
Qwen3-Coder 모델 소개
최근 오픈소스 AI 모델 시장에서 ‘에이전트형(Agentic)’ 모델에 대한 관심이 커지고 있습니다. 특히 코드 작성, 리팩토링, 디버깅 등의 자동화를 위해 특별히 설계된 모델들이 주목받고 있는데, 그중 대표적인 사례가 Alibaba의 Qwen 팀에서 공개한 Qwen3-Coder입니다. 이 모델은 단순히 코드 생성에 그치지 않고, 다양한 도구와 브라우저 사용까지 포함하는 ‘에이전트형 태스크(agentic task)’에서 높은 성능을 보이고 있어 많은 개발자와 연구자들의 관심을 끌고 있습니다.
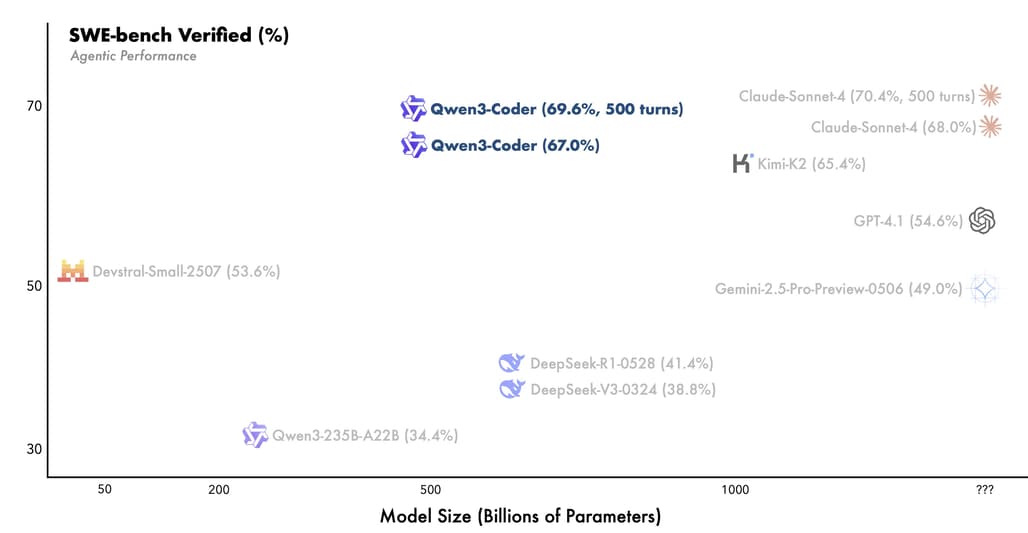
Qwen3-Coder는 두 가지 크기의 모델로 구성되어 있지만, 가장 주목할 만한 모델은 Qwen3-Coder-480B-A35B-Instruct입니다. 이 모델은 총 480B 규모의 파라미터를 가지는 Mixture-of-Experts(MoE) 구조로, 실제로는 35B억 파라미터가 동시에 활성화됩니다. 이를 통해 기존의 오픈 모델 대비 에이전트 태스크에서 Claude Sonnet와 비교될 정도로 높은 성능을 달성했습니다. 특히, Qwen3-Coder는 256K 토큰의 긴 컨텍스트 처리를 기본으로 지원하며, YaRN을 통해 최대 100만 토큰까지 확장 가능합니다. 이는 코드 리포지토리 수준의 문맥 이해가 필요한 작업에 매우 유용합니다.
또한, Qwen3-Coder는 358개의 프로그래밍 언어를 지원하며, Python, JavaScript, C++ 등 주요 언어는 물론, Brainfuck, COBOL, Solidity 같은 비주류 언어까지 포함되어 있어 폭넓은 활용이 가능합니다. 이러한 범용성과 성능 덕분에 Qwen3-Coder는 단순한 LLM을 넘어 코드 에이전트 구현의 핵심 인프라로 떠오르고 있습니다.
Qwen3-Coder는 벤치마크 상으로 Claude Sonnet과 비교될 만큼의 성능을 보이며, 특히 에이전트형 코드 생성 태스크에서 강점을 보입니다. 이 모델의 가장 큰 특징 중 하나는 Mixture-of-Experts 구조입니다. 이는 필요한 상황에 따라 일부 전문가(sub-models)만 활성화되는 구조로, 전체 모델의 규모는 크지만 실질적인 추론 시 사용되는 파라미터 수는 적어 효율적입니다. 이는 Meta의 Mixtral이나 Mistral과도 유사한 아키텍처입니다.
또한, 긴 문맥 길이를 처리할 수 있는 점은 OpenAI의 GPT-4 Turbo, Anthropic의 Claude 3, Google Gemini와도 경쟁할 수 있는 지점입니다. 특히 Yarn 기반의 확장성은 레포지토리 레벨의 코드 이해나 대규모 문서 기반의 AI 개발에 매우 적합합니다.
사전 학습: 규모의 힘을 극대화
Qwen3-Coder는 7.5조 개의 토큰을 기반으로 사전 학습되었습니다. 전체 데이터의 70%는 코드로 구성되어 있어, 일반적인 언어 능력과 수학 능력을 유지하면서도 코드 관련 태스크에 특화된 성능을 보여줍니다. 또한 Qwen2.5-Coder를 활용한 데이터 정제 및 재작성을 통해 노이즈가 많은 웹 데이터를 개선하여 고품질 학습 데이터를 확보하였습니다. 이러한 데이터 전략은 모델의 전반적인 성능을 끌어올리는 데 중요한 역할을 했습니다.
코드 RL: 실행 기반 강화 학습
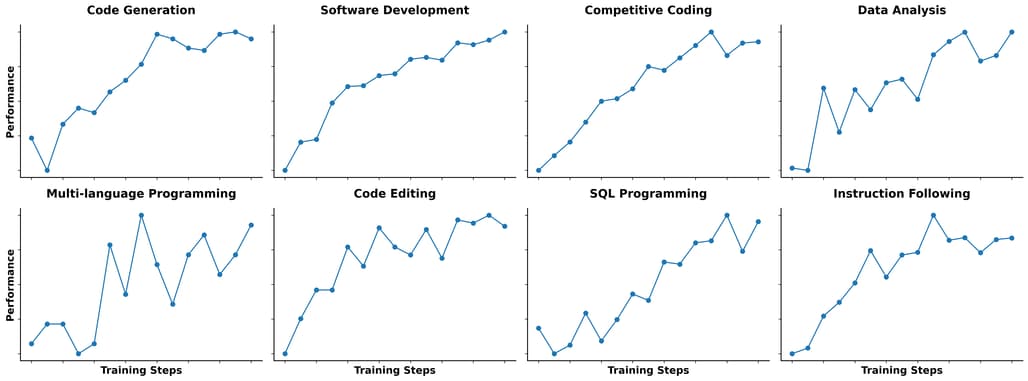
Qwen3-Coder는 기존 코드 생성 모델과 달리, RL 기반의 후처리 학습을 강화하였습니다. 특히 자동 생성된 다양한 테스트 케이스를 통해 실행 가능한 코드의 성공률을 높이는 방향으로 강화 학습을 확장했습니다. 이는 단순히 정답을 맞추는 것이 아니라, 실제 코드가 실행 가능한지를 기준으로 학습을 수행하기 때문에 현실성 있는 결과를 생성하는 데 매우 효과적입니다.
장기 상호작용 환경에서의 강화 학습
Qwen3-Coder는 SWE-Bench와 같은 실제 소프트웨어 공학 태스크에서 도구를 사용하고, 피드백을 받고, 다단계로 계획을 세우며 작업을 수행할 수 있어야 합니다. 이를 위해 Qwen 팀은 Alibaba Cloud 기반으로 2만 개의 독립 환경을 동시에 실행할 수 있는 스케일러블한 에이전트 RL 환경을 구축하였습니다. 이 환경은 에이전트 모델이 장기적인 태스크에서도 우수한 성능을 낼 수 있도록 학습과 평가를 지원합니다.
공개된 Qwen3-Coder 모델
Qwen3-Coder는 대표적으로 다음과 같은 모델로 제공됩니다:
| model name | type | length | Download |
|---|---|---|---|
| Qwen3-Coder-480B-A35B-Instruct | instruct | 256k | |
| Qwen3-Coder-480B-A35B-Instruct-FP8 | instruct | 256k |
두 모델 모두 Hugging Face (및 ModelScope)를 통해 다운로드할 수 있으며, 기본적으로 256K 토큰 컨텍스트를 지원합니다.
다양한 개발 언어 지원
Qwen3-Coder는 358개의 프로그래밍 언어를 인식하고 생성할 수 있습니다. Python, JavaScript, C++, Java 등 일반적인 언어뿐 아니라, COBOL, Brainfuck, Solidity, R, SQL, Rust, Swift, Verilog, VHDL 등도 포함되어 있어, 도메인 특화 코드 작성이나 특수 언어 기반 프로젝트에 활용할 수 있는 범용 모델입니다.
Qwen3-Coder가 지원하는 전체 개발언어 목록은 다음과 같습니다:
['ABAP', 'ActionScript', 'Ada', 'Agda', 'Alloy', 'ApacheConf', 'AppleScript', 'Arc', 'Arduino', 'AsciiDoc', 'AspectJ', 'Assembly', 'Augeas', 'AutoHotkey', 'AutoIt', 'Awk', 'Batchfile', 'Befunge', 'Bison', 'BitBake', 'BlitzBasic', 'BlitzMax', 'Bluespec', 'Boo', 'Brainfuck', 'Brightscript', 'Bro', 'C', 'C#', 'C++', 'C2hs Haskell', 'CLIPS', 'CMake', 'COBOL', 'CSS', 'CSV', "Cap'n Proto", 'CartoCSS', 'Ceylon', 'Chapel', 'ChucK', 'Cirru', 'Clarion', 'Clean', 'Click', 'Clojure', 'CoffeeScript', 'ColdFusion', 'ColdFusion CFC', 'Common Lisp', 'Component Pascal', 'Coq', 'Creole', 'Crystal', 'Csound', 'Cucumber', 'Cuda', 'Cycript', 'Cython', 'D', 'DIGITAL Command Language', 'DM', 'DNS Zone', 'Darcs Patch', 'Dart', 'Diff', 'Dockerfile', 'Dogescript', 'Dylan', 'E', 'ECL', 'Eagle', 'Ecere Projects', 'Eiffel', 'Elixir', 'Elm', 'Emacs Lisp', 'EmberScript', 'Erlang', 'F#', 'FLUX', 'FORTRAN', 'Factor', 'Fancy', 'Fantom', 'Forth', 'FreeMarker', 'G-code', 'GAMS', 'GAP', 'GAS', 'GDScript', 'GLSL', 'Genshi', 'Gentoo Ebuild', 'Gentoo Eclass', 'Gettext Catalog', 'Glyph', 'Gnuplot', 'Go', 'Golo', 'Gosu', 'Grace', 'Gradle', 'Grammatical Framework', 'GraphQL', 'Graphviz (DOT)', 'Groff', 'Groovy', 'Groovy Server Pages', 'HCL', 'HLSL', 'HTML', 'HTML+Django', 'HTML+EEX', 'HTML+ERB', 'HTML+PHP', 'HTTP', 'Haml', 'Handlebars', 'Harbour', 'Haskell', 'Haxe', 'Hy', 'IDL', 'IGOR Pro', 'INI', 'IRC log', 'Idris', 'Inform 7', 'Inno Setup', 'Io', 'Ioke', 'Isabelle', 'J', 'JFlex', 'JSON', 'JSON5', 'JSONLD', 'JSONiq', 'JSX', 'Jade', 'Jasmin', 'Java', 'Java Server Pages', 'JavaScript', 'Julia', 'Jupyter Notebook', 'KRL', 'KiCad', 'Kit', 'Kotlin', 'LFE', 'LLVM', 'LOLCODE', 'LSL', 'LabVIEW', 'Lasso', 'Latte', 'Lean', 'Less', 'Lex', 'LilyPond', 'Linker Script', 'Liquid', 'Literate Agda', 'Literate CoffeeScript', 'Literate Haskell', 'LiveScript', 'Logos', 'Logtalk', 'LookML', 'Lua', 'M', 'M4', 'MAXScript', 'MTML', 'MUF', 'Makefile', 'Mako', 'Maple', 'Markdown', 'Mask', 'Mathematica', 'Matlab', 'Max', 'MediaWiki', 'Metal', 'MiniD', 'Mirah', 'Modelica', 'Module Management System', 'Monkey', 'MoonScript', 'Myghty', 'NSIS', 'NetLinx', 'NetLogo', 'Nginx', 'Nimrod', 'Ninja', 'Nit', 'Nix', 'Nu', 'NumPy', 'OCaml', 'ObjDump', 'Objective-C++', 'Objective-J', 'Octave', 'Omgrofl', 'Opa', 'Opal', 'OpenCL', 'OpenEdge ABL', 'OpenSCAD', 'Org', 'Ox', 'Oxygene', 'Oz', 'PAWN', 'PHP', 'POV-Ray SDL', 'Pan', 'Papyrus', 'Parrot', 'Parrot Assembly', 'Parrot Internal Representation', 'Pascal', 'Perl', 'Perl6', 'Pickle', 'PigLatin', 'Pike', 'Pod', 'PogoScript', 'Pony', 'PostScript', 'PowerShell', 'Processing', 'Prolog', 'Propeller Spin', 'Protocol Buffer', 'Public Key', 'Pure Data', 'PureBasic', 'PureScript', 'Python', 'Python traceback', 'QML', 'QMake', 'R', 'RAML', 'RDoc', 'REALbasic', 'RHTML', 'RMarkdown', 'Racket', 'Ragel in Ruby Host', 'Raw token data', 'Rebol', 'Red', 'Redcode', "Ren'Py", 'RenderScript', 'RobotFramework', 'Rouge', 'Ruby', 'Rust', 'SAS', 'SCSS', 'SMT', 'SPARQL', 'SQF', 'SQL', 'STON', 'SVG', 'Sage', 'SaltStack', 'Sass', 'Scala', 'Scaml', 'Scheme', 'Scilab', 'Self', 'Shell', 'ShellSession', 'Shen', 'Slash', 'Slim', 'Smali', 'Smalltalk', 'Smarty', 'Solidity', 'SourcePawn', 'Squirrel', 'Stan', 'Standard ML', 'Stata', 'Stylus', 'SuperCollider', 'Swift', 'SystemVerilog', 'TOML', 'TXL', 'Tcl', 'Tcsh', 'TeX', 'Tea', 'Text', 'Textile', 'Thrift', 'Turing', 'Turtle', 'Twig', 'TypeScript', 'Unified Parallel C', 'Unity3D Asset', 'Uno', 'UnrealScript', 'UrWeb', 'VCL', 'VHDL', 'Vala', 'Verilog', 'VimL', 'Visual Basic', 'Volt', 'Vue', 'Web Ontology Language', 'WebAssembly', 'WebIDL', 'X10', 'XC', 'XML', 'XPages', 'XProc', 'XQuery', 'XS', 'XSLT', 'Xojo', 'Xtend', 'YAML', 'YANG', 'Yacc', 'Zephir', 'Zig', 'Zimpl', 'desktop', 'eC', 'edn', 'fish', 'mupad', 'nesC', 'ooc', 'reStructuredText', 'wisp', 'xBase']
에이전트 기능 (Agentic Coding)
Qwen3-Coder의 가장 큰 강점은 다양한 에이전트형 작업을 처리할 수 있다는 점입니다. 예를 들어, 브라우저를 통해 정보를 검색하고 해당 내용을 기반으로 코드를 작성하거나, 여러 외부 툴을 연계해 일련의 작업을 자동으로 수행할 수 있습니다. 이러한 기능은 자체 파서(qwen3coder_tool_parser.py)와 함께 제공되며, 코드 내 함수 호출 구조도 특수 포맷을 적용해 직관적인 인터페이스를 제공합니다.
긴 문맥 지원
Qwen3-Coder는 기본적으로 256K 토큰을 지원하며, Yarn 확장을 통해 최대 100만 토큰까지 입력을 받아 처리할 수 있습니다. 이를 통해 코드 리포지토리 전체를 읽고 요약하거나, 긴 문서 기반 질문 응답이 가능해졌습니다.
채팅 기반 인터페이스
transformers 라이브러리를 사용해 Qwen3-Coder와 대화형 인터페이스를 구성할 수 있습니다. 간단한 예시 코드는 다음과 같습니다:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-480B-A35B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "write a quick sort algorithm."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
output = model.generate(**model_inputs, max_new_tokens=65536)
response = tokenizer.batch_decode(output, skip_special_tokens=True)[0]
Fill-in-the-middle 코드 생성
코드의 일부를 비워두고 그 사이를 자동으로 채워주는 FIM(Fill-in-the-middle) 태스크도 지원합니다. <|fim_prefix|>와 <|fim_suffix|> 사이를 자동으로 채우는 포맷을 사용하며, 논문 “Efficient Training of Language Models to Fill in the Middle”를 기반으로 구현되어 있습니다:
 Qwen3-Coder 소개 블로그
Qwen3-Coder 소개 블로그
 Qwen3-Coder GitHub 저장소
Qwen3-Coder GitHub 저장소
https://github.com/QwenLM/Qwen3-Coder
Qwen3 모델 기술 문서 (Technical Report)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()