
Qwen3.5-397B-A17B 모델 소개
최근 대규모 언어 모델(LLM) 생태계는 텍스트를 넘어 이미지, 비디오 등 다양한 형태의 데이터를 동시에 이해하고, 실세계 환경에서 주도적으로 도구를 활용하는 네이티브 멀티모달 에이전트(Native Multimodal Agent) 시대로 진입하고 있습니다. 이러한 흐름을 선도하기 위해 Qwen 팀은 2026년 2월 15일, Qwen3.5 시리즈의 첫 번째 개방형 가중치(Open-weight) 모델인 Qwen3.5-397B-A17B를 공식 발표했습니다. 이 모델은 초기 단계부터 텍스트와 시각 정보를 융합하여 훈련된 네이티브 비전-언어 모델(Vision-Language Model)로, 단순한 대화를 넘어 복잡한 추론, 자율 코딩, 멀티모달 이해를 아우르는 에이전트 중심의 워크플로우에 최적화되어 있습니다. 개발자와 기업들은 이 모델을 통해 전에 없던 생산성 향상과 실질적인 문제 해결 능력을 경험할 수 있습니다.
Qwen3.5의 가장 핵심적인 혁신은 압도적인 성능과 극단적인 추론 효율성을 동시에 달성한 '하이브리드 아키텍처(Hybrid Architecture)'에 있습니다. 총 3,970억(397B) 규모의 거대한 파라미터 규모를 자랑하지만, 희소 전문가 혼합(Sparse Mixture-of-Experts, MoE) 구조를 채택하여 한 번의 순방향 패스(Forward Pass) 시 전체의 약 4.2%에 불과한 170억(17B) 개의 파라미터만 활성화됩니다. 여기에 Gated Delta Networks(GDN) 기반의 선형 어텐션(Linear Attention)을 융합하여 속도와 비용을 최적화하면서도 모델의 역량 손실을 원천적으로 차단했습니다.
또한 글로벌 서비스로의 도약을 위해 다국어 지원 능력을 대폭 강화했습니다. 지원하는 언어 및 방언의 수를 기존 119개에서 201개로 확장하였으며, 전 세계 다양한 지역의 문화적 맥락까지 정교하게 이해할 수 있도록 설계되었습니다. 인프라 운영 없이 즉각적인 도입을 원하는 기업 사용자를 위해 알리바바 클라우드(Alibaba Cloud)의 Model Studio를 통해 관리형 서비스인 Qwen3.5-Plus 모델도 함께 제공됩니다. 이 서비스는 기본적으로 100만(1M) 토큰의 거대한 컨텍스트 윈도우를 지원하며, 웹 검색 및 코드 인터프리터 등 공식 내장 도구와 적응형 도구 사용 기능을 제공하여 상용 수준의 에이전트 애플리케이션 구축을 완벽하게 지원합니다. 알리바바 클라우드에서 Qwen3.5-Plus 모델 사용과 관련한 더 자세한 내용은 사용자 가이드를 참고해주세요.
Qwen3.5-397B-A17B vs. 주요 프론티어 모델 비교
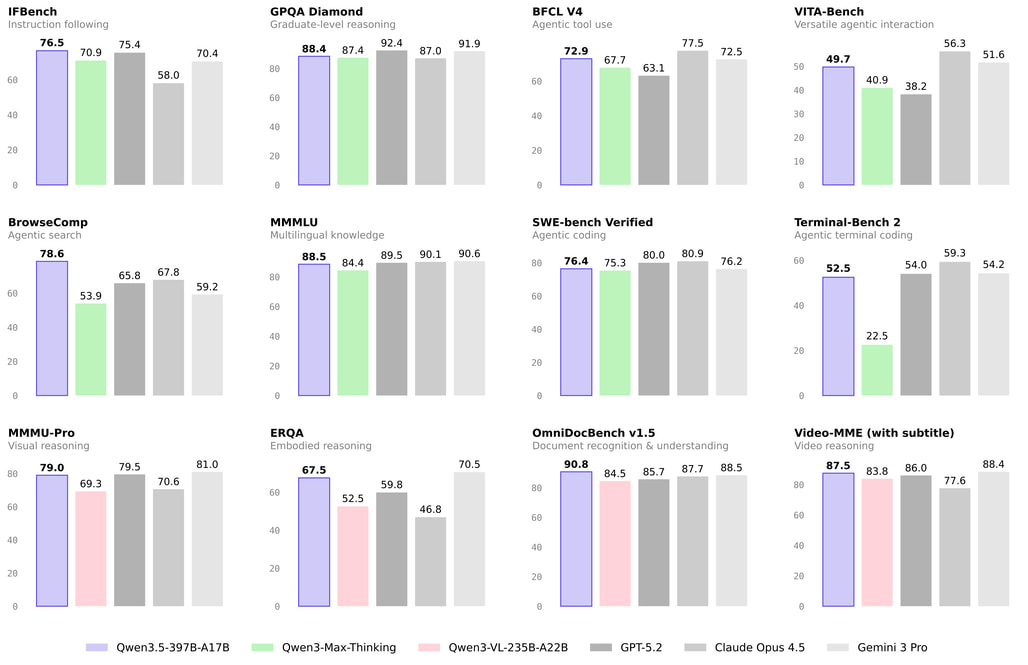
Qwen3.5는 성능Power), 효율성(Efficiency), 범용성(Versatility) 세 가지 핵심 축에서 이전 세대 모델과 타사의 최상위 프론티어 모델들을 압도하거나 동등한 수준의 성취를 이루었습니다:
-
성능 및 스케일의 진화: 엄격하게 필터링된 풍부한 한국어/중국어/영어, 다국어, STEM, 추론 데이터와 함께 이전 세대인 Qwen3 대비 시각-텍스트 토큰의 규모를 비약적으로 늘려 학습했습니다. 그 결과 397B 규모임에도 불구하고 파라미터가 1조(1T) 개 이상인 Qwen3-Max-Base 모델과 대등한 세대 간 패리티(Cross-generation parity)를 달성했습니다.
-
압도적인 추론 효율성: Gated DeltaNet과 Gated Attention이 결합된 Qwen3-Next 하이브리드 아키텍처 덕분에 32k 및 256k 컨텍스트 길이 환경에서 Qwen3-Max 대비 각각 8.6배, 19.0배 높은 디코딩 처리량(Throughput)을 기록했습니다. 이는 더 작은 모델이었던 Qwen3-235B-A22B와 비교해도 3.5배~7.2배 더 빠른 수치입니다.
-
프론티어 모델과의 벤치마크 경쟁력: Qwen3.5-397B-A17B는 업계 최고 수준의 모델인 GPT5.2, Claude 4.5 Opus, Gemini-3 Pro, Kimi K2.5-1T-A32B 등과 비교하여 광범위한 평가에서 최상위권의 성과를 기록했습니다.
-
언어 및 지식: MMLU-Pro에서 87.8점, MMLU-Redux에서 94.9점을 기록하며 Claude 4.5 Opus 수준에 근접했습니다.
-
수학 및 추론: MATH(74.14), AIME26(91.3), LiveCodeBench v6(83.6) 등 고난도 추론 분야에서 최고 수준의 문제 해결 능력을 입증했습니다.
-
멀티모달 (비전-언어): MMMU 85.0, MathVision 88.6 등 STEM 및 퍼즐 영역에서 타 모델을 능가하며, VideoMME(87.5) 등 비디오 이해력에서도 탁월한 성능을 보입니다.
-
일반 에이전트 능력: 단순 지표 최적화를 넘어 수백만 개의 에이전트 스캐폴드(Scaffold) 환경에서 강화학습(RL)을 진행한 결과, BFCL-V4(72.9), TAU2-Bench(86.7) 등 도구 활용 및 의사결정 벤치마크에서 비약적인 발전을 이루었습니다.
-
Qwen3.5의 주요 특징
혁신적인 하이브리드 아키텍처 및 상세 제원
Qwen3.5-397B-A17B는 메모리 병목을 줄이고 초장문 컨텍스트 처리에 최적화된 복잡하고 정교한 내부 구조를 가지고 있습니다.
-
파라미터 및 기본 구조: 총 60개의 레이어로 구성되어 있으며, 은닉 차원(Hidden Dimension)은 4096입니다. 토큰 임베딩 크기는 248,320으로 확장된 250k 어휘 사전(Vocabulary)을 수용하여 대부분의 언어에서 10~60%의 인코딩/디코딩 효율 향상을 가져왔습니다.
-
독특한 히든 레이아웃 (Hidden Layout):
15 * (3 * (Gated DeltaNet -> MoE) -> 1 * (Gated Attention -> MoE))구조를 채택했습니다. 이는 3번의 고효율 선형 어텐션 처리 후 1번의 정밀한 표준 어텐션을 수행하는 방식을 반복하여 성능과 연산량의 균형을 극대화한 것입니다. -
Gated DeltaNet (선형 어텐션 부분): Value(V) 처리를 위해 64개의 헤드를, Query-Key(QK) 처리를 위해 16개의 헤드를 사용하며 헤드 차원은 128입니다.
-
Gated Attention (표준 어텐션 부분): Query(Q)를 위해 32개의 헤드, Key-Value(KV)를 위해 단 2개의 헤드를 사용하는 GQA(Grouped Query Attention) 변형 구조를 가지며, 헤드 차원은 256, RoPE(Rotary Position Embedding) 차원은 64입니다.
-
희소 전문가 혼합 (Sparse MoE): 중간 차원(Intermediate Dimension)이 1024인 512개의 전문가(Expert)로 구성되어 있습니다. 추론 시에는 매 토큰마다 10개의 라우팅된 전문가와 1개의 공유 전문가(Shared Expert)가 결합하여 작동합니다.
-
MTP (Multi-Token Prediction): 여러 스텝의 토큰을 동시에 예측하도록 학습되어 초당 생성 토큰 수(TPS)를 크게 높였습니다.
-
초장문 컨텍스트: 기본적으로 262,144(256k) 토큰의 컨텍스트 길이를 네이티브로 지원하며, 추후 설명할 YaRN 기법을 통해 최대 1,010,000(1M) 토큰까지 확장 가능합니다.
멀티모달 및 에이전트 역량의 진화
텍스트-비전 융합 훈련의 결과로, 다양한 실물 세계 및 디지털 환경에서의 에이전트 능력이 강화되었습니다.
- 공간 지능 (Spatial Intelligence): 이미지 내 픽셀 단위의 공간 관계를 정확히 파악합니다. 객체 계수(Counting), 상대적 위치 파악(예: "노란 밴 오른쪽에 공중전화 부스가 있는가?"), 시점 변화나 가려짐(Occlusion)이 발생하는 환경에서의 상황 판단 능력이 뛰어나 자율주행이나 로봇 비전의 훌륭한 백엔드 모델로 기능합니다.
- 코딩 및 웹 개발 에이전트: 자연어 지시만으로 작동하는 HTML 코드 생성, 간단한 자동차 게임 제작 등 웹 프론트엔드 작업에 탁월합니다. OpenClaw 등과 연동하여 웹 검색, 정보 수집, 구조화된 보고서 작성, 디버깅을 아우르는 '바이브 코딩(Vibe Coding)' 경험을 제공합니다.
- 도구 사용(Tool Use): 코드 인터프리터(Code Interpreter)를 통합하여 내부적으로 코드를 실행해 보고 그 결과(예: 미로 찾기 최단 경로 그리기, 수학 계산)를 검증한 뒤 최종 답변을 도출하는 정교한 시각적 사고(Thinking with Images) 과정을 거칩니다.
차세대 분산 학습 인프라 및 시스템 최적화
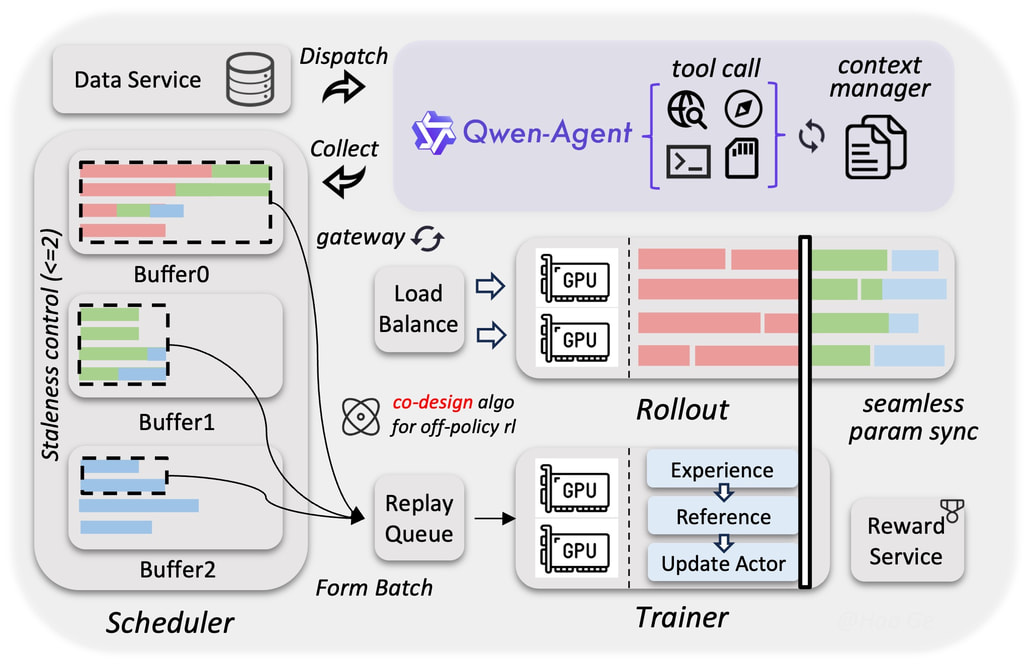
전 세계적인 규모의 데이터와 멀티모달 환경을 감당하기 위해 Qwen 팀은 인프라 수준의 대대적인 혁신을 단행했습니다.
-
이기종 인프라 기반의 훈련/추론 분리: 텍스트, 비전, 비디오 등 다양한 모달리티의 병렬화 전략을 분리(Decoupling)하여 균일한 접근 방식으로 인해 발생하는 비효율성을 제거했습니다. 텍스트-이미지-비디오 혼합 데이터를 학습할 때도 순수 텍스트 훈련과 거의 100% 동일한 처리량을 달성했습니다.
-
네이티브 FP8 파이프라인: 활성화(Activations), MoE 라우팅, GEMM 연산에 FP8 저정밀도를 적용하고 런타임 모니터링을 통해 민감한 레이어만 BF16으로 보호합니다. 이로 인해 활성화 메모리는 50% 감소하고 속도는 10% 이상 증가했습니다.
-
비동기식 강화학습(Asynchronous RL) 프레임워크: FP8 종단 간(End-to-end) 훈련, 롤아웃 라우터 리플레이(Rollout router replay), 추측 디코딩(Speculative decoding)을 도입하여 하드웨어 활용도와 동적 로드 밸런싱을 최적화했습니다. 그레이디언트 지연(Gradient staleness)과 데이터 편향(Data skewness)을 효과적으로 통제하여 종단 간 3~5배의 속도 향상과 훈련 안정성을 달성했습니다.
Qwen-Agent 및 생태계 통합 (Agentic Usage)
Qwen3.5는 도구 호출(Tool Calling)에 극도로 최적화되어 있습니다. Qwen-Agent 라이브러리를 사용하면 손쉽게 에이전트 애플리케이션을 구축할 수 있습니다.
-
MCP (Model Context Protocol) 지원: 파일 시스템 접근이나 외부 도구 연동 시 MCP를 네이티브로 지원하여,
npx -y @modelcontextprotocol/server-filesystem같은 명령어를 통해 로컬 데스크톱을 관리하거나 파일을 생성하는 에이전트를 몇 줄의 코드로 작성할 수 있습니다. -
Qwen Code 활용: 터미널 환경에 최적화된 오픈소스 AI 에이전트인 Qwen Code를 통해 방대한 코드베이스를 이해하고 지루한 반복 작업을 자동화할 수 있습니다.
초장문 텍스트 처리 (YaRN 스케일링)
입출력 합계가 262,144 토큰을 초과하는 극단적인 긴 컨텍스트 작업을 위해, Qwen3.5는 RoPE 스케일링 기법 중 하나인 YaRN 적용을 공식 지원합니다.
- 사용을 위해서는
config.json의text_config내rope_parameters를 수정하여rope_type을 "yarn"으로 변경하고,factor값을 확장하고자 하는 비율에 맞게 조정해야 합니다. (예: 1M 토큰 확장을 위해factor: 4.0적용). - 정적 YaRN 구현체의 특성상 짧은 텍스트에서 성능 저하가 발생할 수 있으므로, 반드시 긴 컨텍스트 처리가 필요한 워크로드에서만 적용할 것을 권장합니다.
vLLM 및 SGLang을 활용한 Qwen3.5 로컬 추론
Qwen3.5-397B-A17B 모델은 그 크기와 고유한 하이브리드 아키텍처 특성상 Hugging Face Transformers 내장 서버보다는 고효율 전용 서빙 엔진인 SGLang 또는 vLLM 환경에서의 구동이 강력히 권장됩니다. 이 모델은 기본적으로 <think>\n...\n</think> 태그를 사용하여 최종 답변 전 내부 추론 과정을 거치는 '사고 모드(Thinking Mode)'로 작동합니다. 메모리 제약(OOM)이 발생하더라도 사고 능력을 유지하기 위해 최소 128k 이상의 컨텍스트 윈도우 할당을 권장합니다.
SGLang을 이용한 배포
SGLang은 LLM 및 VLM을 위한 초고속 서빙 프레임워크입니다. 최신 Qwen3.5 지원을 위해 GitHub main 브랜치 버전의 설치가 필요합니다.
uv pip install 'git+https://github.com/sgl-project/sglang.git#subdirectory=python&egg=sglang[all]'
다음은 SGLang으로 8 GPU 텐서 병렬화, 256k 컨텍스트 길이로 표준 API 서버 실행하는 예시 명령어입니다:
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--port 8000 \
--tp-size 8 \
--mem-fraction-static 0.8 \
--context-length 262144 \
--reasoning-parser qwen3
그 외, 도구 호출(Tool Use) 지원 모드를 실행하려면 위 명령어 끝에 --tool-call-parser qwen3_coder를 추가합니다.
또한, 생성 속도를 극대화하기 위해 MTP (Multi-Token Prediction) 기능을 활성화하는 명령어는 다음과 같습니다:
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--port 8000 \
--tp-size 8 \
--mem-fraction-static 0.8 \
--context-length 262144 \
--reasoning-parser qwen3 \
--speculative-algo NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4
vLLM을 이용한 배포
vLLM 역시 메모리 효율이 뛰어난 대중적인 서빙 엔진입니다. 2026년 2월 기준, Nightly 빌드 설치가 필요합니다:
uv pip install vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
다음은 8개의 GPU를 사용하여 OpenAI 호환 표준 API 서버를 실행하는 예시 명령어입니다:
vllm serve Qwen/Qwen3.5-397B-A17B \
--port 8000 \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--reasoning-parser qwen3
도구 호출(Tool Call) 및 MTP 활성화를 위해서는 위 명령어에 다음 옵션들을 추가하면 됩니다:
- 도구 호출:
--enable-auto-tool-choice --tool-call-parser qwen3_coder옵션 추가 - MTP:
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'옵션 추가
그 외에도, 메모리 절약을 위해 텍스트 전용 모드를 지원합니다. 만약 비전 인코더와 멀티모달 프로파일링을 건너뛰어 KV 캐시 공간을 더 확보하려면 --language-model-only 옵션을 사용하면 됩니다.
최상의 결과를 위해 권장하는 매개변수
OpenAI 호환 API를 통해 Qwen3.5를 호출할 때 최상의 결과를 얻기 위해 다음 파라미터를 준수하는 것을 권장합니다:
-
사고 모드 (Thinking Mode - 기본값):
- 권장 파라미터:
Temperature=0.6,TopP=0.95,TopK=20,MinP=0
- 권장 파라미터:
-
비사고 모드 (Instruct Mode - 빠른 직접 응답):
- 권장 파라미터:
Temperature=0.7,TopP=0.8,TopK=20,MinP=0 - 비활성화 방법: API 호출 시
extra_body={"chat_template_kwargs": {"enable_thinking": False}}를 전달. (단, Alibaba Cloud Model Studio API 사용 시에는extra_body={"enable_thinking": False}형식 사용)
- 권장 파라미터:
-
출력 길이 제한: 일반적인 쿼리는
max_tokens=32768로 충분하지만, 복잡한 프로그래밍이나 수학 문제 등 내부 추론 궤적이 길어지는 작업은 모델이 충분히 생각할 수 있도록max_tokens=81920으로 넉넉하게 설정하는 것을 권장합니다.
 Qwen3.5-397B-A17B 모델 출시 블로그
Qwen3.5-397B-A17B 모델 출시 블로그
 Qwen3.5-397B-A17B 모델 다운로드
Qwen3.5-397B-A17B 모델 다운로드
 Qwen3.5 모델 GitHub 저장소
Qwen3.5 모델 GitHub 저장소
2026/02/18 현재, 아직 코드가 업데이트되지 않았습니다
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()