
Qwen3-Next 모델 소개
최근 Qwen.ai 팀이 발표한 Qwen3-Next는 대형 언어 모델(LLM)의 학습과 추론 효율성을 동시에 개선하기 위해 설계된 새로운 모델입니다. Qwen3-Next는 기존 Qwen3 시리즈의 후속으로 등장했으며, 단순히 모델을 더 키우는 방향이 아니라 비용, 속도, 자원 활용 최적화라는 실용적 관점에서 발전했습니다.

대규모 언어 모델은 그 자체로 강력한 성능을 제공하지만, 실제 서비스 환경에서는 학습 비용(training cost), 추론 속도(inference latency), 메모리와 연산 자원(compute resource)의 한계가 큰 장애물이 됩니다. 특히 긴 문맥(long context)을 다루거나, 사용자 요청에 즉각 응답해야 하는 실시간 시스템에서는 이러한 제약이 더욱 두드러집니다. Qwen3-Next는 이러한 한계를 극복하기 위해 MoE(Mixture of Experts), 하이브리드 Attention, Multi-Token Prediction(MTP) 등의 기술을 적극적으로 도입했습니다.
지금까지 LLM을 실제 서비스에 적용 시, 학습 시간이나 하드웨어 비용, 추론 시 지연 등이 주요한 제약이었습니다. Qwen3-Next는 서버 운영 비용 절감, 실시간 대화형 서비스에서의 응답 속도 향상, 그리고 제한된 자원 환경에서도 대형 모델을 활용할 수 있게 된다는 점에서 이러한 제약들을 어느 정도 극복할 수 있을 것으로 기대합니다.
Qwen3-Next와 다른 기존의 LLM들의 주요한 특징들을 비교하면 다음과 같습니다:
| 항목 | Qwen3-Next | 이전 Qwen3 / Qwen2.5 등 | 다른 경쟁 모델 예: DeepSeek, Claude, GPT-계열 |
|---|---|---|---|
| 목적 | 훈련 및 추론 효율성 극대화 (시간, 자원, 속도) | 이전에는 일반적 성능, 응답 품질, 다중 모달 지원 등 | 때로는 성능과 품질 우선, 비용/자원 최적화는 부차적 |
| 기술적 접근 | 경량화, 효율적인 파라미터 활용, 메모리 절약, 연산 최적화 | 큰 파라미터 수 + 무거운 추론 / 긴 문맥 길이 지원 | 일부 경량 모델 또는 특화된 모델에서 유사한 추구 존재 |
| 적용 영역 | 다양한 추론(tasks), 대화(chat), 멀티모달 포함 가능성 있음 | 포괄적 기능 제공, 하지만 비용/지연 시간이 클 수 있음 | 트레이드오프: 높은 품질 vs 비용/지연성 |
Qwen3-Next 모델의 주요 기술적 특징
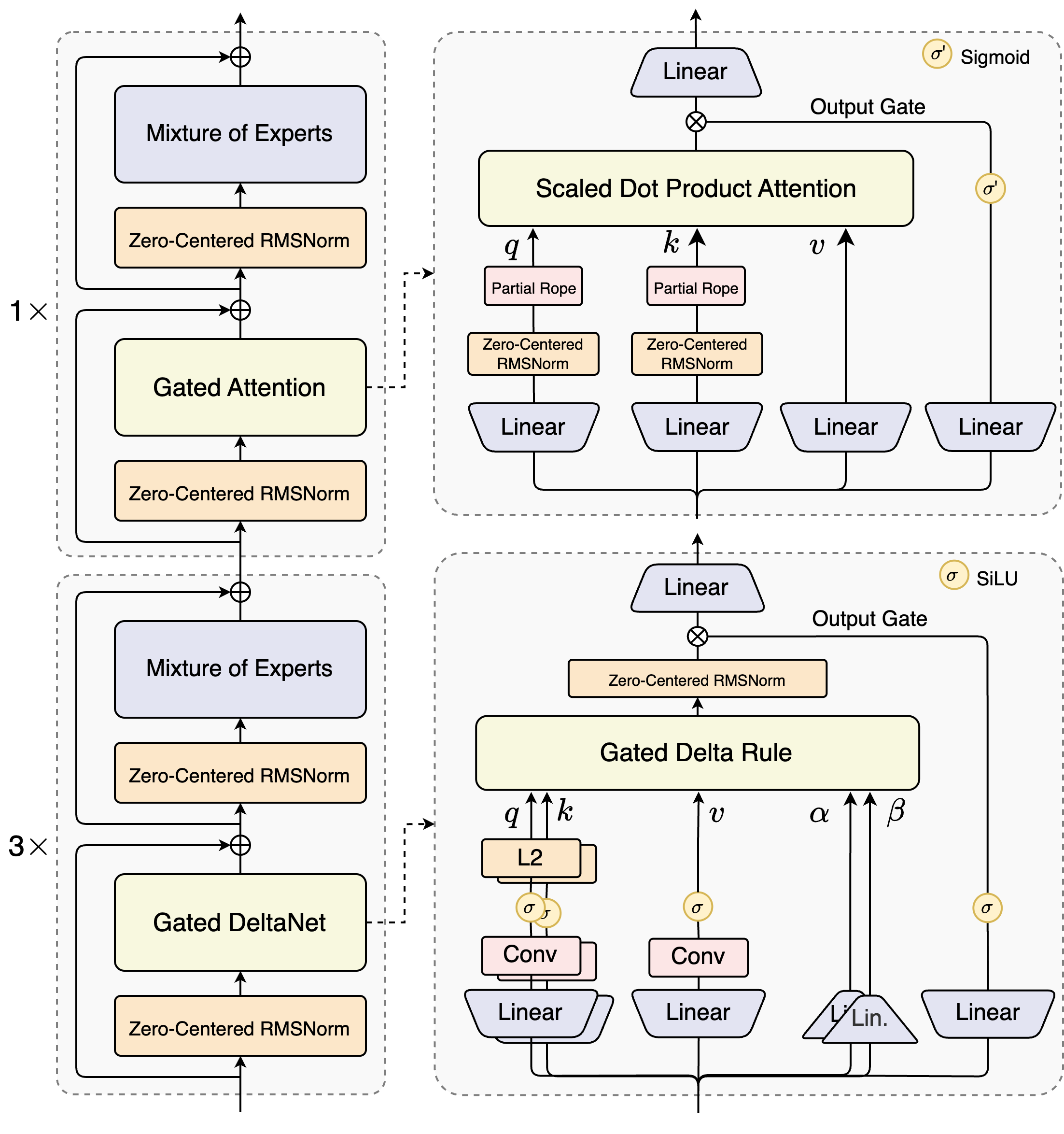
Qwen3-Next는 전통적인 Dense 모델이 아닌 Sparse MoE 기반 모델로, 필요할 때만 일부 전문가(Expert)를 호출하여 연산을 최적화합니다. 이러한 기법을 활용하여 Qwen3-Next-80B-A3B 모델은 전체 80B 규모의 모델 크기를 갖지만, 실제 추론 시에는 3B 규모의 파라매터만 활성화되기 때문에 연산 효율성이 크게 향상됩니다.
Qwen3-Next 모델의 주요한 기술적 특징은 이러한 Sparse MoE 기반의 모델이라는 점 외에도, 하이브리드 아키텍처와 학습 안정성을 위한 세부 설계, 그리고 멀티 토큰 예측(Multi-Token Prediction, MTP) 같은 것들이 있습니다:
하이브리드 아키텍처: Gated DeltaNet과 Gated Attention
Qwen3-Next의 첫 번째 특징은 Gated DeltaNet과 Gated Attention을 결합한 하이브리드 구조를 채택했다는 점입니다. 기존의 표준 Attention은 문맥 의존성 학습에 뛰어난 성능을 보이지만, 입력 길이에 따라 연산 복잡도가 제곱 형태(O(n^2))로 증가하여 긴 문맥에서는 매우 비효율적입니다. 반대로 선형 어텐션(Linear Attention)은 연산 효율성에서 강점을 가지지만, 장기 문맥을 회상하는 능력이 상대적으로 제한적이라는 단점이 있습니다.
Qwen3-Next는 이 두 가지를 절충하기 위해 전체 레이어의 75%에는 Gated DeltaNet을 적용하고, 나머지 25%에는 표준 Attention을 유지하는 방식을 채택하였습니다. 실험 결과 이 조합은 Sliding Window Attention이나 Mamba2보다 우수한 in-context learning 능력을 보였으며, 효율성과 정확성을 동시에 확보할 수 있음을 입증하였습니다. 아울러 표준 Attention 레이어에는 출력 게이팅 메커니즘을 도입하여 저차원 표현 문제를 완화하고, Attention head의 차원을 기존 128에서 256으로 확장하여 표현력을 강화하였습니다. 또한 RoPE(Rotary Position Embedding)를 전체 포지션 차원의 25%에만 적용하여 장문 입력에 대한 일반화 능력을 개선하였습니다.
단 3.7%의 파라매터만 활성화하는 Ultra-Sparse MoE
Qwen3-Next는 Ultra-Sparse MoE(Mixture of Experts) 구조를 도입하여 효율성과 성능을 동시에 확보하였습니다. Qwen3-Next 모델은 약 800억 개의 파라미터를 보유하고 있지만, 실제 추론 단계에서 활성화되는 파라미터는 약 37억 개로 전체의 3.7%에 불과합니다.
이는 Qwen3에서 사용된 MoE 설계와 비교했을 때 중요한 차별점입니다. Qwen3는 128명의 전문가 중 8명을 활성화하는 구조였으나, Qwen3-Next는 512명의 전문가 풀을 보유하면서도 매 토큰마다 10명의 전문가(Experts)와 1명의 공유 전문가(Shared Expert)만 활성화합니다. 이러한 방식은 전문가 풀의 규모를 확장하면서도 연산 효율성을 극대화하고 성능 저하를 방지합니다. 또한 글로벌 로드 밸런싱 기법을 적용하여 특정 전문가에게 연산이 과도하게 집중되는 문제를 방지함으로써 안정적인 성능을 확보하였습니다.
학습 안정성을 위한 정교한 설계 (Training-Stability-Friendly Designs)
대규모 모델을 학습시키는 과정에서는 Attention Sink나 Massive Activation과 같은 불안정성이 자주 발생합니다. Qwen3-Next는 이러한 문제를 완화하기 위해 출력 게이팅 메커니즘을 도입하여 Attention 출력의 안정성을 보장하였고, Qwen3에서 사용되던 QK-Norm 대신 Zero-Centered RMSNorm을 채택하였습니다.
또한, 정규화 파라미터가 비정상적으로 커지는 현상을 막기 위해 weight decay를 적용하였으며, MoE 라우터 파라미터 초기화 과정에서도 전문가가 편향되지 않도록 정규화를 진행했습니다. 이러한 안정성 중심 설계는 소규모 실험의 재현성을 높이는 동시에 대규모 학습을 원활하게 진행할 수 있도록 돕습니다.
추론 효율을 위한 다중 토큰 예측(MTP: Multi-Token Prediction)
Qwen3-Next는 기존 모델과 달리 한 번에 여러 토큰을 생성할 수 있는 Multi-Token Prediction(MTP) 기능을 기본적으로 지원합니다. 이는 단순히 속도를 높이는 것에 그치지 않고, Speculative Decoding과 결합될 때 높은 수용률(Acceptance Rate)을 보임으로써 추론의 효율성을 극대화합니다.
특히 Qwen3-Next는 멀티 스텝 학습을 통해 학습 단계와 추론 단계 간의 일관성을 유지하도록 설계되었기 때문에 실제 서비스 환경에서도 지연시간(latency)를 줄이고 처리량을 크게 개선할 수 있습니다. 이러한 특성은 실시간 응용 서비스에서 매우 중요한 장점으로 작용합니다.
사전 학습 (Pre-training)
효율성 및 추론 속도 (Pretraining Efficiency & Inference Speed)
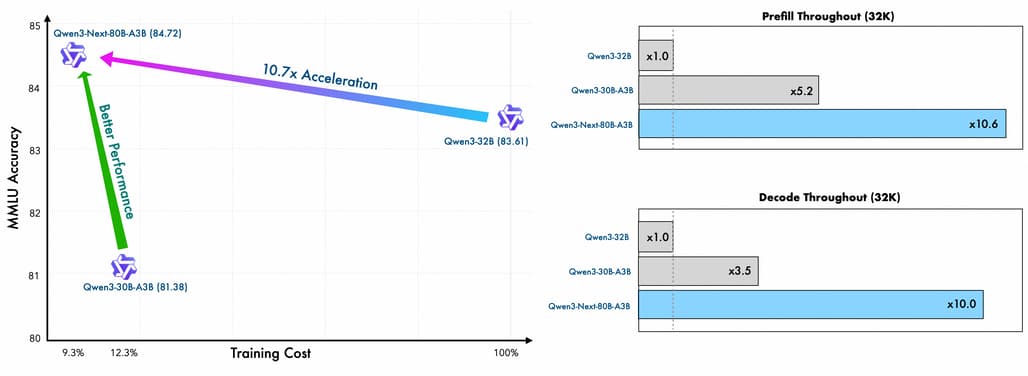
Qwen3-Next는 Qwen3에서 사용된 36조(36T) 토큰의 대규모 학습 말뭉치 중 15조(15T) 토큰을 균일하게 샘플링(Uniformly Sampled Subset)하여 사전 학습에 활용하였습니다. 이 과정에서 단순히 데이터 규모를 줄인 것이 아니라, 모델 구조의 효율화와 최적화된 학습 기법을 통해 기존보다 훨씬 적은 연산량으로도 더 나은 성능을 달성할 수 있었습니다.
실제로 기존에 공개했던 Qwen3-30A-3B와 비교했을 때 GPU 학습 시간이 80% 이하로 줄었고, Qwen3-32B 대비 연산 비용은 9.3% 수준에 불과하면서도 오히려 성능이 개선되었습니다. 이는 대규모 모델의 학습 효율성 측면에서 매우 중요한 이정표라 할 수 있습니다.
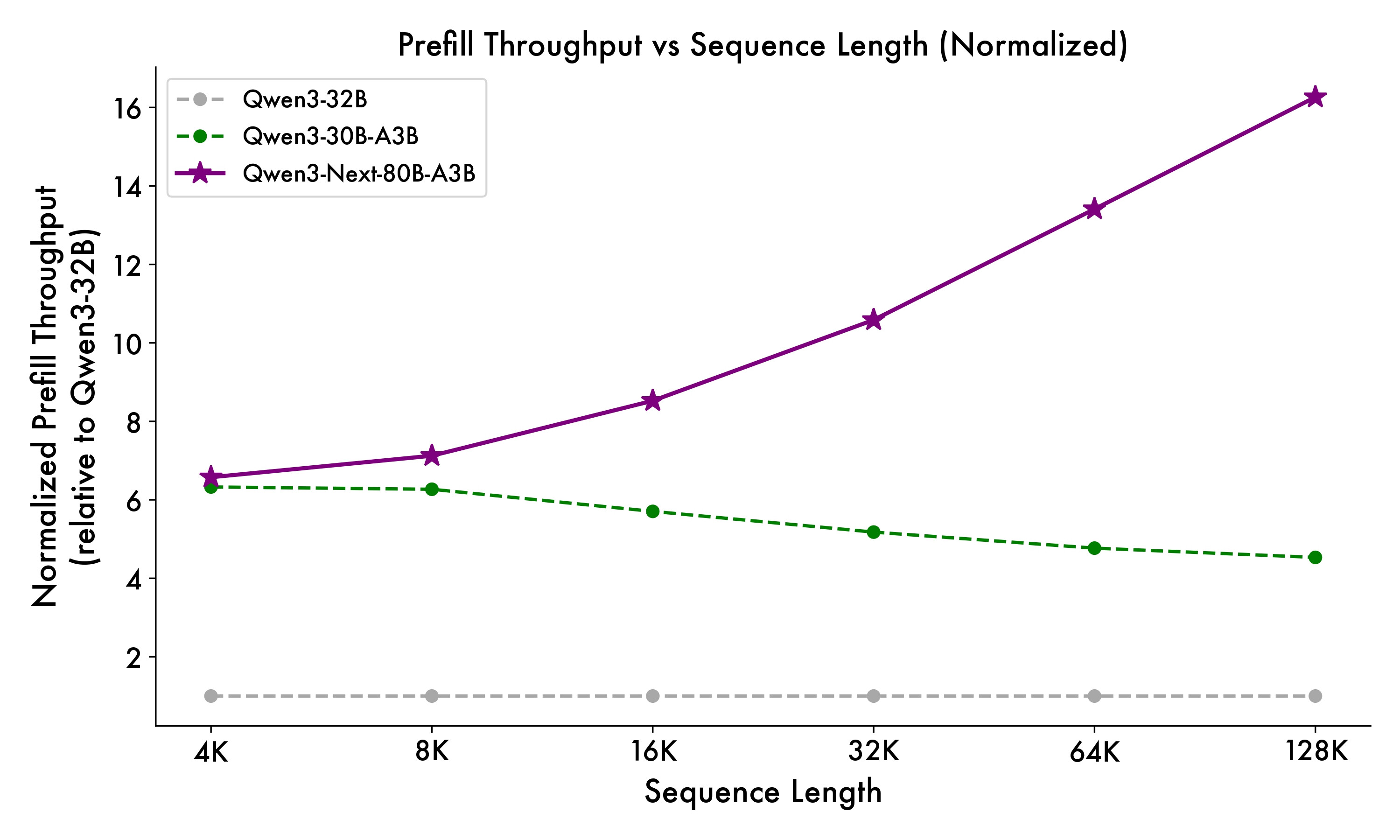
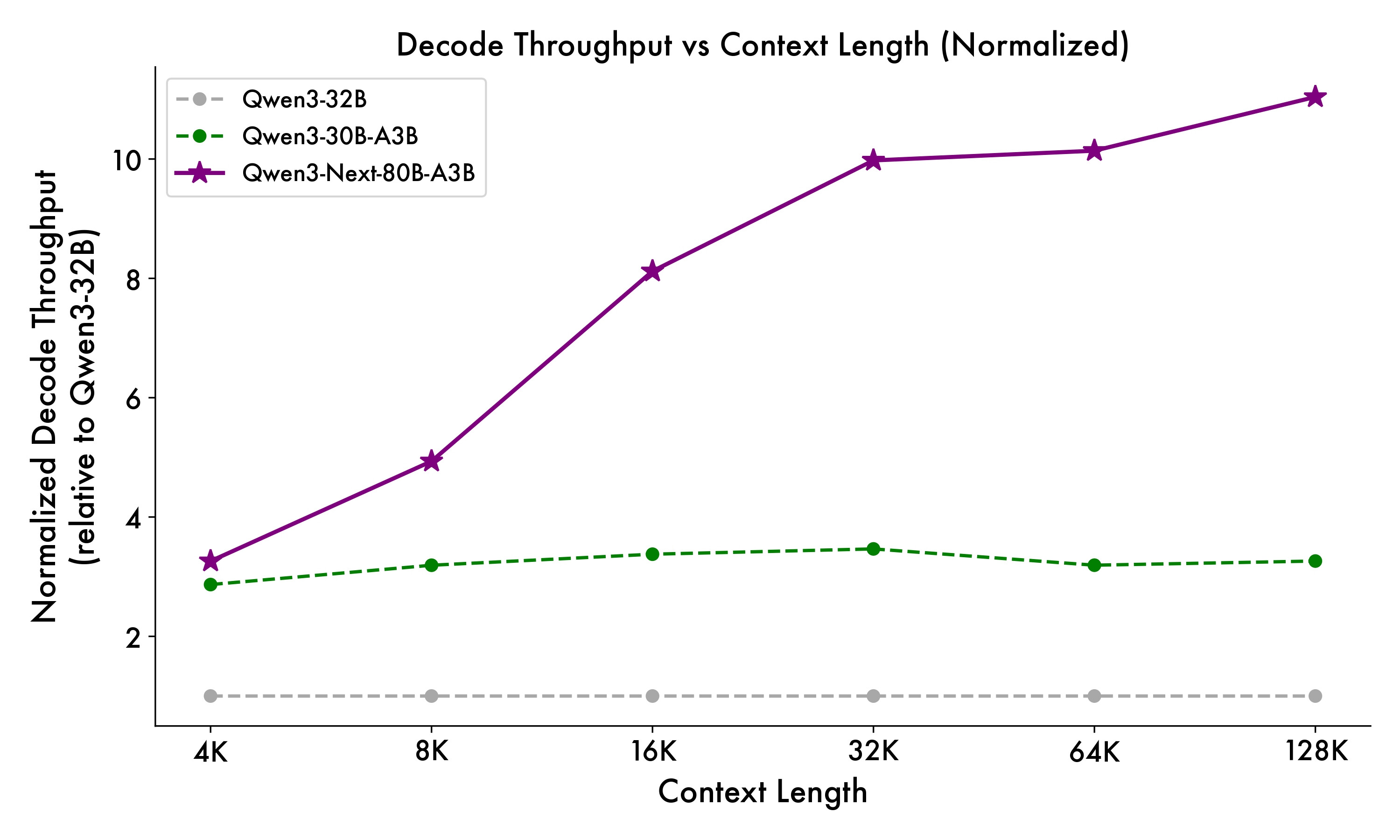
Qwen3-Next는 추론 단계에서도 독특한 하이브리드 아키텍처 덕분에 강력한 장점을 보여줍니다. 문맥을 사전 주입하는 프리필(prefill) 단계에서는 4K 토큰 기준으로 Qwen3-32B보다 약 7배 높은 처리량을 기록하였으며, 32K 이상의 긴 문맥으로 갈수록 그 차이는 10배 이상으로 벌어집니다. 텍스트를 실제로 생성하는 디코드(decode) 단계에서도 4K 기준으로 약 4배 더 빠르고, 긴 문맥에서도 여전히 10배 이상의 속도 우위를 유지합니다. 이러한 개선은 단순히 벤치마크 수치의 향상을 넘어, 실시간 대화형 서비스나 초대형 문서 처리에서 체감할 수 있는 성능 향상을 의미합니다.
기본 모델 성능 (Base Model Performance)
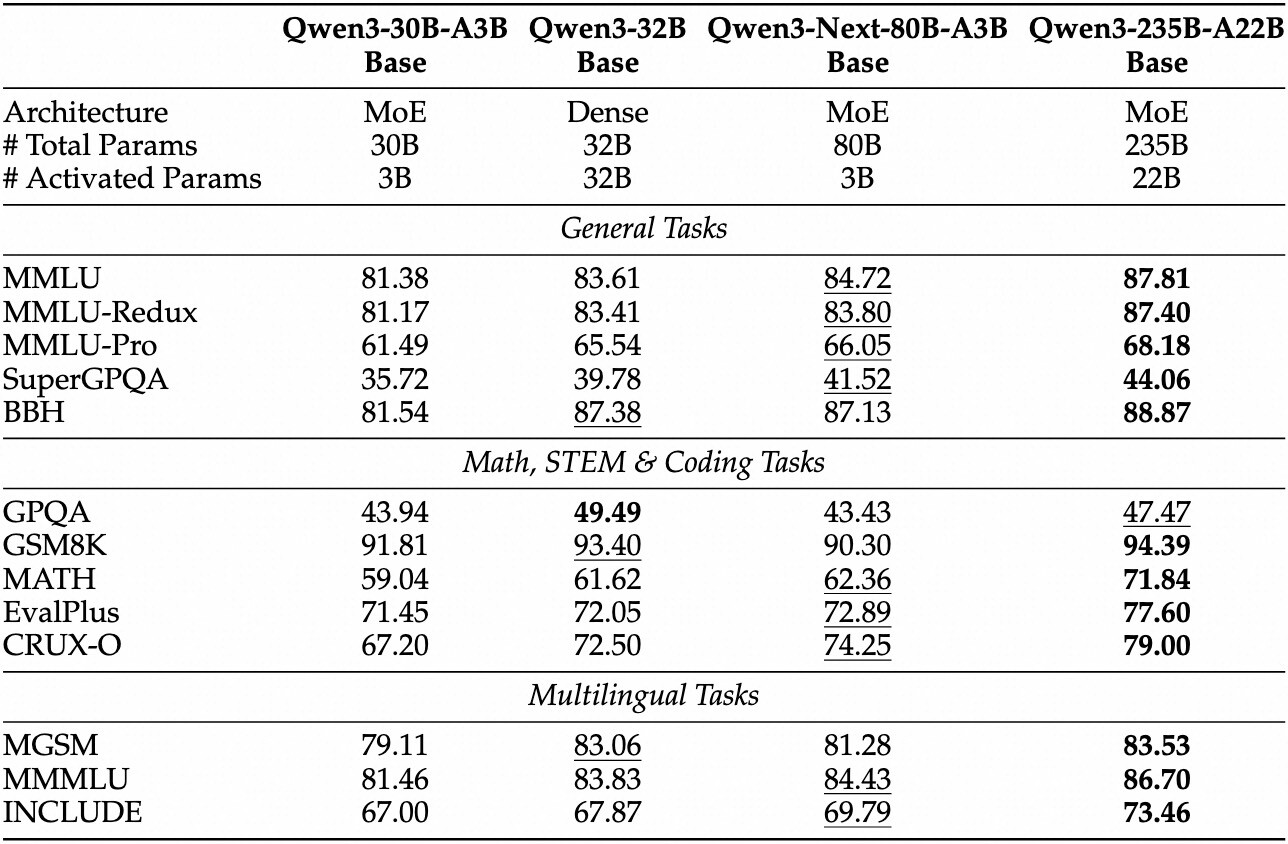
Qwen3-Next-80B-A3B-Base 모델은 전체적으로 800억 개에 달하는 파라미터를 보유하지만, 추론 시 활성화되는 비임베딩(non-embedding) 파라미터는 Qwen3-32B-Base의 10분의 1에 불과합니다. 그럼에도 불구하고 다양한 벤치마크에서 Qwen3-32B-Base를 능가하며, Qwen3-30B-A3B보다도 확실히 우수한 성능을 보입니다. 이는 단순히 모델 크기에 의존하지 않고, 효율적인 구조 설계와 선택적 연산 덕분에 자원 소모를 최소화하면서도 경쟁력을 유지할 수 있다는 점을 보여줍니다. 결과적으로 Qwen3-Next는 효율성과 성능이라는 두 가지 축을 동시에 충족하는 드문 사례라 할 수 있습니다.
사후 학습 (Post-training)
지시 모델 성능 (Instruct Model Performance)
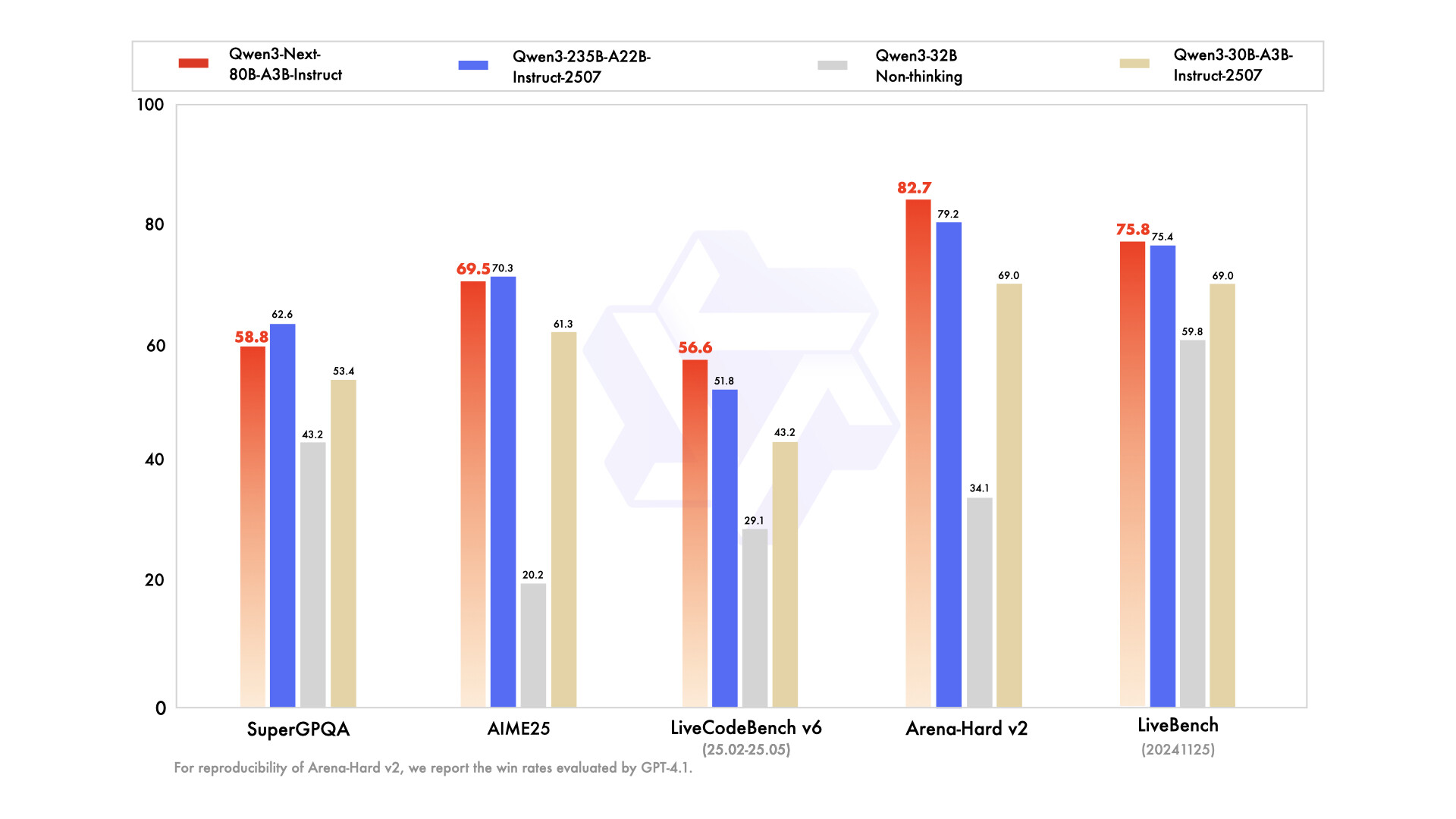

사용자의 지시나 질문에 맞춰 응답하는 Instruct 모델은 Qwen3-Next의 가장 실용적인 응용 형태입니다. Qwen3-Next-80B-A3B-Instruct는 이전 세대 모델인 Qwen3-30B-A3B-Instruct-2507 및 Qwen3-32B-Non-thinking 모델을 확실히 앞서며, 플래그십 모델인 Qwen3-235B-A22B-Instruct-2507에 거의 근접하는 성능을 보입니다. 특히 장문 처리 성능을 평가하는 RULER 벤치마크에서는 모든 문맥 길이에서 Qwen3-30B-A3B-Instruct-2507을 능가했을 뿐 아니라, 256K 토큰 환경에서는 더 큰 규모의 Qwen3-235B 모델보다도 우세한 결과를 기록했습니다. 이는 Gated DeltaNet과 Gated Attention을 결합한 하이브리드 구조가 긴 문맥 처리에서 특히 강력한 효과를 발휘한다는 사실을 입증합니다.
추론 모델 성능 (Thinking Model Performance)
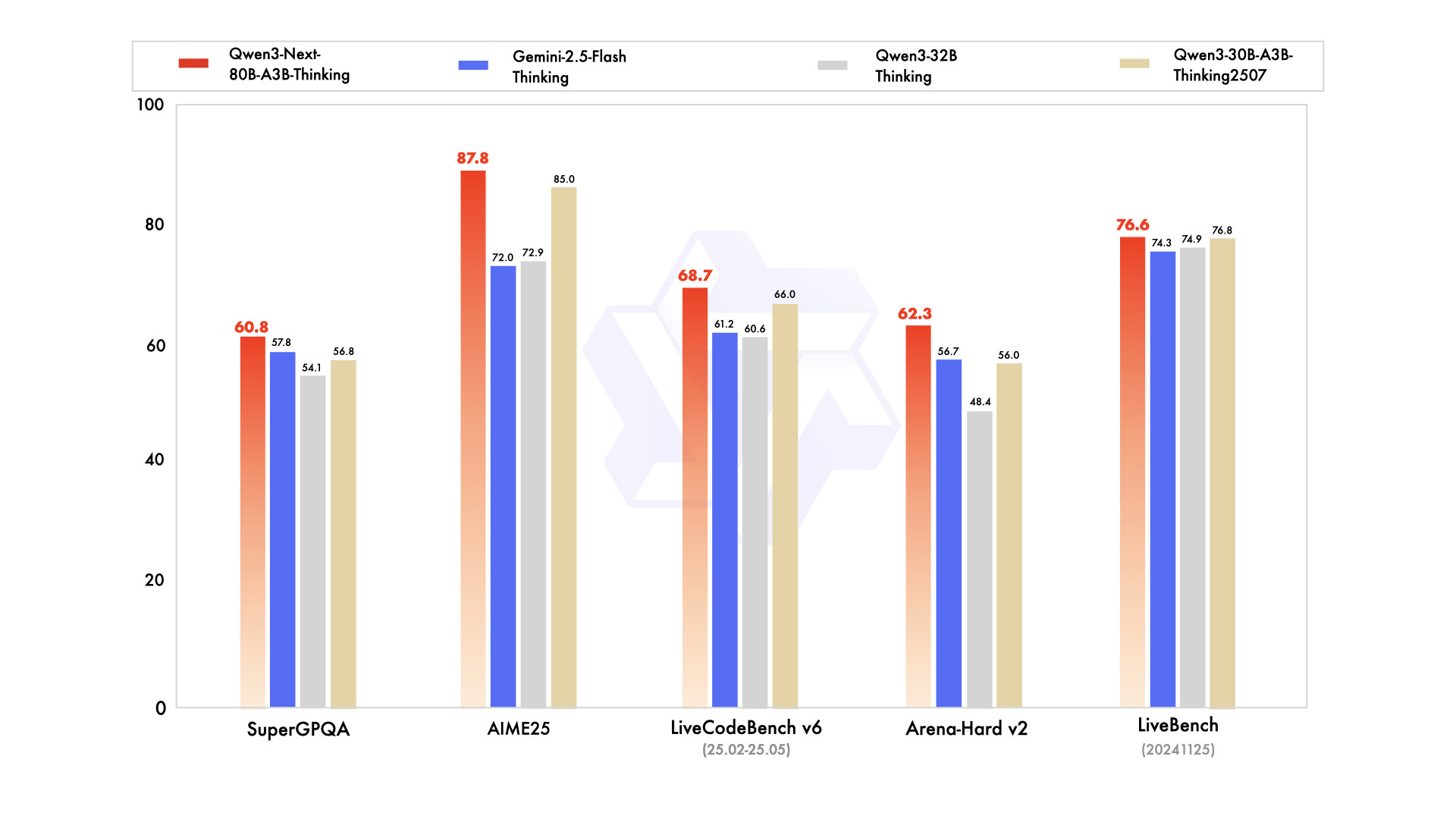
Qwen3-Next는 복잡한 추론과 사고 과정을 요구하는 태스크에 특화된 Thinking 버전도 제공합니다. Qwen3-Next-80B-A3B-Thinking은 Qwen3-30B-A3B-Thinking-2507이나 Qwen3-32B-Thinking 같은 고비용 모델보다 더 나은 결과를 내며, 폐쇄형 상용 모델인 Gemini-2.5-Flash-Thinking을 여러 벤치마크에서 능가했습니다. 또한 최신 플래그십 모델인 Qwen3-235B-A22B-Thinking-2507과도 주요 지표에서 근접한 성능을 보였습니다. 이는 Qwen3-Next가 단순히 효율성을 강조하는 모델이 아니라, 실제 고난도의 reasoning task에서도 충분히 경쟁할 수 있음을 보여줍니다.
Qwen3-Next 개발 및 활용
Qwen3-Next는 Hugging Face Transformers 라이브러리에 통합되어 있으며, 간단한 코드 설치를 통해 바로 사용할 수 있습니다. 모델 불러오기와 텍스트 생성을 위한 기본 코드가 제공되며, Instruct 버전을 기준으로 다양한 태스크를 수행할 수 있습니다. Qwen3-Next 모델을 불러오는 중 KeyError: 'qwen3_next'라는 에러가 발생한다면, 다음과 같은 명령어로 최신 버전의 Transformers를 설치하여 해결할 수 있습니다:
pip install git+https://github.com/huggingface/transformers.git@main
다만 멀티 토큰 예측(Multi-Token Prediction, MTP) 기능은 아직 Hugging Face 기본 구현에 포함되어 있지 않아, 효율성 개선을 위해서는 SGLang이나 vLLM 같은 전용 추론 프레임워크 사용이 권장됩니다. 이러한 프레임워크는 OpenAI 호환 API 서버를 손쉽게 띄울 수 있도록 지원하며, 긴 문맥 환경에서도 안정적인 성능을 발휘합니다.
아래는 Hugging Face 환경에서 Instruct 모델을 불러와 간단한 대화형 입력을 처리하는 예시 코드입니다:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# 토크나이저와 모델 로드
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# 사용자 입력 준비
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 텍스트 생성
generated_ids = model.generate(**model_inputs, max_new_tokens=16384)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
위 예시를 통해 단순한 프롬프트 입력에서부터 대규모 출력까지 수행할 수 있으며, 긴 문맥 입력을 처리할 때도 안정적으로 동작합니다.
추론 효율성을 더욱 극대화하려면 vLLM 또는 SGLang을 사용하는 것이 좋습니다. vLLM은 메모리 효율과 처리량을 극대화한 추론 엔진으로, OpenAI 호환 API 서버를 실행할 수 있습니다.
먼저, 최신 버전의 vLLM 또는 SGLang이 필요합니다. 사용자의 선호에 따라 둘 중 하나를 선택하여 설치합니다:
# vLLM 설치
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
# SGLang 설치
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
기본적으로는 다음과 같은 명령어를 통해 4개의 GPU를 활용하여 256K 토큰 컨텍스트 길이를 지원하는 API 엔드포인트를 띄울 수 있습니다:
# 기본 실행 w/ 4개 GPU + 256K Context
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144
만약 MTP 기능까지 활용하고 싶다면 다음과 같이 speculative decoding 옵션을 추가하여 실행할 수 있습니다.
# MTP 기능 활용 실행 w/ 4개 GPU + 256K Context
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
SGLang에서도 다음의 명령어들로 실행할 수 있습니다:
# 기본 실행 w/ 4개 GPU + 256K Context
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 \
python -m sglang.launch_server \
--model-path Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 30000 \
--tp-size 4 \
--context-length 262144 \
--mem-fraction-static 0.8
# MTP 기능 활용 실행 w/ 4개 GPU + 256K Context
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 \
python -m sglang.launch_server \
--model-path Qwen/Qwen3-Next-80B-A3B-Instruct \
--port 30000 \
--tp-size 4 \
--context-length 262144 \
--mem-fraction-static 0.8 \
--speculative-algo NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4
에이전틱 활용: Qwen-Agent
Qwen3-Next 모델은 Qwen-Agent를 통해 에이전틱 기능을 확장할 수 있습니다. 이는 도구 호출(tool calling) 능력을 내장하고 있어, 외부 도구와 연계된 복잡한 작업을 수행할 때 코드 작성의 부담을 줄여줍니다. 예를 들어, 시간 조회나 웹 데이터 가져오기 같은 도구를 MCP 설정 파일로 간단히 등록하거나, 내장된 코드 인터프리터를 사용할 수 있습니다. 이러한 기능은 Qwen3-Next를 단순한 언어 모델이 아니라, 다양한 환경에 통합될 수 있는 지능형 에이전트로 발전시키는 기반이 됩니다. 다음은 Qwen-Agent를 이용해 기본적인 어시스턴트를 정의하고, 외부 요청을 처리하는 예시입니다:
from qwen_agent.agents import Assistant
# 모델 설정
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
'model_server': 'http://localhost:8000/v1', # OpenAI 호환 API 엔드포인트
'api_key': 'EMPTY',
}
# 툴 정의
tools = [
{'mcpServers': {
'time': {'command': 'uvx', 'args': ['mcp-server-time', '--local-timezone=Asia/Seoul']},
"fetch": {"command": "uvx", "args": ["mcp-server-fetch"]}
}},
'code_interpreter'
]
# 에이전트 실행
bot = Assistant(llm=llm_cfg, function_list=tools)
messages = [{'role': 'user', 'content': 'Qwen의 최신 업데이트를 소개해줘'}]
for responses in bot.run(messages=messages):
pass
print(responses)
이처럼 Qwen3-Next는 단순한 언어 모델을 넘어, 강력한 추론 엔진과 다양한 개발 툴, 에이전트 환경까지 통합하여 활용할 수 있는 실용적인 플랫폼으로 자리잡고 있습니다. Hugging Face, SGLang, vLLM, 그리고 Qwen-Agent와 같은 생태계의 지원을 통해, 개발자들은 손쉽게 서비스를 구축하고 실제 환경에서의 성능을 극대화할 수 있습니다.
초장문 처리와 확장성
Qwen3-Next는 기본적으로 262,144 토큰까지의 문맥 길이를 네이티브로 지원하며, 확장 기법을 적용하면 최대 100만 토큰까지 처리할 수 있습니다. 이를 위해 RoPE 스케일링, 특히 YaRN 기법이 활용되며, 현재 Transformers, vLLM, SGLang 같은 주요 프레임워크에서 지원됩니다. 이를 활성화하기 위해서는 다운로드 받은 모델 파일 중 config.json 파일에 다음과 같이 rope_scaling 필드를 추가하면 됩니다:
# 모델 디렉토리 내의 config.json 아래 `rope_scaling`을 추가합니다.
# Hugging Face에서 다운로드 받은 모델은 일반적으로 ~/.cache/huggingface/hub/ 에 위치합니다.
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
vLLM 또는 SGLang으로 실행하는 경우에는 config.json 파일을 수정하는 대신, 다음과 같은 옵션을 제공하여 사용할 수 있습니다:
# vLLM 사용 시
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
# SGLang 사용 시
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
다만 YaRN은 입력 길이와 상관없이 고정된 스케일링 계수를 사용하기 때문에 짧은 텍스트에서는 성능에 영향을 줄 수 있습니다. 따라서 애플리케이션의 일반적 입력 길이에 따라 적절한 계수를 설정하는 것이 바람직합니다. 예컨대 일반적으로 50만 토큰 정도의 입력을 다루는 경우라면 factor를 2.0으로 설정하는 식의 조정이 권장됩니다.
정리
Qwen3-Next는 단순히 또 하나의 대형 언어 모델이 아니라, 학습과 추론의 효율성을 동시에 달성하면서도 긴 문맥 처리와 복잡한 추론까지 포괄할 수 있는 새로운 세대의 모델입니다. Instruct와 Thinking 두 가지 형태로 제공되어 다양한 응용 시나리오에 대응할 수 있으며, 성능 면에서는 기존 235B 모델에 근접한 수준을 보여주면서도 훨씬 가볍고 빠르게 동작합니다. 이러한 특성은 오픈소스 생태계 전반에서 개발자들이 최신 아키텍처의 장점을 적극적으로 활용할 수 있도록 하며, 향후 Qwen3.5로 이어지는 발전의 초석이 될 것입니다.
 Qwen3-Next 사용 데모: Qwen Chat
Qwen3-Next 사용 데모: Qwen Chat
Qwen3-Next 사용 데모: Hugging Face
 Qwen3-Next 출시 블로그
Qwen3-Next 출시 블로그
 Qwen3-Next-80B 모델 다운로드
Qwen3-Next-80B 모델 다운로드
 Qwen3-Next-80B 모델 다운로드
Qwen3-Next-80B 모델 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()