 │ │Vector │
│(FTS5) │ │Search │ │(FTS5) │ │Search │ │(FTS5) │ │Search │
└───┬───┘ └───┬───┘ └───┬───┘ └───┬───┘ └───┬───┘ └───┬───┘
│ │ │ │ │ │
└───────┬───────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└────────────────────────┼───────────────────────┘
│
▼
┌───────────────────────┐
│ RRF Fusion + Bonus │
│ Original query: ×2 │
│ Top-rank bonus: +0.05│
│ Top 30 Kept │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ LLM Re-ranking │
│ (qwen3-reranker) │
│ Yes/No + logprobs │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ Position-Aware Blend │
│ Top 1-3: 75% RRF │
│ Top 4-10: 60% RRF │
│ Top 11+: 40% RRF │
└───────────────────────┘
이후, 이러한 개별 단계의 결과들을 하나의 최종 순위로 결합하기 위해 RRF(Reciprocal Rank Fusion) 알고리즘과 위치 인지 블렌딩(Position-Aware Blending) 기술을 적용합니다. 예를 들어, 최상위 1~3위 결과는 원본 검색 결과에 높은 가중치(검색 75%, 리랭커 25%)를 두어 정확한 키워드 매칭의 가치를 보존하고, 11위 이하의 후순위 결과에서는 문맥을 파악하는 리랭커의 판단(검색 40%, 리랭커 60%)을 더 신뢰하도록 동적으로 가중치를 조절하여 검색 품질의 최적화를 달성합니다.
온-디바이스 로컬 AI와 GGUF 모델 활용
이 모든 복잡한 하이브리드 검색 및 평가 과정은 철저히 사용자 기기 내부(On-device)에서 오프라인 상태로 안전하게 실행됩니다. QMD는 외부의 상용 클라우드 API에 의존하는 대신 Node-llama-cpp 라이브러리와 양자화된 GGUF 포맷의 모델을 활용하여 로컬에서 고성능 AI 연산을 직접 처리합니다.
시스템을 최초로 실행할 때, 약 2GB 크기에 달하는 3개의 핵심 로컬 모델(텍스트를 변환하는 embeddinggemma-300M 임베딩 모델, 문서의 연관성을 재평가하는 Qwen3-Reranker-0.6B 크로스 인코더 리랭커, 그리고 쿼리의 의미를 확장해 주는 qmd-query-expansion-1.7B 쿼리 확장 모델)을 백그라운드에서 자동으로 다운로드합니다.
이로 인해 유료 API 키 발급 비용이나 쿼리당 토큰 소모 비용이 전혀 발생하지 않으며, 엄격한 사내 보안 규정이나 개인정보 보호에 민감한 환경에서도 데이터를 외부로 유출하지 않고 안심하며 사용할 수 있습니다.
강력한 계층적 문맥(Context) 시스템
단순한 문서 검색을 넘어, 추후 연동될 AI가 검색된 문서의 배경을 더 깊이 이해할 수 있도록 돕는 혁신적인 문맥(Context) 트리 시스템을 제공합니다. 사용자는 특정 디렉터리나 파일 컬렉션 단위로 일종의 메타데이터 형태인 문맥 설명을 명시적으로 추가할 수 있습니다. 예를 들어, ~/notes 폴더에는 "개인적인 아이디어와 메모"라는 컨텍스트를 부여하고, ~/Documents/meetings 폴더에는 "업무 회의록"이라는 컨텍스트를 등록할 수 있습니다.
이러한 문맥 정보는 디렉터리 구조를 따라 계층적 트리 형태로 작동하며, 검색 결과가 사용자나 API를 통해 반환될 때 해당 문서가 속한 문맥 텍스트가 항시 함께 제공됩니다.
결과적으로 qmd와 연동된 상위 LLM 어시스턴트는 이 부가적인 문맥 정보를 바탕으로 정보의 출처 성격과 작성 배경을 정확히 파악하여, 사용자에게 훨씬 더 맥락에 맞고 할루시네이션(환각)이 적은 훌륭한 답변을 생성해 낼 수 있게 됩니다.
에이전트 연동을 위한 MCP 서버 지원
qmd는 단순히 개발자가 터미널 창에서 직접 타이핑하여 사용하는 수동적인 CLI 도구를 넘어, 자율형 AI 에이전트의 지식 저장소 백엔드로 활용될 수 있도록 범용적으로 설계되었습니다. 이를 위해 최신 프로토콜인 MCP(Model Context Protocol)를 완벽하게 지원하며, 상태를 유지하지 않는 HTTP 서버 모드(qmd mcp 커맨드 또는 POST /mcp 엔드포인트)로 백그라운드에서 실행할 수 있습니다.
서버 모드로 구동할 경우 상대적으로 무거운 로컬 AI 모델들을 지속적으로 RAM 메모리에 유지하기 때문에, 매 쿼리마다 모델을 디스크에서 다시 불러와야 하는 초기 구동 지연 시간(Cold-start penalty)을 획기적으로 제거할 수 있습니다. 덕분에 OpenClaw나 Claude Code와 같은 최신 AI 코딩 어시스턴트 및 에이전트 기반 워크플로우에 원활하게 통합되어 강력한 로컬 RAG(Retrieval-Augmented Generation) 시스템을 아주 쉽게 구축할 수 있습니다.
QMD 설치 및 주요 사용법
QMD를 원활하게 설치 및 실행하기 위해서는 몇 가지 기본적인 시스템 요구사항을 충족해야 합니다. 먼저 최신 JavaScript 런타임 환경이 필수적이며, Node.js 22 이상 버전 또는 Bun 1.0.0 이상의 환경에서 안정적으로 동작합니다.
또한, 내부적으로 벡터 검색을 위해 SQLite 확장 기능을 심도 있게 사용하므로, macOS 사용자의 경우 Homebrew를 통해 시스템 SQLite(brew install sqlite)를 사전에 반드시 설치해 두어야 합니다.
설치는 Node.js나 Bun의 전역 패키지 관리자를 통해 매우 간단하게 진행할 수 있습니다:
# Node.js 생태계를 사용하는 경우
npm install -g @tobilu/qmd
# Bun 생태계를 사용하는 경우
bun install -g @tobilu/qmd
설치 완료 후 활용할 수 있는 주요 핵심 CLI 명령어는 다음과 같습니다.
qmd collection add <경로> --name <이름>: 특정 로컬 폴더를 색인화할 새로운 컬렉션으로 추가합니다.qmd context add <경로> "<설명>": 특정 경로의 파일들에 검색 문맥(Context) 메타데이터를 부여합니다.qmd embed: 추가된 컬렉션 문서들의 벡터 임베딩을 실제로 생성하고 인덱스를 갱신합니다. (데이터베이스 일관성을 위해 수동 실행을 권장합니다)qmd search "<자연어 검색어>": 전체 문서를 대상으로 3단계 하이브리드 검색을 수행하여 가장 연관성 높은 결과를 반환합니다.qmd vsearch "<검색어>": 리랭킹 과정을 생략하고 빠른 키워드 기반의 고속 하이브리드 검색을 수행합니다.
라이선스
QMD 프로젝트는 MIT License로 공개 및 배포되고 있습니다.
 qmd 프로젝트 GitHub 저장소
qmd 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()