
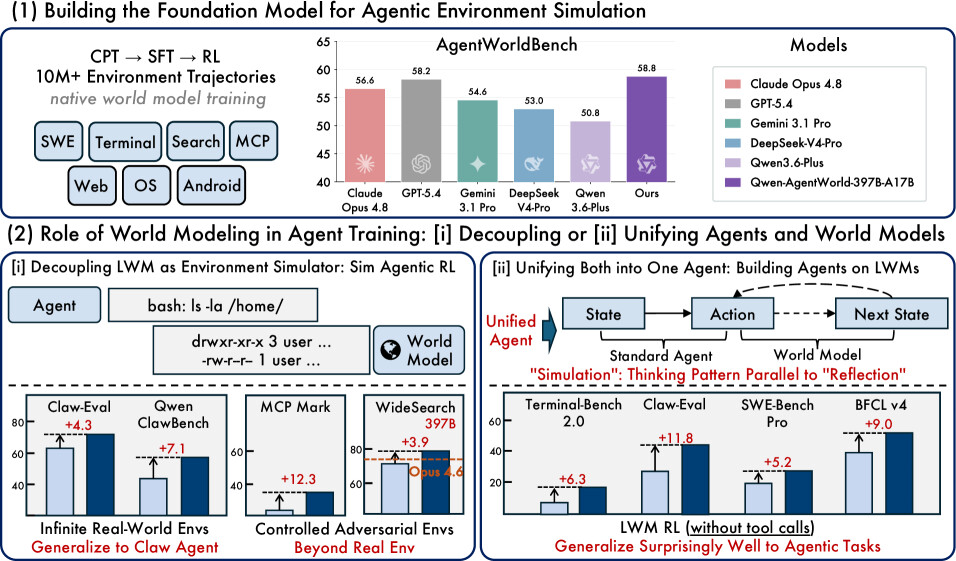
Qwen-AgentWorld 소개
체스를 잘 두는 사람은 말을 옮기기 전에 머릿속으로 몇 수 앞을 미리 둬봅니다. "여기에 두면 상대가 이렇게 받을 테고, 그러면 내 비숍이 위험해지겠지"라고 시뮬레이션한 뒤, 더 나은 수를 고르는 것입니다. 그런데 지금까지의 대형 언어 모델(LLM) 에이전트는 이런 "행동하기 전에 결과를 미리 그려보는" 능력 없이, 일단 도구를 호출하고 명령을 실행한 다음 그 결과를 받아보는 방식으로만 동작해 왔습니다.
이 논문은 바로 이 빈틈을 메우기 위해, 에이전트가 활동하는 환경 자체를 시뮬레이션하는 언어 세계 모델(Language World Model, LWM) 인 Qwen-AgentWorld를 제안합니다. 세계 모델(World Model)이란 현재 관찰과 행동을 입력받아 "그 행동을 하면 환경이 어떻게 바뀌는지"를 예측하는 모델로, 추론과 계획의 핵심 인지 메커니즘으로 여겨져 왔습니다. Qwen-AgentWorld는 알리바바 Qwen 팀이 공개한 모델로, MCP, 검색(Search), 터미널(Terminal), 소프트웨어 엔지니어링(SWE), 안드로이드(Android), 웹(Web), 운영체제(OS)라는 7개 도메인의 에이전트 환경을 단일 모델로 시뮬레이션하는 최초의 언어 세계 모델입니다.
왜 지금까지의 에이전트에는 세계 모델이 없었나
에이전트와 환경의 상호작용 루프는 두 가지 요소로 구성됩니다. 하나는 상태에서 행동을 결정하는 정책(Policy) 이고, 다른 하나는 상태와 행동으로부터 다음 상태를 예측하는 세계 모델(World Model) 입니다. 그런데 지금까지 LLM 에이전트 연구는 거의 전적으로 정책 쪽에만 집중해 왔습니다. "어떤 행동을 할 것인가"는 열심히 학습시켰지만, "그 행동을 하면 환경이 어떻게 반응할 것인가"를 모델 안에 내재화하는 일은 거의 다루지 않았던 것입니다.
이론적으로도 세계 모델은 단순히 있으면 좋은 것이 아니라 필수적인 요소로 밝혀지고 있습니다. Richens 등의 General agents contain world models 연구는 "충분히 넓은 범위의 작업에 걸쳐 일반화할 수 있는 에이전트는 반드시 세계 모델을 학습했어야 한다"는 것을 증명했습니다. 직관적으로도, 행동을 확정하기 전에 환경의 피드백을 예측할 수 있는 에이전트는 그렇지 못한 에이전트보다 결코 나쁠 수 없습니다. 다음 상태를 예측하는 능력은 이를테면 미래를 향한 "반성(Reflection)"과 같은 메타 수준의 사고 패턴이 될 수 있기 때문입니다.
실제 환경이 있는데 왜 굳이 세계 모델인가
여기서 자연스러운 의문이 생깁니다. 검색 엔진이든 터미널이든 실제 환경이 이미 존재하는데, 왜 굳이 그것을 흉내 내는 모델을 따로 학습시킬까요? 저자들은 그 목적이 비용 절감이 아니라, 실제 환경만으로는 도달할 수 없는 새로운 축을 여는 것이라고 분명히 합니다. 핵심 장점은 두 가지입니다.
첫째는 확장성(Scalability) 입니다. 세계 모델을 시뮬레이터로 쓰면 샌드박스나 GUI 가상 머신 같은 전용 인프라 없이도 수천 개의 다양한 환경을 턴 단위로 만들어낼 수 있습니다. 비가역적 조작이 포함되거나, 독점 배포라 외부 접근이 불가능하거나, 공개 구현 자체가 없는 고부가가치 전문 도메인까지 포괄할 수 있습니다.
둘째는 제어 가능성(Controllability) 입니다. 세계 모델은 자연어 지시만으로 시뮬레이션의 양상을 정밀하게 조절할 수 있습니다. 예를 들어 검색 결과를 일부러 일부만 반환해 에이전트가 추가 단계를 밟아 완전한 정보를 모으도록 강제하거나, 간헐적 API 오류나 페이지네이션 같은 까다로운 상황을 주입할 수 있습니다. 실제 환경에서는 거의 일어나지 않는 이런 표적 교란(perturbation)으로 에이전트의 약점을 체계적으로 드러내고 훈련시키면, 실제 환경만으로 학습한 에이전트를 능가하게 됩니다.
언어 세계 모델(LWM)과 7개 도메인의 통합
언어 세계 모델은 상호작용 이력과 에이전트의 현재 행동이 주어졌을 때 다음 환경 관찰(observation)을 예측하는 조건부 텍스트 생성기입니다. 시스템 프롬프트 c , 턴 t 의 관찰 o_t , 행동 a_t 가 있을 때, 세계 모델 f_\theta 는 다음을 생성합니다.
학습 목표는 실제 환경에서 얻은 정답 관찰 o_{t+1} 입니다. 단순한 정의처럼 보이지만, 이 하나의 목적함수가 추론, 지식, 긴 컨텍스트 이해를 동시에 요구한다는 점이 핵심입니다. 예를 들어 터미널에서 curl -s localhost:3000 | python3 -m json.tool 의 출력을 예측하려면 Node.js 미설치, 서버 미실행, 포트 미개방, curl의 조용한 실패, 빈 입력을 받은 json.tool의 오류로 이어지는 인과 사슬을 정확히 따라가야 합니다.

7개 도메인은 행동과 관찰의 표현이 제각각입니다. 아래 표는 각 도메인이 어떤 행동을 받고 어떤 관찰을 내놓으며, 다음 상태 예측이 어떤 핵심 능력을 요구하는지 정리한 것입니다. 특히 GUI 도메인(Android, Web, OS)은 픽셀 프레임이 아니라 접근성 트리(accessibility tree)와 UI 뷰 계층(view hierarchy) 이라는 텍스트 표현으로 화면 상태를 다룹니다. 덕분에 순수 텍스트 모델만으로도 GUI 환경을 시뮬레이션할 수 있습니다.
| 도메인 | 행동(Action) | 관찰(Observation) | 핵심 능력 |
|---|---|---|---|
| MCP | JSON 도구 호출 | 도구 응답(파일 내용, DB 등) | 사실적 세계 지식 |
| Search | 웹 검색 / 추출 | 대화 이력(질의 + 결과) | 사실적 세계 지식 |
| SWE | Read / Edit / Bash | 도구 출력(파일 내용 + diff) | 코드 실행 추론 |
| Terminal | Bash 명령 / 키 입력 | 터미널 출력(stdout + 프롬프트) | 긴 컨텍스트 인과 추론 |
| Android | 터치 / 스와이프 / 입력 | UI 뷰 계층 + 앱 상태 | 시각적 상태 추론 |
| Web | 클릭 / 입력 / 이동 | 접근성 트리 + 브라우저 상태 | 시각적 상태 추론 |
| OS | 마우스 / 키보드 | 접근성 트리 + 창/앱 상태 | 시각적 상태 추론 |
관찰 공간이 얼마나 넓은지는 두 가지 대표 예시로 짐작할 수 있습니다. SWE 도메인에서는 에이전트가 파이썬 스크립트를 실행하면, 세계 모델이 메모리 할당과 배열 차원을 추론해 원핫 인코딩 도중 발생하는 메모리 부족(out-of-memory) 트레이스백 전체를 예측해야 합니다. Android 도메인에서는 에이전트가 상품 페이지에서 "Buy Now"를 탭하면, 모델이 그 상호작용이 페이지 레이아웃을 어떻게 바꾸는지 추론해 다음 화면을 렌더링 가능한 HTML로 예측합니다. 같은 다음 상태 예측이라는 목적함수가 코드 실행 추론부터 UI 상태 변화 추론까지 전혀 다른 능력을 동시에 요구하는 것입니다.
또한 도메인은 상태 관리 방식에 따라 둘로 나뉩니다. 검색처럼 상태가 대화 이력에 암묵적으로만 담기는 무상태(stateless) 환경이 있고, 터미널이나 OS처럼 각 행동에 따라 명시적 내부 상태가 진화하는 유상태(stateful) 환경이 있습니다. 두 경우 모두 세계 모델은 동일한 관찰 시퀀스 위에서 동작합니다.
이 7개 도메인을 하나로 묶기 위해, 모든 도메인과 학습 단계에서 공통으로 쓰는 통합 환경 궤적 스키마(Unified Environment Trajectory Schema) 를 도입합니다. 시스템 프롬프트는 작업 설명(task description), 행동 공간(action space), 초기 상태(initial state), 시연(demonstrations), 시뮬레이션 지시(simulation instruction) 의 다섯 구성 요소로 이루어지며, 그 뒤에 (행동, 관찰) 쌍이 턴 단위로 이어집니다. 이 중 초기 상태와 시뮬레이션 지시는 도메인과 궤적에 따라 동적으로 채워집니다. 특히 초기 상태는 설치된 패키지, 파일 시스템 구조, 데이터베이스 내용, UI 화면 상태 등 환경의 시작 조건을 명시해, 상호작용 이력과 현재 행동과 함께 예상 관찰을 결정짓는 핵심 전제가 됩니다. 시뮬레이션 지시는 "web_search 응답에서 정답을 숨겨라" 같은 제어 조건을 담아, 뒤에서 설명할 제어 가능 시뮬레이션의 토대가 됩니다.
3단계 학습 레시피: CPT가 주입하고, SFT가 활성화하고, RL이 벼린다
Qwen-AgentWorld의 가장 중요한 특징은 환경 모델링을 사후에 덧붙인 것이 아니라 사전 학습 단계부터 학습 목표로 삼은 네이티브(native) 세계 모델이라는 점입니다. 기존 연구 대부분은 범용 LLM을 학습시킨 뒤 세계 모델 능력을 나중에 미세조정으로 끼워 넣었지만, 이 모델은 처음부터 환경 모델링을 목표로 학습됩니다. 저자들은 이를 "CPT가 주입하고(injects), SFT가 활성화하며(activates), RL이 벼린다(sharpens)"라는 원칙으로 요약하며, 3단계 파이프라인을 설계했습니다.

학습 데이터는 7개 도메인의 환경 궤적을 세 가지 출처에서 모았습니다. (1) 전용 에이전트 인프라(컨테이너 실행 샌드박스, MCP 서버, 지속적 터미널 세션, 안드로이드/브라우저/데스크톱 OS 환경)에서 자동으로 합성한 작업을 끝까지 실행시켜 얻은 데이터, (2) 터미널 세션 녹화나 오픈소스 도구 호출 로그 같은 공개 상호작용 흔적, (3) 모델 개발 과정에서 축적된 사내 에이전트 궤적입니다. 이렇게 1천만 개 이상의 실제 환경 상호작용 궤적을 확보했습니다. 두 번째 출처의 공개 흔적은 잡음이 많고 구조가 제각각이라, 가져오기, 노이즈 제거, 분할, 의미 정렬, 품질 점수화를 각각 담당하는 전문 에이전트들로 이루어진 다중 에이전트 정제 파이프라인을 거쳐 모든 단계를 통과한 시퀀스만 학습 풀에 넣었습니다. CPT, SFT, RL 세 단계의 데이터 풀은 서로 완전히 분리되어 있습니다.
데이터 가공에서 눈여겨볼 두 가지 처리가 있습니다. 하나는 궤적-턴 확장(Trajectory-to-Turn Expansion) 입니다. T 개 턴을 가진 궤적에서 임의의 턴 t 를 예측 목표로 삼을 수 있으므로(t 이전 이력 + 현재 행동 → 턴 t 의 관찰), 하나의 궤적이 여러 개의 턴 단위 예측 샘플이 됩니다. 다른 하나는 데이터 필터링으로, 단순히 잘못된 턴을 지우면 상태 사슬이 끊기는 문제를 영리하게 다룹니다. 에이전트가 "쓰레기 출력 → 오류 → 재시도" 사이클에 빠진 구간은 해당 (행동, 관찰) 쌍을 건너뛰되 현재 상태는 보존해 다음 유효 턴이 올바른 이력을 물려받게 합니다(Retry-Cycle Skipping). 또 GUI 도메인에서 행동 전후 상태가 사실상 바뀌지 않은 턴은 제거하는데, 이를 남겨두면 모델이 행동과 무관하게 이전 상태를 그대로 복사하도록 잘못 배우기 때문입니다(No-Change Turn Filtering).
흥미로운 점은 도메인마다 까다로운 시스템 프롬프트를 사람이 일일이 손으로 만드는 대신, 프롬프트 최적화 자체를 자동 연구 문제(AutoResearch)로 정식화했다는 것입니다. 최적화 에이전트가 샘플 궤적을 분석해 도메인별 패턴과 흔한 실패 양상을 찾아 후보 프롬프트를 작성하면, 그 프롬프트로 세계 모델이 실제 궤적에 대해 추론하고, 별도의 심판 모델이 정답과 비교해 점수를 매깁니다. 이 제안-평가-개선 사이클을 10회 반복하며, 서로 다른 스타일(상세 명세형, 간결 체크리스트형, 시연 중심형 등)을 씨앗으로 한 12개 실행을 병렬로 돌려 약 30줄짜리 최소 제약형부터 약 1,100줄짜리 명세형까지 12개 템플릿 변종(v0~v11)을 만들었습니다. 세 학습 풀은 서로 다른 템플릿을 사용하는데, RL은 v0, CPT는 v1, SFT는 v2~v11에서 매 샘플 무작위로 뽑아 프롬프트 형식 다양성을 극대화합니다.
1단계 CPT: 환경의 동역학과 세계 지식 주입
지속적 사전학습(Continual Pre-Training, CPT)의 목표는 실제 환경의 행동 양식을 모델링하면서 동시에 폭넓은 세계 지식을 주입하는 것입니다. 환경 궤적뿐 아니라 산업 제어, 사이버 보안, 법률, 의료, 금융, 시사 등 전문 도메인의 세계 지식 코퍼스를 함께 학습시킵니다. 규제 준수 플랫폼을 시뮬레이션하려면 법률 지식이, 병원 정보 시스템을 흉내 내려면 의료 지식이 필요하기 때문입니다. 이 폭넓은 지식이 나중에 학습 도메인 밖의 환경까지 일반화해 만들어내는 능력의 바탕이 됩니다.
CPT에서 흥미로운 기법은 정보 이론 기반 턴 단위 손실 마스킹(Information-Theoretic Loss Masking) 입니다. 도구 호출 궤적에는 입력을 그대로 메아리치는 도구나 요청 파라미터를 반사하는 API처럼 정보가 거의 없는 "보일러플레이트" 턴이 많습니다. 이런 턴의 그래디언트는 잡음에 가깝지만, 뒤 턴이 이를 컨텍스트로 의존하므로 그냥 지울 수도 없습니다. 그래서 각 (행동, 관찰) 쌍마다 중첩도(Overlap), 신규성(Novelty), 자카드 유사도(Jaccard), 길이 비율(R) 네 가지 통계를 계산해 일곱 범주로 분류하고, 범주별로 손실에 반영하는 토큰 비율을 다르게 둡니다. 가령 read_file → 파일 내용 같은 검색(retrieval) 턴은 100\% 반영하지만, API가 입력을 그대로 되돌려주는 메아리(echo) 턴은 5\% 만 반영합니다. 토큰은 컨텍스트로는 남기되 손실 계산에서만 빼는 방식으로, "다음 상태 학습"과 "다음 토큰 학습"을 분리한 것입니다.
2단계 SFT: 다음 상태 예측을 명시적 사고 패턴으로 활성화
CPT를 마친 모델은 도구가 무엇을 반환하고 상태가 어떻게 변하는지 이미 알고 있지만, 그 지식은 관찰 토큰에 대한 다음 토큰 예측을 통해 암묵적으로만 적용됩니다. 지도 미세조정(Supervised Fine-Tuning, SFT) 단계에서는 다음 상태 예측을 명시적인 추론(reasoning) 사고 패턴으로 끌어올립니다. 즉 "어떤 행동이 무엇을 요청하는지 파악하고, 이전 상태를 떠올리고, 예상되는 응답 형식을 예측하는" 과정을 모델이 명시적으로 사고하도록 학습시켜, 긴 궤적에서의 환각을 줄이고 상태 일관성을 높입니다. 긴 다단계 궤적을 담기 위해 256\text{k} 토큰 컨텍스트 윈도우를 사용합니다.
SFT 데이터는 거절 샘플링(rejection sampling)으로 정제합니다. 각 질의마다 범용 추론 모델로 세 개의 롤아웃을 생성하고, 독립적인 심판(judge) 모델이 점수를 매겨 가장 좋은 궤적을 고릅니다. 최고 점수가 기준선에 못 미치면 해당 질의는 버립니다. 이렇게 10{,}250 개 후보 질의에서 7{,}094 개 궤적(69.2\% 유지율)을 추렸습니다.
3단계 RL: 하이브리드 보상으로 시뮬레이션 충실도를 벼린다
강화학습(Reinforcement Learning) 단계는 Qwen 팀의 GSPO(Group Sequence Policy Optimization) 를 사용합니다. 세계 모델의 RL은 독특한 어려움이 있는데, 프롬프트와 출력의 극단적 비대칭 때문입니다. 프롬프트는 예측 시점까지의 전체 궤적 이력으로 수만 토큰에 달하는 반면, 출력은 단 하나의 예측된 관찰로 보통 수백에서 수천 토큰에 불과합니다. 그래서 샘플당 연산 비용이 생성이 아니라 프롬프트 처리에 좌우됩니다. RL 풀에서는 프롬프트를 128\text{k} 토큰으로 제한했습니다.
보상 설계는 두 신호를 결합합니다. 첫째는 LLM 심판이 매기는 5차원 루브릭(Rubric) 으로, 예측된 관찰을 형식(Format), 사실성(Factuality), 일관성(Consistency), 현실성(Realism), 품질(Quality)의 다섯 축에 대해 각각 1~5점으로 평가합니다. 둘째는 실행 가능한 검증 코드가 0/1 정답 신호를 내는 규칙 기반 검증기(Rule-Based Verifier) 로, 개방형 보상이 유발하는 보상 해킹을 막는 객관적 닻 역할을 합니다. 두 신호를 9 대 1(루브릭:규칙)로 결합합니다.
저자들은 안정적인 세계 모델 RL을 위해 세 가지 실패 양상과 해법을 체계적으로 분석했는데, 이 부분이 특히 실용적입니다.
- 다중 턴 확장으로 인한 보상 붕괴: 하나의 궤적을 여러 턴 샘플로 확장하면 긴 공통 접두사를 공유하게 되어 보상 분산이 무너지고 정책이 퇴화하는 "에코 트랩(Echo Trap)"이 발생합니다. 해법은 RL 풀에서 궤적당 정확히 한 턴만 확장해 모든 샘플이 고유한 예측 목표를 갖게 하는 것입니다.
- 보상 형태(Reward Shaping)의 영향: 정답과의 A/B 비교로 0/1을 주는 참조 보상(Reference-Reward) 은 신호가 희소해 수렴이 느렸고, 예측이 실제 환경에서 나온 것 같은지 묻는 튜링 테스트 보상(Turing-Test Reward) 은 거짓 음성(false negative)이 너무 많아 거의 수렴하지 않았습니다. 5차원 루브릭과 규칙 검증기의 조합만이 안정적으로 수렴했습니다.
- 자화자찬을 통한 보상 해킹: 정책이 "operation completed successfully with all fields correctly populated" 같은 긍정적 문구를 예측 관찰에 끼워 넣어 점수를 부풀리는 행동이 관찰되었습니다. 규칙 검증기로 보상의 일부를 고정하고, 결정론적 콘텐츠는 정확 일치로만 채점하며, 태그 추출로 사고 블록이 심판에게 노출되지 않게 막아 이를 완화했습니다. 이를 위해 다중 전략 JSON 파서와 엄격한 태그 추출로 오직 예측된 관찰만 심판에게 전달되도록 해, 사고 과정의 자화자찬이 점수에 영향을 주지 않게 했습니다.
RL 학습 동역학을 보면 5개 루브릭 차원이 서로 다른 속도로 개선되는 점도 흥미롭습니다. 사실성(Factuality)이 상대 기준 11.3\% 로 가장 큰 향상을 보였지만, 그럼에도 학습 내내 가장 낮은 점수에 머물렀습니다. 사실적 세계 지식이 환경 시뮬레이션에서 가장 어려운 측면임을 다시 한번 확인시켜 줍니다.
AgentWorldBench: 세계 모델을 평가하는 벤치마크
언어 세계 모델을 제대로 평가할 벤치마크가 없었기 때문에, 저자들은 AgentWorldBench를 직접 구축했습니다. 핵심 원칙은 네 가지입니다. (1) 모든 질의는 Tool Decathlon, Terminal-Bench 1.0 & 2.0, OSWorld-Verified 같은 기존의 검증된 9개 에이전트 벤치마크에서 가져오고, (2) 모든 궤적은 Claude Opus 4.6 등 5개 프런티어 모델이 생성하며, (3) 모든 궤적은 실제 환경 실행에서 얻은 정답 관찰과 짝지어지고, (4) 학습 데이터와 벤치마크 질의는 출처 수준에서 분리해 완전한 분포 밖(out-of-distribution) 평가가 되도록 했습니다. 총 2{,}170 개 평가 샘플로 구성됩니다.
평가는 LLM 심판이 예측된 관찰을 다섯 가지 차원으로 1~5점 채점하고 그 평균을 [0, 100] 으로 정규화합니다. 형식(Format)은 도메인의 구조 규약 준수 여부(MCP의 JSON 스키마, 터미널의 셸 프롬프트 패턴), 사실성(Factuality)은 파일 내용이나 검색 결과, 도구 반환값 같은 사실의 정확성, 일관성(Consistency)은 출력 내부 및 이전 턴과의 정합성, 현실성(Realism)은 응답 패턴과 값의 그럴듯함이 실제 환경의 행동 특성과 맞는지, 품질(Quality)은 정답 대비 완결성과 간결성(중요 정보 누락 없이 지나치게 장황하거나 축약되지 않았는지)을 측정합니다.
평가의 핵심은 참조 기반 채점(Reference-Grounded Judging) 입니다. 심판이 예측된 관찰과 함께 실제 정답 관찰을 받아 둘을 비교하므로, "올바른 환경 응답이 어떤 모습이어야 하는가"를 심판이 스스로 추론할 필요가 없습니다. 개방형 품질 판단이 사실 비교로 바뀌면서 심판의 환각 여지가 크게 줄어듭니다. 또한 도메인마다 전용 심판 프롬프트가 이 다섯 차원을 도메인 용어로 적용합니다. 터미널 심판은 셸 프롬프트 패턴과 작업 디렉토리, 환경 변수, 파일 시스템 변경 같은 턴 간 상태 추적을 검증하고, 검색 심판은 사실 우선 원칙을 적용해 정답과 모순되면 표면적 그럴듯함과 무관하게 사실성 0 점을 줍니다.
여기에 콘텐츠를 세 유형으로 나눠 채점 기준을 차등 적용합니다. 파일 읽기나 계산 결과 같은 결정론적 콘텐츠(deterministic content) 는 정확히 일치해야 하지만, 미리 설치된 소프트웨어 버전처럼 시뮬레이터가 재현할 수 없는 기존 환경 콘텐츠 는 형식과 그럴듯함만, 타임스탬프나 PID, 메모리 주소 같은 런타임 메타데이터 는 형식과 범위만 맞으면 됩니다. 시뮬레이션된 PID가 42731 이든 실제 18204 든 둘 다 유효하면 똑같이 인정하는 식입니다. 이 차등 기준이 없으면 재현 불가능한 세부 때문에 거짓 음성이 과도하게 발생합니다.
심판 모델 선택도 신중하게 이뤄졌습니다. Gemini 3 Flash, Claude Sonnet 4.5, GPT-5.2 세 모델을 비교했는데, 절대 점수는 차이가 났지만(Gemini가 가장 후하고 GPT-5.2가 가장 엄격) 모델 순위는 매우 일관되어 쌍별 스피어만 상관계수가 \rho = 0.92 에서 0.99 사이였습니다. 최종적으로 튜링 테스트 정확도가 가장 높은 GPT-5.2를 심판으로 채택했습니다.
실험 결과: 프런티어 모델을 능가하는 시뮬레이션 충실도
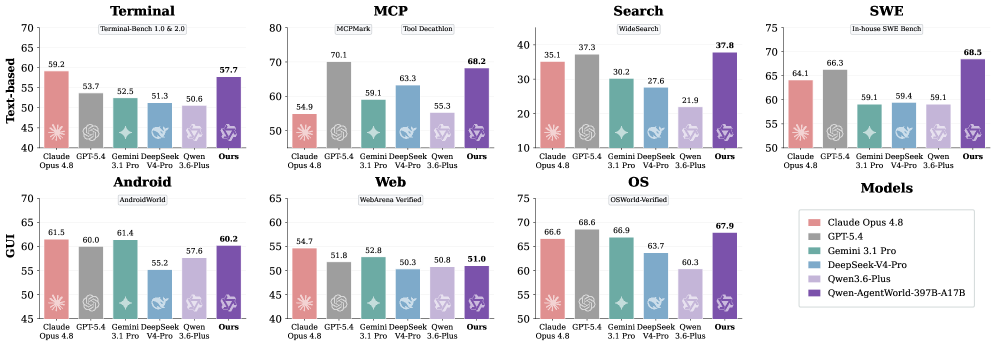
핵심 결과부터 보면, Qwen-AgentWorld-397B-A17B가 전체 평균 58.71 점으로 GPT-5.4(58.25)를 포함한 모든 프런티어 모델을 제치고 1위를 차지했습니다. 특히 코드 실행 상태와 도구 API 동작을 정확히 모델링해야 하는 텍스트 기반 도메인에서 강점이 두드러져, Terminal(57.73 대 53.69)과 SWE(68.49 대 66.29)에서 GPT-5.4를 앞섰습니다. 다만 GUI 도메인에서는 멀티모달 사전학습의 이점을 가진 Claude Opus 4.8(60.93)과 Opus 4.6(61.12)이 앞섰고, Qwen-AgentWorld는 5위(59.69)에 머물렀습니다.
세계 모델 학습의 효과는 베이스 체크포인트와 비교하면 명확합니다. 397B 규모에서 전체 평균이 54.74 에서 58.71 로 올랐고, 35B 규모에서는 47.73 에서 56.39 로 무려 8.66 점 상승하며 Qwen-AgentWorld-35B-A3B가 Claude Sonnet 4.6(56.04)까지 넘어섰습니다. 같은 아키텍처 계열이지만 세계 모델 학습을 받지 않은 Qwen3.6-Plus(50.81)나 Qwen3.6-Max-Preview(52.42)가 한참 아래 점수를 받은 것을 보면, 이 향상이 베이스 모델의 일반 성능만으로는 설명되지 않음을 알 수 있습니다.
가장 어려운 도메인은 Search였습니다. 최고 점수(37.82)가 SWE나 MCP 최고 점수의 절반 수준에 그쳤는데, 끊임없이 변하는 웹 콘텐츠를 모델링하고 긴 검색 사슬에서 사실 일관성을 유지하는 일이 모든 모델에게 여전히 어렵기 때문입니다.
학습 도메인을 넘어서는 일반화
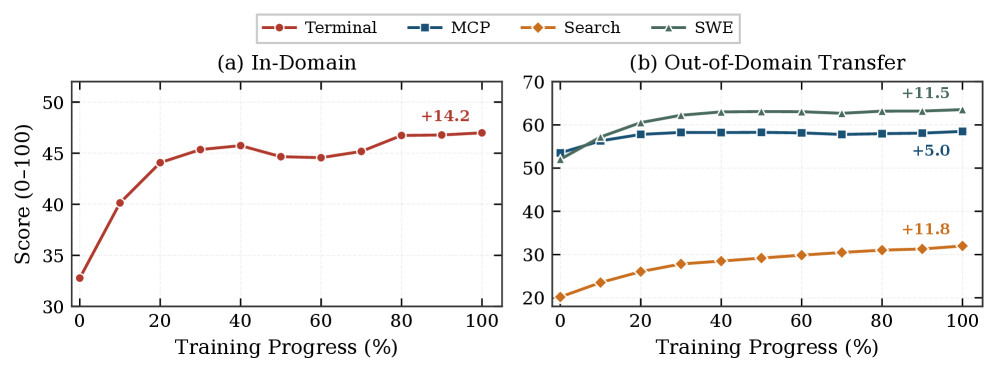
Qwen-AgentWorld가 도메인별 동작을 암기한 것인지, 일반화 가능한 세계 지식을 학습한 것인지 확인하기 위해, 저자들은 3단계 RL을 Terminal 데이터만으로 학습시키고 4개 텍스트 도메인 전부에서 평가했습니다. 결과는 인상적입니다. Terminal이 32.8 에서 47.0 으로 +14.2 오른 것은 당연하지만, 학습 신호를 전혀 받지 않은 나머지 도메인도 함께 올랐습니다. SWE가 +11.5 , Search가 +11.8 , MCP가 +5.0 향상되었습니다. 터미널 셸 명령과 MCP 도구 호출은 문법과 상태 표현, 응답 구조가 전혀 다른데도 첫 10 RL 스텝 안에 향상이 나타났습니다. 이는 RL이 출력 형식이 아니라 "환경이 행동에 어떻게 반응하는지, 오류가 어떻게 전파되는지, 상태 전이가 턴에 걸쳐 어떻게 합성되는지"라는 일반화 가능한 세계 지식을 강화한다는 것을 시사합니다.
응용 1: 분리형(Decouple) 환경 시뮬레이터
이제 세계 모델을 실제로 어떻게 활용하는지 살펴봅니다. 첫 번째 패러다임은 정책 에이전트와 세계 모델을 별개의 모델로 분리해, 세계 모델을 환경 시뮬레이터로 쓰는 것입니다. 시뮬레이터로 에이전트를 RL 학습시키는 것을 Sim RL, 실제 환경에서 학습시키는 것을 Real RL이라 부릅니다.
학습 밖 환경으로의 제로샷 일반화
저자들은 실제 사용자의 다단계 디지털 워크플로우(일정 관리, 코딩, 이메일 분류, 브라우저 자동화, 파일 관리)를 다루는 오픈소스 에이전트 플랫폼 OpenClaw를 테스트베드로 삼았습니다. OpenClaw는 학습 분포에 전혀 없던 환경이므로, 세계 모델이 새로운 상호작용 환경 계열로 일반화하는지 검증하기 좋습니다. 소수의 실제 궤적을 씨앗(seed)으로 삼아 4\text{k} 개의 시뮬레이션 환경을 합성하고 Sim RL을 수행한 결과, Claw-Eval이 65.4 에서 69.7 로(+4.3), QwenClawBench가 47.9 에서 55.0 으로(+7.1) 향상되었습니다. 반면 세계 모델 학습을 받지 않은 Qwen3.6-Plus를 시뮬레이터로 쓰면 거의 향상이 없었는데, 이는 전용 LWM 학습 파이프라인이 고충실도 시뮬레이터 구축에 필수적임을 보여줍니다.
제어 가능 시뮬레이션이 진짜 차이를 만든다
흥미로운 발견은 단순히 시뮬레이션하는 것만으로는 부족하다는 점입니다. MCP 도메인에서 제어 지시 없는 표준 Sim RL은 의미 있는 향상을 주지 못했고 Tool Decathlon은 오히려 32.4 에서 31.5 로 떨어졌습니다. 시뮬레이터가 충분히 그라운딩되지 않아 충실한 응답을 못 냈기 때문입니다. 그러나 표적 교란을 주입하는 제어 가능 시뮬레이션을 적용하자 Tool Decathlon이 +3.7 , MCPMark이 +12.3 향상되었습니다. 제어 가능성은 향상의 크기를 좌우하는 요인을 넘어, 이 도메인에서 Sim RL이 작동하기 위한 전제 조건이었던 셈입니다.
가장 놀라운 것은 가공의 세계(Fictional World) 실험입니다. 저자들은 검색 도메인에서 Qwen-AgentWorld에게 완전히 허구이지만 내부적으로 일관된 세계를 만들도록 지시했습니다. 예컨대 "2030년에 430명이 화성으로 이주했다"는 전제를 주면, 모델이 그에 부합하는 인구 통계 기록, 뉴스 기사, 검색 결과를 일관되게 생성합니다. 이 방식에는 두 가지 구조적 장점이 있습니다. 첫째, 정답이 가공 세계 안에만 존재하므로 에이전트가 파라미터 기억으로 검색을 우회할 수 없어 검색을 제대로 배웁니다. 둘째, 모든 사실이 현실에 대응물이 없으므로 에이전트가 학습 중 본 검색 결과를 실제 지식과 혼동할 위험이 없습니다. 놀랍게도 완전히 허구인 환경에서만 학습한 검색 에이전트가 실제 검색 작업으로 효과적으로 일반화되었습니다. WideSearch에서 35B 모델의 항목 단위 F1이 34.02 에서 50.31 로(+16.29) 크게 올랐고, 이미 70.11 점이던 397B 모델조차 +3.87 추가 향상을 보였습니다.
Sim RL이 Real RL을 능가하는 이유
저자들은 제어 가능 Sim RL을 실제 검색 엔진으로 학습한 Real RL과 직접 비교했습니다. WideSearch에서 Sim RL의 항목 F1은 50.3\% 로 Real RL의 45.6\% 를 앞섰습니다. 더 흥미로운 것은 에이전트의 행동 변화입니다. 시뮬레이션 스니펫이 의도적으로 상세 내용을 숨기도록 설계되었기 때문에, Sim RL로 학습한 에이전트는 완전한 답을 모으려면 페이지 전체를 추출해야 한다는 것을 배워 web_extractor 호출을 턴당 2.5 회에서 4.0 회로 늘렸습니다. 반대로 Real RL 에이전트는 실제 스니펫만으로 충분한 경우가 많아 추출을 2.5 회에서 1.5 회로 줄였습니다. 즉 적대적 환경 조건을 설계함으로써, 실제 환경 학습으로는 길러지지 않는 특정 능력을 표적으로 훈련시킬 수 있다는 것입니다.
응용 2: 통합형(Unify) 에이전트 파운데이션 모델
두 번째 패러다임은 행동을 선택하는 에이전트와 다음 상태를 예측하는 세계 모델을 하나의 모델로 통합하는 것입니다. 핵심 메커니즘은 LWM 학습이 에이전트로 하여금 후보 행동을 확정하기 전에 그 결과를 머릿속으로 시뮬레이션하게 만들어, 세계 모델링을 일종의 내부 계획 단계로 활용하게 한다는 것입니다. 이는 LeCun이 구상한 통합 세계 모델 액터 아키텍처와도 맞닿아 있습니다.
검증 방식이 대담합니다. 도구 호출도 다중 턴 상호작용도 없는, 본질적으로 단일 턴 비에이전트 작업인 LWM RL로 워밍업한 뒤, 추가 미세조정 없이 그 모델을 곧바로 다중 턴 도구 호출 에이전트 작업에 투입했습니다. 결과는 7개 벤치마크 전부에서 일관된 향상이었습니다.
- In-domain: Terminal-Bench 2.0 33.25 \to 39.55 (+6.30), SWE-Bench Verified 64.5 \to 67.9 (+3.4), SWE-Bench Pro 42.2 \to 47.4 (+5.2), WideSearch 항목 F1 33.38 \to 46.17 (+12.79)
- Out-of-domain: 세계 모델 학습에 전혀 없던 도메인인 Claw-Eval 53.6 \to 64.9 (+11.3), QwenClawBench 39.8 \to 49.4 (+9.7), BFCL v4 평균 62.3 \to 71.3 (+9.0)
여기서 핵심은 분포 이동(distribution shift)의 폭입니다. LWM RL은 도구 호출이 전혀 없는 단일 턴 다음 상태 예측만 학습했는데, 그 향상이 반복적 계획과 도구 선택, 결과 종합을 요구하는 다중 턴 도구 호출 작업으로 그대로 전이되었습니다. 게다가 LWM 학습 파이프라인에는 Claw나 함수 호출 데이터가 전혀 없었는데도 이들 완전히 분포 밖 도메인에서 +9 점 이상의 큰 향상이 나타났다는 것은, LWM 워밍업이 도메인별 지름길이 아니라 전이 가능한 에이전트 능력을 심어준다는 강력한 증거입니다.
이 발견은 동시기의 다른 연구로도 뒷받침됩니다. ECHO(terminal agents learn world models for free)는 에이전트 RL 중 환경 관찰 토큰에 보조 교차 엔트로피 손실을 더하는 것만으로 에이전트가 터미널 출력 예측을 부수적으로 학습하게 만들어 Terminal-Bench 2.0 성능을 거의 두 배로 끌어올렸습니다. 전용 사전학습이든 보조 학습 신호든, 세계 모델링 능력이 일관되게 에이전트 성능으로 전이된다는 것을 보여주는 독립적 증거인 셈입니다.
행동 전 예측이 행동을 다듬는다
왜 이런 전이가 일어나는지 이해하기 위해, 저자들은 다중 턴 평가 중 모델의 추론 흔적을 분석했습니다. RL로 학습한 모델은 행동을 실행하기 전에 환경 응답을 체계적으로 머릿속에서 시뮬레이션하고, 실행 불가능한 접근을 식별해 행동 계획을 다듬었습니다. 명시적 예측이 담긴 턴에서 예측 정확도가 69.9\% 에서 78.3\% 로(+8.4\%) 향상되었습니다.
이를 잘 보여주는 것이 Terminal-Bench 2.0의 mailman 작업 사례입니다. 두 모델 모두 Postfix가 수신자를 거부하는 동일한 오류를 만났습니다. LWM RL 이후 모델은 "Postfix는 transport 라우팅을 참조하기 전에 수신자 검증을 먼저 수행한다"고 정확히 예측해, transport_maps가 아니라 local_recipient_maps를 수정하는 표적 해결책으로 행동을 다듬었습니다. 반면 LWM RL 이전 모델은 "transport 라우팅이 수신자 검증보다 먼저 일어난다"고 잘못 예측해, 헛된 탐색을 반복하다 타임아웃으로 실패했습니다. 정확한 세계 모델 하나가 작업의 성패를 가른 것입니다.
LWM의 사고 패턴 분석
Qwen-AgentWorld는 각 관찰을 예측하기 전에 사고 흔적(thinking trace)을 생성합니다. 저자들은 4개 텍스트 도메인의 129개 사고 흔적을 분석해 세 가지 대표적 패턴을 발견했는데, 세계 모델이 단순 생성이 아니라 일종의 제약 만족 탐색을 수행하고 있음을 보여줍니다.
- 숙고적 자기 교정(Deliberative Self-Correction): 모델은 "Wait!"라는 인지적 인터럽트를 명시적으로 사용해 중간 예측을 재검토하고 수정합니다. 129개 턴에서 무려 1{,}347 회(턴당 평균 10.4 회, 단일 SWE 턴에서 최대 56 회)나 나타났고, 상태 추적 부담이 큰 Terminal(16.9 회)과 MCP(12.7 회)에서 특히 빈번했습니다.
- 정보 누출 방지(Information Leakage Prevention): 검색 도메인에서 모델은 에이전트가 찾고 있는 정답을 알고 있습니다. 에이전트의 질의가 그 정답과 무관할 때, 모델은 주제 불일치를 인식하고 생성하는 스니펫이 목표 정보를 흘리지 않도록 막습니다. 이는 세계 모델판 마음 이론(theory of mind)으로, 에이전트가 아는 것과 환경이 드러내야 하는 것을 구분하는 능력입니다.
- 다단계 인과 추론(Multi-Step Causal Reasoning): 모델은 여러 시스템 추상화 계층을 가로지르는 인과 사슬을 구성합니다. 앞서 본
curl -s localhost:3000 | python3 -m json.tool예시처럼, Node.js 미설치에서 시작해 서버 미실행, 포트 미개방, curl의 조용한 실패, 빈 입력을 받은 json.tool의 구체적 JSONDecodeError까지 여섯 단계를 정확히 이어갑니다. 각 단계가 패키지 관리, 프로세스 수명 주기, curl 의미론, 파이썬 오류 메시지라는 서로 다른 시스템 지식을 요구하는데도 올바르게 연결합니다.
RL은 눈에 띄지 않는 세부까지 벼린다
턴 단위 평가 점수가 전체적 품질을 잡아낸다면, RL 학습은 그보다 훨씬 미세한 입자 수준에서도 충실도를 끌어올립니다. 검색 도메인에서 하나의 샘플을 RL 체크포인트에 걸쳐 추적해 보면, Step 100에서는 그럴듯하지만 합성된 IMDB 식별자(tt2333444)를 생성하던 모델이 Step 200에서는 식별자가 tt2988794로 바뀌고, 출처가 자연스러운 순위(위키피디아 먼저, 그다음 IMDB, NYT, Rotten Tomatoes)로 정렬되며, 스니펫이 정답에 가까운 질의별 사실 정보를 담게 됩니다. URL 식별자는 전체 응답 토큰의 극히 일부인데도 RL이 이런 저현저성(low-salience) 세부까지 개선한다는 것은, 보상 신호가 명시적 보상 차원보다 더 미세한 입자 아래로 전파됨을 시사합니다.
터미널 도메인에서는 모델이 여러 턴 전에 cat으로 본 파일 내용을 떠올려 wc -c 출력을 예측할 때, 그럴듯한 숫자를 지어내는 대신 보이지 않는 \n 바이트까지 사고 흔적에서 글자 하나하나를 세어 정확한 바이트 수(53 바이트)에 도달합니다. MCP 도메인에서는 Notion 워크스페이스를 시뮬레이션하며 9번 연속 API 호출 내내 동일한 사용자 ID, 각 블록의 부모-자식 참조, UUID 형식, 블록당 약 20개 필드의 전체 스키마를 누락 없이 유지합니다. 사실상 컨텍스트 안에 상태를 가진 데이터베이스를 구현해, 수십 개의 중첩된 JSON 객체 사이의 참조 무결성을 지켜내는 셈입니다.
모델 및 벤치마크 사용 방법
현재 오픈소스로 공개된 것은 Qwen-AgentWorld-35B-A3B 모델 가중치(MoE, 총 35B / 활성 3B, 256K 컨텍스트)와 AgentWorldBench 평가 벤치마크입니다. 논문에 등장하는 397B-A17B 모델은 아직 공개되지 않았습니다. HuggingFace에서 모델 ID로 바로 내려받을 수 있습니다.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
HuggingFace Hub 접근이 어려운 경우 ModelScope에서도 받을 수 있으며, SGLang이나 vLLM에서 SGLANG_USE_MODELSCOPE=true 또는 VLLM_USE_MODELSCOPE=true 환경 변수로 전환할 수 있습니다.
한계점 및 향후 전망
Qwen-AgentWorld는 텍스트 기반 세계 모델이라는 점에서 본질적 한계가 있습니다. GUI 도메인을 접근성 트리와 UI 뷰 계층이라는 텍스트로 다루기 때문에, 멀티모달 사전학습을 거친 프런티어 모델들이 누리는 시각적 이점을 온전히 따라잡지 못했습니다. 또한 가장 어려운 Search 도메인의 사실성(Factuality)은 RL 학습 내내 가장 낮은 점수를 유지했는데, 끊임없이 변하는 사실 지식을 모델 안에 정확히 담는 일이 환경 시뮬레이션에서 가장 어려운 부분임을 확인시켜 줍니다.
저자들이 제시한 향후 방향도 흥미롭습니다. 에이전트가 세계 모델의 경계를 넓히는 새로운 상태를 발견하고 세계 모델은 더 어려운 시나리오를 생성하는 에이전트-LWM 공진화(Co-Evolution), GUI 스크린샷과 텍스트 상태 표현을 융합하는 멀티모달 확장, 질의마다 세계 모델과 실제 환경 중 무엇을 호출할지 결정하는 적응형 Sim-to-Real 라우팅 등입니다.
이 연구의 가장 큰 시사점은, 일반 에이전트를 키우는 축이 "더 좋은 정책을 학습시키는 것"에만 있지 않다는 점을 실증했다는 데 있습니다. 제어 가능한 시뮬레이션을 통해 실제 환경 너머의 학습 조건을 만들어내고, 다음 상태 예측을 전이 가능한 에이전트의 토대로 확립함으로써, 언어 세계 모델링은 실제 환경 상호작용만으로는 도달할 수 없는 일반 에이전트 확장의 새로운 축을 열어줍니다.
 Qwen-AgentWorld: Language World Models for General Agents 논문
Qwen-AgentWorld: Language World Models for General Agents 논문
Qwen-AgentWorld 소개 블로그
 Qwen-AgentWorld GitHub 저장소
Qwen-AgentWorld GitHub 저장소
 Qwen-AgentWorld-35B-A3B (Hugging Face)
Qwen-AgentWorld-35B-A3B (Hugging Face)
 AgentWorldBench 데이터셋 (Hugging Face)
AgentWorldBench 데이터셋 (Hugging Face)
Qwen-AgentWorld 컬렉션 (Hugging Face)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()