
Qwen2-VL 모델 소개 (2B / 7B / 72B)
Qwen2-VL은 지난 8월 30일 공개된 Qwen 모델 패밀리의 최신 버전으로, 시각적 언어 이해 능력을 크게 향상시킨 AI 모델입니다. 이 모델은 다양한 해상도와 비율의 이미지를 분석할 수 있으며, 복잡한 영상의 시각적 데이터를 처리할 수 있는 기능을 갖추고 있습니다. 특히 Qwen2-VL은 Qwen-VL의 후속 버전으로, 이미지와 비디오를 동시에 이해할 수 있는 능력을 갖추고 있습니다. 이를 통해 사용자는 이미지 기반의 질문 응답, 대화형 콘텐츠 생성, 시각적 환경 분석 등의 작업을 수행할 수 있습니다.
Qwen2-VL은 20분 이상의 비디오를 이해할 수 있는 고급 비디오 분석 능력을 갖추고 있으며, 다양한 모바일 장치나 로봇과 통합되어 자동화된 작업을 수행할 수 있는 에이전트 기능도 제공합니다. 이러한 기능을 통해 모바일 기기나 로봇의 시각적 환경을 인식하고, 텍스트 지시에 따라 자동으로 작업을 수행할 수 있습니다. 또한 Qwen2-VL은 영어와 중국어뿐만 아니라 유럽 언어, 일본어, 한국어, 아랍어, 베트남어 등을 포함한 다국어 텍스트 이해 기능도 제공합니다.
Qwen2-VL의 다양한 모델들은 Apache 2.0 라이선스 하에 오픈소스로 제공되며, 2B와 7B의 모델이 Hugging Face Transformers, vLLM, 기타 서드파티 프레임워크에 통합되어 있습니다. Qwen2-VL-72B 모델은 DashScope을 통해 API로도 제공됩니다. 이러한 접근성은 개발자들이 Qwen2-VL을 다양한 애플리케이션에 활용할 수 있게 하여, 더 나은 시각적 언어 이해 모델로 발전시키고자 하는 목표를 반영합니다.
Qwen2-VL의 성능
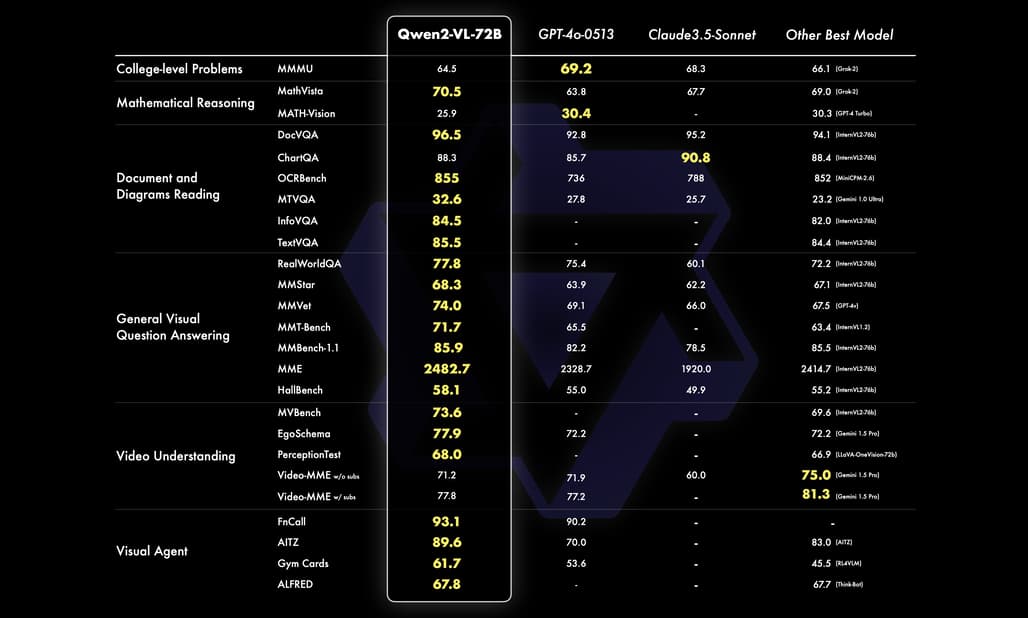
Qwen2-VL의 성능은 복잡한 대학 수준의 문제 해결, 수학적 능력, 문서 및 테이블 이해, 다국어 텍스트-이미지 이해, 일반적인 시나리오 질문 응답, 비디오 이해 및 에이전트 기반 상호작용 등 여섯 가지 핵심 차원에서 평가되었습니다. 특히 Qwen2-VL-72B 모델은 대부분의 시각적 이해 벤치마크에서 최고 수준의 성능을 보였으며, GPT-4o 및 Claude 3.5-Sonnet과 같은 폐쇄형 모델보다도 우수한 결과를 기록했습니다. 이 모델은 특히 문서 이해에서 탁월한 성과를 나타냈으며, 복잡한 시각적 문제를 해결하는 데 강점을 보였습니다.
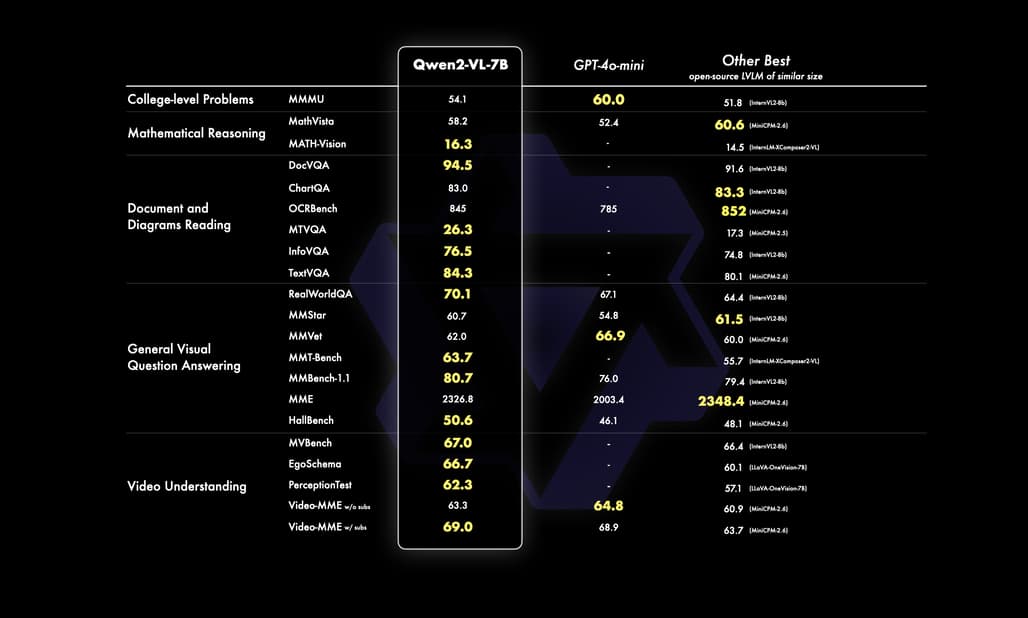
Qwen2-VL-7B 모델은 비용 효율성을 고려한 중간 크기의 모델로, 이미지, 다중 이미지 및 비디오 입력을 지원합니다. 이 모델은 DocVQA와 같은 문서 이해 작업과 MTVQA를 통한 다국어 텍스트 이해에서 우수한 성능을 발휘하며, 작지만 강력한 기능을 제공합니다. 이러한 특성은 비싼 대형 모델에 접근할 수 없는 사용자들에게 매력적입니다. 7B 모델은 특히 비용 대비 성능이 중요한 환경에서 효과적으로 활용될 수 있습니다.
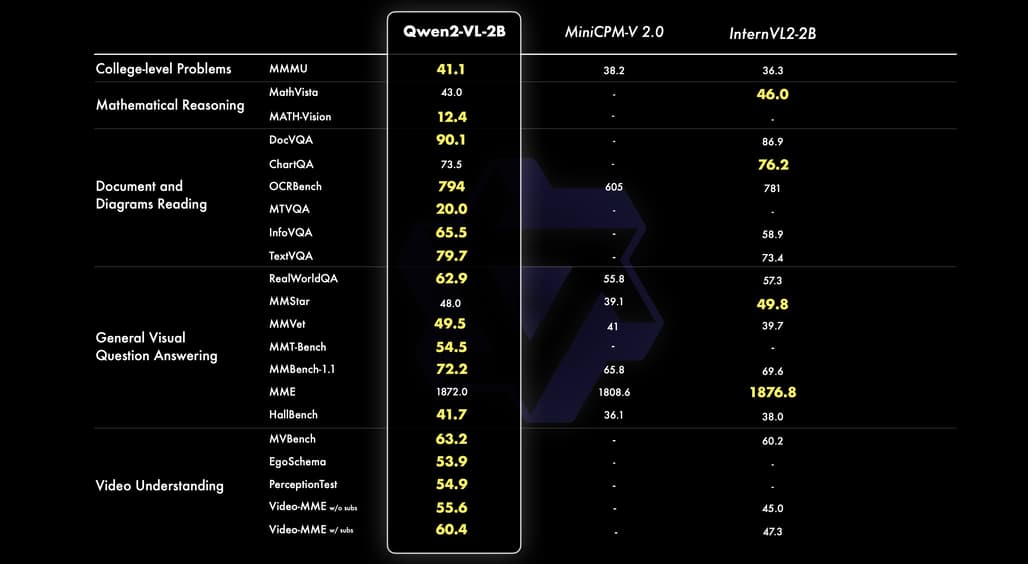
Qwen2-VL의 가장 작은 모델인 2B 모델은 모바일 장치에서의 사용을 위해 최적화되었습니다. 이 모델은 작은 크기에도 불구하고 이미지, 비디오, 다국어 이해에서 강력한 성능을 발휘하며, 특히 비디오 관련 작업과 문서 이해, 일반적인 시나리오 질문 응답에서 두드러진 성과를 보입니다. 이는 다른 유사한 크기의 모델과 비교했을 때 상당히 우수한 결과이며, 모바일 및 임베디드 환경에서의 활용 가능성을 크게 확대합니다.
Qwen2-VL의 주요 기능 및 특징
향상된 인식 능력
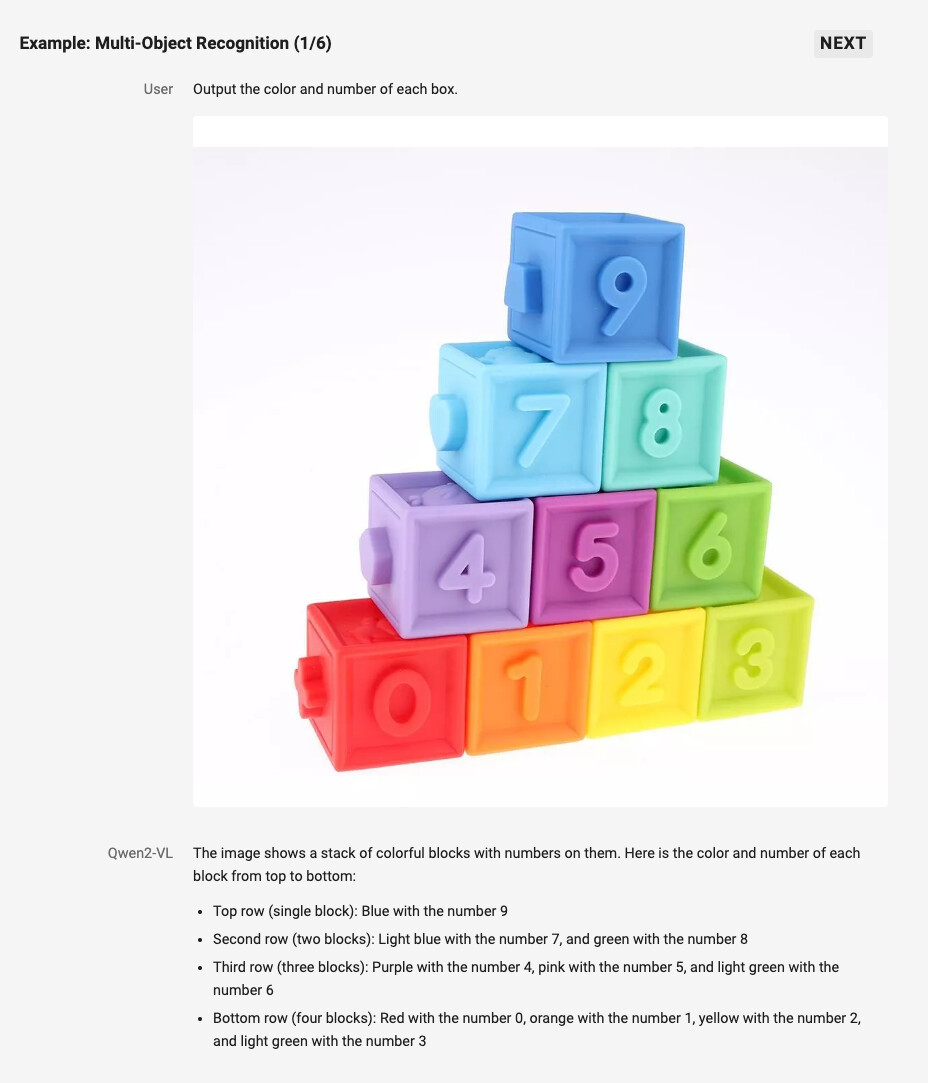

Qwen2-VL은 기존 모델보다 향상된 객체 인식 능력을 제공합니다. 이는 단순히 특정 식물이나 랜드마크를 인식하는 것을 넘어, 한 장면에서 여러 객체 간의 복잡한 관계를 이해하는 데까지 발전했습니다. 이 기능은 이미지 속 여러 객체의 상호작용을 보다 정확하게 해석할 수 있게 해주며, 이를 통해 복잡한 상황을 이해하고 적절한 응답을 생성할 수 있습니다. 또한, 손글씨 텍스트 인식과 다국어 텍스트 인식 능력도 크게 향상되어 전 세계 사용자들이 보다 쉽게 접근할 수 있습니다.


예를 들어, Qwen2-VL은 여러 색상과 번호가 있는 상자들을 정확하게 식별하고 그 위치와 색상, 번호를 설명할 수 있습니다. 이러한 다중 객체 인식은 사용자로 하여금 복잡한 시각 정보를 쉽게 파악하고 활용할 수 있도록 도와줍니다. 이는 물리적 환경에서의 시각적 데이터를 효과적으로 분석할 수 있게 해주는 중요한 기능입니다.



이 모델은 다국어 이미지 이해에서도 뛰어난 성능을 보입니다. Qwen2-VL은 영어와 중국어뿐만 아니라 다양한 유럽 언어, 일본어, 한국어, 아랍어 등을 포함한 언어의 텍스트를 인식하고 이해할 수 있습니다. 이러한 다국어 지원은 글로벌 사용자들에게 큰 이점을 제공하며, 특히 비즈니스 환경에서 다국어 문서나 표를 분석하고 해석하는 데 매우 유용합니다.
시각적 추론: 현실 세계의 문제 해결
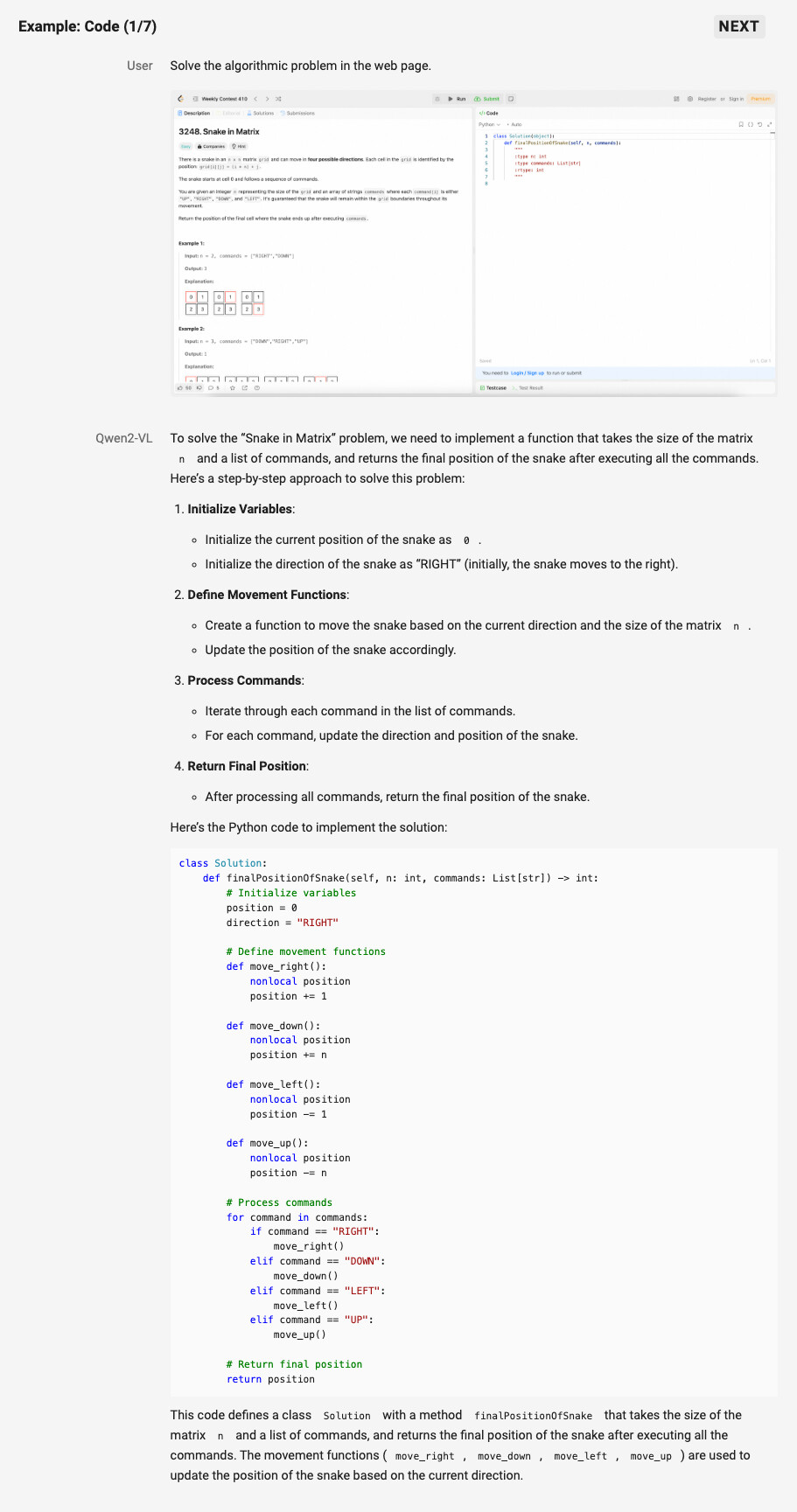
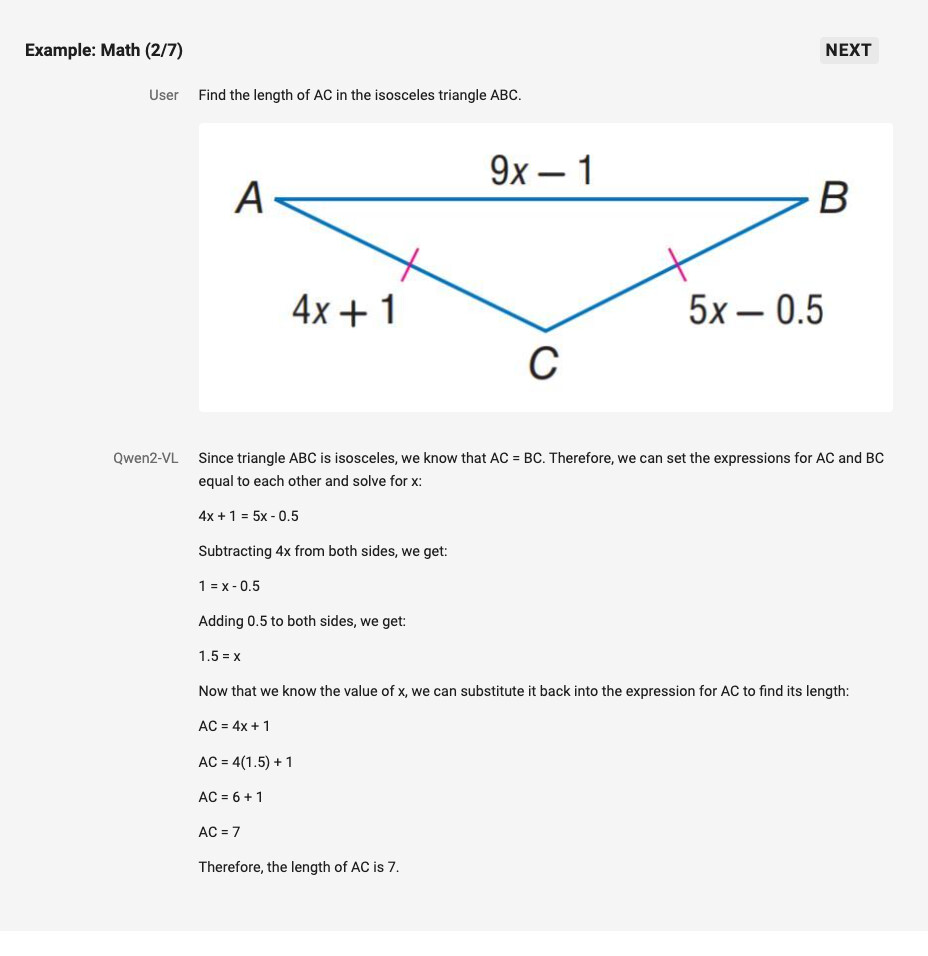
Qwen2-VL은 향상된 시각적 추론 능력을 갖추고 있어 복잡한 수학적 문제나 프로그래밍 문제도 해결할 수 있습니다. 모델은 이미지를 분석하여 수학적 그래프나 차트에서 데이터를 추출하고, 이를 바탕으로 복잡한 문제를 해결할 수 있습니다. 이러한 능력은 특히 교육 및 연구 분야에서 매우 유용하며, 수학적 개념을 시각적으로 표현하고 이를 통해 추론하는 과정을 자동화할 수 있습니다.
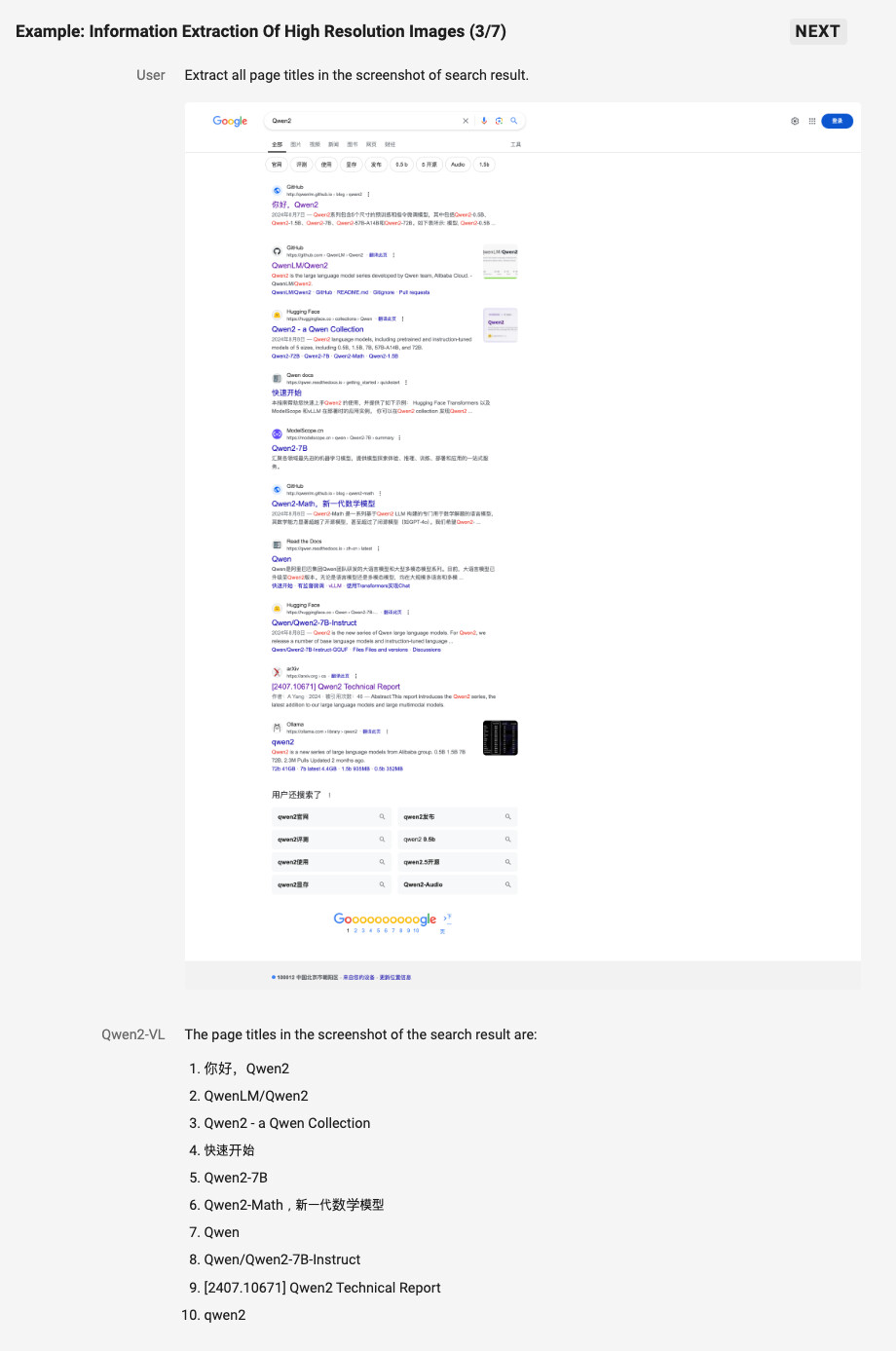
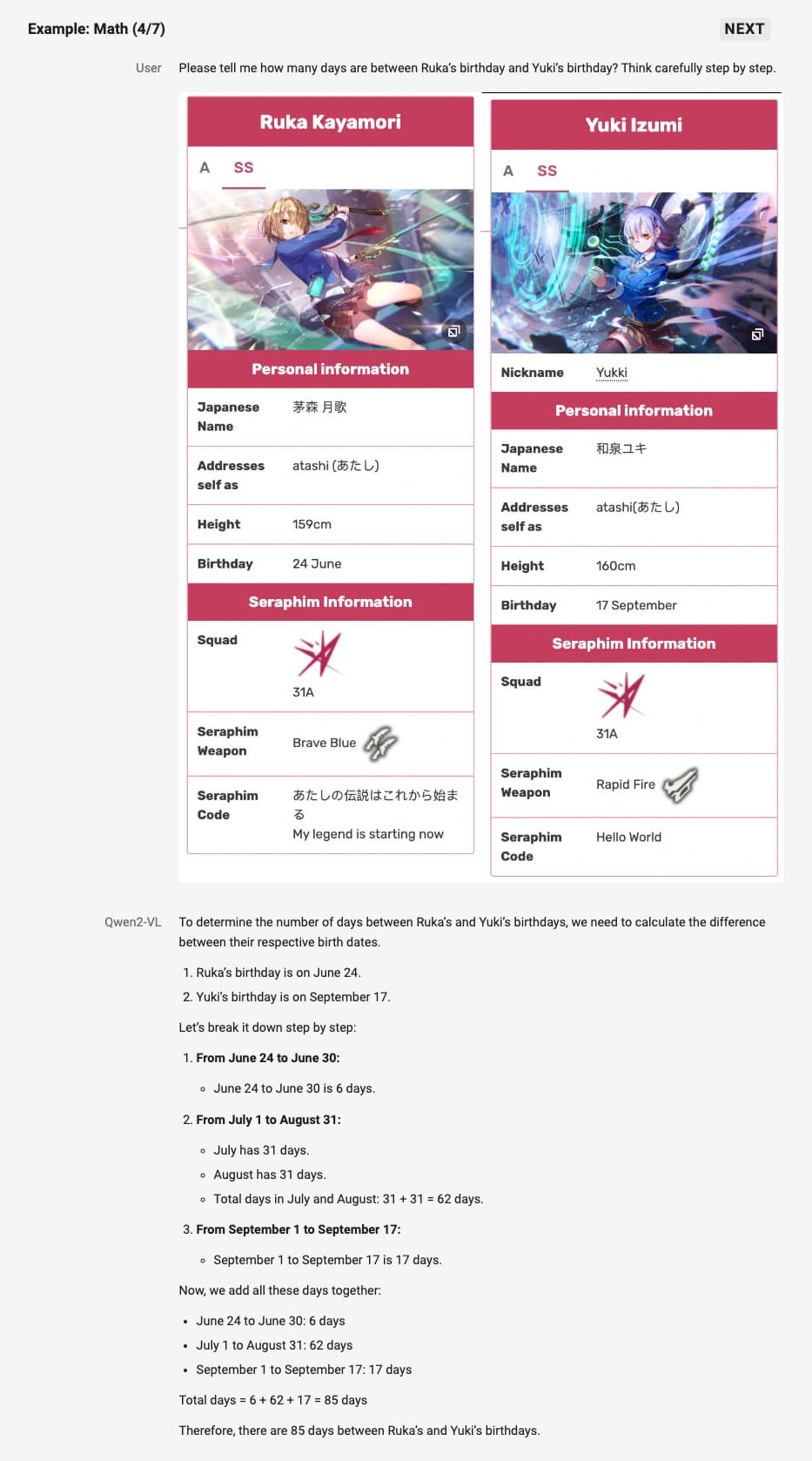
또한, Qwen2-VL은 왜곡된 이미지나 복잡한 비율을 가진 시각적 데이터를 정확히 이해할 수 있습니다. 이는 전통적인 텍스트 기반의 문제 해결 방식과는 다른 접근으로, 시각적으로 표현된 정보를 논리적으로 해석하고 이를 바탕으로 답을 생성하는 방식입니다. 이러한 접근은 기술적 문제를 해결할 때 매우 유용하며, 실세계의 복잡한 시각적 정보를 정확히 처리할 수 있는 능력을 제공합니다.
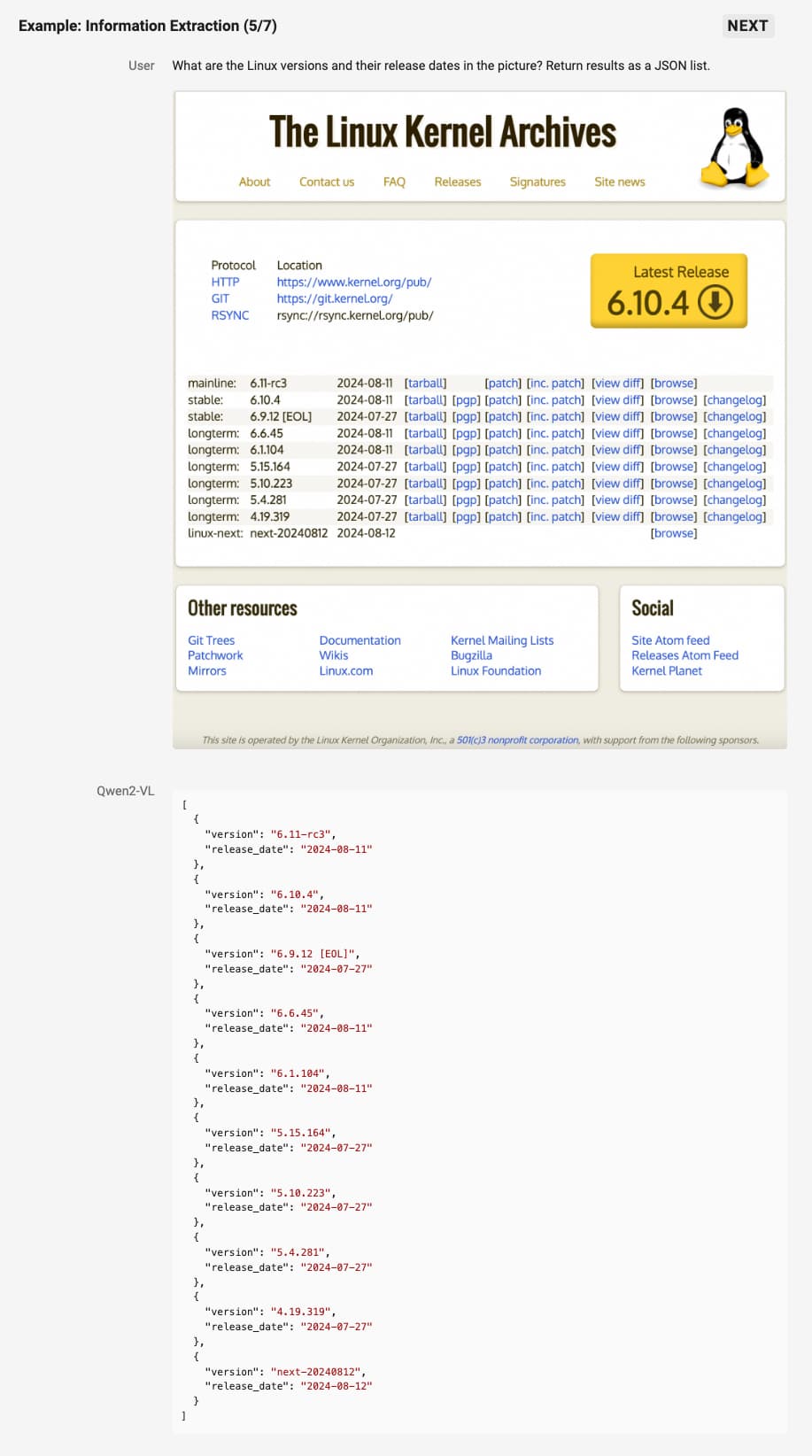
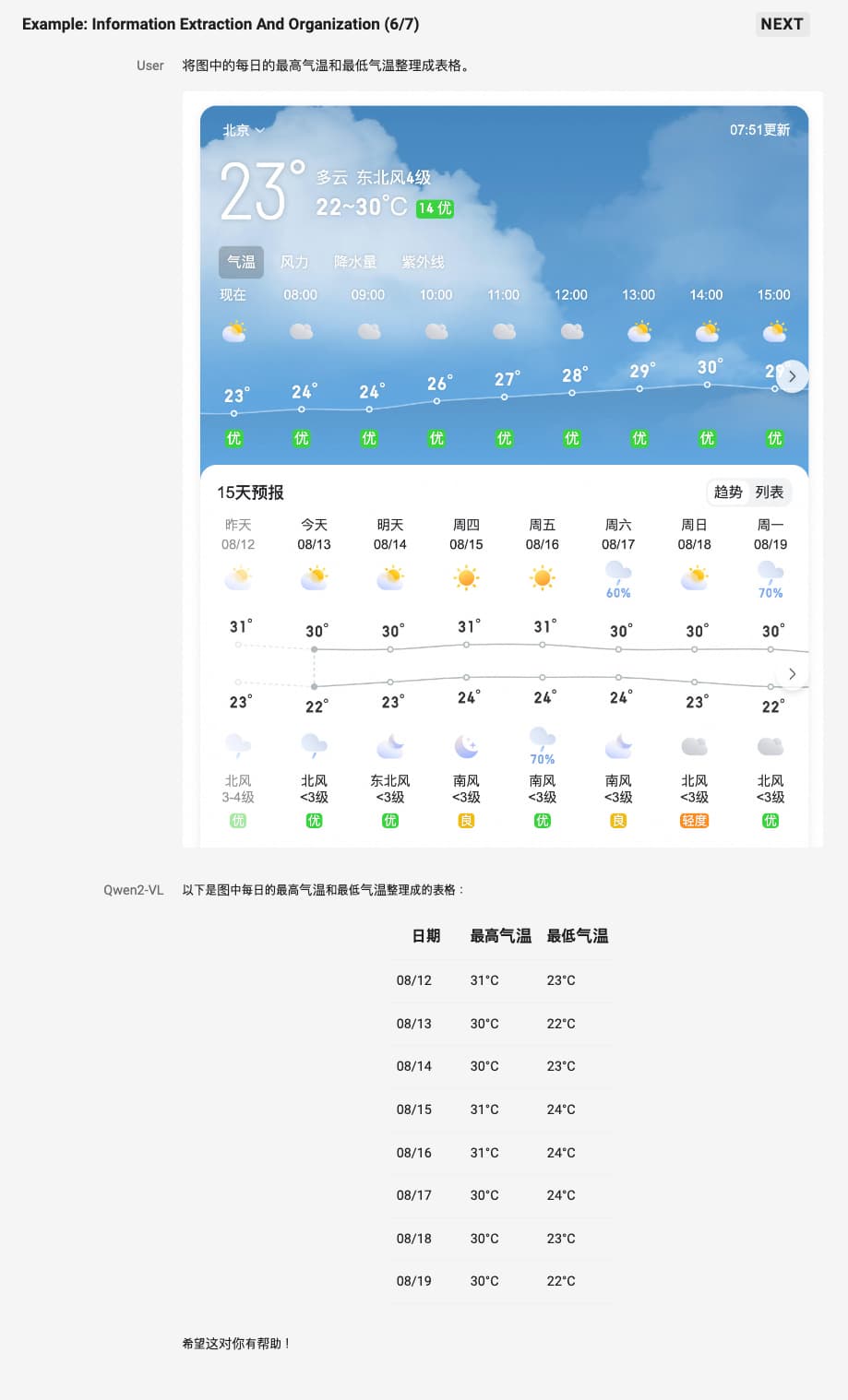
모델은 또한 실제 시각적 환경에서 문제를 인식하고, 이를 해결하기 위한 단계별 접근 방식을 제공합니다. 예를 들어, 특정 알고리즘 문제를 이미지로 제시했을 때, Qwen2-VL은 이를 해석하고 코드로 변환하여 문제를 해결할 수 있습니다. 이는 AI가 시각적 인식을 통해 프로그래밍적 사고를 할 수 있게 함으로써, 더 복잡한 자동화와 문제 해결을 가능하게 합니다.
비디오 이해 및 실시간 채팅
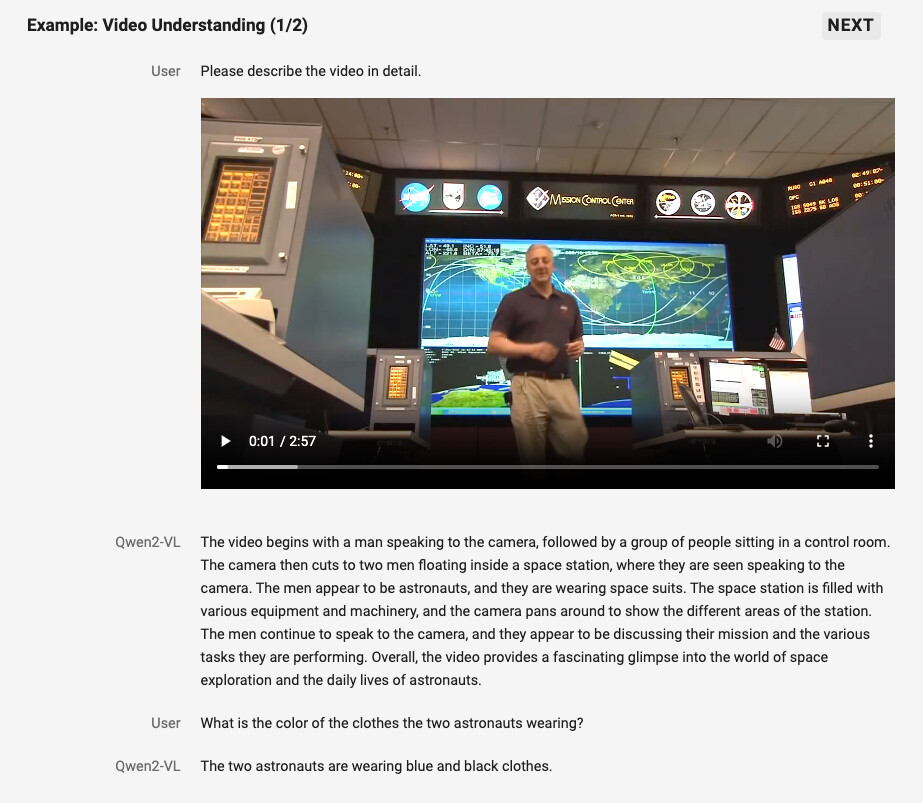
Qwen2-VL은 정적인 이미지 분석을 넘어 동영상의 내용을 이해하고 요약할 수 있는 능력을 갖추고 있습니다. 사용자는 비디오 콘텐츠에 대해 질문을 할 수 있으며, Qwen2-VL은 해당 비디오의 내용을 기반으로 답변을 생성할 수 있습니다. 이 기능은 실시간 대화에서도 적용될 수 있어, 사용자가 비디오를 시청하면서 궁금한 점을 즉각적으로 질문하고 답변을 받을 수 있습니다. 이와 같은 기능은 비디오 기반의 학습이나 정보 검색에서 큰 이점을 제공합니다.
Qwen2-VL은 또한 비디오의 각 장면을 분석하여 시각적 정보와 대화를 결합할 수 있습니다. 예를 들어, 우주 비행사들이 나오는 비디오를 분석하여 그들이 입고 있는 옷의 색상이나 장비에 대한 정보를 제공할 수 있습니다. 이러한 비디오 이해 기능은 단순한 콘텐츠 분석을 넘어, 사용자의 맥락에 맞춘 정보를 제공하고 실시간 대화형 AI 경험을 가능하게 합니다.
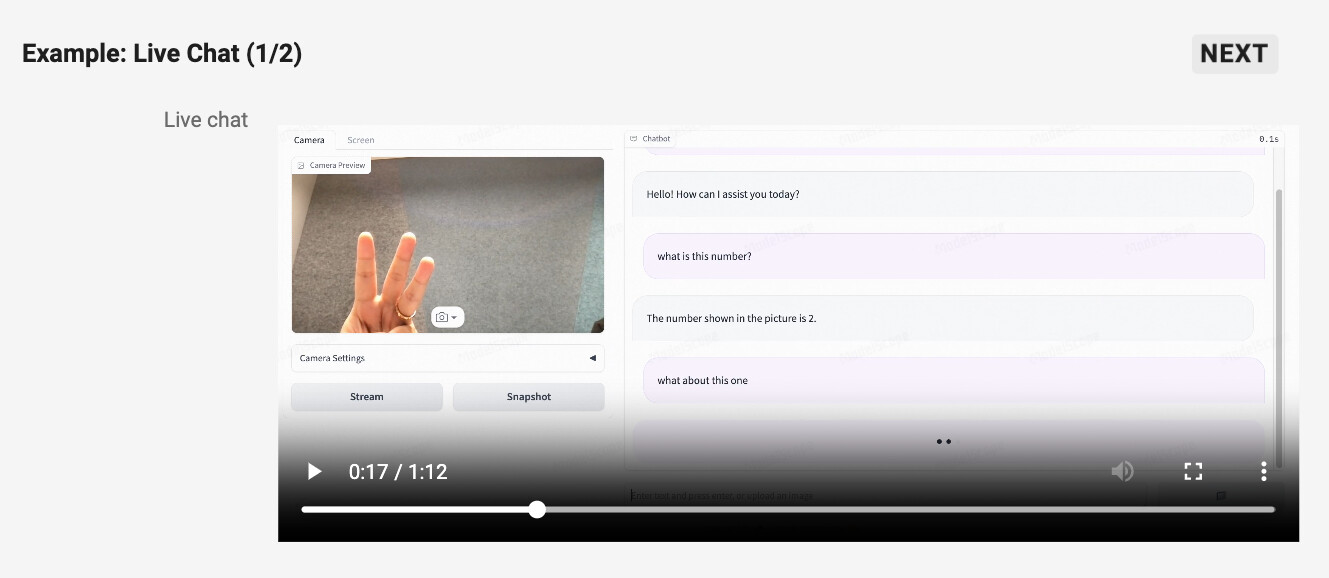
또한, Qwen2-VL의 실시간 채팅 기능은 비디오 콘텐츠를 이해하고 이를 바탕으로 사용자의 질문에 연속적으로 답변할 수 있는 능력을 제공합니다. 이는 개인 비서로서의 역할을 수행할 수 있으며, 비디오의 정보를 실시간으로 해석하여 사용자에게 맞춤형 피드백을 제공할 수 있습니다. 이러한 기능은 특히 교육 및 고객 서비스와 같은 분야에서 유용하게 활용될 수 있습니다.
시각 에이전트 기능: 함수 호출 및 시각적 상호작용
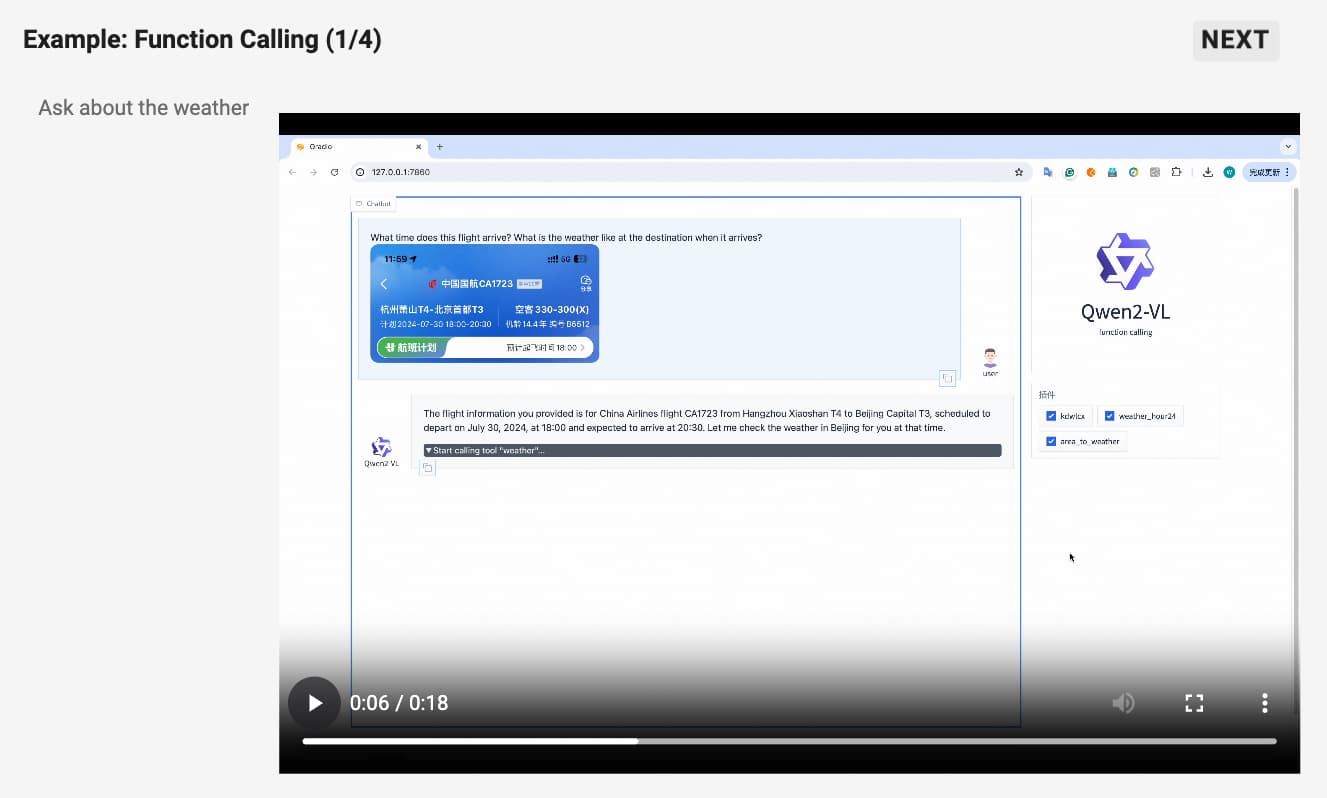
Qwen2-VL은 단순히 시각적 데이터를 해석하는 것을 넘어, 실제 작업을 수행할 수 있는 시각 에이전트로서의 기능도 갖추고 있습니다. 이 모델은 외부 도구와의 연동을 통해 실시간 데이터를 수집하고 처리할 수 있으며, 사용자의 시각적 요구에 따라 특정 기능을 호출할 수 있습니다. 예를 들어, 비행 상태 확인, 날씨 예보, 패키지 추적과 같은 작업을 시각적 데이터 분석을 통해 수행할 수 있습니다.
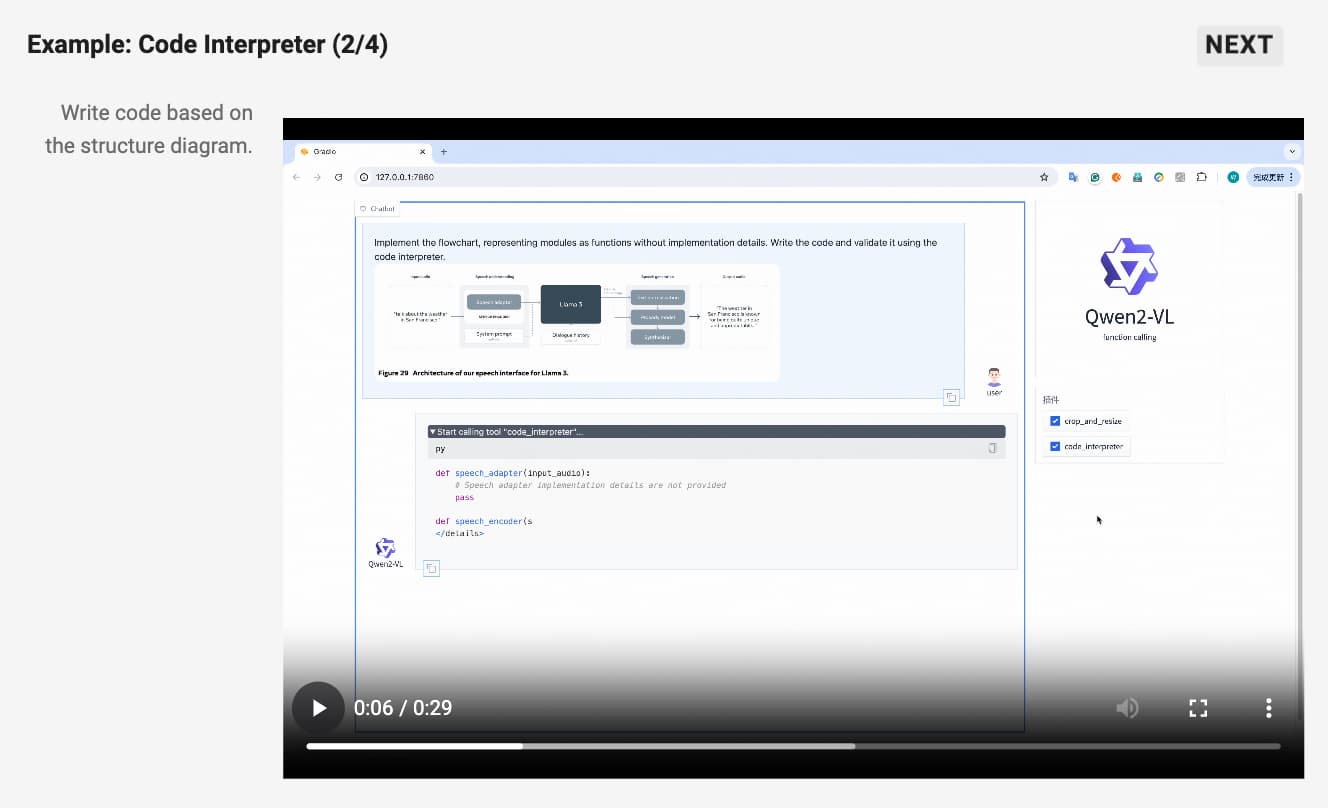
시각 에이전트로서의 Qwen2-VL은 인간의 시각적 인지와 유사한 방식으로 환경을 인식하고 반응할 수 있습니다. 이는 단순한 관찰자를 넘어, 사용자의 시각적 경험에 능동적으로 참여할 수 있는 존재로서 AI의 역할을 확장합니다. 예를 들어, UI 요소를 인식하고 상호작용하는 등의 작업을 수행할 수 있으며, 이는 보다 직관적이고 몰입감 있는 사용자 경험을 제공합니다.
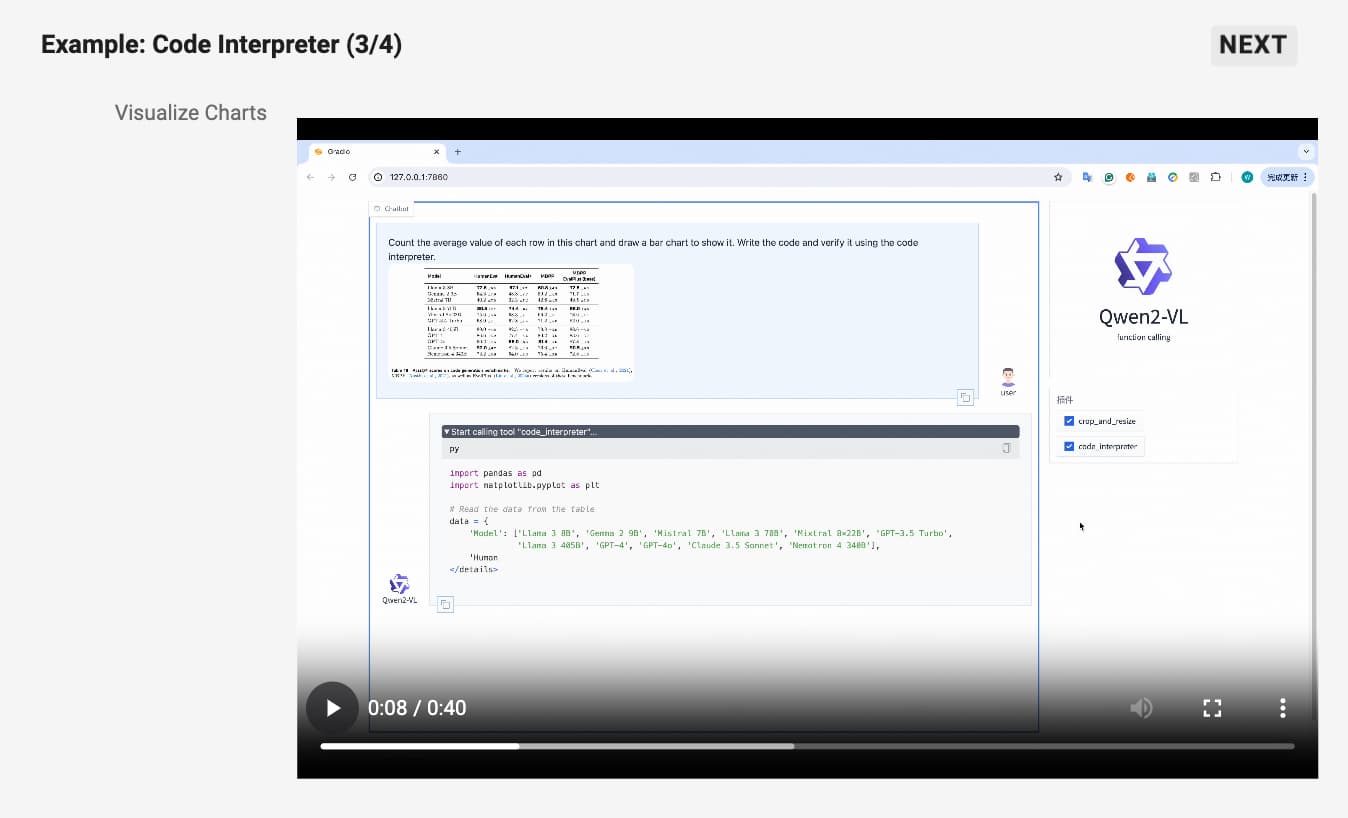
이러한 기능은 Qwen2-VL이 실제 환경에서의 시각적 상호작용을 가능하게 하여, 다양한 응용 프로그램에서 사용할 수 있도록 합니다. 특히, 시각적 데이터를 실시간으로 분석하고 이를 바탕으로 자동화된 결정을 내릴 수 있다는 점에서, Qwen2-VL은 정보 관리 및 의사 결정 지원 도구로서 강력한 잠재력을 가지고 있습니다.
Qwen2-VL 모델의 구조
Qwen2-VL은 Qwen-VL의 아키텍처를 기반으로 하여 Vision Transformer(ViT)와 Qwen2 언어 모델을 결합한 형태로 설계되었습니다. 이 모델은 이미지와 비디오 입력을 매끄럽게 처리할 수 있도록 약 6억 개의 파라미터를 가진 ViT를 사용하고 있습니다. 특히, 비디오에서 시각적 정보를 효과적으로 인식하고 이해할 수 있도록 설계된 여러 업그레이드가 포함되었습니다.
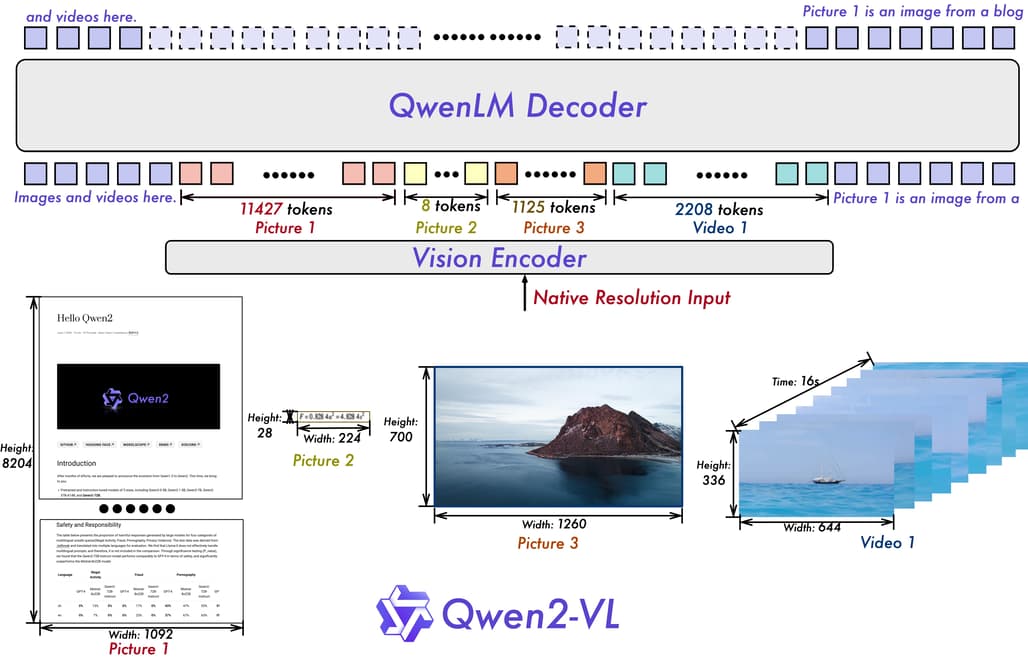
주요 아키텍처 개선 중 하나는 Naive Dynamic Resolution 지원입니다. 이 기능은 Qwen2-VL이 임의의 해상도의 이미지를 처리할 수 있도록 하여, 이미지의 고유 정보를 보존하면서 일관된 입력을 제공할 수 있게 합니다. 이는 사람의 시각적 인지 방식을 모방하여, 어떤 해상도의 이미지든 효과적으로 처리할 수 있는 능력을 제공합니다.

또한, **Multimodal Rotary Position Embedding (M-ROPE)**은 1D 텍스트, 2D 이미지, 3D 비디오의 위치 정보를 동시에 캡처하고 통합할 수 있도록 설계되었습니다. 이는 Qwen2-VL이 다양한 유형의 시각적 및 텍스트 정보를 동시에 처리하고 이해할 수 있게 하여, 복합적인 시각적 환경에서도 높은 수준의 이해력을 제공할 수 있게 해줍니다.
라이선스
Qwen2-VL-2B 모델과 Qwen2-VL-7B 모델은 Apache 2.0 라이선스 하에 제공되어 개발자들이 자유롭게 사용하고 수정할 수 있습니다. Apache 2.0 라이선스는 상업적 사용이 가능합니다.
Qwen2-VL-72B 모델은 아직 공개 전이며, 별도의 라이선스로 배포될 가능성이 있습니다.
 Qwen2-VL 모델 공개 관련 블로그 글
Qwen2-VL 모델 공개 관련 블로그 글
Qwen2-VL 기술 문서
(2024/09/12 현재, 기술 문서는 아직 공개 전입니다. 공개되면 업데이트하도록 하겠습니다. ![]() )
)
 Qwen2-VL 모델 데모
Qwen2-VL 모델 데모
https://huggingface.co/spaces/Qwen/Qwen2-VL
 Qwen2-VL 모델 코드
Qwen2-VL 모델 코드
https://github.com/QwenLM/Qwen2-VL
 Qwen2-VL 모델 가중치
Qwen2-VL 모델 가중치
양자화(Quantized)된 Qwen2-VL 모델 가중치 및 벤치마크
(모든 벤치마크는 VLMEvalkit로 진행하였습니다.)
7B / Qwen2-VL-7B-Instruct 기반
| Quantization | MMMU | DocVQA | MMBench | MathVista |
|---|---|---|---|---|
| BF16 ( |
53.77 | 93.89 | 81.78 | 58.20 |
| GPTQ-Int8 ( |
53.00 | 93.94 | 82.38 | 57.90 |
| GPTQ-Int4 ( |
52.55 | 93.16 | 81.27 | 60.30 |
| AWQ ( |
53.66 | 93.10 | 81.61 | 56.80 |
2B / Qwen2-VL-2B-Instruct 기반
| Quantization | MMMU | DocVQA | MMBench | MathVista |
|---|---|---|---|---|
| BF16 ( |
41.88 | 88.34 | 72.07 | 44.40 |
| GPTQ-Int8 ( |
41.55 | 88.28 | 71.99 | 44.60 |
| GPTQ-Int4 ( |
39.22 | 87.21 | 70.87 | 41.69 |
| AWQ ( |
41.33 | 86.96 | 71.64 | 39.90 |
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()